Zeyuan ALLEN-ZHU 
Publications
Last Update: April 09, 2024.
Last Update: April 09, 2024.

Our 12 scaling laws (for LLM knowledge capacity) are out: https://t.co/qNTarfEb3l. Took me 4mos to submit 50,000 jobs; took Meta 1mo for legal review; FAIR sponsored 4,200,000 GPU hrs. Hope this is a new direction to study scaling laws + help practitioners make informed decisions pic.twitter.com/gF2O3LivEW
— Zeyuan Allen-Zhu (@ZeyuanAllenZhu) April 9, 2024
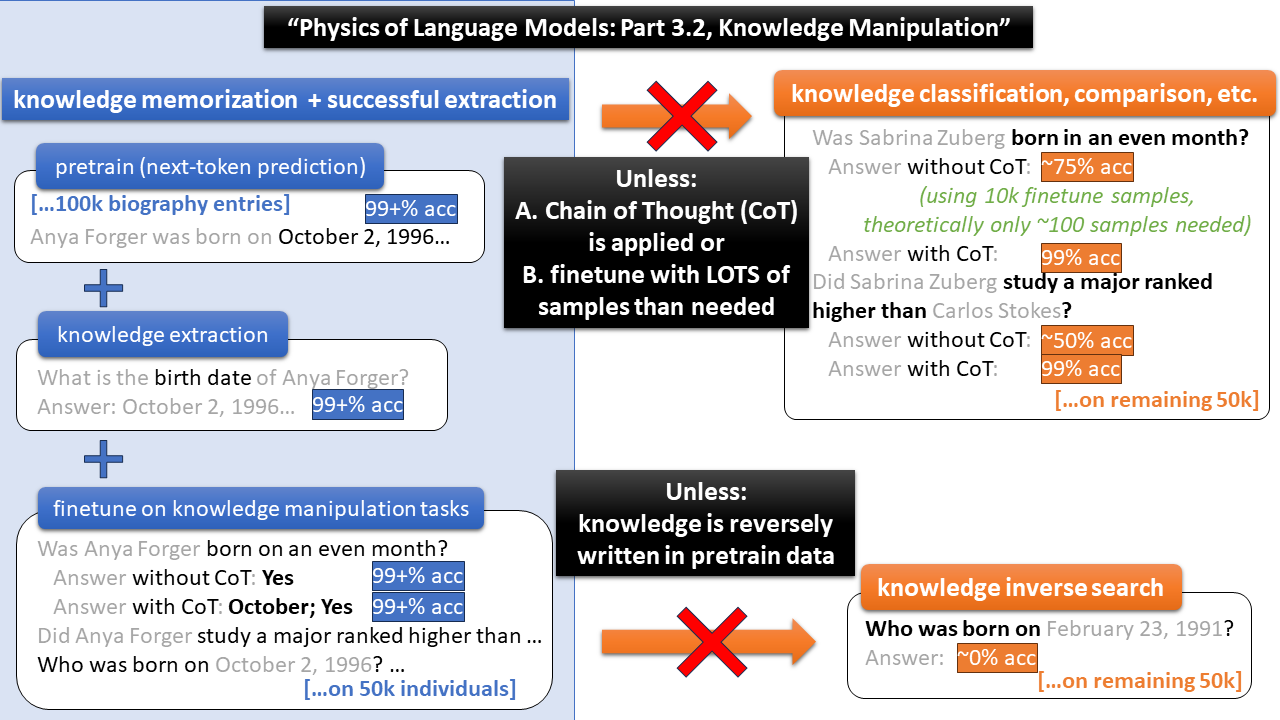
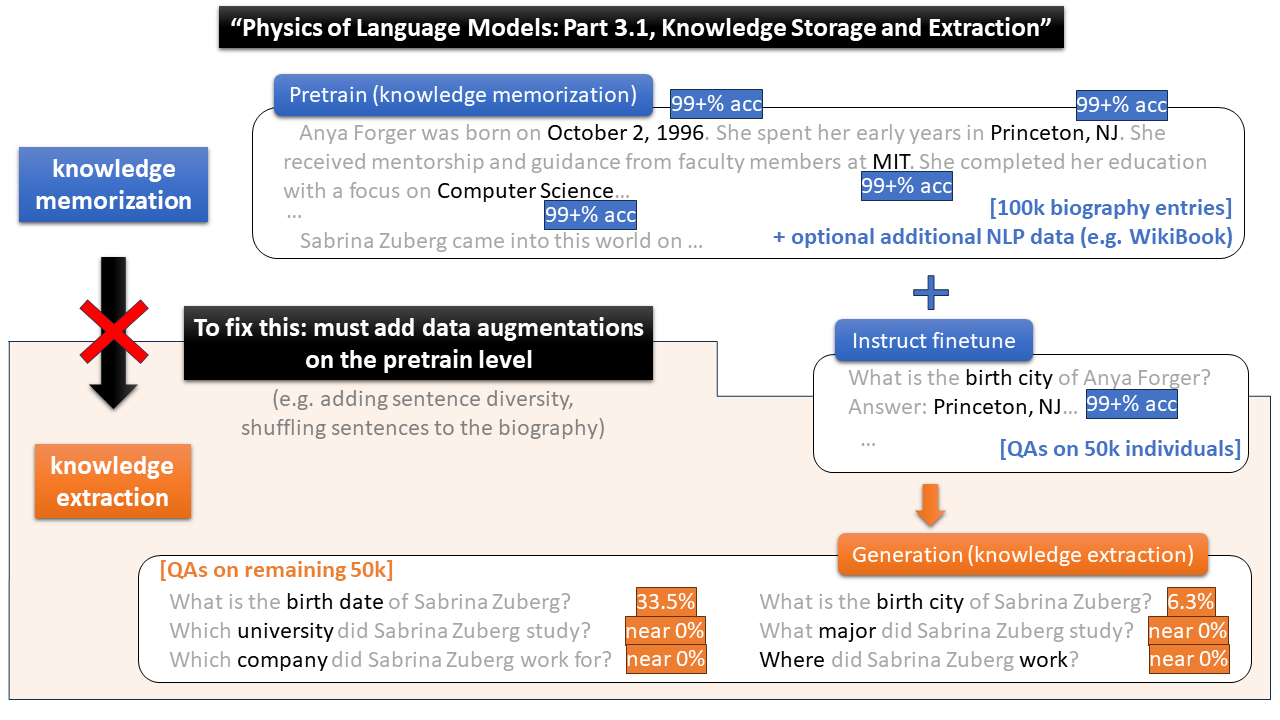
My current research focuses on investigating the physics of language models and AI in a broader sense. This involves designing experiments to elucidate the underlying fundamental principles governing how transformers/GPTs learn to accomplish diverse AI tasks. By probing into the neurons of the pre-trained transformers, my goal is to uncover and comprehend the intricate (and sometimes surprising!) physical mechanisms behind large language models. Our first paper in this series can be found on arxiv.
Before that, I work on the mathematics of deep learning. That involves developing rigorous theoretical proofs towards the learnability of neural networks, in ideal and theory-friendly settings, to explain certain mysterious phenomena observed in deep learning. In this area, our paper on ensemble / knowledge distillation received some award from ICLR'23; although I am most proud of our COLT'23 result that provably shows why deep learning is actually deep –– better than shallow learners such as layer-wise training, kernel methods, etc.
In my past life, I have also worked in machine learning, optimization theory, and theoretical computer science.
