IEEE Transactions
on Pattern Analysis and Machine Intelligence, Vol. 33, No. 12, December 2011
Data & Matlab/C++ Code
Ce Liu
Microsoft Research New England
Massachusetts Institute of Techonolgy
[Webpage] [Download the PDF]
Download the code and database
Disclaimer
|
|
This code is written purely for research purposes. I have tested the system on 64-bit version of Windows 7, Mac OS 10.6 and Linux. However, there is no guarantee that the system is going to work in your system (depending on your OS, C++ compiler and Matlab version), and I am not responsible for debugging the system for you. You are more than welcome to send me bugs as well as your thoughts, but reply is not guaranteed. |
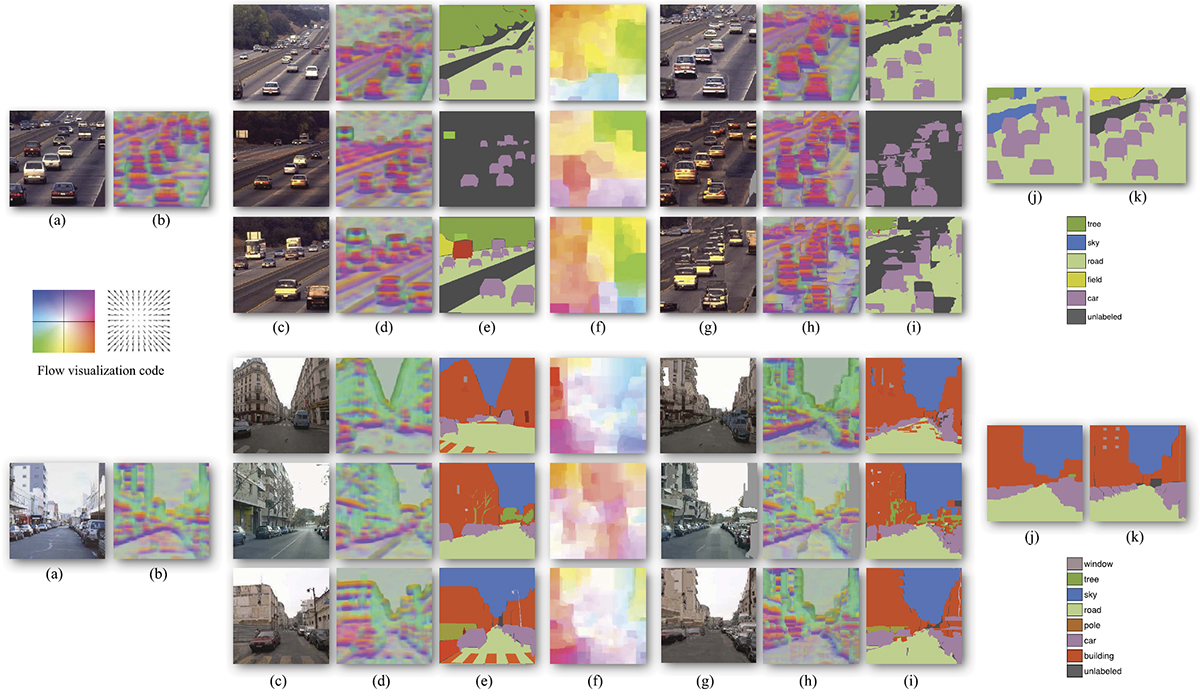 |
|
Label transfer system overview. For a query image, our system uses scene retrieval techniques such as [Shotton 2011] to find nearest neighbors in our
database. We apply coarse-to-fine SIFT flow to align the query image to the nearest neighbors, and obtain top voting candidates (3
here). (c), (d), (e): The RGB image, SIFT image and user annotation of the voting candidates. (f): The inferred SIFT flow field, visualized using the
color scheme shown on the left (hue: orientation; saturation: magnitude). (g), (h), and (i) are the warped version of (c), (d), (e) with respect to the
SIFT flow in (f). Notice the similarity between (a) and (g), (b) and (h). Our system combines the voting from multiple candidates and generates
scene parsing in (j) by optimizing the posterior. (k): The ground-truth annotation of (a).
|
Mex
There are two folders, matlab and datasets under the home folder. Under matlab, there are subfolders called mexDenseSIFT, SIFTflow, warpImageInt, and mexIntegrateAnnotation. Please make sure that corresponding mex files are in these folders. For example, in mexDenseSIFT, you can find mexDenseSIFT.mexw64 (for Win 64) and mexDenseSIFT.mexmaci64 (for Mac OS 10). There is a file project.h in each folder specifying the OS. For example, if you need to compile the files under Linux, you need to uncomment the line
In general, it is straightforward to compile the mex file in each folder. We have provided a batch process file; simply run
in the folder of matlab to mex all the dlls. If some of them fail, you can compile them separately as well.
There is one cpp file with the same name as the subfolder. For example, in mexDenseSIFT subfolder, there are four cpp files, mexDenseSIFT.cpp, Matrix.cpp, Vector.cpp and dir.cpp. Change current directory to this folder, and type
mex mexDenseSIFT.cpp Matrix.cpp Vector.cpp dir.cpp
in Matlab to compile the dll.
