Constructors, Destructors, and Assignment Operators
Almost every class you write will have one or more constructors, a destructor, and an assignment operator. Little wonder. These are your bread-and-butter functions, the ones that control the fundamental operations of bringing a new object into existence and making sure it's initialized; getting rid of an object and making sure it's been properly cleaned up; and giving an object a new value. Making mistakes in these functions will lead to far-reaching and distinctly unpleasant repercussions throughout your classes, so it's vital that you get them right. In this section, I offer guidance on putting together the functions that comprise the backbone of well-formed
Item 11: Declare a copy constructor and an assignment operator for classes with dynamically allocated memory.
Consider a class for representing String objects:
// a poorly designed String class
class String {
public:
String(const char *value);
~String();
... // no copy ctor or operator=
private:
char *data;
};
String::String(const char *value)
{
if (value) {
data = new char[strlen(value) + 1];
strcpy(data, value);
}
else {
data = new char[1];
*data = '\0';
}
}
inline String::~String() { delete [] data; }
Note that there is no assignment operator or copy constructor declared in this class. As you'll see, this has some unfortunate
If you make these object
String a("Hello");
String b("World");
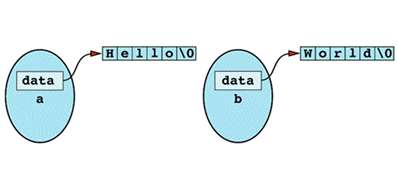
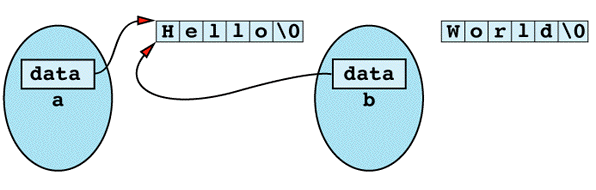
the situation is as shown
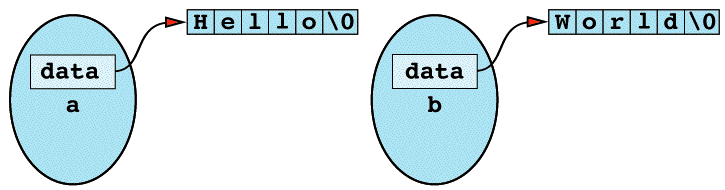
Inside object a is a pointer to memory containing the character string "Hello". Separate from that is an object b containing a pointer to the character string "World". If you now perform an
b = a;
there is no client-defined operator= to call, so C++ generates and calls the default assignment operator instead (see Item 45). This default assignment operator performs memberwise assignment from the members of a to the members of b, which for pointers (a.data and b.data) is just a bitwise copy. The result of this assignment is shown
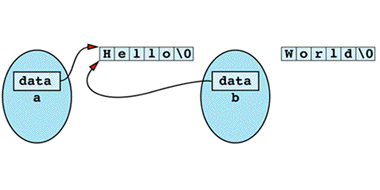
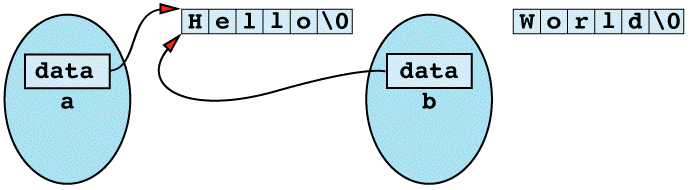
There are at least two problems with this state of affairs. First, the memory that b used to point to was never deleted; it is lost forever. This is a classic example of how a memory leak can arise. Second, both a and b now contain pointers to the same character string. When one of them goes out of scope, its destructor will delete the memory still pointed to by the other. For
String a("Hello"); // define and construct a
{ // open new scope
String b("World"); // define and construct b
...
b = a; // execute default op=,
// lose b's memory
} // close scope, call b's
// destructor
String c = a; // c.data is undefined!
// a.data is already deleted
The last statement in this example is a call to the copy constructor, which also isn't defined in the class, hence will be generated by C++ in the same manner as the assignment operator (again, see Item 45) and with the same behavior: bitwise copy of the underlying pointers. That leads to the same kind of problem, but without the worry of a memory leak, because the object being initialized can't yet point to any allocated memory. In the case of the code above, for example, there is no memory leak when c.data is initialized with the value of a.data, because c.data doesn't yet point anywhere. However, after c is initialized with a, both c.data and a.data point to the same place, so that place will be deleted twice: once when c is destroyed, once again when a is
The case of the copy constructor differs a little from that of the assignment operator, however, because of the way it can bite you: pass-by-value. Of course, Item 22 demonstrates that you should only rarely pass objects by value, but consider this
void doNothing(String localString) {}
String s = "The Truth Is Out There";
doNothing(s);
Everything looks innocuous enough, but because localString is passed by value, it must be initialized from s via the (default) copy constructor. Hence, localString has a copy of the pointer that is inside s. When doNothing finishes executing, localString goes out of scope, and its destructor is called. The end result is by now familiar: s contains a pointer to memory that localString has already
By the way, the result of using delete on a pointer that has already been deleted is undefined, so even if s is never used again, there could well be a problem when it goes out of
The solution to these kinds of pointer aliasing problems is to write your own versions of the copy constructor and the assignment operator if you have any pointers in your class. Inside those functions, you can either copy the pointed-to data structures so that every object has its own copy, or you can implement some kind of reference-counting scheme (see Item M29) to keep track of how many objects are currently pointing to a particular data structure. The reference-counting approach is more complicated, and it calls for extra work inside the constructors and destructors, too, but in some (though by no means all) applications, it can result in significant memory savings and substantial increases in
For some classes, it's more trouble than it's worth to implement copy constructors and assignment operators, especially when you have reason to believe that your clients won't make copies or perform assignments. The examples above demonstrate that omitting the corresponding member functions reflects poor design, but what do you do if writing them isn't practical, either? Simple: you follow this Item's advice. You declare the functions (private, as it turns out), but you don't define (i.e., implement) them at all. That prevents clients from calling them, and it prevents compilers from generating them, too. For details on this nifty trick, see Item 27.
