Classes and Functions: Design and Declaration
Declaring a new class in a program creates a new type: class design is type design. You probably don't have much experience with type design, because most languages don't offer you the opportunity to get any practice. In C++, it is of fundamental importance, not just because you can do it if you want to, but because you are doing it every time you declare a class, whether you mean to or
Designing good classes is challenging because designing good types is challenging. Good types have a natural syntax, an intuitive semantics, and one or more efficient implementations. In C++, a poorly thought out class definition can make it impossible to achieve any of these goals. Even the performance characteristics of a class's member functions are determined as much by the declarations of those member functions as they are by their
How, then, do you go about designing effective classes? First, you must understand the issues you face. Virtually every class requires that you confront the following questions, the answers to which often lead to constraints on your
operator new, operator new[] operator delete, and operator delete[] explicit constructor in class B that can be called with a single argument. If you wish to allow explicit conversions only, you'll want to write functions to perform the conversions, but you'll want to avoid making them type conversion operators or non-explicit single-argument constructors. (Item M5 discusses the advantages and disadvantages of user-defined conversion functions.)
private.
These are difficult questions to answer, so defining effective classes in C++ is far from simple. Done properly, however, user-defined classes in C++ yield types that are all but indistinguishable from built-in types, and that makes all the effort
A discussion of the details of each of the above issues would comprise a book in its own right, so the guidelines that follow are anything but comprehensive. However, they highlight some of the most important design considerations, warn about some of the most frequent errors, and provide solutions to some of the most common problems encountered by class designers. Much of the advice is as applicable to non-member functions as it is to member functions, so in this section I consider the design and declaration of global and namespace-resident functions,
Item 18: Strive for class interfaces that are complete and minimal.
The client interface for a class is the interface that is accessible to the programmers who use the class. Typically, only functions exist in this interface, because having data members in the client interface has a number of drawbacks (see Item 20).
Trying to figure out what functions should be in a class interface can drive you crazy. You're pulled in two completely different directions. On the one hand, you'd like to build a class that is easy to understand, straightforward to use, and easy to implement. That usually implies a fairly small number of member functions, each of which performs a distinct task. On other hand, you'd like your class to be powerful and convenient to use, which often means adding functions to provide support for commonly performed tasks. How do you decide which functions go into the class and which ones
Try this: aim for a class interface that is complete and minimal.
A complete interface is one that allows clients to do anything they might reasonably want to do. That is, for any reasonable task that clients might want to accomplish, there is a reasonable way to accomplish it, although it may not be as convenient as clients might like. A minimal interface, on the other hand, is one with as few functions in it as possible, one in which no two member functions have overlapping functionality. If you offer a complete, minimal interface, clients can do whatever they want to do, but the class interface is no more complicated than absolutely
The desirability of a complete interface seems obvious enough, but why a minimal interface? Why not just give clients everything they ask for, adding functionality until everyone is
Aside from the moral issue — is it really right to mollycoddle your clients? — there are definite technical disadvantages to a class interface that is crowded with functions. First, the more functions in an interface, the harder it is for potential clients to understand. The harder it is for them to understand, the more reluctant they will be to learn how to use it. A class with 10 functions looks tractable to most people, but a class with 100 functions is enough to make many programmers run and hide. By expanding the functionality of your class to make it as attractive as possible, you may actually end up discouraging people from learning how to use
A large interface can also lead to confusion. Suppose you create a class that supports cognition for an artificial intelligence application. One of your member functions is called think, but you later discover that some people want the function to be called ponder, and others prefer the name ruminate. In an effort to be accommodating, you offer all three functions, even though they do the same thing. Consider then the plight of a potential client of your class who is trying to figure things out. The client is faced with three different functions, all of which are supposed to do the same thing. Can that really be true? Isn't there some subtle difference between the three, possibly in efficiency or generality or reliability? If not, why are there three different functions? Rather than appreciating your flexibility, such a potential client is likely to wonder what on earth you were thinking (or pondering, or ruminating