Multi-threading
Multi-threading can make the code run much faster. Make sure that your matlab supports multiple workers (either local or through network). If your matlab supports multiple workers, then please make sure
setting.IsMultiThread = true;
is uncommented in setEnvironment.m. Otherwise, please comment this line so that multithreading is turned off.
Under the folder matlab, run
to set multi-threaded parfor loop in matlab. You can specify the number of cores (workers) based on your computer name. I have found it very useful to do so when I have to debug my system on multiple machines. If you do not specify computer names, then the number of workers is 4.
Datasets
There are two subfolders under datasets: datasetLMO and datasetSUN. They correspond to the LabelMe Outdoor (LMO) and SUN databases, respectively. We have genreated the split of training and testing datasets in the datasets enclosed in the package. All the images in the databases have been densely labeled using the LabelMe online annotation tool.
In the original download package, SIFT flow fields are NOT included since they are too large. However, some precompted SIFT flow fields for these datasets can be downloaded below:
After these files are downloaded, please make sure that they are expanded to the folder alpha=* under folder matching in the corresponding dataset. For example, after downloading and unzipping the first file, you should able to see 200 mat files under the folder
home/datasets/datasetLMO/matching/alpha=0.7/
where home is the folder to which the entire package is unzipped.
Please do not worry if you feel that the precomputed SIFT flow fields are too large to download. You will receive instructions in the next section how to compute SIFT flow fields by yourself (it will take some time to compute, though).
Run the code
The two main matlab functions are batchSIFTflow.m and objectRecognition.m. First, we need to call batchSIFTflow.m to generate dense correspondens. Here are some sample code:
database = 'datasetLMO';
setMultiThread
batchSIFTflow(database,'K',20,'KNNmethod','all','alpha',1);
This will generate the same data files as zipped in datasetLMO_SIFTflow_alpha=1.rar, under the folder home/datasets/datasetLMO/matching/alpha=1/. Of course, if you have downloaded the rar file, there is no need to run the above commands. It takes about a few hours to generate SIFT flow fields for the LMO database (K=20) on an 8-core machine.
There are four options for the parameter KNNmethod, including
| 'gistL2' |
% L2 norm on GIST features |
| 'gistCorr' |
% correlation on GIST features |
| 'hog' |
% L2 norm on HOG features |
| 'all' |
% the union of all above |
When KNNmethod = 'all', the union of the nearest neighbors of all the three methods is computed and stored. Morever, it is ok to specify a big number of K in batch SIFT flow. In the later label transfer stage, the nearest neighbors will be recaculated using specified method. It is fine as long as the nearest neighbors in label transfer (objectRecognition) is a subset of the nearest neighbors in batchSIFTflow.
The SIFT flow files are saved under folder alpha=*, so if the code is run multiple times with the same alpha but different K, then the output of the later run will overwrite the output of the former run. That is why we provided the zipped SIFT flow fields for LMO database for different alpha's.
In the following we genrete the SIFT flow fields with a different spatial regularization alpha=0.7. We also increase the number of nearest neighbors to 85.
batchSIFTflow(database,'K',85,'KNNmethod','gistL2','alpha',0.7);
This will generate the same data files as zipped in datasetLMO_SIFTflow_alpha=0.7.rar, under the folder home/datasets/datasetLMO/matching/alpha=1/. The running time of the above command can be 10 hours on an 8-core machine.
Now we move to the SUN database:
database = 'datasetSUN';
batchSIFTflow(database,'K',20,'KNNmethod','hog','alpha',0.7);
This will generate the same data files as zipped in datasetSUN_SIFTflow_alpha=0.7.rar, under the folder home/datasets/datasetSUN/matching/alpha=0.7/. The running time of the above commands can be around a day on an 8-core machine.
Once SIFT flow fields are computed, it is straightforward to use label transfer for image parsing. Run
database = 'datasetLMO';
recogRate = objectRecognition(database,'KNNmethod','gistL2','nNeighbors',85,...
'nCandidates',9,'prior_weight',0.06,'spatial_weight',20,'alpha',0.7);
and you will get recognition rate 76.59% as reported in the paper. Feel free to play with the parameters. Here nNeighbors corresponds to K in batch SIFT flow. Parameter prior_weight corresponds to α and spatial_weight corresponds to β in the paper. alpha is the spatial regularization in SIFT flow.
database = 'datasetSUN';
recogRate = objectRecognition(database,'KNNmethod','hog','nNeighbors',20,...
'nCandidates',9,'prior_weight',0.06,'spatial_weight',20,'alpha',0.7);
and you will get recognition rate 44.58% (not as good as reported in the paper because nNeighbors is very small). Notice that nNeighbors has to be equal or less than K in the batch SIFT flow. Matlab will report error if that is not case. For example, if you want to set nNeighbors=85 as in LMO database, then you have to set K=85 in batchSIFTflow for the SUN database. However, this will take a lot of space (>10GB) and time.