One more thing about the String class I used in this Item. In the constructor body, I was careful to use [] with new both times I called it, even though in one of the places I wanted only a single object. As described in Item 5, it's essential to employ the same form in corresponding applications of new and delete, so I was careful to be consistent in my uses of new. This is something you do not want to forget. Always make sure that you use [] with delete if and only if you used [] with the corresponding use of new.
Item 12: Prefer initialization to assignment in constructors.
Consider a template for generating classes that allow a name to be associated with a pointer to an object of some type
template<class T>
class NamedPtr {
public:
NamedPtr(const string& initName, T *initPtr);
...
private: string name; T *ptr; };
(In light of the aliasing that can arise during the assignment and copy construction of objects with pointer members (see Item 11), you might wish to consider whether NamedPtr should implement these functions. Hint: it should (see Item 27).)
When you write the NamedPtr constructor, you have to transfer the values of the parameters to the corresponding data members. There are two ways to do this. The first is to use the member initialization
template<class T>
NamedPtr<T>::NamedPtr(const string& initName, T *initPtr )
: name(initName), ptr(initPtr)
{}
The second is to make assignments in the constructor
template<class T>
NamedPtr<T>::NamedPtr(const string& initName, T *initPtr)
{
name = initName;
ptr = initPtr;
}
There are important differences between these two
From a purely pragmatic point of view, there are times when the initialization list must be used. In particular, const and reference members may only be initialized, never assigned. So, if you decided that a NamedPtr<T> object could never change its name or its pointer, you might follow the advice of Item 21 and declare the members const:
template<class T>
class NamedPtr {
public:
NamedPtr(const string& initName, T *initPtr);
...
private: const string name; T * const ptr; };
This class definition requires that you use a member initialization list, because const members may only be initialized, never
NamedPtr<T> object should contain a reference to an existing name. Even so, you'd still have to initialize the reference on your constructors' member initialization lists. Of course, you could also combine the two, yielding NamedPtr<T> objects with read-only access to names that might be modified outside the class:
template<class T>
class NamedPtr {
public:
NamedPtr(const string& initName, T *initPtr);
...
private:
const string& name; // must be initialized via
// initializer list
T * const ptr; // must be initialized via
// initializer list
};
The original class template, however, contains no const or reference members. Even so, using a member initialization list is still preferable to performing assignments inside the constructor. This time the reason is efficiency. When a member initialization list is used, only a single string member function is called. When assignment inside the constructor is used, two are called. To understand why, consider what happens when you declare a NamedPtr<T>
Construction of objects proceeds in two
(For objects with base classes, base class member initialization and constructor body execution occurs prior to that for derived
For the NamedPtr classes, this means that a constructor for the string object name will always be called before you ever get inside the body of a NamedPtr constructor. The only question, then, is this: which string constructor will be
That depends on the member initialization list in the NamedPtr classes. If you fail to specify an initialization argument for name, the default string constructor will be called. When you later perform an assignment to name inside the NamedPtr constructors, you will call operator= on name. That will total two calls to string member functions: one for the default constructor and one more for the
On the other hand, if you use a member initialization list to specify that name should be initialized with initName, name will be initialized through the copy constructor at a cost of only a single function
Even in the case of the lowly string type, the cost of an unnecessary function call may be significant, and as classes become larger and more complex, so do their constructors, and so does the cost of constructing objects. If you establish the habit of using a member initialization list whenever you can, not only do you satisfy a requirement for const and reference members, you also minimize the chances of initializing data members in an inefficient
In other words, initialization via a member initialization list is always legal, is never less efficient than assignment inside the body of the constructor, and is often more efficient. Furthermore, it simplifies maintenance of the class (see Item M32), because if a data member's type is later modified to something that requires use of a member initialization list, nothing has to
There is one time, however, when it may make sense to use assignment instead of initialization for the data members in a class. That is when you have a large number of data members of built-in types, and you want them all initialized the same way in each constructor. For example, here's a class that might qualify for this kind of
class ManyDataMbrs {
public:
// default constructor
ManyDataMbrs();
// copy constructor ManyDataMbrs(const ManyDataMbrs& x);
private: int a, b, c, d, e, f, g, h; double i, j, k, l, m; };
Suppose you want to initialize all the ints to 1 and all the doubles to 0, even if the copy constructor is used. Using member initialization lists, you'd have to write
ManyDataMbrs::ManyDataMbrs()
: a(1), b(1), c(1), d(1), e(1), f(1), g(1), h(1), i(0),
j(0), k(0), l(0), m(0)
{ ... }
ManyDataMbrs::ManyDataMbrs(const ManyDataMbrs& x)
: a(1), b(1), c(1), d(1), e(1), f(1), g(1), h(1), i(0),
j(0), k(0), l(0), m(0)
{ ... }
This is more than just unpleasant drudge work. It is error-prone in the short term and difficult to maintain in the long
However, you can take advantage of the fact that there is no operational difference between initialization and assignment for (non-const, non-reference) objects of built-in types, so you can safely replace the memberwise initialization lists with a function call to a common initialization
class ManyDataMbrs {
public:
// default constructor
ManyDataMbrs();
// copy constructor ManyDataMbrs(const ManyDataMbrs& x);
private: int a, b, c, d, e, f, g, h; double i, j, k, l, m;
void init(); // used to initialize data
// members
};
void ManyDataMbrs::init()
{
a = b = c = d = e = f = g = h = 1;
i = j = k = l = m = 0;
}
ManyDataMbrs::ManyDataMbrs()
{
init();
...