A second disadvantage to a large class interface is that of maintenance (see Item M32). It's simply more difficult to maintain and enhance a class with many functions than it is a class with few. It is more difficult to avoid duplicated code (with the attendant duplicated bugs), and it is more difficult to maintain consistency across the interface. It's also more difficult to
Finally, long class definitions result in long header files. Because header files typically have to be read every time a program is compiled (see Item 34), class definitions that are longer than necessary can incur a substantial penalty in total compile-time over the life of a
The long and short of it is that the gratuitous addition of functions to an interface is not without costs, so you need to think carefully about whether the convenience of a new function (a new function can only be added for convenience if the interface is already complete) justifies the additional costs in complexity, comprehensibility, maintainability, and compilation
Yet there's no sense in being unduly miserly. It is often justifiable to offer more than a minimal set of functions. If a commonly performed task can be implemented much more efficiently as a member function, that may well justify its addition to the interface. (Then again, it may not. See Item M16.) If the addition of a member function makes the class substantially easier to use, that may be enough to warrant its inclusion in the class. And if adding a member function is likely to prevent client errors, that, too, is a powerful argument for its being part of the
Consider a concrete example: a template for classes that implement arrays with client-defined upper and lower bounds and that offer optional bounds-checking. The beginning of such an array template is shown
template<class T>
class Array {
public:
enum BoundsCheckingStatus {NO_CHECK_BOUNDS = 0,
CHECK_BOUNDS = 1};
Array(int lowBound, int highBound,
BoundsCheckingStatus check = NO_CHECK_BOUNDS);
Array(const Array& rhs);
~Array();
Array& operator=(const Array& rhs);
private: int lBound, hBound; // low bound, high bound
vector<T> data; // contents of array; see
// Item 49 for vector info
BoundsCheckingStatus checkingBounds; };
The member functions declared so far are the ones that require basically no thinking (or pondering or ruminating). You have a constructor to allow clients to specify each array's bounds, a copy constructor, an assignment operator, and a destructor. In this case, you've declared the destructor nonvirtual, which implies that this class is not to be used as a base class (see Item 14).
The declaration of the assignment operator is actually less clear-cut than it might at first appear. After all, built-in arrays in C++ don't allow assignment, so you might want to disallow it for your Array objects, too (see Item 27). On the other hand, the array-like vector template (in the standard library — see Item 49) permits assignments between vector objects. In this example, you'll follow vector's lead, and that decision, as you'll see below, will affect other portions of the classes's
Old-time C hacks would cringe to see this interface. Where is the support for declaring an array of a particular size? It would be easy enough to add another
Array(int size,
BoundsCheckingStatus check = NO_CHECK_BOUNDS);
but this is not part of a minimal interface, because the constructor taking an upper and lower bound can be used to accomplish the same thing. Nonetheless, it might be a wise political move to humor the old geezers, possibly under the rubric of consistency with the base
What other functions do you need? Certainly it is part of a complete interface to index into an
// return element for read/write T& operator[](int index);
// return element for read-only const T& operator[](int index) const;
By declaring the same function twice, once const and once non-const, you provide support for both const and non-const Array objects. The difference in return types is significant, as is explained in Item 21.
As it now stands, the Array template supports construction, destruction, pass-by-value, assignment, and indexing, which may strike you as a complete interface. But look closer. Suppose a client wants to loop through an array of integers, printing out each of its elements, like
Array<int> a(10, 20); // bounds on a are 10 to 20
...
for (int i = lower bound of a; i <= upper bound of a; ++i) cout << "a[" << i << "] = " << a[i] << '\n';
How is the client to get the bounds of a? The answer depends on what happens during assignment of Array objects, i.e., on what happens inside Array::operator=. In particular, if assignment can change the bounds of an Array object, you must provide member functions to return the current bounds, because the client has no way of knowing a priori what the bounds are at any given point in the program. In the example above, if a was the target of an assignment between the time it was defined and the time it was used in the loop, the client would have no way to determine the current bounds of a.