I would love to thank my wonderful collaborators without whom these results below would never have been accomplished. In inverse chronological order:
Olga Golovneva (1), Jason Weston (1), Sainbayar Sukhbaatar (1), Cathy Li (1), Emily Wenger (1), Francois Charton (1), Kristin Lauter (1), Edward J. Hu (1), Yelong Shen (1), Phillip Wallis (1), Shean Wang (1), Faeze Ebrahimian (1), Yingyu Liang(1), Zhao Song(2), Michael Jordan (1), Chi Jin (1), David Simchi-Levi (1), Xinshang Wang (1), Dan Alistarh (2), Jerry Li (2), Sébastien Bubeck (2), Ankit Garg (1), Wei Hu (1), Avi Wigderson (2), Rafael Oliveira (2), Yining Wang (2), Aarti Singh (2), Naman Agarwal (1), Brian Bullins (1), Tengyu Ma (1), Yuanzhi Li (26), Elad Hazan (4), Karthik Sridharan (1), Yang Yuan (4), Peter Richtárik (1), Zheng Qu (1), Zhenyu Liao (2), Yin Tat Lee (1), Lorenzo Orecchia (8), Aditya Bhaskara (1), Ilya Razenshteyn (1), Rati Gelashvili (2), Nir Shavit (1), Aaron Sidford (1), Silvio Lattanzi (2), Vahab Mirrokni (2), Jonathan Kelner (2), Sasa Misailovic (1), Martin Rinard (1), Alessandro Chiesa (4), Silvio Micali (5), Wei Chen (1), Pinyan Lu (2), Xiaorui Sun (2), Bo Tang (1), Yajun Wang (2), Zheng Chen (5), Tom Minka (1), Haixun Wang (1), Dong Wang (1), Chenguang Zhu (5), Gang Wang (4), Weizhu Chen (6).


|
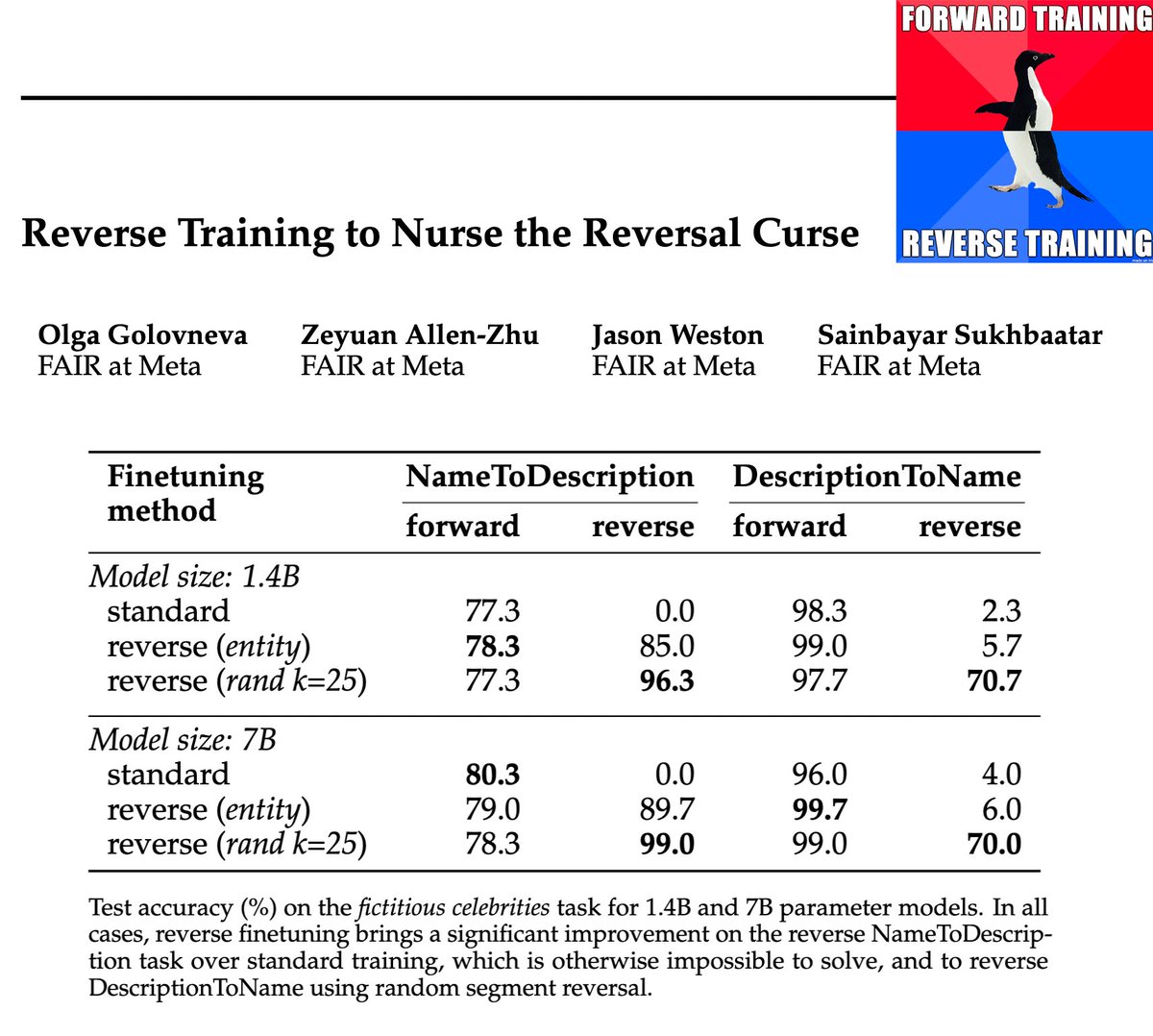
Large language models (LLMs) have a surprising failure: when trained on "A has a feature B", they do not generalize to "B is a feature of A", which is termed the Reversal Curse. Even when training with trillions of tokens this issue still appears due to Zipf's law - hence even if we train on the entire internet. This work proposes an alternative training scheme, called reverse training, whereby all words are used twice, doubling the amount of available tokens. The LLM is trained in both forward and reverse directions by reversing the training strings while preserving (i.e., not reversing) chosen substrings, such as entities. We show that data-matched reverse-trained models provide superior performance to standard models on standard tasks, and compute-matched reverse-trained models provide far superior performance on reversal tasks, helping resolve the reversal curse issue. |
|
|
We design experiments to study how generative language models, like GPT, learn context-free grammars (CFGs) --- diverse language systems with a tree-like structure capturing many aspects of natural languages, programs, and human logics. CFGs are as hard as pushdown automata, and can be ambiguous so that verifying if a string satisfies the rules requires dynamic programming. We construct synthetic data and demonstrate that even for very challenging CFGs, pre-trained transformers can learn to generate sentences with near-perfect accuracy and remarkable diversity. More importantly, we delve into the >physical principles behind how transformers learns CFGs. We discover that the hidden states within the transformer implicitly and precisely encode the CFG structure (such as putting tree node information exactly on the subtree boundary), and learn to form ``boundary to boundary'' attentions that resemble dynamic programming. We also cover some extension of CFGs as well as the robustness aspect of transformers against grammar mistakes. Overall, our research provides a comprehensive and empirical understanding of how transformers learn CFGs, and reveals the physical mechanisms utilized by transformers to capture the structure and rules of languages. |
Learning with Errors (LWE) is a hard math problem used in post-quantum cryptography. Homomorphic Encryption (HE) schemes rely on the hardness of the LWE problem for their security, and two LWE-based cryptosystems were recently standardized by NIST for digital signatures and key exchange (KEM). Thus, it is critical to continue assessing the security of LWE and specific parameter choices. For example, HE uses small secrets, and the HE community has considered standardizing small sparse secrets to improve efficiency and functionality. However, prior work, SALSA and PICANTE, showed that ML attacks can recover sparse binary secrets. Building on these, we propose VERDE, an improved ML attack that can recover sparse binary, ternary, and small Gaussian secrets. Using improved preprocessing and secret recovery techniques, VERDE can attack LWE with larger dimensions (n=512) and smaller moduli (\(\log_2(q)=12\) for n=256), using less time and power. We propose novel architectures for scaling. Finally, we develop a theory that explains the success of ML LWE attacks. |
|

|
|
The dominant paradigm of natural language processing consists of large-scale pre-training on general domain data and adaptation to particular tasks or domains. As we pre-train larger models, conventional fine-tuning, which retrains all model parameters, becomes less feasible. Using GPT-3 175B as an example, deploying many independent instances of fine-tuned models, each with 175B parameters, is extremely expensive. We propose Low-Rank Adaptation, or LoRA, which freezes the pre-trained model weights and injects trainable rank decomposition matrices into each layer of the Transformer architecture, greatly reducing the number of trainable parameters for downstream tasks. For GPT-3, LoRA can reduce the number of trainable parameters by 10,000 times and the computation hardware requirement by 3 times compared to full fine-tuning. LoRA performs on-par or better than fine-tuning in model quality on both GPT-3 and GPT-2, despite having fewer trainable parameters, a higher training throughput, and no additional inference latency. We also provide an empirical investigation into rank-deficiency in language model adaptations, which sheds light on the efficacy of LoRA. |
|
We study adversary-resilient stochastic distributed optimization, in which m machines can independently compute stochastic gradients, and cooperate to jointly optimize over their local objective functions. However, an ��-fraction of the machines are Byzantine, in that they may behave in arbitrary, adversarial ways. We consider a variant of this procedure in the challenging non-convex case. Our main result is a new algorithm SafeguardSGD which can provably escape saddle points and find approximate local minima of the non-convex objective. The algorithm is based on a new concentration filtering technique, and its sample and time complexity bounds match the best known theoretical bounds in the stochastic, distributed setting when no Byzantine machines are present. Our algorithm is very practical: it improves upon the performance of all prior methods when training deep neural networks, it is relatively lightweight, and it is the first method to withstand two recently-proposed Byzantine attacks. |
The experimental design problem concerns the selection of k points from a potentially large design pool of p-dimensional vectors, so as to maximize the statistical efficiency regressed on the selected k design points. Statistical efficiency is measured by \emph{optimality criteria}, including A(verage), D(eterminant), T(race), E(igen), V(ariance) and G-optimality. Except for the T-optimality, exact optimization is NP-hard. We propose a polynomial-time regret minimization framework to achieve a \((1+\varepsilon)\) approximation with only \(O(p/\varepsilon^2)\) design points, for all the optimality criteria above. In contrast, to the best of our knowledge, before our work, no polynomial-time algorithm achieves \((1+\varepsilon)\) approximations for D/E/G-optimality, and the best poly-time algorithm achieving \((1+\varepsilon)\)-approximation for A/V-optimality requires \(k=\Omega(p^2/\varepsilon)\) design points. |
|
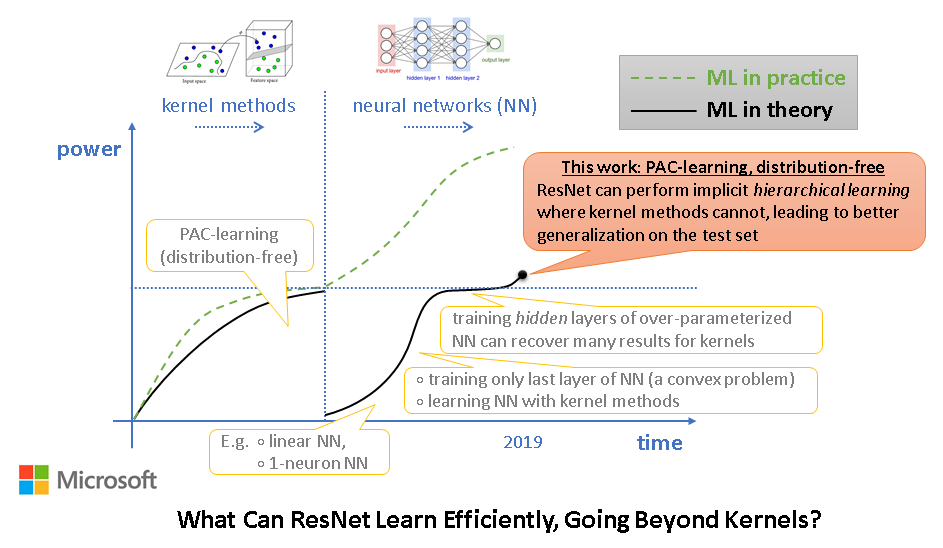