}
ManyDataMbrs::ManyDataMbrs(const ManyDataMbrs& x)
{
init();
...
}
Because the initialization routine is an implementation detail of the class, you are, of course, careful to make it private,
Note that static class members should never be initialized in a class's constructor. Static members are initialized only once per program run, so it makes no sense to try to "initialize" them each time an object of the class's type is created. At the very least, doing so would be inefficient: why pay to "initialize" an object multiple times? Besides, initialization of static class members is different enough from initialization of their nonstatic counterparts that an entire Item — Item 47 — is devoted to the
Item 13: List members in an initialization list in the order in which they are declared.
Unrepentant Pascal and Ada programmers often yearn for the ability to define arrays with arbitrary bounds, i.e., from 10 to 20 instead of from 0 to 10. Long-time C programmers will insist that everybody who's anybody will always start counting from 0, but it's easy enough to placate the begin/end crowd. All you have to do is define your own Array class
template<class T>
class Array {
public:
Array(int lowBound, int highBound);
...
private:
vector<T> data; // the array data is stored
// in a vector object; see
// Item 49 for info about
// the vector template
size_t size; // # of elements in array
int lBound, hBound; // lower bound, higher bound };
template<class T>
Array<T>::Array(int lowBound, int highBound)
: size(highBound - lowBound + 1),
lBound(lowBound), hBound(highBound),
data(size)
{}
An industrial-strength constructor would perform sanity checking on its parameters to ensure that highBound was at least as great as lowBound, but there is a much nastier error here: even with perfectly good values for the array's bounds, you have absolutely no idea how many elements data
"How can that be?" I hear you cry. "I carefully initialized size before passing it to the vector constructor!" Unfortunately, you didn't — you just tried to. The rules of the game are that class members are initialized in the order of their declaration in the class; the order in which they are listed in a member initialization list makes not a whit of difference. In the classes generated by your Array template, data will always be initialized first, followed by size, lBound, and hBound.
Perverse though this may seem, there is a reason for it. Consider this
class Wacko {
public:
Wacko(const char *s): s1(s), s2(0) {}
Wacko(const Wacko& rhs): s2(rhs.s1), s1(0) {}
private: string s1, s2; };
Wacko w1 = "Hello world!"; Wacko w2 = w1;
If members were initialized in the order of their appearance in an initialization list, the data members of w1 and w2 would be constructed in different orders. Recall that the destructors for the members of an object are always called in the inverse order of their constructors. Thus, if the above were allowed, compilers would have to keep track of the order in which the members were initialized for each object, just to ensure that the destructors would be called in the right order. That would be an expensive proposition. To avoid that overhead, the order of construction and destruction is the same for all objects of a given type, and the order of members in an initialization list is
Actually, if you really want to get picky about it, only nonstatic data members are initialized according to the rule. Static data members act like global and namespace objects, so they are initialized only once; see Item 47 for details. Furthermore, base class data members are initialized before derived class data members, so if you're using inheritance, you should list base class initializers at the very beginning of your member initialization lists. (If you're using multiple inheritance, your base classes will be initialized in the order in which you inherit from them; the order in which they're listed in your member initialization lists will again be ignored. However, if you're using multiple inheritance, you've probably got more important things to worry about. If you don't, Item 43 would be happy to make suggestions regarding aspects of multiple inheritance that are
The bottom line is this: if you hope to understand what is really going on when your objects are initialized, be sure to list the members in an initialization list in the order in which those members are declared in the
Item 14: Make sure base classes have virtual destructors.
