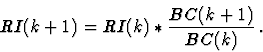
In 1985 Newborn discovered that the self-play results of BELLE correlated closely with the rates of new best moves as chosen by it during searches to fixed depths of 11 plies on a set of 447 test positions from real games. Moreover, the behaviour of TECH III [199] during searches to fixed depths of 11 plies for the 300 well-known ``Win At Chess'' test positions resembled the behaviour of BELLE during its equally deep searches. Based on these two observations Newborn [163] formulated an interesting hypothesis concerning the playing strength of chess programs in general. His hypothesis relates the increases in playing strength for deeper searches to the rates of new best moves as chosen at consecutive search depths (deeper versus shallower). Specifically, let BC(k) denote the rate or number of new best moves as observed in iteration #k and let RI(k) denote the actual increase in playing strength for searches of depth k in comparison with searches of depth k-1.
The hypothesis intuitively relies on the straightforward yet very important assumption that the new best moves as determined by deeper searches are of higher quality than the existing best moves which they displace. If this fundamental rationale is not fulfilled, the hypothesis does not make much sense at all. Please imagine a chess program that simply switches back and forth between a few good moves all the time. Such behaviour does surely not increase the playing strength of the program at any search depth. Therefore, the discovery of ``fresh ideas'' (e.g. new best moves which the program never deemed best before) looks like a much better and more meaningful indicator of increases in playing strength than just the change of the preferred choices. Surprisingly enough, nobody seems to have investigated this aspect of Newborn's hypothesis prior to us. In Section 1.5.6 we present empirical evidence that supports the validity of the hypothesis in this respect. According to the experimental results of both CRAFTY and DARKTHOUGHT sizable 30%-50% of all new best moves as chosen by modern chess programs represent ``fresh ideas'' on average.
Newborn's hypothesis neatly fitted the results of the self-play experiments and the behavioural experiments to fixed search depths of 11 plies as available for BELLE in 1985. To the best of our knowledge, however, no researcher ever tested the validity of the hypothesis for higher search depths than 11 plies nor for other chess programs than BELLE. Nevertheless, in 1997 Hyatt and Newborn [114] applied the above formula of expected rating increase for an additional ply of search to their experimental results of CRAFTY in order to calculate ``extrapolated'' ratings of the program at search depths of 6-14 plies. They seeded their calculations with the according ratings of BELLE from 1985 as given values for the 4-ply and 5-ply searches. Hyatt and Newborn obviously interpreted the similar search behaviours of BELLE and CRAFTY on different sets of test positions as sufficient reason to assume the validity of Newborn's hypothesis for CRAFTY as well.
We object to Hyatt and Newborn's ``extrapolation'' because in our opinion neither the application of the hypothesis itself nor the repeatedly recursive style of its application were appropriate in this case. First and foremost, there exist no published results of self-play experiments for CRAFTY at any fixed search depths such that not even a single value of RI(k) could be determined in compliance with the prescriptions of the hypothesis. Instead, Hyatt and Newborn rather calculated them too by repeatedly applying the recursive formula of expected rating increase to each additional ply of search. This essentially means that Hyatt and Newborn employed the hypothesis in order to derive assumedly independent preconditions of itself. These fabricated preconditions then served as the basis for the next true application of the hypothesis yielding the calculation of an absolute rating and so forth. Thence, the ratings of CRAFTY as postulated by Hyatt and Newborn in Figure 7 of their article (e.g. 2601 points at a fixed search depth of 11 plies and 2983 points at a fixed search depth of 14 plies) lack real substance.