Can you determine who believes something incorrectly in this scene? In this project, we study how to recognize when a person in a scene is mistaken. Above, the woman is mistaken about the chair being pulled away from her in the third frame, causing her to fall down. The red arrow indicates false belief. We introduce a new dataset of abstract scenes to study when people have false beliefs. We propose approaches to learn to recognize who is mistaken and when they are mistaken.
Recognizing when people have false beliefs is crucial for understanding their actions. We introduce the novel problem of identifying when people in abstract scenes have incorrect beliefs. We present a dataset of scenes, each visually depicting an 8-frame story in which a character has a mistaken belief. We then create a representation of characters' beliefs for two tasks in human action understanding: predicting who is mistaken, and when they are mistaken. Experiments suggest that our method for identifying mistaken characters performs better on these tasks than simple baselines. Diagnostics on our model suggest it learns important cues for recognizing mistaken beliefs, such as gaze. We believe models of people's beliefs will have many applications in action understanding, robotics, and healthcare.
Scenes
Below are some selected scenes from our dataset. These scenes highlight the many ways characters can be mistaken. In these scenes, we use red arrows to indicate which characters are mistaken. Each scene (row) contains eight images, depicting a visual story when read left to right. The caption below each scene was collected during annotation for visualization purposes only.
Animated Scenes
We animated some of the scenes in our dataset. In the videos below, red arrows indicate which characters are mistaken. The text in the bottom portion of each video is the scene-level description collected during annotation. These descriptions were not used during training. For more videos, please see this page
Person-Centric Representation
Before predicting whether a character is mistaken, we
must tell our model which character to focus on. To do
this, we propose a person-centric representation of the world,
where the model takes the perspective of an outside ob-
server focusing on a specific character. For each frame in
the scene, we center the frame at the head of the specified
character. We also flip the frame so the specified character
always faces left. For example, in the figure below, the frame in the
upper left can be viewed from each of the three characters’
perspectives, shown on the right.
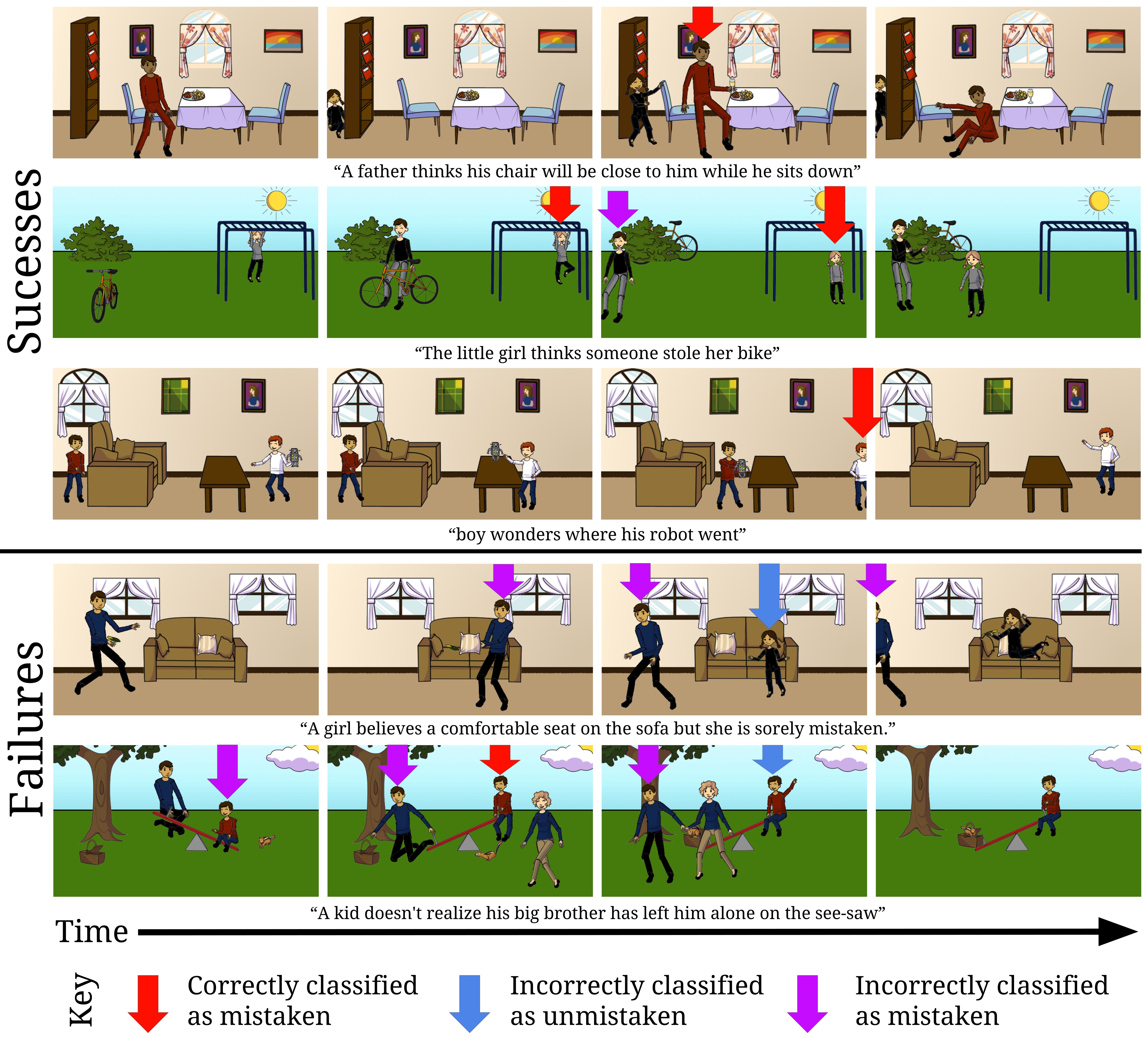
Predictions from our model
In the figure below, we show predictions made by our model on five scenes. Our model performs well on the first three scenes, but fails to detect mistaken characters in the last two scenes.
Explanations:
First Row: Our model correctly detects that the man is mistaken in the third frame when the girl is about to pull his chair from beneath him. In this scene, the man is mistaken because he cannot see the girl's actions behind him.
Second Row: Our model correctly predicts that the girl is mistaken in the second and third frames as she can not see the man take her bike. Our model incorrectly predicts that the man is also mistaken in the third frame. This is possibly because our model has learned that a character is likely to be mistaken when another character is performing actions behind it.