Sometimes it's convenient for a class to keep track of how many objects of its type exist. The straightforward way to do this is to create a static class member for counting the objects. The member is initialized to 0, is incremented in the class constructors, and is decremented in the class destructor. (Item M26 shows how to package this approach so it's easy to add to any class, and my article on counting objects describes additional refinements to the
You might envision a military application, in which a class representing enemy targets might look something like
class EnemyTarget {
public:
EnemyTarget() { ++numTargets; }
EnemyTarget(const EnemyTarget&) { ++numTargets; }
~EnemyTarget() { --numTargets; }
static size_t numberOfTargets()
{ return numTargets; }
virtual bool destroy(); // returns success of
// attempt to destroy
// EnemyTarget object
private: static size_t numTargets; // object counter };
// class statics must be defined outside the class; // initialization is to 0 by default size_t EnemyTarget::numTargets;
This class is unlikely to win you a government defense contract, but it will suffice for our purposes here, which are substantially less demanding than are those of the Department of Defense. Or so we may
Let us suppose that a particular kind of enemy target is an enemy tank, which you model, naturally enough (see Item 35, but also see Item M33), as a publicly derived class of EnemyTarget. Because you are interested in the total number of enemy tanks as well as the total number of enemy targets, you'll pull the same trick with the derived class that you did with the base
class EnemyTank: public EnemyTarget {
public:
EnemyTank() { ++numTanks; }
EnemyTank(const EnemyTank& rhs)
: EnemyTarget(rhs)
{ ++numTanks; }
~EnemyTank() { --numTanks; }
static size_t numberOfTanks()
{ return numTanks; }
virtual bool destroy();
private: static size_t numTanks; // object counter for tanks };
Having now added this code to two different classes, you may be in a better position to appreciate Item M26's general solution to the
Finally, let's assume that somewhere in your application, you dynamically create an EnemyTank object using new, which you later get rid of via delete:
EnemyTarget *targetPtr = new EnemyTank;
...
delete targetPtr;
Everything you've done so far seems completely kosher. Both classes undo in the destructor what they did in the constructor, and there's certainly nothing wrong with your application, in which you were careful to use delete after you were done with the object you conjured up with new. Nevertheless, there is something very troubling here. Your program's behavior is undefined — you have no way of knowing what will
The EnemyTarget does), the results are undefined. That means compilers may generate code to do whatever they like: reformat your disk, send suggestive mail to your boss, fax source code to your competitors, whatever. (What often happens at runtime is that the derived class's destructor is never called. In this example, that would mean your count of EnemyTanks would not be adjusted when targetPtr was deleted. Your count of enemy tanks would thus be wrong, a rather disturbing prospect to combatants dependent on accurate battlefield
To avoid this problem, you have only to make the EnemyTarget destructor virtual. Declaring the destructor virtual ensures well-defined behavior that does precisely what you want: both EnemyTank's and EnemyTarget's destructors will be called before the memory holding the object is
Now, the EnemyTarget class contains a virtual function, which is generally the case with base classes. After all, the purpose of virtual functions is to allow customization of behavior in derived classes (see Item 36), so almost all base classes contain virtual
If a class does not contain any virtual functions, that is often an indication that it is not meant to be used as a base class. When a class is not intended to be used as a base class, making the destructor virtual is usually a bad idea. Consider this example, based on a discussion in the ARM (see Item 50):
// class for representing 2D points
class Point {
public:
Point(short int xCoord, short int yCoord);
~Point();
private: short int x, y; };
If a short int occupies 16 bits, a Point object can fit into a 32-bit register. Furthermore, a Point object can be passed as a 32-bit quantity to functions written in other languages such as C or FORTRAN. If Point's destructor is made virtual, however, the situation
The implementation of virtual functions requires that objects carry around with them some additional information that can be used at runtime to determine which virtual functions should be invoked on the object. In most compilers, this extra information takes the form of a pointer called a vptr ("virtual table pointer"). The vptr points to an array of function pointers called a vtbl ("virtual table"); each class with virtual functions has an associated vtbl. When a virtual function is invoked on an object, the actual function called is determined by following the object's vptr to a vtbl and then looking up the appropriate function pointer in the vtbl.
The details of how virtual functions are implemented are unimportant (though, if you're curious, you can read about them in Item M24). What is important is that if the Point class contains a virtual function, objects of that type will implicitly double in size, from two 16-bit shorts to two 16-bit shorts plus a 32-bit vptr! No longer will Point objects fit in a 32-bit register. Furthermore, Point objects in C++ no longer look like the same structure declared in another language such as C, because their foreign language counterparts will lack the vptr. As a result, it is no longer possible to pass Points to and from functions written in other languages unless you explicitly compensate for the vptr, which is itself an implementation detail and hence
The bottom line is that gratuitously declaring all destructors virtual is just as wrong as never declaring them virtual. In fact, many people summarize the situation this way: declare a virtual destructor in a class if and only if that class contains at least one virtual
This is a good rule, one that works most of the time, but unfortunately, it is possible to get bitten by the nonvirtual destructor problem even in the absence of virtual functions. For example, Item 13 considers a class template for implementing arrays with client-defined bounds. Suppose you decide (in spite of the advice in Item M33) to write a template for derived classes representing named arrays, i.e., classes where every array has a
template<class T> // base class template
class Array { // (from Item 13)
public:
Array(int lowBound, int highBound);
~Array();
private: vector<T> data; size_t size; int lBound, hBound; };
template<class T>
class NamedArray: public Array<T> {
public:
NamedArray(int lowBound, int highBound, const string& name);
...
