Différents arbres possiblesRemarques sur le code
Analyse des résultats
Comparaison avec le codage de Huffmann
On souhaite résoudre de manière automatique le problème des pièces. On possède pour cela :
On cherche une stratégie permettant en pesant des groupes de pièce :
On calcule l'entropie par la formule suivante : H = - p1 log3 p1 - p2 log3 p2 - ... où pi est la probabilté d'être dans le cas i et log3 le logarithme en base 3 (on choisit 3 car chaque pesée à 3 issues : déséquilibre à gauche ou à droite et équilibre). A chaque étape, on calcule l'entropie conditionnelle de chaque pesée (i.e. l'espérance de l'entropie après la pesée). Puis on choisit celle qui aboutit à l'entropie la plus faible. Et pour itérer, on envisage les trois résultats de la pesée et dans chaque cas, on cherche à nouveau la pesée qui minimise l'entropie conditionnelle... On arrête de contruire l'arbe quand on aboutit à une situation d'entropie nulle. Il est à noter que par moment, on rencontre des résultats impossibles, i.e. incohérent avec les résultats précédents; dans le déroulement de l'algorithme, ces issues apparaissent comme ayant une probabilité nulle de se produire et donc elles sont simplement mis à l'écart.
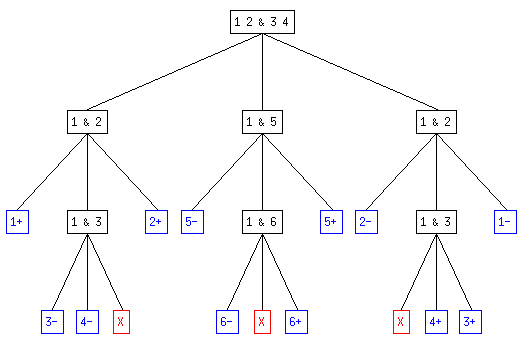
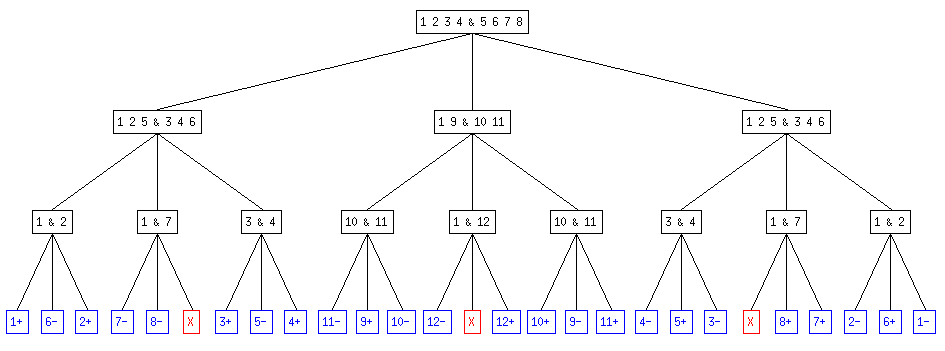
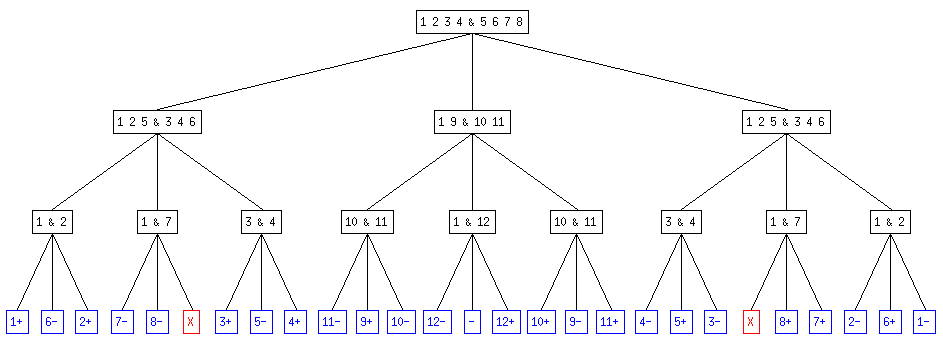
