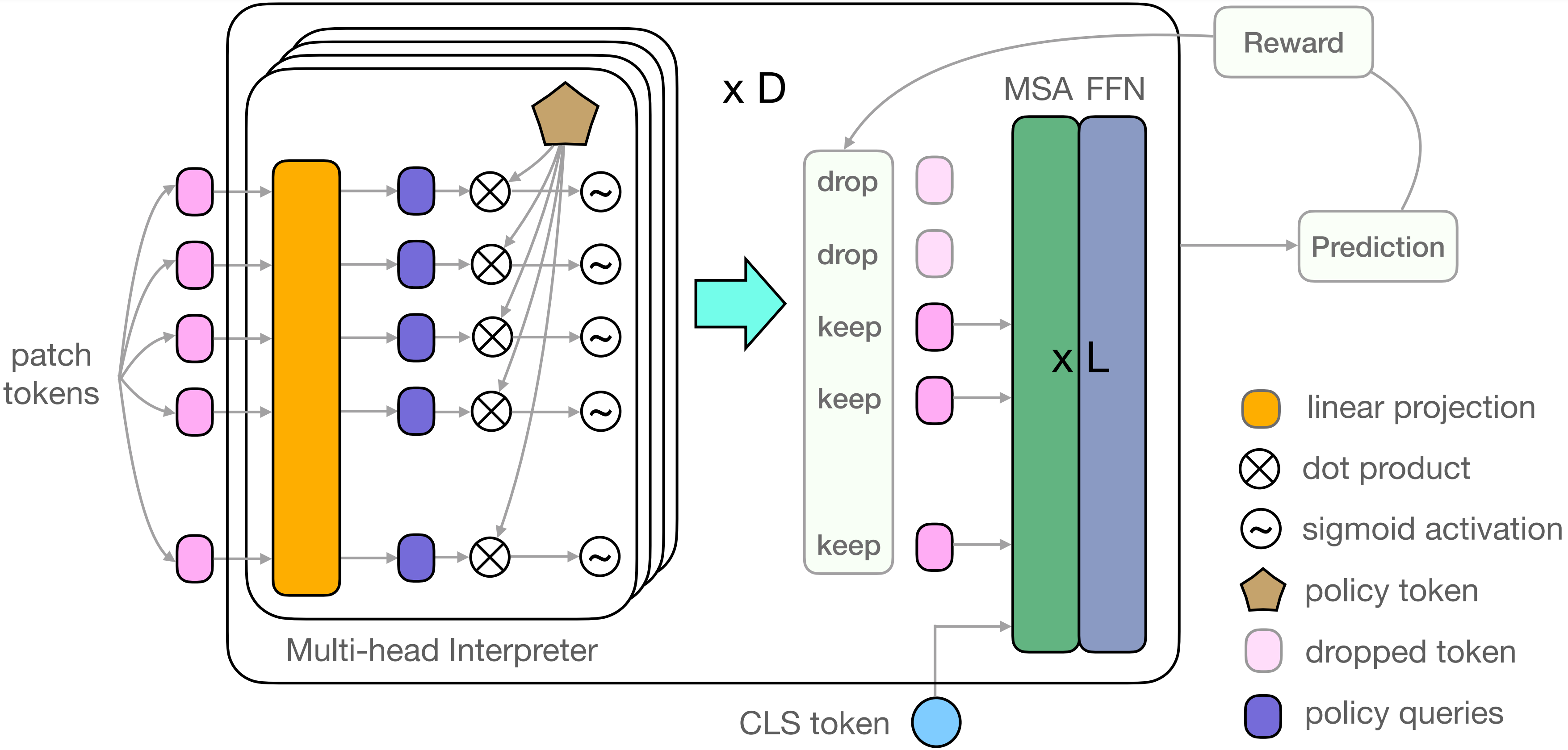
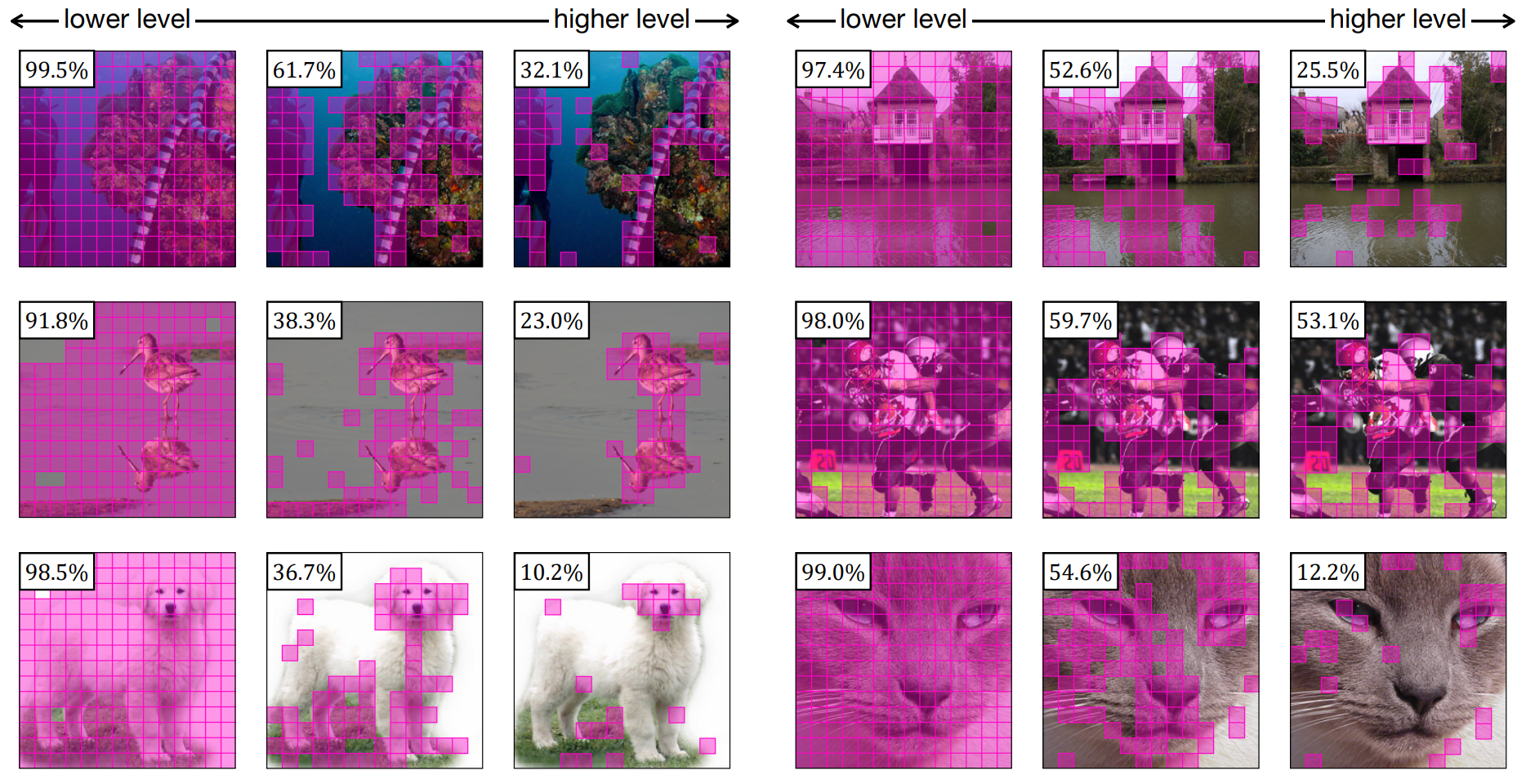
We propose a novel Interpretability-Aware REDundancy REDuction (IA-RED2) framework for reducing the redundancy of vision transformers. The key mechanism that IA-RED2 uses to increase efficiency is to dynamically drop some less informative patches in the original input sequence so that the length of the input sequence could be reduced. While the original vision transformer tokenizes all of the input patches, it neglects the fact that some of the input patches are redundant and such redundancy is input-dependant (see from Figure). We leverage the idea of dynamic inference, and adopt a policy network (referred to as multi-head interpreter) to decide which patches are uninformative and then discard them. Our proposed method is inherently interpretability-aware as the policy network learns to discriminate which region is crucial for the final prediction results.
IA-RED2: Interpretability-Aware Redundancy Reduction for Vision Transformer |
||
Bowen Pan1, Rameswar Panda2, Yifan Jiang3, Zhangyang Wang3, |
||
1 MIT CSAIL, 2 MIT-IBM Watson AI Lab, 3 UT Austin |
||
[Paper] [Code (coming soon)] [Interpretation Tool] |
||