The fundamental learning theory behind neural networks remains largely open. What classes of functions can neural networks actually learn? Why doesn't the trained neural networks overfit when the it is overparameterized (namely, having more parameters than statistically needed to overfit training data)? In this work, we prove that overparameterized neural networks can learn some notable concept classes, including two and three-layer networks with fewer parameters and smooth activations. Moreover, the learning can be simply done by SGD (stochastic gradient descent) or its variants in polynomial time using polynomially many samples. The sample complexity can also be almost independent of the number of parameters in the overparameterized network. |
Recurrent Neural Networks (RNNs) are among the most popular models in sequential data analysis. Yet, in the foundational PAC learning language, what concept class can it learn? Moreover, how can the same recurrent unit simultaneously learn functions from different input tokens to different output tokens, without affecting each other? Existing generalization bounds for RNN scale exponentially with the input length, significantly limiting their practical implications. In this paper, we show using the vanilla stochastic gradient descent (SGD), RNN can actually learn some notable concept class efficiently, meaning that both time and sample complexity scale polynomially in the input length (or almost polynomially, depending on the concept). This concept class at least includes functions where each output token is generated from inputs of earlier tokens using a smooth two-layer neural network. |
How can local-search methods such as stochastic gradient descent (SGD) avoid bad local minima in training multi-layer neural networks? Why can they fit random labels even given non-convex and non-smooth architectures? Most existing theory only covers networks with one hidden layer, so can we go deeper? In this paper, we focus on recurrent neural networks (RNNs) which are multi-layer networks widely used in natural language processing. They are harder to analyze than feedforward neural networks, because the same recurrent unit is repeatedly applied across the entire time horizon of length L, which is analogous to feedforward networks of depth L. We show when the number of neurons is sufficiently large, meaning polynomial in the training data size and in L, then SGD is capable of minimizing the regression loss in the linear convergence rate. This gives theoretical evidence of how RNNs can memorize data. More importantly, in this paper we build general toolkits to analyze multi-layer networks with ReLU activations. For instance, we prove why ReLU activations can prevent exponential gradient explosion or vanishing, and build a perturbation theory to analyze first-order approximation of multi-layer networks. |
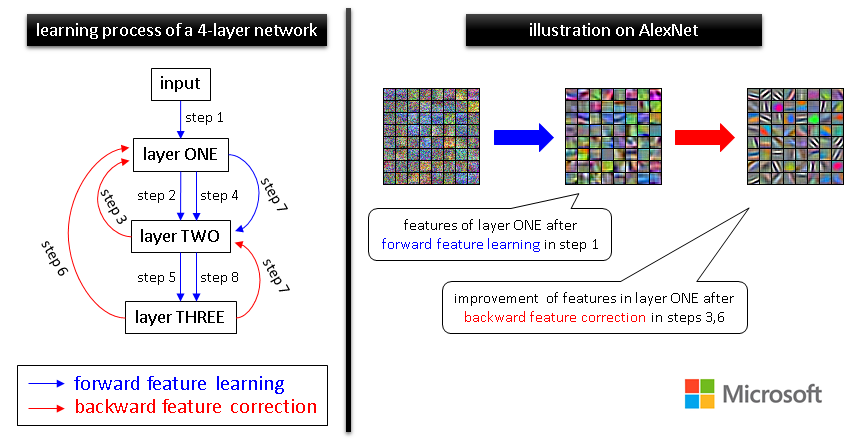
Deep neural networks (DNNs) have demonstrated dominating performance in many fields; since AlexNet, networks used in practice are going wider and deeper. On the theoretical side, a long line of works have been focusing on why we can train neural networks when there is only one hidden layer. The theory of multi-layer networks remains somewhat unsettled. In this work, we prove why simple algorithms such as stochastic gradient descent (SGD) can find global minima on the training objective of DNNs in polynomial time. We only make two assumptions: the inputs do not degenerate and the network is over-parameterized. The latter means the number of hidden neurons is sufficiently large: polynomial in \(L\), the number of DNN layers and in \(n\), the number of training samples. As concrete examples, starting from randomly initialized weights, we show that SGD attains 100% training accuracy in classification tasks, or minimizes regression loss in linear convergence speed \(\varepsilon \propto e^{-\Omega(T)}\), with running time polynomial in \(n\) and \(L\). Our theory applies to the widely-used but non-smooth ReLU activation, and to any smooth and possibly non-convex loss functions. In terms of network architectures, our theory at least applies to fully-connected neural networks, convolutional neural networks (CNN), and residual neural networks (ResNet). |
We design a stochastic algorithm to train any smooth neural network to \(\varepsilon\)-approximate local minima, using \(O(\varepsilon^{-3.25})\) backpropagations. The best result was essentially \(O(\varepsilon^{-4})\) by SGD. More broadly, it finds \(\varepsilon\)-approximate local minima of any smooth nonconvex function in rate \(O(\varepsilon^{-3.25})\), with only oracle access to stochastic gradients. |
Stochastic gradient descent (SGD) gives an optimal convergence rate when minimizing convex stochastic objectives \(f(x)\). However, in terms of making the gradients small, the original SGD does not give an optimal rate, even when \(f(x)\) is convex. If \(f(x)\) is convex, to find a point with gradient norm \(\varepsilon\), we design an algorithm SGD3 with a near-optimal rate \(\tilde{O}(\varepsilon^{-2})\), improving the best known rate \(O(\varepsilon^{-8/3})\). If \(f(x)\) is nonconvex, to find its \(\varepsilon\)-approximate local minimum, we design an algorithm SGD5 with rate \(\tilde{O}(\varepsilon^{-3.5})\), where previously SGD variants are only known to achieve rate \(\tilde{O}(\varepsilon^{-4})\). |
Model-free reinforcement learning (RL) algorithms, such as Q-learning, directly parameterize and update value functions or policies without explicitly modeling the environment. They are typically simpler, more flexible to use, and thus more prevalent in modern deep RL than model-based approaches. However, empirical work has suggested that model-free algorithms may require more samples to learn. The theoretical question of "whether model-free algorithms can be made sample efficient" is one of the most fundamental questions in RL, and remains unsolved even in the basic scenario with finitely many states and actions. We prove that, in an episodic MDP setting, Q-learning with UCB exploration achieves regret \(\tilde{O}(\sqrt{H^3SAT})\), where S and A are the numbers of states and actions, H is the number of steps per episode, and T is the total number of steps. This sample efficiency matches the optimal regret that can be achieved by any model-based approach, up to a single \(\sqrt{H}\) factor. This is the first analysis in the model-free setting that establishes \(\sqrt{T}\) regret without requiring access to a "simulator." |
Classically, the time complexity of a first-order method is estimated by its number of gradient computations. In this paper, we study a more refined complexity by taking into account the "lingering" of gradients: once a gradient is computed at \(x_k\), the additional time to compute gradients at \(x_{k+1},x_{k+2},\dots\) may be reduced. We show how this improves the running time of gradient descent and SVRG. For instance, if the "additional time" scales linearly with respect to the traveled distance, then the "convergence rate" of gradient descent can be improved from \(1/T\) to \(\exp(−T^{1/3})\). On the empirical side, we solve a hypothetical revenue management problem on the Yahoo! Front Page Today Module application with 4.6m users to 10−6 error (or 10−12 dual error) using 6 passes of the dataset. |
This paper studies the problem of distributed stochastic optimization in an adversarial setting where, out of the \(m\) machines which allegedly compute stochastic gradients every iteration, an \(\alpha\)-fraction are Byzantine, and can behave arbitrarily and adversarially. Our main result is a variant of stochastic gradient descent (SGD) which finds \(\varepsilon\)-approximate minimizers of convex functions in \(T = \tilde{O}\big( \frac{1}{\varepsilon^2 m} + \frac{\alpha^2}{\varepsilon^2} \big)\) iterations. In contrast, traditional mini-batch SGD needs \(T = O\big( \frac{1}{\varepsilon^2 m} \big)\) iterations, but cannot tolerate Byzantine failures. Further, we provide a lower bound showing that, up to logarithmic factors, our algorithm is information-theoretically optimal both in terms of sampling complexity and time complexity. |