private: string arrayName; };
If anywhere in an application you somehow convert a pointer-to-NamedArray into a pointer-to-Array and you then use delete on the Array pointer, you are instantly transported to the realm of undefined
NamedArray<int> *pna = new NamedArray<int>(10, 20, "Impending Doom");
Array<int> *pa;
...
pa = pna; // NamedArray<int>* -> Array<int>*
...
delete pa; // undefined! (Insert theme to
//° Twilight Zone here); in practice,
// pa->arrayName will often be leaked,
// because the NamedArray part of
// *pa will never be destroyed
This situation can arise more frequently than you might imagine, because it's not uncommon to want to take an existing class that does something, Array in this case, and derive from it a class that does all the same things, plus more. NamedArray doesn't redefine any of the behavior of Array — it inherits all its functions without change — it just adds some additional capabilities. Yet the nonvirtual destructor problem persists. (As do others. See Item M33.)
Finally, it's worth mentioning that it can be convenient to declare pure virtual destructors in some classes. Recall that pure virtual functions result in abstract classes — classes that can't be instantiated (i.e., you can't create objects of that type). Sometimes, however, you have a class that you'd like to be abstract, but you don't happen to have any functions that are pure virtual. What to do? Well, because an abstract class is intended to be used as a base class, and because a base class should have a virtual destructor, and because a pure virtual function yields an abstract class, the solution is simple: declare a pure virtual destructor in the class you want to be
class AWOV { // AWOV = "Abstract w/o
// Virtuals"
public:
virtual ~AWOV() = 0; // declare pure virtual
// destructor
};
This class has a pure virtual function, so it's abstract, and it has a virtual destructor, so you can rest assured that you won't have to worry about the destructor problem. There is one twist, however: you must provide a definition for the pure virtual
AWOV::~AWOV() {} // definition of pure
// virtual destructor
You need this definition, because the way virtual destructors work is that the most derived class's destructor is called first, then the destructor of each base class is called. That means that compilers will generate a call to ~AWOV even though the class is abstract, so you have to be sure to provide a body for the function. If you don't, the linker will complain about a missing symbol, and you'll have to go back and add
You can do anything you like in that function, but, as in the example above, it's not uncommon to have nothing to do. If that is the case, you'll probably be tempted to avoid paying the overhead cost of a call to an empty function by declaring your destructor inline. That's a perfectly sensible strategy, but there's a twist you should know
Because your destructor is virtual, its address must be entered into the class's vtbl (see Item M24). But inline functions aren't supposed to exist as freestanding functions (that's what inline means, right?), so special measures must be taken to get addresses for them. Item 33 tells the full story, but the bottom line is this: if you declare a virtual destructor inline, you're likely to avoid function call overhead when it's invoked, but your compiler will still have to generate an out-of-line copy of the function somewhere,
Item 15: Have operator= return a reference to *this.
Which brings us to assignment. With the built-in types, you can chain assignments together, like
int w, x, y, z;
w = x = y = z = 0;
As a result, you should be able to chain together assignments for user-defined types,
string w, x, y, z; // string is "user-defined"
// by the standard C++
// library (see Item 49)
w = x = y = z = "Hello";
As fate would have it, the assignment operator is right-associative, so the assignment chain is parsed like
w = (x = (y = (z = "Hello")));
It's worthwhile to write this in its completely equivalent functional form. Unless you're a closet LISP programmer, this example should make you grateful for the ability to define infix
w.operator=(x.operator=(y.operator=(z.operator=("Hello"))));
This form is illustrative because it emphasizes that the argument to w.operator=, x.operator=, and y.operator= is the return value of a previous call to operator=. As a result, the return type of operator= must be acceptable as an input to the function itself. For the default version of operator= in a class C, the signature of the function is as follows (see Item 45):
C& C::operator=(const C&);
You'll almost always want to follow this convention of having operator= both take and return a reference to a class object, although at times you may overload operator= so that it takes different argument types. For example, the standard string type provides two different versions of the assignment
string& // assign a string operator=(const string& rhs); // to a string
string& // assign a char* operator=(const char *rhs); // to a string
Notice, however, that even in the presence of overloading, the return type is a reference to an object of the
A common error amongst new C++ programmers is to have operator= return void, a decision that seems reasonable until you realize it prevents chains of assignment. So don't do
Another common error is to have operator= return a reference to a const object, like
class Widget {
public:
... // note
const Widget& operator=(const Widget& rhs); // const
... // return
}; // type
The usual motivation is to prevent clients from doing silly things like
Widget w1, w2, w3;
...
(w1 = w2) = w3; // assign w2 to w1, then w3 to
// the result! (Giving Widget's
// operator= a const return value
// prevents this from compiling.)
Silly this may be, but not so silly that it's prohibited for the built-in
int i1, i2, i3;
...
(i1 = i2) = i3; // legal! assigns i2 to
// i1, then i3 to i1!
