|
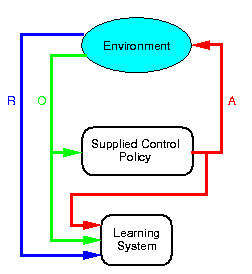
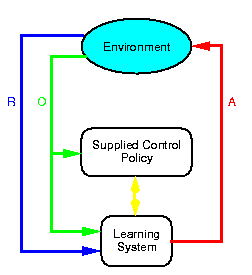
The goal is to make it easier for humans to program robots by using reinforcement learning and supplying a very high-level task description (in the form of a reward function) instead of explicit control instructions. Instead of learning from scratch, we show the robot "interesting" parts of the space by either driving it around with a joystick or providing it with an example solution. Neither of these need actually perform the task that we want to robot to learn. All that they have to do is to allow the learning system to observe interactions with the environment and the rewards that this interaction generates.
In implementing such a system, we must solve two main sets of problems; how to deal with large, continuous state and action spaces in reinforcement learning, and how to bootstrap useful information into the learning system.
We use a locally weighted regression based learning algorithm which makes conservative predictions of the Q-value function, in order to minimize common problems incurred when performing value function approximation. The basic idea behind the algorithm is to only interpolate from previously seen training data, and never to extrapolate from it. This tends to reduce the overestimation of the Q-values, which has been shown to be a leading cause of failure in value function approximation. We achieve this by using a technique from statistics known as the Independent Variable Hull.
When asked to make a prediction, we collect a set of points "close" to the query point, and construct an approximate elliptic hull around them. If the query point falls within this hull, we perform the prediction as normal. If not, then we refuse to make a prediction (since we have no support from the training data), and return a default Q-value. Details of the algorithm are available in a recent paper.
Humans have insight into how to perform many tasks that robots are called on to do. How can we take this (often implicit) knowledge and incorporate it into a reinforcement learning framework?
In this work, we have used the idea of a supplied initial policy. This policy can be either computer code, or a human directing the robot with a joystick. This policy is used to generate "interesting" trajectories though the state-action space, showing the robot areas of high and low reward. These trajectories (and their associated rewards) are then used in a first, passive phase of learning. The reinforcement learning component observes the states, actions, next states and rewards being generated and bootstraps this information into its value function representation. It does not, however, have any control over the robot. This allows the system to safely and efficiently bootstrap information into the value function representation.
After a suitable amount of information has been acquired in this way, learning switches to a second phase, where the reinforcement learning system is in direct control of the robot. By this time, however, the value function approximation is good enough to allow more informed exploration of the environment.
|
|
A key point of this approach is that we are not learning the initial policy. We are simply using it to generate experiences of the world. In fact, we have found that poor initial policies are often better, because they expose more of the interesting (from a reward function perspective) parts of the state space. Initial policies which are good, and head directly for the goal state, typically do not expose much of the state space, since their trajectories through it are much more directed.
|
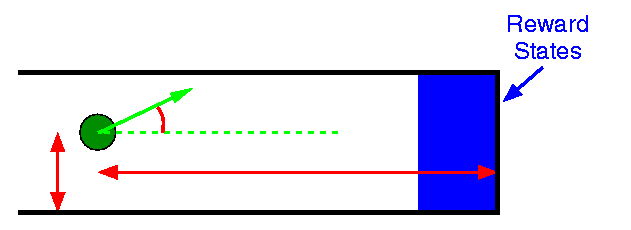
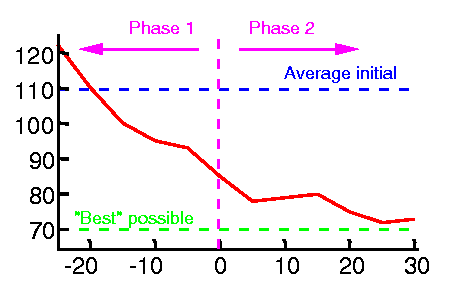
The preliminary results are shown in the graph below. Our performance metric is number of steps until we reach the goal region. The average performance of the supplied initial policy is 100 steps to goal. The "optimal" performance of 70 steps was found by driving the robot down the corridor with a joystick, trying to make the traversal as fast as possible. Learning was suspended every 5 runs and the current learned policy was evaluated.
In the initial learning phase, when the supplied control policy is in control of the robot, the learned policy quickly learns to do better (on average) than the supplied policy. This underlines the fact that we are not learning the supplied policy, merely using it to generate experience for us. In phase two, when the learned policy is in control, the improvement with time is not quite as dramatic, but the system continues to improve its performance. At the end of the experiment, after 25 phase one runs and 30 phase two runs, the performance is not significantly different from the "optimal" policy (at a 95% confidence level).
|
One final point to note is that the entire experiment took about two hours to complete. This time includes the time spent developing the initial supplied policy, doing the learning runs, and performing the evaluations. We believe that this is competitive with the time that it would have taken to fine-tune the initial policy to a similar performance level.