We propose a reduction for non-convex optimization that can (1) turn a stationary-point finding algorithm into a local-minimum finding one, and (2) replace the Hessian-vector product computations with only gradient computations. It works both in the stochastic and the deterministic settings, without hurting the algorithm's performance. As applications, our reduction turns Natasha2 into a first-order method without hurting its performance. It also converts SGD, GD, SCSG, and SVRG into local-minimum finding algorithms outperforming some best known results. |

The problem of minimizing sum-of-nonconvex functions (i.e., convex functions that are average of non-convex ones) is becoming increasingly important in machine learning, and is the core machinery for PCA, SVD, regularized Newton's method, accelerated non-convex optimization, and more. We show how to provably obtain an accelerated stochastic algorithm for minimizing sum-of-nonconvex functions, by adding one additional line to the well-known SVRG method. This line corresponds to momentum, and shows how to directly apply momentum to the finite-sum stochastic minimization of sum-of-nonconvex functions. As a side result, our method enjoys linear parallel speed-up using mini-batch. |
Regret bounds in online learning compare the player's performance to \(L^*\), the optimal performance in hindsight with a fixed strategy. Typically such bounds scale with the square root of the time horizon \(T\). The more refined concept of first-order regret bound replaces this with a scaling \(\sqrt{L^*}\), which may be much smaller than \(\sqrt{T}\). It is well known that minor variants of standard algorithms satisfy first-order regret bounds in the full information and multi-armed bandit settings. In a COLT 2017 open problem, Agarwal, Krishnamurthy, Langford, Luo, and Schapire raised the issue that existing techniques do not seem sufficient to obtain first-order regret bounds for the contextual bandit problem. In the present paper, we resolve this open problem by presenting a new strategy based on augmenting the policy space. |
We propose a new second-order method for geodesically convex optimization on the natural hyperbolic metric over positive definite matrices. We apply it to solve the operator scaling problem in time polynomial in the input size and logarithmic in the error. This is an exponential improvement over previous algorithms which were analyzed in the usual Euclidean, commutative metric (for which the above problem is not convex). Our method is general and applicable to other settings. As a consequence, we solve the equivalence problem for the left-right group action underlying the operator scaling problem, and derandomize a new class of Polynomial Identity Testing (PIT) problems, which was the original motivation for studying operator scaling. |
We propose a rank-k variant of the classical Frank-Wolfe algorithm to solve convex optimization over a trace-norm ball. Our algorithm replaces the top singular-vector computation (1-SVD) in Frank-Wolfe with a top-k singular-vector computation (k-SVD), which can be done by repeatedly applying 1-SVD k times. Our algorithm has a linear convergence rate when the objective function is smooth and strongly convex, and the optimal solution has rank at most k. This improves the convergence rate and the total complexity of the Frank-Wolfe method and its variants. |
We study online principle component analysis (PCA), that is to find the top k eigenvectors of a \(d\times d\) hidden matrix \(\mathbf{\Sigma}\) with online data samples drawn from covariance matrix \(\mathbf{\Sigma}\). We provide global convergence for Oja's algorithm which is popularly used in practice but lacks theoretical understanding for \(k>1\). We also provide a modified variant \(\mathsf{Oja}^{++}\) that runs even faster than Oja's. Our results match the information theoretic lower bound in terms of dependency on error, on eigengap, on rank \(k\), and on dimension \(d\), up to poly-log factors. In addition, our convergence rate can be made gap-free, that is proportional to the approximation error and independent of the eigengap. In contrast, for general rank k, before our work (1) it was open to design any algorithm with efficient global convergence rate; and (2) it was open to design any algorithm with (even local) gap-free convergence rate. |
We develop several efficient algorithms for the classical Matrix Scaling problem, which is used in many diverse areas, from preconditioning linear systems to approximation of the permanent. On an input \(n\times n\) matrix \(A\), this problem asks to find diagonal scaling matrices \(X, Y\) (if they exist), so that \(X A Y\) \(\varepsilon\)-approximates a doubly stochastic matrix, or more generally a matrix with prescribed row and column sums. We address the general scaling problem as well as some important special cases. In particular, if \(A\) has \(m\) nonzero entries, and if there exist \(X, Y\) with polynomially large entries such that \(X A Y\) is doubly stochastic, then we can solve the problem in total complexity \(\tilde{O}(m + n^{4/3})\). This greatly improves on the best known previous results, which were either \(\tilde{O}(n^4)\) or \(O(m n^{1/2}/\varepsilon)\). |
Matrix multiplicative weight update (MMWU) is an extremely powerful algorithmic tool for computer science and related fields. However, it comes with a slow running time due to the matrix exponential and eigendecomposition computations. For this reason, many researchers studied the followed-the-perturbed-leader (FTPL) framework which is faster, but a factor \(\sqrt{d}\) worse than the optimal regret of MMWU for dimension-d matrices. In this paper, we propose a followed-the-compressed-leader framework which, not only matches the optimal regret of MMWU (up to polylog factors), but runs even faster than FTPL. Our main idea is to compress the matrix exponential computation to dimension 3 in the adversarial setting, or dimension 1 in the stochastic setting. This result resolves an open question regarding how to obtain both (nearly) optimal and efficient algorithms for the online eigenvector problem. |
Given a non-convex function \(f(x)\) that is an average of n smooth functions, we design stochastic first-order methods to find its approximate stationary points. The performance of our new methods depend on the smallest (negative) eigenvalue \(-\sigma\) of the Hessian. This parameter \(\sigma\) captures how strongly non-convex \(f(x)\) is, and is analogous to the strong convexity parameter for convex optimization. Our methods outperform the best known results for a wide range of \(\sigma\), and can also be used to find approximate local minima. In particular, we find an interesting dichotomy: there exists a threshold \(\sigma_0\) so that the fastest methods for \(\sigma>\sigma_0\) and for \(\sigma<\sigma_0\) have drastically different behaviors: the former scales with \(n^{2/3}\) and the latter scales with \(n^{3/4}\). |
This paper has been superceded by our subsequent paper "Near-Optimal Discrete Optimization for Experimental Design: A Regret Minimization Approach". |
We solve principal component regression (PCR), up to a multiplicative accuracy \(1+\gamma\), by reducing the problem to \(\tilde{O}(\gamma^{-1})\) black-box calls of ridge regression. Therefore, our algorithm does not require any explicit construction of the top principal components, and is suitable for large-scale PCR instances. In contrast, previous result requires \(\tilde{O}(\gamma^{-2})\) such black-box calls. We obtain this result by developing a general stable recurrence formula for matrix Chebyshev polynomials, and a degree-optimal polynomial approximation to the matrix sign function. Our techniques may be of independent interests, especially when designing iterative methods. |