I know of no practical use for this kind of thing, but if it's good enough for the ints, it's good enough for me and my classes. It should be good enough for you and yours, too. Why introduce gratuitous incompatibilities with the conventions followed by the built-in
Within an assignment operator bearing the default signature, there are two obvious candidates for the object to be returned: the object on the left hand side of the assignment (the one pointed to by this) and the object on the right-hand side (the one named in the parameter list). Which is
Here are the possibilities for a String class (a class for which you'd definitely want to write an assignment operator, as explained in Item 11):
String& String::operator=(const String& rhs)
{
...
return *this; // return reference
// to left-hand object
}
String& String::operator=(const String& rhs)
{
...
return rhs; // return reference to
// right-hand object
}
This might strike you as a case of six of one versus a half a dozen of the other, but there are important
First, the version returning rhs won't compile. That's because rhs is a reference-to-const-String, but operator= returns a reference-to-String. Compilers will give you no end of grief for trying to return a reference-to-non-const when the object itself is const. That seems easy enough to get around, however — just redeclare operator= like
String& String::operator=(String& rhs) { ... }
Alas, now the client code won't compile! Look again at the last part of the original chain of
x = "Hello"; // same as x.op=("Hello");
Because the right-hand argument of the assignment is not of the correct type — it's a char array, not a String — compilers would have to create a temporary String object (via the String constructor — see Item M19) to make the call succeed. That is, they'd have to generate code roughly equivalent to
const String temp("Hello"); // create temporary
x = temp; // pass temporary to op=
Compilers are willing to create such a temporary (unless the needed constructor is explicit — see Item 19), but note that the temporary object is const. This is important, because it prevents you from accidentally passing a temporary into a function that modifies its parameter. If that were allowed, programmers would be surprised to find that only the compiler-generated temporary was modified, not the argument they actually provided at the call site. (We know this for a fact, because early versions of C++ allowed these kinds of temporaries to be generated, passed, and modified, and the result was a lot of surprised
Now we can see why the client code above won't compile if String's operator= is declared to take a reference-to-non-const String: it's never legal to pass a const object to a function that fails to declare the corresponding parameter const. That's just simple const-correctness.
You thus find yourself in the happy circumstance of having no choice whatsoever: you'll always want to define your assignment operators in such a way that they return a reference to their left-hand argument, *this. If you do anything else, you prevent chains of assignments, you prevent implicit type conversions at call sites, or
Item 16: Assign to all data members in operator=.
Item 45 explains that C++ will write an assignment operator for you if you don't declare one yourself, and Item 11 describes why you often won't much care for the one it writes for you, so perhaps you're wondering if you can somehow have the best of both worlds, whereby you let C++ generate a default assignment operator and you selectively override those parts you don't like. No such luck. If you want to take control of any part of the assignment process, you must do the entire thing
In practice, this means that you need to assign to every data member of your object when you write your assignment
template<class T> // template for classes associating
class NamedPtr { // names with pointers (from Item 12)
public:
NamedPtr(const string& initName, T *initPtr);
NamedPtr& operator=(const NamedPtr& rhs);
private: string name; T *ptr; };
template<class T>
NamedPtr<T>& NamedPtr<T>::operator=(const NamedPtr<T>& rhs)
{
if (this == &rhs)
return *this; // see Item 17
// assign to all data members name = rhs.name; // assign to name
*ptr = *rhs.ptr; // for ptr, assign what's
// pointed to, not the
// pointer itself
return *this; // see Item 15 }
This is easy enough to remember when the class is originally written, but it's equally important that the assignment operator(s) be updated if new data members are added to the class. For example, if you decide to upgrade the NamedPtr template to carry a timestamp marking when the name was last changed, you'll have to add a new data member, and this will require updating the constructor(s) as well as the assignment operator(s). In the hustle and bustle of upgrading a class and adding new member functions, etc., it's easy to let this kind of thing slip your
The real fun begins when inheritance joins the party, because a derived class's assignment operator(s) must also handle assignment of its base class members! Consider
class Base {
public:
Base(int initialValue = 0): x(initialValue) {}
private: int x; };
class Derived: public Base {
public:
Derived(int initialValue)
: Base(initialValue), y(initialValue) {}
Derived& operator=(const Derived& rhs);
private: int y; };
The logical way to write Derived's assignment operator is like
// erroneous assignment operator
Derived& Derived::operator=(const Derived& rhs)
{
if (this == &rhs) return *this; // see Item 17
y = rhs.y; // assign to Derived's
// lone data member
return *this; // see Item 15 }
Unfortunately, this is incorrect, because the data member x in the Base part of a Derived object is unaffected by this assignment operator. For example, consider this code fragment:
void assignmentTester()
{
Derived d1(0); // d1.x = 0, d1.y = 0
Derived d2(1); // d2.x = 1, d2.y = 1
d1 = d2; // d1.x = 0, d1.y = 1! }
Notice how the Base part of d1 is unchanged by the
The straightforward way to fix this problem would be to make an assignment to x in Derived::operator=. Unfortunately, that's not legal, because x is a private member of Base. Instead, you have to make an explicit assignment to the Base part of Derived from inside Derived's assignment
// correct assignment operator
Derived& Derived::operator=(const Derived& rhs)
{
if (this == &rhs) return *this;
Base::operator=(rhs); // call this->Base::operator= y = rhs.y;
return *this; }
Here you just make an explicit call to Base::operator=. That call, like all calls to member functions from within other member functions, will use *this as its implicit left-hand object. The result will be that Base::operator= will do whatever work it does on the Base part of *this — precisely the effect you
Alas, some compilers (incorrectly) reject this kind of call to a base class's assignment operator if that assignment operator was generated by the compiler (see Item 45). To pacify these renegade translators, you need to implement Derived::operator= this
Derived& Derived::operator=(const Derived& rhs)
{
if (this == &rhs) return *this;
static_cast<Base&>(*this) = rhs; // call operator= on
// Base part of *this
y = rhs.y;
return *this; }
This monstrosity casts *this to be a reference to a Base, then makes an assignment to the result of the cast. That makes an assignment to only the Base part of the Derived object. Careful now! It is important that the cast be to a reference to a Base object, not to a Base object itself. If you cast *this to be a Base object, you'll end up calling the copy constructor for Base, and the new object you construct (see Item M19) will be the target of the assignment; *this will remain unchanged. Hardly what you
Regardless of which of these approaches you employ, once you've assigned the Base part of the Derived object, you then continue with Derived's assignment operator, making assignments to all the data members of Derived.