On the other hand, if the bounds of an Array object cannot be changed during assignment, then the bounds are fixed at the point of definition, and it would be possible (though cumbersome) for a client to keep track of these bounds. In that case, though it would be convenient to offer functions to return the current bounds, such functions would not be part of a truly minimal
Proceeding on the assumption that assignment can modify the bounds of an object, the bounds functions could be declared
int lowBound() const; int highBound() const;
Because these functions don't modify the object on which they are invoked, and because you prefer to use const whenever you can (see Item 21), these are both declared const member functions. Given these functions, the loop above would be written as
for (int i = a.lowBound(); i <= a.highBound(); ++i) cout << "a[" << i << "] = " << a[i] << '\n';
Needless to say, for such a loop to work for an array of objects of type T, an operator<< function must be defined for objects of type T. (That's not quite true. What must exist is an operator<< for T or for some other type to which T may be implicitly converted (see Item M5). But you get the
Some designers would argue that the Array class should also offer a function to return the number of elements in an Array object. The number of elements is simply highBound()-lowBound()+1, so such a function is not really necessary, but in view of the frequency of off-by-one errors, it might not be a bad idea to add such a
Other functions that might prove worthwhile for this class include those for input and output, as well as the various relational operators (e.g., <, >, ==, etc.). None of those functions is part of a minimal interface, however, because they can all be implemented in terms of loops containing calls to operator[].
Speaking of functions like operator<<, operator>>, and the relational operators, Item 19 discusses why they are frequently implemented as non-member friend functions instead of as member functions. That being the case, don't forget that friend functions are, for all practical purposes, part of a class's interface. That means that friend functions count toward a class interface's completeness and
Item 19: Differentiate among member functions, non-member functions, and friend functions.
The biggest difference between member functions and non-member functions is that member functions can be virtual and non-member functions can't. As a result, if you have a function that has to be dynamically bound (see Item 38), you've got to use a virtual function, and that virtual function must be a member of some class. It's as simple as that. If your function doesn't need to be virtual, however, the water begins to muddy a
Consider a class for representing rational
class Rational {
public:
Rational(int numerator = 0, int denominator = 1);
int numerator() const;
int denominator() const;
private: ... };
As it stands now, this is a pretty useless class. (Using the terms of Item 18, the interface is certainly minimal, but it's far from complete.) You know you'd like to support arithmetic operations like addition, subtraction, multiplication, etc., but you're unsure whether you should implement them via a member function, a non-member function, or possibly a non-member function that's a
When in doubt, be object-oriented. You know that, say, multiplication of rational numbers is related to the Rational class, so try bundling the operation with the class by making it a member
class Rational {
public:
...
const Rational operator*(const Rational& rhs) const; };
(If you're unsure why this function is declared the way it is — returning a const by-value result, but taking a reference-to-const as its argument — consult Items 21-23.)
Now you can multiply rational numbers with the greatest of
Rational oneEighth(1, 8); Rational oneHalf(1, 2);
Rational result = oneHalf * oneEighth; // fine
result = result * oneEighth; // fine
But you're not satisfied. You'd also like to support mixed-mode operations, where Rationals can be multiplied with, for example, ints. When you try to do this, however, you find that it works only half the
result = oneHalf * 2; // fine
result = 2 * oneHalf; // error!
This is a bad omen. Multiplication is supposed to be commutative,
The source of the problem becomes apparent when you rewrite the last two examples in their equivalent functional
result = oneHalf.operator*(2); // fine
result = 2.operator*(oneHalf); // error!
The object oneHalf is an instance of a class that contains an operator*, so your compilers call that function. However, the integer 2 has no associated class, hence no operator* member function. Your compilers will also look for a non-member operator* (i.e., one that's in a visible namespace or is global) that can be called like
result = operator*(2, oneHalf); // error!
but there is no non-member operator* taking an int and a Rational, so the search
Look again at the call that succeeds. You'll see that its second parameter is the integer 2, yet Rational::operator* takes a Rational object as its argument. What's going on here? Why does 2 work in one position and not in the
What's going on is implicit type conversion. Your compilers know you're passing an int and the function requires a Rational, but they also know that they can conjure up a suitable Rational by calling the Rational constructor with the int you provided, so that's what they do (see Item M19). In other words, they treat the call as if it had been written more or less like
const Rational temp(2); // create a temporary
// Rational object from 2
result = oneHalf * temp; // same as
// oneHalf.operator*(temp);
Of course, they do this only when non-explicit constructors are involved, because explicit constructors can't be used for implicit conversions; that's what explicit means. If Rational were defined like
class Rational {
public:
explicit Rational(int numerator = 0, // this ctor is
int denominator = 1); // now explicit
...
const Rational operator*(const Rational& rhs) const;
...