Third Row: Our model correctly identifies the boy wearing a white shirt as mistaken in the third frame.
Fourth Row: The man plays a prank on the girl by hiding a piece of corn beneath a pillow. Our model incorrectly predicts that the man is mistaken, likely because he cannot see the actions of the girl behind him. Our model incorrectly predicts that the girl is not mistaken in the third frame, perhaps because the corn is occluded behind the pillow. Our model might think that the corn disappeared when it became occluded.
Fifth Row: Another failure case in which a man places a basket on the see-saw, leaving the boy stranded. Our model incorrectly predicts that the boy has a misbelief in the first frame, but is not mistaken in the third frame. Understanding this situation requires knowledge of basic physics, which our model currently lacks.
Brief Technical Overview
We use a frame-wise approach to processing scenes, extracting visual features for each frame and concatenate them temporally to create a time-series.
We extract visual features from the person-centric images using a convolutional network trained for object recognition.
To combine information from multiple frames, we perform a 1-dimension convolution across time.
Experimentally, we found that looking features from past and future frames helps the model recognize mistaken characters in the present frame. We also found that gaze and the arrow of time were important cues for recognizing mistaken characters.
Notes on Failures & Limitations
Recognizing mistaken character's is a challenging task, and our model has several limitations.
There are many ways characters can be mistaken. Our model cannot reason about occlusion and physics, so it fails to recognize some types of mistaken characters.
Our model was trained on abstract scenes, not real videos. We computed image features using a model trained on real images, which might make it easier to apply our model to real videos.
When collecting our dataset of abstract scenes, we instructed workers to include at least one mistaken character in each scene. In real videos, characters as mistaken less frequently than they are in our scenes.
Our dataset contains biases which do not exist in real videos. For example, in our scenes, characters are more likely to be mistaken near the end of the scene, and certain characters are more likely to be mistaken than others. Our baseline models, which exploit these biases perform better than random chance, but worse than our model.
Related Works
This project builds on top of a number of great papers. We encourage you to read them!
Run python mistaken.py -h to show command line options. Flags such as -USE_EXPRESSION indicate which features to use. Multiple flags can be specified to include multiple features. Arguments such as --LOOKAHEAD=3 allow other model parameters to be set.
We believe strongly in collaboration and reproducible results. Please contact us know if you encounter bugs or if pieces are confusing.
Data
We are making the scenes and annotations available for others to use:
We thank the many workers on Amazon Mechanical Turk for their creative scenes. NVidia donated GPUs used for this research. This work was supported by Samsung, a Google PhD fellowship to Carl Vondrick, and the MIT UROP program.