A similar inheritance-related problem often arises when implementing derived class copy constructors. Take a look at the following, which is the copy constructor analogue of the code we just
class Base {
public:
Base(int initialValue = 0): x(initialValue) {}
Base(const Base& rhs): x(rhs.x) {}
private: int x; };
class Derived: public Base {
public:
Derived(int initialValue)
: Base(initialValue), y(initialValue) {}
Derived(const Derived& rhs) // erroneous copy
: y(rhs.y) {} // constructor
private: int y; };
Class Derived demonstrates one of the nastiest bugs in all C++-dom: it fails to copy the base class part when a Derived object is copy constructed. Of course, the Base part of such a Derived object is constructed, but it's constructed using Base's default constructor. Its member x is initialized to 0 (the default constructor's default parameter value), regardless of the value of x in the object being
To avoid this problem, Derived's copy constructor must make sure that Base's copy constructor is invoked instead of Base's default constructor. That's easily done. Just be sure to specify an initializer value for Base in the member initialization list of Derived's copy
class Derived: public Base {
public:
Derived(const Derived& rhs): Base(rhs), y(rhs.y) {}
...
};
Now when a client creates a Derived by copying an existing object of that type, its Base part will be copied,
Item 17: Check for assignment to self in operator=.
An assignment to self occurs when you do something like
class X { ... };
X a;
a = a; // a is assigned to itself
This looks like a silly thing to do, but it's perfectly legal, so don't doubt for a moment that programmers do it. More importantly, assignment to self can appear in this more benign-looking
a = b;
If b is another name for a (for example, a reference that has been initialized to a), then this is also an assignment to self, though it doesn't outwardly look like it. This is an example of aliasing: having two or more names for the same underlying object. As you'll see at the end of this Item, aliasing can crop up in any number of nefarious disguises, so you need to take it into account any time you write a
Two good reasons exist for taking special care to cope with possible aliasing in assignment operator(s). The lesser of them is efficiency. If you can detect an assignment to self at the top of your assignment operator(s), you can return right away, possibly saving a lot of work that you'd otherwise have to go through to implement assignment. For example, Item 16 points out that a proper assignment operator in a derived class must call an assignment operator for each of its base classes, and those classes might themselves be derived classes, so skipping the body of an assignment operator in a derived class might save a large number of other function
A more important reason for checking for assignment to self is to ensure correctness. Remember that an assignment operator must typically free the resources allocated to an object (i.e., get rid of its old value) before it can allocate the new resources corresponding to its new value. When assigning to self, this freeing of resources can be disastrous, because the old resources might be needed during the process of allocating the new
Consider assignment of String objects, where the assignment operator fails to check for assignment to self:
class String {
public:
String(const char *value); // see Item 11 for
// function definition
~String(); // see Item 11 for
// function definition
...
