
This PyTorch code implements the methods that are presented in:
Kenji Kawaguchi* and Haihao Lu*. Ordered SGD: A New Stochastic Optimization Framework for Empirical Risk Minimization.
In Proceedings of the 23rd International Conference on Artificial Intelligence and Statistics (AISTATS), 2020.
The proposed algorithm, Ordered SGD, is fast (computationally efficient), is easy to be implemented, and comes with theoretical gurantees in both optimization and generalization. Implementing Ordered SGD only requires modifications of one line or few lines in any code that uses SGD. The Ordered SGD algorithm accelerates training and improves test accuracy by focusing on the important data samples. The following figure illustrates the advantage of Ordered SGD in that Ordered SGD learns a different type of models than those learned by the standard SGD, which is sometimes beneficial.
As a result of the above mechanism (and other theoretical facts), Ordered SGD is fast and can improve test errors as shown in the following figure and tables:
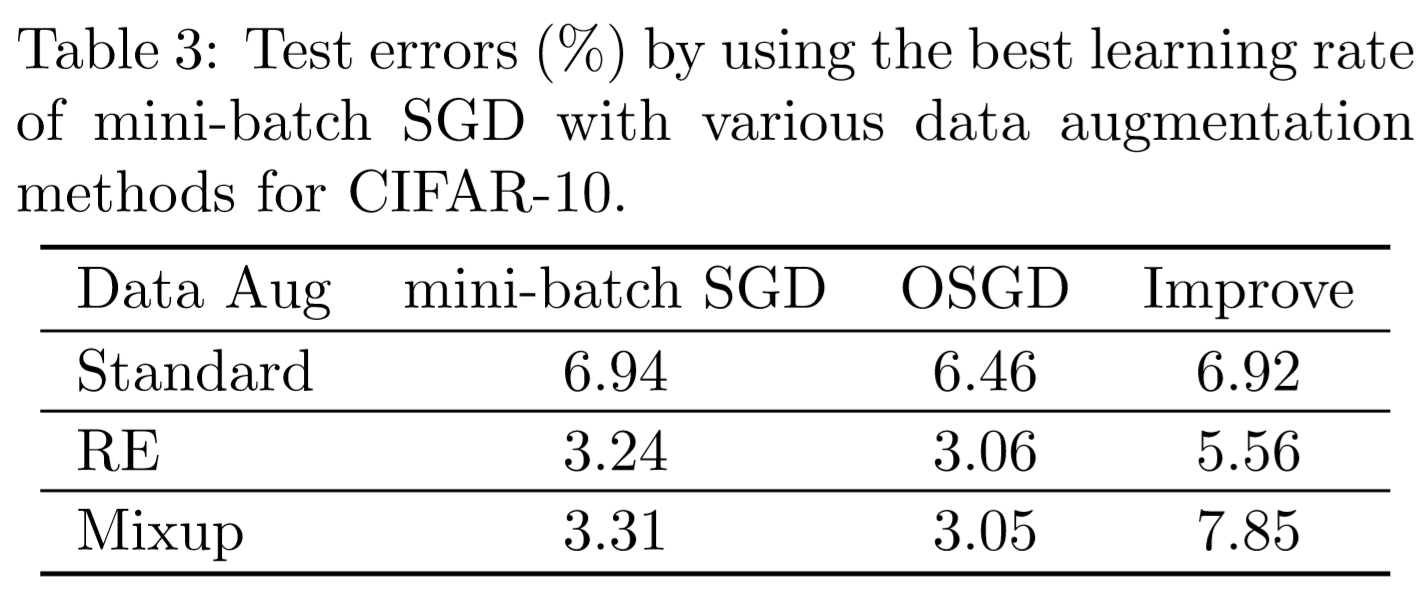


If you find this useful in your research, please consider citing:
@InProceedings{pmlr-v108-kawaguchi20a,
title = {Ordered SGD: A New Stochastic Optimization Framework for Empirical Risk Minimization},
author = {Kawaguchi, Kenji and Lu, Haihao},
booktitle = {Proceedings of the Twenty Third International Conference on Artificial Intelligence and Statistics},
pages = {669--679},
year = {2020},
editor = {Chiappa, Silvia and Calandra, Roberto},
volume = {108},
series = {Proceedings of Machine Learning Research},
month = {26--28 Aug},
publisher = {PMLR}
}In this paper, we propose a new stochastic first-order method for empirical risk minimization problems such as those that arise in machine learning. The traditional approaches, such as (mini-batch) stochastic gradient descent (SGD), utilize an unbiased gradient estimator of the empirical average loss. In contrast, we develop a computationally efficient method to construct a gradient estimator that is purposely biased toward those observations with higher current losses, and that itself is an unbiased gradient estimator of an ordered modification of the empirical average loss. On the theory side, we show that the proposed algorithm is guaranteed to converge at a sublinear rate to a global optimum for convex loss and to a critical point for non-convex loss. Furthermore, we prove a new generalization bound for the proposed algorithm. On the empirical side, we present extensive numerical experiments, in which our proposed method consistently improves the test errors compared with the standard mini-batch SGD in various models including SVM, logistic regression, and (non-convex) deep learning problems.