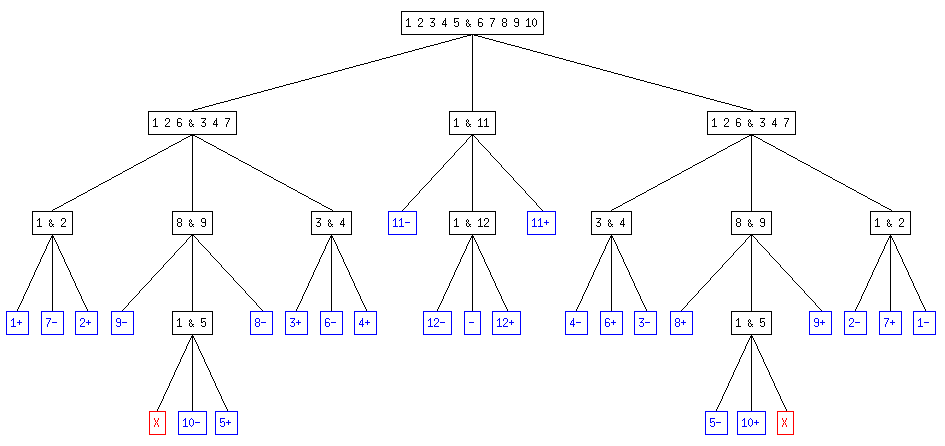
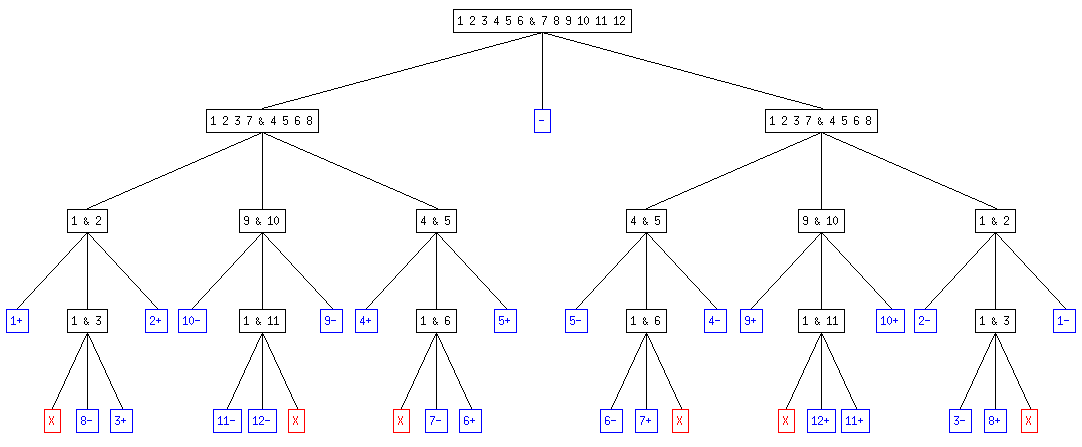
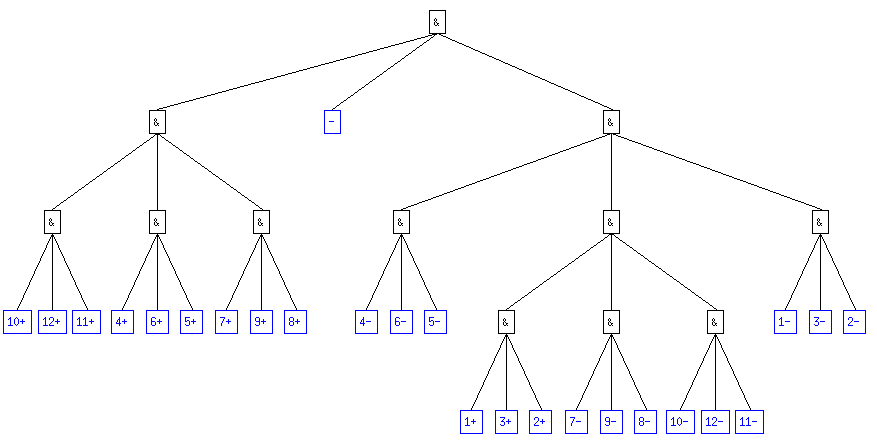
On obtient ainsi un arbre ternaire qui représente la succession des pesées dans chacun des cas. Le fils de gauche correspond à l'hypothèse "la balance penche à gauche", celui du milieu à "la balance ne penche pas" et celui de droite à "la balance penche à droite".
Par exemple, l'arbre pour 6 pièces avec certitude d'en avior une fausse (en bleu, les résultats finaux avec "n-" la pièce n est légère , "n+" la pièce n est lourde, "-" aucune pièce n'est fausse; en rouge, les résultats impossibles) :
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
A priori, on peut considérer ce code comme étant acceptable dans le sens où il vérifie bien la relation H <= L < H + 1 où L est la longueur moyenne d'un mot. On voit même que l'on est assez proche du cas d'égalité.
Néanmoins, le cas p0 = 0.1 bien que vérifiant la relation ci-dessus n'appraît pas aussi bon que l'on pourrait le souhaiter. En effet, on a L = 3.075 et on sait que dans le cas p0 = 0.04 par exemple on a une longueur maximale de 3. Quelles que soient les probabilités, on est donc sûr de pouvoir coder tous les cas avec L <= 3 ; simplement en utilisant l'arbre p0 = 0.04 . Dans ce cas, on est sûr de ne pas avoir atteint la longueur minimale du code.