String& operator=(const String& rhs);
private: char *data; };
// an assignment operator that omits a check
// for assignment to self
String& String::operator=(const String& rhs)
{
delete [] data; // delete old memory
// allocate new memory and copy rhs's value into it data = new char[strlen(rhs.data) + 1]; strcpy(data, rhs.data);
return *this; // see Item 15 }
Consider now what happens in this case:
String a = "Hello";
a = a; // same as a.operator=(a)
Inside the assignment operator, *this and rhs seem to be different objects, but in this case they happen to be different names for the same object. You can envision it like
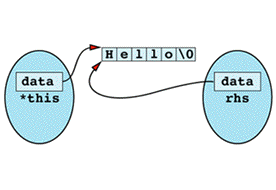
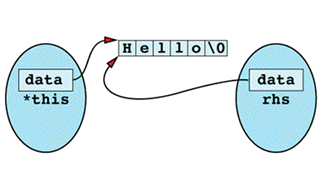
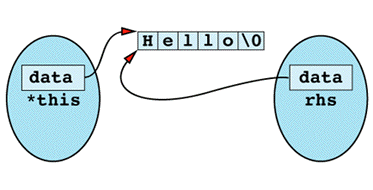
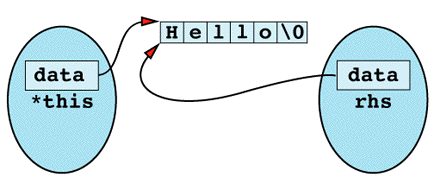
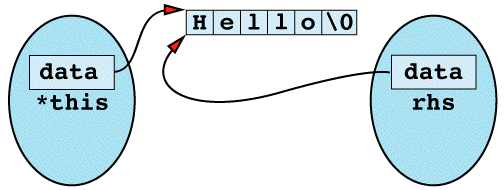
The first thing the assignment operator does is use delete on data, and the result is the following state of
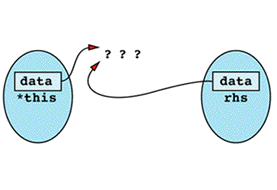
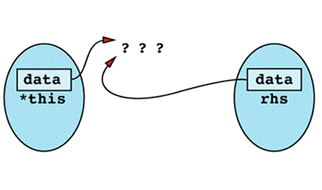
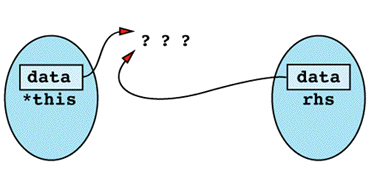
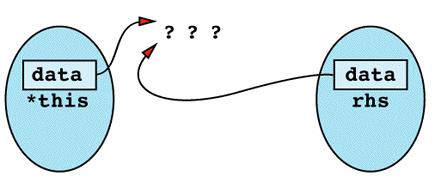

Now when the assignment operator tries to do a strlen on rhs.data, the results are undefined. This is because rhs.data was deleted when data was deleted, which happened because data, this->data, and rhs.data are all the same pointer! From this point on, things can only get
By now you know that the solution to the dilemma is to check for an assignment to self and to return immediately if such an assignment is detected. Unfortunately, it's easier to talk about such a check than it is to write it, because you are immediately forced to figure out what it means for two objects to be "the
The topic you confront is technically known as that of object identity, and it's a well-known topic in object-oriented circles. This book is no place for a discourse on object identity, but it is worthwhile to mention the two basic approaches to the
One approach is to say that two objects are the same (have the same identity) if they have the same value. For example, two String objects would be the same if they represented the same sequence of
String a = "Hello"; String b = "World"; String c = "Hello";
Here a and c have the same value, so they are considered identical; b is different from both of them. If you wanted to use this definition of identity in your String class, your assignment operator might look like
String& String::operator=(const String& rhs)
{
if (strcmp(data, rhs.data) == 0) return *this;
...
}
Value equality is usually determined by operator==, so the general form for an assignment operator for a class C that uses value equality for object identity is
C& C::operator=(const C& rhs)
{
// check for assignment to self
if (*this == rhs) // assumes op== exists
return *this;
...
}
Note that this function is comparing objects (via operator==), not pointers. Using value equality to determine identity, it doesn't matter whether two objects occupy the same memory; all that matters is the values they
The other possibility is to equate an object's identity with its address in memory. Using this definition of object equality, two objects are the same if and only if they have the same address. This definition is more common in C++ programs, probably because it's easy to implement and the computation is fast, neither of which is always true when object identity is based on values. Using address equality, a general assignment operator looks like
C& C::operator=(const C& rhs)
{
// check for assignment to self
if (this == &rhs) return *this;
...
}
This suffices for a great many
If you need a more sophisticated mechanism for determining whether two objects are the same, you'll have to implement it yourself. The most common approach is based on a member function that returns some kind of object
class C {
public:
ObjectID identity() const; // see also Item 36
...
};
Given object pointers a and b, then, the objects they point to are identical if and only if a->identity() == b->identity(). Of course, you are responsible for writing operator== for ObjectIDs.
The problems of aliasing and object identity are hardly confined to operator=. That's just a function in which you are particularly likely to run into them. In the presence of references and pointers, any two names for objects of compatible types may in fact refer to the same object. Here are some other situations in which aliasing can show its Medusa-like
class Base {
void mf1(Base& rb); // rb and *this could be
// the same
...
};
void f1(Base& rb1,Base& rb2); // rb1 and rb2 could be
// the same
class Derived: public Base {
void mf2(Base& rb); // rb and *this could be
// the same
...
};
int f2(Derived& rd, Base& rb); // rd and rb could be
// the same
These examples happen to use references, but pointers would serve just as
As you can see, aliasing can crop up in a variety of guises, so you can't just forget about it and hope you'll never run into it. Well, maybe you can, but most of us can't. At the expense of mixing my metaphors, this is a clear case in which an ounce of prevention is worth its weight in gold. Anytime you write a function in which aliasing could conceivably be present, you must take that possibility into account when you write the