We study k-GenEV, the problem of finding the top k generalized eigenvectors, and k-CCA, the problem of finding the top k vectors in canonical-correlation analysis. We propose algorithms LazyEV and LazyCCA to solve the two problems with running times linearly dependent on the input size and on k. Furthermore, our algorithms are DOUBLY-ACCELERATED: our running times depend only on the square root of the matrix condition number, and on the square root of the eigengap. This is the first such result for both k-GenEV or k-CCA. We also provide the first gap-free results, which provide running times that depend on \(1/\sqrt{\varepsilon}\) rather than the eigengap. |
We introduce
Unlike previous results, The main ingredient behind our result is Katyusha momentum, a novel "negative momentum on top of momentum" that can be incorporated into a variance-reduction based algorithm and speed it up. As a result, since variance reduction has been successfully applied to a fast growing list of practical problems, our paper suggests that in each of such cases, one had better hurry up and give Katyusha a hug. |
We design a non-convex second-order optimization algorithm that is guaranteed to return an approximate local minimum in time which is linear in the input representation. The time complexity of our algorithm to find an approximate local minimum is even faster than that of gradient descent to find a critical point. Our algorithm applies to a general class of optimization problems including training a neural network and other non-convex objectives arising in machine learning. |
First-order methods play a central role in large-scale machine learning. Even though many variations exist, each suited to a particular problem, almost all such methods fundamentally rely on two types of algorithmic steps: gradient descent, which yields primal progress, and mirror descent, which yields dual progress. We observe that the performances of gradient and mirror descent are complementary, so that faster algorithms can be designed by linearly coupling the two. We show how to reconstruct Nesterov's accelerated gradient methods using linear coupling, which gives a cleaner interpretation than Nesterov's original proofs. We also discuss the power of linear coupling by extending it to many other settings that Nesterov's methods cannot apply to. |
We study k-SVD that is to obtain the first k singular vectors of a matrix A. Recently, a few breakthroughs have been discovered on k-SVD: Musco and Musco [1] provided the first gap-free theorem for the block Krylov method, Shamir [2] discovered the first variance-reduction stochastic method, and Bhojanapalli et al. [3] provided the fastest \(O(\mathsf{nnz}(A)+\mathsf{poly}(1/\varepsilon))\)-time algorithm using alternating minimization. In this paper, we put forward a new and simple LazySVD framework to improve the above breakthroughs. This framework leads to a faster gap-free method outperforming [1], and the first accelerated and stochastic method outperforming [2]. In the \(O(\mathsf{nnz}(A)+\mathsf{poly}(1/\varepsilon))\) running-time regime, LazySVD outperforms [3] in certain parameter regimes without even using alternating minimization. |

The diverse world of machine learning applications has given rise to a plethora of algorithms and optimization methods, finely tuned to the specific regression or classification task at hand. We reduce the complexity of algorithm design for machine learning by reductions: we develop reductions that take a method developed for one setting and apply it to the entire spectrum of smoothness and strong-convexity in applications. Furthermore, unlike existing results, our new reductions are OPTIMAL and more PRACTICAL. We show how these new reductions give rise to new and faster running times on training linear classifiers for various families of loss functions, and conclude with experiments showing their successes also in practice. |
The amount of data available in the world is growing faster and bigger than our ability to deal with it. However, if we take advantage of the internal structure, data may become much smaller for machine learning purposes. In this paper we focus on one of the most fundamental machine learning tasks, empirical risk minimization (ERM), and provide faster algorithms with the help from the clustering structure of the data. We introduce a simple notion of raw clustering that can be efficiently obtained with just one pass of the data, and propose two algorithms. Our variance-reduction based algorithm ClusterSVRG introduces a new gradient estimator using the clustering information, and our accelerated algorithm ClusterACDM is built on a novel Haar transformation applied to the dual space of each cluster. Our algorithms outperform their classical counterparts both in theory and practice. |

We consider the fundamental problem in non-convex optimization of efficiently reaching a stationary point. In contrast to the convex case, in the long history of this basic problem, the only known theoretical results on first-order non-convex optimization remain to be full gradient descent that converges in \(O(1/\varepsilon)\) iterations for smooth objectives, and stochastic gradient descent that converges in \(O(1/\varepsilon^2)\) iterations for objectives that are sum of smooth functions. We provide the first improvement in this line of research. Our result is based on the variance reduction trick recently introduced to convex optimization, as well as a brand new analysis of variance reduction that is suitable for non-convex optimization. For objectives that are sum of smooth functions, our first-order minibatch stochastic method converges with an \(O(1/\varepsilon)\) rate, and is faster than full gradient descent by \(\Omega(n^{1/3})\). We demonstrate the effectiveness of our methods on empirical risk minimizations with non-convex loss functions and training neural nets. |

Accelerated coordinate descent is widely used in optimization due to its cheap per-iteration cost and scalability to large-scale problems. Up to a primal-dual transformation, it is also the same as accelerated stochastic gradient descent that is one of the central methods used in machine learning. In this paper, we improve the best known running time of accelerated coordinate descent by a factor up to \(\sqrt{n}\). Our improvement is based on a clean, novel non-uniform sampling that selects each coordinate with a probability proportional to the square root of its smoothness parameter. Our proof technique also deviates from the classical estimation sequence technique used in prior work. Our speed-up applies to important problems such as empirical risk minimization and solving linear systems, both in theory and in practice. |

Many classical algorithms are found until several years later to outlive the confines in which they were conceived, and continue to be relevant in unforeseen settings. In this paper, we show that SVRG is one such method: being originally designed for strongly convex objectives, it is also very robust in non-strongly convex or sum-of-non-convex settings. More precisely, we provide new analysis to improve the state-of-the-art running times in both settings by either applying SVRG or its novel variant. Since non-strongly convex objectives include important examples such as Lasso or logistic regression, and sum-of-non-convex objectives include famous examples such as stochastic PCA and is even believed to be related to training deep neural nets, our results also imply better performances in these applications. |
We study two fundamental problems in computational geometry: finding the maximum inscribed ball (MaxIB) inside a bounded polyhedron defined by $m$ hyperplanes, and the minimum enclosing ball (MinEB) of a set of $n$ points, both in $d$-dimensional space. We improve the running time of iterative algorithms on
|