};
neither of these statements would
result = oneHalf * 2; // error! result = 2 * oneHalf; // error!
That would hardly qualify as support for mixed-mode arithmetic, but at least the behavior of the two statements would be
The Rational class we've been examining, however, is designed to allow implicit conversions from built-in types to Rationals — that's why Rational's constructor isn't declared explicit. That being the case, compilers will perform the implicit conversion necessary to allow result's first assignment to compile. In fact, your handy-dandy compilers will perform this kind of implicit type conversion, if it's needed, on every parameter of every function call. But they will do it only for parameters listed in the parameter list, never for the object on which a member function is invoked, i.e., the object corresponding to *this inside a member function. That's why this call
result = oneHalf.operator*(2); // converts int -> Rationaland this one does not:
result = 2.operator*(oneHalf); // doesn't convert
// int -> Rational
The first case involves a parameter listed in the function declaration, but the second one does
Nonetheless, you'd still like to support mixed-mode arithmetic, and the way to do it is by now perhaps clear: make operator* a non-member function, thus allowing compilers to perform implicit type conversions on all
class Rational {
... // contains no operator*
};
// declare this globally or within a namespace; see
// Item M20 for why it's written as it is
const Rational operator*(const Rational& lhs,
const Rational& rhs)
{
return Rational(lhs.numerator() * rhs.numerator(),
lhs.denominator() * rhs.denominator());
}
Rational oneFourth(1, 4); Rational result;
result = oneFourth * 2; // fine result = 2 * oneFourth; // hooray, it works!
This is certainly a happy ending to the tale, but there is a nagging worry. Should operator* be made a friend of the Rational
In this case, the answer is no, because operator* can be implemented entirely in terms of the class's public interface. The code above shows one way to do it. Whenever you can avoid friend functions, you should, because, much as in real life, friends are often more trouble than they're
However, it's not uncommon for functions that are not members, yet are still conceptually part of a class interface, to need access to the non-public members of the
As an example, let's fall back on a workhorse of this book, the String class. If you try to overload operator>> and operator<< for reading and writing String objects, you'll quickly discover that they shouldn't be member functions. If they were, you'd have to put the String object on the left when you called the
// a class that incorrectly declares operator>> and
// operator<< as member functions
class String {
public:
String(const char *value);
...
istream& operator>>(istream& input); ostream& operator<<(ostream& output);
private: char *data; };
String s;
s >> cin; // legal, but contrary
// to convention
s << cout; // ditto
That would confuse everyone. As a result, these functions shouldn't be member functions. Notice that this is a different case from the one we discussed above. Here the goal is a natural calling syntax; earlier we were concerned about implicit type
If you were designing these functions, you'd come up with something like
istream& operator>>(istream& input, String& string)
{
delete [] string.data;
read from input into some memory, and make string.data point to it
return input; }
ostream& operator<<(ostream& output,
const String& string)
{
return output << string.data;
}
Notice that both functions need access to the data field of the String class, a field that's private. However, you already know that you have to make these functions non-members. You're boxed into a corner and have no choice: non-member functions with a need for access to non-public members of a class must be made friends of that
The lessons of this Item are summarized below, in which it is assumed that f is the function you're trying to declare properly and C is the class to which it is conceptually
f needs to be virtual, make it a member function of C.
operator>> and operator<< are never members. If f is operator>> or operator<<, make f a non-member function. If, in addition, f needs access to non-public members of C, make f a friend of C.
f needs type conversions on its left-most argument, make f a non-member function. If, in addition, f needs access to non-public members of C, make f a friend of C.
f a member function of C.
Item 20: Avoid data members in the public interface.
