
BlueDBM : An Appliance for Big Data Analytics
1. Overview
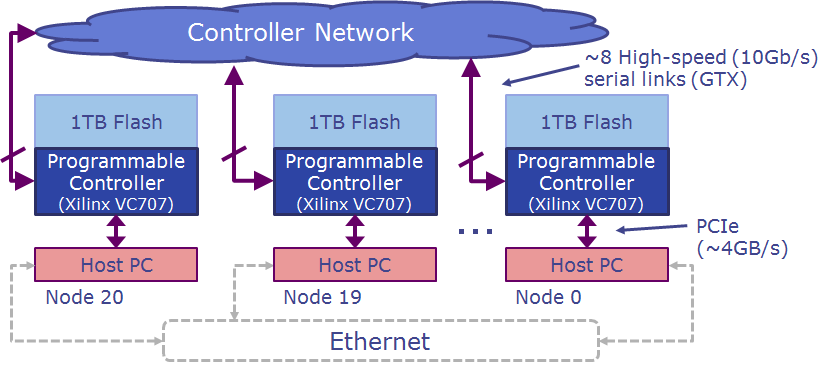
BlueDBM is a system architecture to accelerate Big Data analytics. BlueDBM has a large distributed flash-based storage with in-store processing capability and a low-latency high-throughput inter-controller networks. In our 20-node BlueDBM prototype, each in-storage hardware accelerator can access a total of 20 TB of distributed flash storage at a uniform latency of less than 50 us, which is lower than distributed DRAM access over Ethernet.
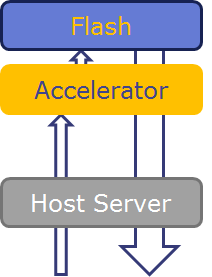
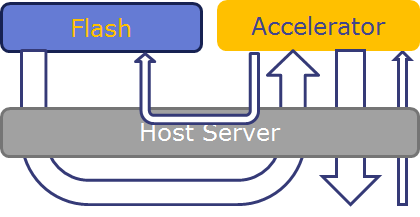
When processing massive amounts of data, performance if often bound by the capacity of fast local DRAM. In cluster systems with more RAM, the network and storage software stacks often becomes bottlenecks. BlueDBM proposes to mitigate these issues by providing an extremely fast access to a scalable network of flash-based storage devices, and to provide a platform for application-specific hardware accelerators on the datapath on each of the storage devices. The diagram below shows shows the difference between in-datapath and off-datapath architectures. BlueDBM provides both architectures by wrapping the storage device under a consistent abstraction.
 |
 |
Each BlueDBM node consists of flash storage coupled with an FPGA, and is plugged into a host system's PCIe port. Each node is directly connected to up to 8 other BlueDBM nodes over a high-speed serial link capable of 10 gigabit bandwidth at 0.5us latency. More BlueDBM storage devices can be networked in a mesh network topology. By default, the FPGA implementes platform functions such as flash, network and on-board DRAM management, and exposes a high-level abstraction.
On top of this, developers can develop specific accelerators such as network protocols, distributed file systems or other application-specific accelerators to take advantage of the acceleration and high-speed network. We are exploring many applications including MapReduce, memcached and SQL databases.
2. Prototype Description
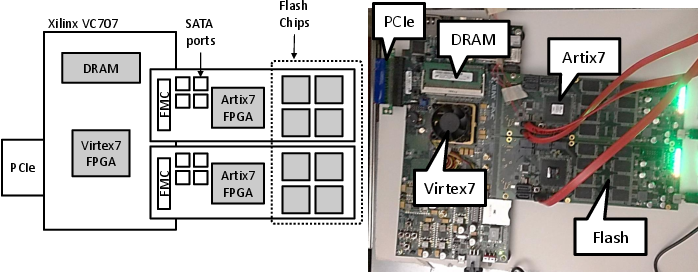
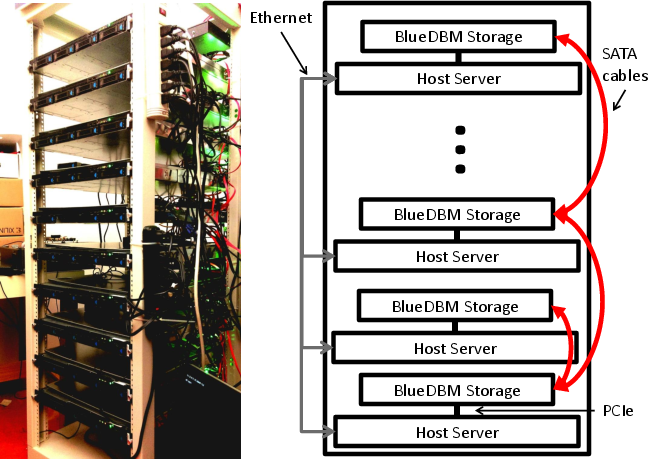
We have built a middle-scale cluster of 20 BlueDBM nodes organized into two racks. This system includes 20 Xeon-based servers, 20 Xilinx VC707 boards, and 40 custom-built flash boards each with one Xilinx Artix 7 FPGA chips and 512GB of flash storage. The total flash capacity of the cluster adds up to 20TBs.