The Restricted Isometry Property (RIP) is a fundamental property of a matrix which enables sparse recovery. Informally, an \(m \times n\) matrix satisfies RIP of order \(k\) for the \(\ell_p\) norm, if \(\|Ax\|_p \approx \|x\|_p\) for every \(x\) with at most \(k\) non-zero coordinates. For every \(1 \leq p < \infty\) we obtain almost tight bounds on the minimum number of rows \(m\) necessary for the RIP property to hold. Before, only the cases \(p \in \big\{1, 1 + \frac{1}{\log k}, 2\big\}\) were studied. Interestingly, our results show that the case \(p = 2\) is a `singularity' in terms of the optimum value of \(m\). We also obtain almost tight bounds for the column sparsity of RIP matrices and discuss implications of our results for the Stable Sparse Recovery problem. |
We study the design of polylogarithmic depth algorithms for approximately solving packing and covering semidefinite programs (or positive SDPs for short). This is a natural SDP generalization of the well-studied positive LP problem. Although positive LPs can be solved in polylogarithmic depth while using only \(\log^{2} n/\varepsilon^3\) parallelizable iterations [3], the best known positive SDP solvers due to Jain and Yao [18] require \(\log^{14} n /\varepsilon^{13}\) parallelizable iterations. Several alternative solvers have been proposed to reduce the exponents in the number of iterations [19, 29]. However, the correctness of the convergence analyses in these works has been called into question [29], as they both rely on algebraic monotonicity properties that do not generalize to matrix algebra. In this paper, we propose a very simple algorithm based on the optimization framework proposed in [3] for LP solvers. Our algorithm only needs \(\log^2 n / \varepsilon^3\) iterations, matching that of the best LP solver. To surmount the obstacles encountered by previous approaches, our analysis requires a new matrix inequality that extends Lieb-Thirring's inequality, and a sign-consistent, randomized variant of the gradient truncation technique proposed in [2, 3]. |
Designing distributed and scalable algorithms to improve network connectivity is a central topic in peer-to-peer networks. In this paper we focus on the following well-known problem: given an n-node d-regular network, we want to design a decentralized, local algorithm that transforms the graph into one that has good connectivity properties (low diameter, expansion, etc.) without affecting the sparsity of the graph. To this end, Mahlmann and Schindelhauer introduced the random "flip" transformation, where in each time step, a random pair of vertices that have an edge decide to 'swap a neighbor'. They conjectured that performing \(\mathrm{poly}(d) \times n\log n\) such flips at random would convert any connected d-regular graph into a d-regular expander graph, with high probability. However, the best known upper bound for the number of steps is roughly \(O(n^{17} d^{23})\), obtained via a delicate Markov chain comparison argument. Our main result is to prove that a natural instantiation of the random flip produces an expander in at most \(O(n^2 d^2 \sqrt{\log n})\) steps, with high probability. Our argument uses a potential-function analysis based on the matrix exponential, together with the recent beautiful results on the higher-order Cheeger inequality of graphs. We also show that our technique can be used to analyze another well-studied random process known as the 'random switch', and show that it produces an expander in \(O(n d)\) steps for \(d=\Omega(\log n)\), with high probability. |
Packing and covering linear programs (PC-LPs) form an important class of linear programs (LPs) across computer science, operations research, and optimization. In 1993, Luby and Nisan constructed an iterative algorithm for approximately solving PC-LPs in nearly linear time, where the time complexity scales nearly linearly in \(N\), the number of nonzero entries of the matrix, and polynomially in \(\varepsilon\), the (multiplicative) approximation error. Unfortunately, existing nearly linear-time algorithms for solving PC-LPs require time at least proportional to \(\varepsilon^{-2}\). In this paper, we break this longstanding barrier by designing a packing solver that runs in time \(\tilde{O}(N \varepsilon^{-1})\) and covering LP solver that runs in time \(\tilde{O}(N \varepsilon^{-1.5})\). Our packing solver can be extended to run in time \(\tilde{O}(N \varepsilon^{-1})\) for a class of well-behaved covering programs. In a follow-up work, Wang et al. showed that all covering LPs can be converted into well-behaved ones by a reduction that blows up the problem size only logarithmically. |
In this paper, we provide a novel construction of the linear-sized spectral sparsifiers of Batson, Spielman and Srivastava [BSS14]. While previous constructions required \(\Omega(n^4)\) running time [BSS14, Zou12], our sparsification routine can be implemented in almost-quadratic running time \(O(n^{2+eps})\). The fundamental conceptual novelty of our work is the leveraging of a strong connection between sparsification and a regret minimization problem over density matrices. This connection was known to provide an interpretation of the randomized sparsifiers of Spielman and Srivastava [SS11] via the application of matrix multiplicative weight updates (MWU) [CHS11, Vis14]. In this paper, we explain how matrix MWU naturally arises as an instance of the Follow-the-Regularized-Leader framework and generalize this approach to yield a larger class of updates. This new class allows us to accelerate the construction of linear-sized spectral sparsifiers, and give novel insights on the motivation behind Batson, Spielman and Srivastava [BSS14]. |
We study the design of nearly-linear-time algorithms for approximately solving positive linear programs. Both the parallel and the sequential deterministic versions of these algorithms require \(\tilde{O}(\varepsilon^{-4})\) iterations, a dependence that has not been improved since the introduction of these methods in 1993 by Luby and Nisan. Moreover, previous algorithms and their analyses rely on update steps and convergence arguments that are combinatorial in nature, and do not seem to arise naturally from an optimization viewpoint. In this paper, we leverage insights from optimization theory to construct a novel algorithm that breaks the longstanding \(\tilde{O}(\varepsilon^{-4})\) barrier. Our algorithm has a simple analysis and a clear motivation. Our work introduces a number of novel techniques, such as the combined application of gradient descent and mirror descent, and a truncated, smoothed version of the standard multiplicative weight update, which may be of independent interest. |
|

Arithmetizing computation is a crucial component of many fundamental results in complexity theory, including results that gave insight into the power of interactive proofs, multi-prover interactive proofs, and probabilistically-checkable proofs. Informally, an arithmetization is a way to encode a machine's computation so that its correctness can be easily verified via few probabilistic algebraic checks. We study the problem of arithmetizing nondeterministic computations for the purpose of constructing short probabilistically-checkable proofs (PCPs) with polylogarithmic query complexity. In such a setting, a PCP's proof length depends (at least!) linearly on the length, in bits, of the encoded computation. Thus, minimizing the number of bits in the encoding is crucial for minimizing PCP proof length. In this paper we show how to arithmetize any T-step computation on a nondeterministic Turing machine by using a polynomial encoding of length $$O\big( T \cdot (\log T)^2 \big) \enspace.$$ Previously, the best known length was \(\Omega(T \cdot (\log T)^4)\). For nondeterministic random-access machines, our length is \(O(T \cdot (\log T)^{2+o(1)})\), while prior work only achieved \(\Omega(T \cdot (\log T)^5)\). The polynomial encoding that we use is the Reed--Solomon code. When combined with the best PCPs of proximity for this code, our result yields quasilinear-size PCPs with polylogarithmic query complexity that are shorter, by at least two logarithmic factors, than in all prior work. Our arithmetization also enjoys additional properties. First, it is succinct, i.e., the encoding of the computation can be probabilistically checked in \((\log T)^{O(1)}\) time; this property is necessary for constructing short PCPs with a polylogarithmic-time verifier. Furthermore, our techniques extend, in a certain well-defined sense, to the arithmetization of yet other NEXP-complete languages. |