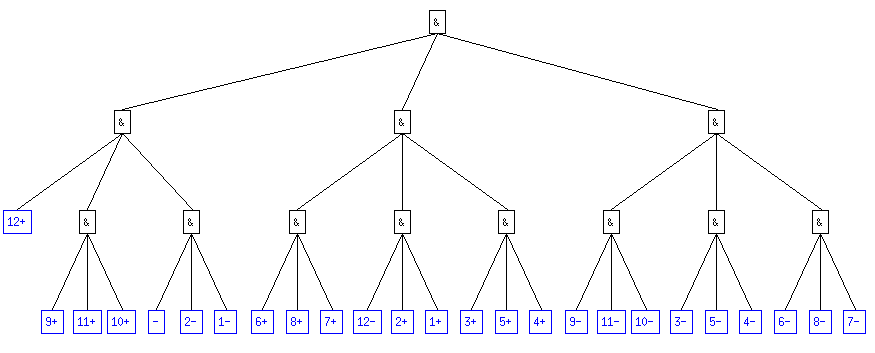
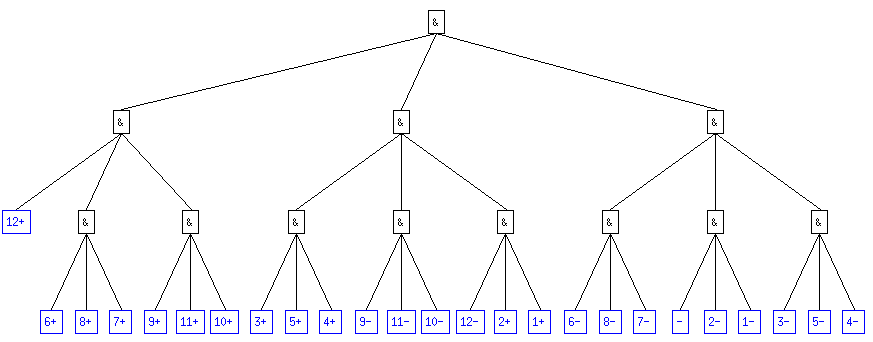
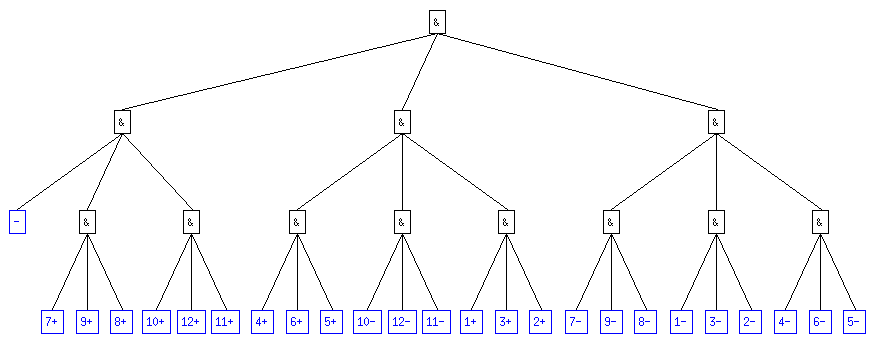
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
On voit alors que le codage réalise systématiquement mieux que la méthode par réduction d'entropie. Et notamment, on ne dépasse jamais la valeur de 3 pour la longueur moyenne.
Une des raisons qui explique cette différence de "performances" est l'existence de résultats d'impossibilité dans la méthode par réduction d'entropie. En effet ces résultats doivent être représentés dans l'arbre et occupent alors "de la place" inutilement et empêche d'atteindre l'optimum. Cela n'explique pas toutefois que la réduction d'entropie dépasse parfois la valeur 3 pour la longueur moyenne du code induit.
Generator procède en deux étapes. Premièrement, il génère tous les ensembles de cardinal au plus n/2 pièces. Deuxièmement, il calcule toutes les intersections deux à deux des ensembles de même cardinal. Quand l'intersection est vide, il "crée" une pesée car la comparaison est possible entre les deux ensembles.
Entropy contient toutes les routines de calcul de l'entropie. Les probabilités conditionnelles sont calculées directement au cas par cas : par exemple, on sait que pour une pièce qui se trouve dans le plateau le plus lourd ne peut pas être trop légère.
Tree construit l'arbre simplement par un procédé récursif selon la méthode décrite ci-dessus. Ce module contient une implémentation pour construire l'arbre de Huffmann dans les mêmes structures que l'arbre des pesées -- cette implémentation n'est pas optimale et a simplement un objectif de comparaison.
On utilise alors deux exécutables : coins et huffmann dont la syntaxe est coins #pièces p0 et huffmann #pièces p0. A chaque exécutable correspond un makefile.
Sylvain Paris (s.paris@netcourrier.com)