Photos below show our implementation of the BlueDBM storage node, and a 10-node BlueDBM rack.
 |
 |
| Connection to host | Currently: PCIe gen 1 at 2GB/s Planned: PCIe gen 2 at 4GB/s |
| Inter-node link | 8x 10GB/s serial links 0.5us single hop latency |
| Flash daughtercard | 2x custom cards with total 1TB 1.2GB/s per daughtercard |
| Flash controller | 1 Artix 7 FPGA per daughtercard, including ECC |
| Link to daughtercard | 2.2GB/s serial communication per daughtercard |
3. Applications
We are working on multiple applications that will benefit from this architecture.Content-based Image Retrieval
Color histogram and edge detection based image querying implemented using distributed flash storage and FPGA-base in-store computing.
Flash-Based Key-Value Store with Hardware Acceleration
Our flash-based memcached replacement, Bluecache, uses hardware acceleration for lower-latency network interface and faster key-value management to overcome the performance disadvantage of flash storage. As a result, Bluecache can provide much larger capacity at much lower capital and operating cost, without losing performance.
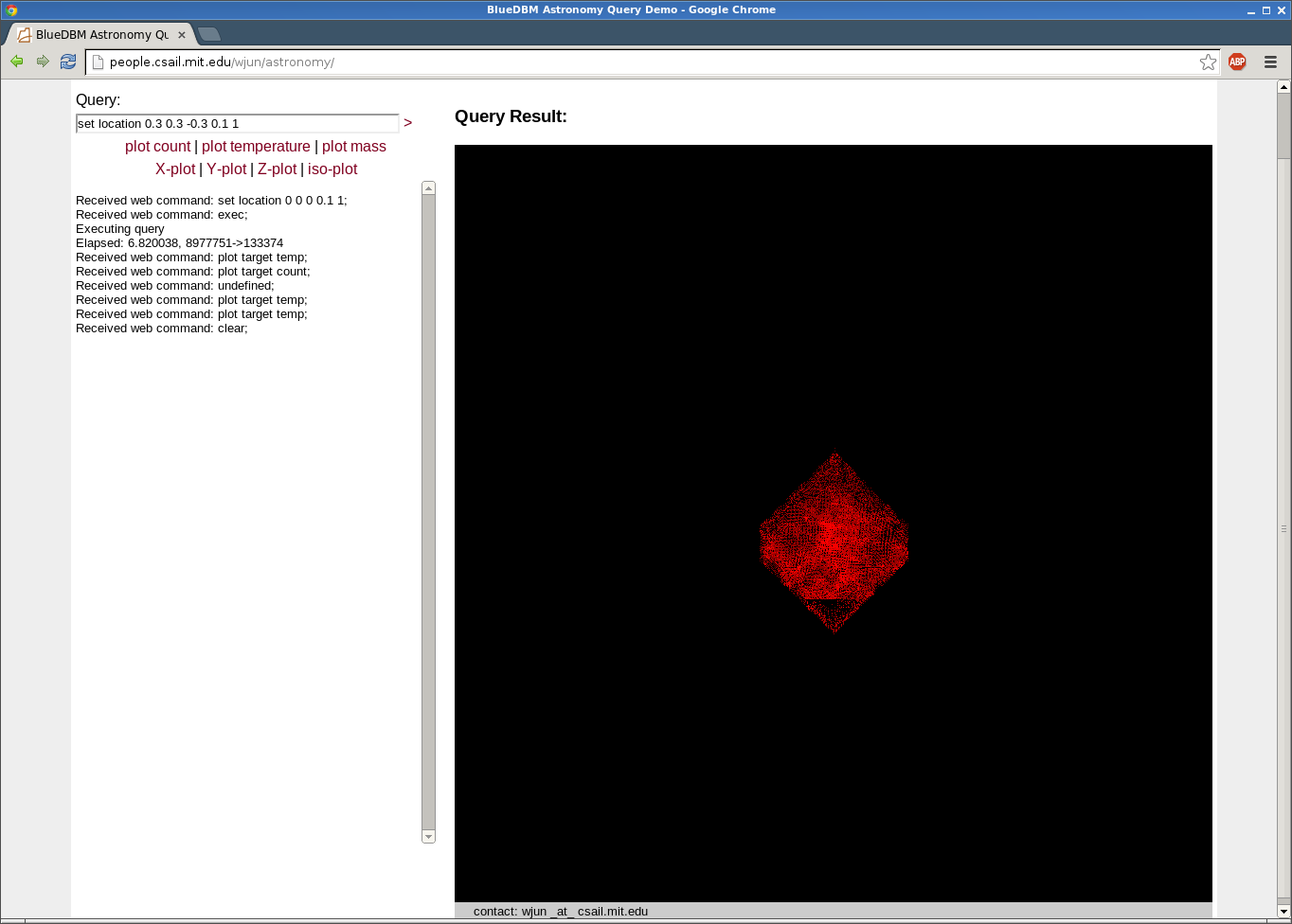
Scientific data analysis by accelerating SQL queries:
We have implemented a simple relational database acceleration module in hardware, and aiming to integrate into a DBMS. We are trying to do things like generate heat maps of a subset of a large simulated universe in real-time. The image below is an example:
Hardware-accelerated external graph analyrics
I am developing a hardware-accelerated fully external graph analytics platform that can handle multi-terabyte graphs on a wimpy PC, using flash storage and hardware accelerators. It uses a novel algorithm called Sort-Reduce to efficiently sequentialize vertex value updates into flash storage.
And Many More!
Bioinformatics, Computer vision, workload balancing with hardware accelerators...