First, let's look at this issue from the point of view of consistency. If everything in the public interface is a function, clients of your class won't have to scratch their heads trying to remember whether to use parentheses when they want to access a member of your class. They'll just do it, because everything is a function. Over the course of a lifetime, that can save a lot of head
You don't buy the consistency argument? How about the fact that using functions gives you much more precise control over the accessibility of data members? If you make a data member public, everybody has read/write access to it, but if you use functions to get and set its value, you can implement no access, read-only access, and read-write access. Heck, you can even implement write-only access if you want
class AccessLevels {
public:
int getReadOnly() const{ return readOnly; }
void setReadWrite(int value) { readWrite = value; }
int getReadWrite() const { return readWrite; }
void setWriteOnly(int value) { writeOnly = value; }
private: int noAccess; // no access to this int
int readOnly; // read-only access to
// this int
int readWrite; // read-write access to
// this int
int writeOnly; // write-only access to
// this int
};
Still not convinced? Then it's time to bring out the big gun: functional abstraction. If you implement access to a data member through a function, you can later replace the data member with a computation, and nobody using your class will be any the
For example, suppose you are writing an application in which some automated equipment is monitoring the speed of passing cars. As each car passes, its speed is computed, and the value is added to a collection of all the speed data collected so
class SpeedDataCollection {
public:
void addValue(int speed); // add a new data value
double averageSoFar() const; // return average speed };
Now consider the implementation of the member function averageSoFar (see also Item M18). One way to implement it is to have a data member in the class that is a running average of all the speed data so far collected. Whenever averageSoFar is called, it just returns the value of that data member. A different approach is to have averageSoFar compute its value anew each time it's called, something it could do by examining each data value in the collection. (For a more general discussion of these two approaches, see Items M17 and M18.)
The first approach — keeping a running average — makes each SpeedDataCollection object bigger, because you have to allocate space for the data member holding the running average. However, averageSoFar can be implemented very efficiently; it's just an inline function (see Item 33) that returns the value of the data member. Conversely, computing the average whenever it's requested will make averageSoFar run slower, but each SpeedDataCollection object will be
Who's to say which is best? On a machine where memory is tight, and in an application where averages are needed only infrequently, computing the average each time is a better solution. In an application where averages are needed frequently, speed is of the essence, and memory is not an issue, keeping a running average is preferable. The important point is that by accessing the average through a member function, you can use either implementation, a valuable source of flexibility that you wouldn't have if you made a decision to include the running average data member in the public
The upshot of all this is that you're just asking for trouble by putting data members in the public interface, so play it safe by hiding all your data members behind a wall of functional abstraction. If you do it now, we'll throw in consistency and fine-grained access control at no extra
Item 21: Use const whenever possible.
The wonderful thing about const is that it allows you to specify a certain semantic constraint — a particular object should not be modified — and compilers will enforce that constraint. It allows you to communicate to both compilers and other programmers that a value should remain invariant. Whenever that is true, you should be sure to say so explicitly, because that way you enlist your compilers' aid in making sure the constraint isn't
The const keyword is remarkably versatile. Outside of classes, you can use it for global or namespace constants (see Items 1 and 47) and for static objects (local to a file or a block). Inside classes, you can use it for both static and nonstatic data members (see also Item 12).
For pointers, you can specify whether the pointer itself is const, the data it points to is const, both, or
char *p = "Hello"; // non-const pointer,
// non-const data4
const char *p = "Hello"; // non-const pointer,
// const data
char * const p = "Hello"; // const pointer,
// non-const data
const char * const p = "Hello"; // const pointer,
// const data
This syntax isn't quite as capricious as it looks. Basically, you mentally draw a vertical line through the asterisk of a pointer declaration, and if the word const appears to the left of the line, what's pointed to is constant; if the word const appears to the right of the line, the pointer itself is constant; if const appears on both sides of the line, both are
When what's pointed to is constant, some programmers list const before the type name. Others list it after the type name but before the asterisk. As a result, the following functions take the same parameter
class Widget { ... };
void f1(const Widget *pw); // f1 takes a pointer to a
// constant Widget object
void f2(Widget const *pw); // so does f2
Because both forms exist in real code, you should accustom yourself to both of
Some of the most powerful uses of const stem from its application to function declarations. Within a function declaration, const can refer to the function's return value, to individual parameters, and, for member functions, to the function as a
Having a function return a constant value often makes it possible to reduce the incidence of client errors without giving up safety or efficiency. In fact, as Item 29 demonstrates, using const with a return value can make it possible to improve the safety and efficiency of a function that would otherwise be
For example, consider the declaration of the operator* function for rational numbers that is introduced in Item 19:
const Rational operator*(const Rational& lhs,
const Rational& rhs);
Many programmers squint when they first see this. Why should the result of operator* be a const object? Because if it weren't, clients would be able to commit atrocities like
Rational a, b, c;
...