Johnson-Lindenstrauss (JL) matrices implemented by sparse random synaptic connections are thought to be a prime candidate for how convergent pathways in the brain compress information. However, to date, there is no complete mathematical support for such implementations given the constraints of real neural tissue. The fact that neurons are either excitatory or inhibitory implies that every so implementable JL matrix must be sign-consistent (i.e., all entries in a single column must be either all non-negative or all non-positive), and the fact that any given neuron connects to a relatively small subset of other neurons implies that the JL matrix had better be sparse. We construct sparse JL matrices that are sign-consistent, and prove that our construction is essentially optimal. Our work answers a mathematical question that was triggered by earlier work and is necessary to justify the existence of JL compression in the brain, and emphasizes that inhibition is crucial if neurons are to perform efficient, correlation-preserving compression. |
We investigate the problem of exactly reconstructing, with high confidence and up to isomorphism, the ball of radius r centered at the starting state of a Markov process from independent and anonymous experiments. In an anonymous experiment, the states are visited according to the underlying transition probabilities, but no global state names are known: one can only recognize whether two states, reached within the same experiment, are the same. We prove quite tight bounds for such exact reconstruction in terms of both the number of experiments and their lengths. |
|
Given a subset S of vertices of an undirected graph G, the cut-improvement problem asks us to find a subset S that is similar to A but has smaller conductance. A very elegant algorithm for this problem has been given by Andersen and Lang [AL08] and requires solving a small number of single-commodity maximum flow computations over the whole graph G. In this paper, we introduce LocalImprove, the first cut-improvement algorithm that is local, i.e. that runs in time dependent on the size of the input set A rather than on the size of the entire graph. Moreover, LocalImprove achieves this local behaviour while essentially matching the same theoretical guarantee as the global algorithm of Andersen and Lang. The main application of LocalImprove is to the design of better local-graph-partitioning algorithms. All previously known local algorithms for graph partitioning are random-walk based and can only guarantee an output conductance of \(\tilde{O}(\sqrt{\phi})\) when the target set has conductance \(\phi \in [0,1]\). Very recently, Zhu, Lattanzi and Mirrokni [ZLM13] improved this to \(O(\phi / \sqrt{\mathsf{Conn}})\) where the internal connectivity parameter \(\mathsf{Conn} \in [0,1]\) is defined as the reciprocal of the mixing time of the random walk over the graph induced by the target set. In this work, we show how to use LocalImprove to obtain a constant approximation \(O(\phi)\) as long as \(\mathsf{Conn}/\phi = \Omega(1)\). This yields the first flow-based algorithm. Moreover, its performance strictly outperforms the ones based on random walks and surprisingly matches that of the best known global algorithm, which is SDP-based, in this parameter regime [MMV12]. Finally, our results show that spectral methods are not the only viable approach to the construction of local graph partitioning algorithm and open door to the study of algorithms with even better approximation and locality guarantees. |
Motivated by applications of large-scale graph clustering, we study random-walk-based local algorithms whose running times depend only on the size of the output cluster, rather than the entire graph. All previously known such algorithms guarantee an output conductance of \(\tilde{O}(\sqrt{\phi(A)})\) when the target set A has conductance \(\phi(A)\in[0,1]\). In this paper, we improve it to \[\tilde{O}\bigg( \min\Big\{\sqrt{\phi(A)}, \frac{\phi(A)}{\sqrt{\mathsf{Conn}(A)}} \Big\} \bigg)\enspace, \] where the internal connectivity parameter \(\mathsf{Conn}(A)\in[0,1]\) is defined as the reciprocal of the mixing time of the random walk over the induced subgraph on A. For instance, using \(\mathsf{Conn}(A)=\Omega(\lambda(A)/\log n)\) where \(\lambda\) is the second eigenvalue of the Laplacian of the induced subgraph on A, our conductance guarantee can be as good as \(\tilde{O}(\phi(A)/\sqrt{\lambda(A)})\). This builds an interesting connection to the recent advance of the so-called improved Cheeger's Inequality [KKL+13], which says that global spectral algorithms can provide a conductance guarantee of \(O(\phi_{\mathsf{opt}}/\sqrt{\lambda_3})\) instead of \(O(\sqrt{\phi_{\mathsf{opt}}})\). In addition, we provide theoretical guarantee on the clustering accuracy (in terms of precision and recall) of the output set. We also prove that our analysis is tight, and perform empirical evaluation to support our theory on both synthetic and real data. It is worth noting that, our analysis outperforms prior work when the cluster is well-connected. In fact, the better it is well-connected inside, the more significant improvement (both in terms of conductance and accuracy) we can obtain. Our results shed light on why in practice some random-walk-based algorithms perform better than its previous theory, and help guide future research about local clustering. |
In this paper, we present a simple combinatorial algorithm that solves symmetric diagonally dominant (SDD) linear systems in nearly-linear time. It uses very little of the machinery that previously appeared to be necessary for a such an algorithm. It does not require recursive preconditioning, spectral sparsi cation, or even the Chebyshev Method or Conjugate Gradient. After constructing a "nice" spanning tree of a graph associated with the linear system, the entire algorithm consists of the repeated application of a simple (non-recursive) update rule, which it implements using a lightweight data structure. The algorithm is numerically stable and can be implemented without the increased bit-precision required by previous solvers. As such, the algorithm has the fastest known running time under the standard unit-cost RAM model. We hope that the simplicity of the algorithm and the insights yielded by its analysis will be useful in both theory and practice. |
|
Despite the fact that approximate computations have come to dominate many areas of computer science, the field of program transformations has focused almost exclusively on traditional semantics-preserving transformations that do not attempt to exploit the opportunity, available in many computations, to acceptably trade off accuracy for benefits such as increased performance and reduced resource consumption. We present a model of computation for approximate computations and an algorithm for optimizing these computations. The algorithm works with two classes of transformations: substitution transformations (which select one of a number of available implementations for a given function, with each implementation offering a different combination of accuracy and resource consumption) and sampling transformations (which randomly discard some of the inputs to a given reduction). The algorithm produces a (1+ε) randomized approximation to the optimal randomized computation (which minimizes resource consumption subject to a probabilistic accuracy specification in the form of a maximum expected error or maximum error variance). |