Implementing Ordered SGD only requires modifications of one line or few lines in any code that uses SGD. For example, in pytorch, suppose that you have the following lines:
loss = F.cross_entropy(model_output, y)
loss.backward()
optimizer.step() where 'optimizer' is the SGD optimizer. Then, you can implement Ordered SGD by simply re-writing these lines to the following lines:
loss = F.cross_entropy(model_output, y, reduction='none')
loss = torch.mean(torch.topk(loss, min(q, s), sorted=False, dim=0)[0])
loss.backward()
optimizer.step() where s is the mini-batch size (e.g., s = 64) and q is the hyper-parameter of Ordered SGD (e.g., q = 32).
To avoid hyper-parameter search for the value of q, we used the following rule to automatically adjust q across all the experiments: q = s at the beginning of training, q = int(s/2) once train_acc >= 80%, q = int(s/4) once train_acc >= 90%, q = int(s/8) once train_acc >= 95%, and q = int(s/16) once train_acc >= 99:5%, where train_acc represents training accuracy.
if train_acc >= 99.5 and q > int(s/16):
q = int(s/16)
elif train_acc >= 95 and q > int(s/8):
q = int(s/8)
elif train_acc >= 90 and q > int(s/4):
q = int(s/4)
elif train_acc >= 80 and q > int(s/2):
q = int(s/2) LeNet on MNIST via SGD without data augmentation:
python main.py --dataset=mnist --data-aug=0 --model=LeNet --method=0LeNet on MNIST via Ordered SGD without data augmentation:
python main.py --dataset=mnist --data-aug=0 --model=LeNet --method=1LeNet on KMNIST via Ordered SGD with data augmentation:
python main.py --dataset=kmnist --data-aug=1 --model=LeNet --method=1LeNet on Fashion MNIST via Ordered SGD with data augmentation:
python main.py --dataset=fashionmnist --data-aug=1 --model=LeNet --method=1PreActResNet18 on CIFAR-10 via SGD without data augmentation:
python main.py --dataset=cifar10 --data-aug=0 --model=PreActResNet18 --method=0PreActResNet18 on CIFAR-10 via Ordered SGD without data augmentation:
python main.py --dataset=cifar10 --data-aug=0 --model=PreActResNet18 --method=1PreActResNet18 on CIFAR-10 via SGD with data augmentation:
python main.py --dataset=cifar10 --data-aug=1 --model=PreActResNet18 --method=0PreActResNet18 on CIFAR-10 via Ordered SGD with data augmentation:
python main.py --dataset=cifar10 --data-aug=1 --model=PreActResNet18 --method=1LeNet on MNIST without data augmentation:
python plot.py --dataset=mnist --data-aug=0 --model=LeNetLeNet on MNIST with data augmentation:
python plot.py --dataset=mnist --data-aug=1 --model=LeNetLeNet on KMNIST with data augmentation:
python plot.py --dataset=kmnist --data-aug=1 --model=LeNetLeNet on Fashion MNIST with data augmentation:
python plot.py --dataset=fashionmnist --data-aug=1 --model=LeNetPreActResNet18 on CIFAR-10 with data augmentation:
python plot.py --dataset=cifar10 --data-aug=1 --model=PreActResNet18for SGD:
python cifar.py --dataset cifar10 --p 0.5 --arch wrn --depth 28 --widen-factor 10 --schedule 100 200 --method=0 for Ordered SGD:
python cifar.py --dataset cifar10 --p 0.5 --arch wrn --depth 28 --widen-factor 10 --schedule 100 200 --method=1 Disclaimer: the code for WideResNet28_10 with CIFAR-10 is based on the code from random erasing repo: (https://github.com/zhunzhong07/Random-Erasing)
Python 3.6.7
torch 1.0.1