In revenue maximization of selling a digital product in a social network, the utility of an agent is often considered to have two parts: a private valuation, and linearly additive in uences from other agents. We study the incomplete information case where agents know a common distribution about others' private valuations, and make decisions simultaneously. The "rational behavior" of agents in this case is captured by the well-known Bayesian Nash equilibrium. Two challenging questions arise: how to compute an equilibrium and how to optimize a pricing strategy accordingly to maximize the revenue assuming agents follow the equilibrium? In this paper, we mainly focus on the natural model where the private valuation of each agent is sampled from a uniform distribution, which turns out to be already challenging. Our main result is a polynomial-time algorithm that can exactly compute the equilibrium and the optimal price, when pairwise in uences are non-negative. If negative in uences are allowed, computing any equilibrium even approximately is PPAD-hard. Our algorithm can also be used to design an FPTAS for optimizing discriminative price profile. [arXiv version] |
We consider the problem of locating facilities in a metric space to serve a set of selfish agents. The cost of an agent is the distance between her own location and the nearest facility. The social cost is the total cost of the agents. We are interested in designing strategy-proof mechanisms without payment that have a small approximation ratio for social cost. A mechanism is a (possibly randomized) algorithm which maps the locations reported by the agents to the locations of the facilities. A mechanism is strategy-proof if no agent can benefit from misreporting her location in any configuration. This setting was first studied by Procaccia and Tennenholtz [21]. They focused on the facility game where agents and facilities are located on the real line. Alon et al. studied the mechanisms for the facility games in a general metric space [1]. However, they focused on the games with only one facility. In this paper, we study the two-facility game in a general metric space, which extends both previous models. We first prove an \(\Omega(n)\) lower bound of the social cost approximation ratio for deterministic strategy-proof mechanisms. Our lower bound even holds for the line metric space. This significantly improves the previous constant lower bounds [21, 17]. Notice that there is a matching linear upper bound in the line metric space [21]. Next, we provide the first randomized strategy-proof mechanism with a constant approximation ratio of 4. Our mechanism works in general metric spaces. For randomized strategy-proof mechanisms, the previous best upper bound is \(O(n)\) which works only in the line metric space. |
Recent advances in click model have positioned it as an attractive method for representing user preferences in web search and online advertising. Yet, most of the existing works focus on training the click model for individual queries, and cannot accurately model the tail queries due to the lack of training data. Simultaneously, most of the existing works consider the query, url and position, neglecting some other important attributes in click log data, such as the local time. Obviously, the click through rate is different between daytime and midnight. In this paper, we propose a novel click model based on Bayesian network, which is capable of modeling the tail queries because it builds the click model on attribute values, with those values being shared across queries. We called our work General Click Model (GCM) as we found that most of the existing works can be special cases of GCM by assigning different parameters. Experimental results on a largescale commercial advertisement dataset show that GCM can significantly and consistently lead to better results as compared to the state-of-the-art works. |
In the conventional regularized learning, training time increases as the training set expands. Recent work on L2 linear SVM challenges this common sense by proposing the inverse time dependency on the training set size. In this paper, we first put forward a Primal Gradient Solver (PGS) to effectively solve the convex regularized learning problem. This solver is based on the stochastic gradient descent method and the Fenchel conjugate adjustment, employing the well-known online strongly convex optimization algorithm with logarithmic regret. We then theoretically prove the inverse dependency property of our PGS, embracing the previous work of the L2 linear SVM as a special case and enable the ℓp-norm optimization to run within a bounded sphere, which qualifies more convex loss functions in PGS. We further illustrate this solver in three examples: SVM, logistic regression and regularized least square. Experimental results substantiate the property of the inverse dependency on training data size. |
(Several minor typos are found and fixed after the conference version is published.) It is an extreme challenge to produce a nonlinear SVM classifier on very large scale data. In this paper we describe a novel P-packSVM algorithm that can solve the Support Vector Machine (SVM) optimization problem with an arbitrary kernel. This algorithm embraces the best known stochastic gradient descent method to optimize the primal objective, and has 1/ε dependency in complexity to obtain a solution of optimization error ε. The algorithm can be highly parallelized with a special packing strategy, and experiences sub-linear speed-up with hundreds of processors. We demonstrate that P-packSVM achieves accuracy sufficiently close to that of SVM-light, and overwhelms the state-of-the-art parallel SVM trainer PSVM in both accuracy and efficiency. As an illustration, our algorithm trains CCAT dataset with 800k samples in 13 minutes and 95% accuracy, while PSVM needs 5 hours but only has 92% accuracy. We at last demonstrate the capability of P-packSVM on 8 million training samples. |
Learning to rank plays an important role in information retrieval. In most of the existing solutions for learning to rank, all the queries with their returned search results are learnt and ranked with a single model. In this paper, we demonstrate that it is highly beneficial to divide queries into multiple groups and conquer search ranking based on query difficulty. To this end, we propose a method which first characterizes a query using a variety of features extracted from user search behavior, such as the click entropy, the query reformulation probability. Next, a classification model is built on these extracted features to assign a score to represent how difficult a query is. Based on this score, our method automatically divides queries into groups, and trains a specific ranking model for each group to conquer search ranking. Experimental results on RankSVM and RankNet with a largescale evaluation dataset show that the proposed method can achieve significant improvement in the task of web search ranking. |
Traditional boosting algorithms for the ranking problems usually employ the pairwise approach and convert the document rating preference into a binary-value label, like RankBoost. However, such a pairwise approach ignores the information about the magnitude of preference in the learning process. In this paper, we present the directed distance function (DDF) as a substitute for binary labels in pairwise approach to preserve the magnitude of preference and propose a new boosting algorithm called MPBoost, which applies GentleBoost optimization and directly incorporates DDF into the exponential loss function. We give the boundedness property of MPBoost through theoretic analysis. Experimental results demonstrate that MPBoost not only leads to better NDCG accuracy as compared to state-of-the-art ranking solutions in both public and commercial datasets, but also has good properties of avoiding the overfitting problem in the task of learning ranking functions. |
|
|
|
|
|
|
|
|
|