(a * b) = c; // assign to the product
// of a*b!
I don't know why any programmer would want to make an assignment to the product of two numbers, but I do know this: it would be flat-out illegal if a, b, and c were of a built-in type. One of the hallmarks of good user-defined types is that they avoid gratuitous behavioral incompatibilities with the built-ins, and allowing assignments to the product of two numbers seems pretty gratuitous to me. Declaring operator*'s return value const prevents it, and that's why It's The Right Thing To
There's nothing particularly new about const parameters — they act just like local const objects. (See Item M19, however, for a discussion of how const parameters can lead to the creation of temporary objects.) Member functions that are const, however, are a different
The purpose of const member functions, of course, is to specify which member functions may be invoked on const objects. Many people overlook the fact that member functions differing only in their constness can be overloaded, however, and this is an important feature of C++. Consider the String class once
class String {
public:
...
// operator[] for non-const objects
char& operator[](int position)
{ return data[position]; }
// operator[] for const objects
const char& operator[](int position) const
{ return data[position]; }
private: char *data; };
String s1 = "Hello";
cout << s1[0]; // calls non-const
// String::operator[]
const String s2 = "World";
cout << s2[0]; // calls const
// String::operator[]
By overloading operator[] and giving the different versions different return values, you are able to have const and non-const Strings handled
String s = "Hello"; // non-const String object
cout << s[0]; // fine — reading a
// non-const String
s[0] = 'x'; // fine — writing a
// non-const String
const String cs = "World"; // const String object
cout << cs[0]; // fine — reading a
// const String
cs[0] = 'x'; // error! — writing a
// const String
By the way, note that the error here has only to do with the return value of the operator[] that is called; the calls to operator[] themselves are all fine. The error arises out of an attempt to make an assignment to a const char&, because that's the return value from the const version of operator[].
Also note that the return type of the non-const operator[] must be a reference to a char — a char itself will not do. If operator[] did return a simple char, statements like this wouldn't
s[0] = 'x';
That's because it's never legal to modify the return value of a function that returns a built-in type. Even if it were legal, the fact that C++ returns objects by value (see Item 22) would mean that a copy of s.data[0] would be modified, not s.data[0] itself, and that's not the behavior you want,
Let's take a brief time-out for philosophy. What exactly does it mean for a member function to be const? There are two prevailing notions: bitwise constness and conceptual
The bitwise const camp believes that a member function is const if and only if it doesn't modify any of the object's data members (excluding those that are static), i.e., if it doesn't modify any of the bits inside the object. The nice thing about bitwise constness is that it's easy to detect violations: compilers just look for assignments to data members. In fact, bitwise constness is C++'s definition of constness, and a const member function isn't allowed to modify any of the data members of the object on which it is
Unfortunately, many member functions that don't act very const pass the bitwise test. In particular, a member function that modifies what a pointer points to frequently doesn't act const. But if only the pointer is in the object, the function is bitwise const, and compilers won't complain. That can lead to counterintuitive
class String {
public:
// the constructor makes data point to a copy
// of what value points to
String(const char *value);
...
operator char *() const { return data;}
private: char *data; };
const String s = "Hello"; // declare constant object
char *nasty = s; // calls op char*() const
*nasty = 'M'; // modifies s.data[0]
cout << s; // writes "Mello"
Surely there is something wrong when you create a constant object with a particular value and you invoke only const member functions on it, yet you are still able to change its value! (For a more detailed discussion of this example, see Item 29.)
This leads to the notion of conceptual constness. Adherents to this philosophy argue that a const member function might modify some of the bits in the object on which it's invoked, but only in ways that are undetectable by clients. For example, your String class might want to cache the length of the object whenever it's requested (see Item M18):
class String {
public:
// the constructor makes data point to a copy
// of what value points to
String(const char *value): lengthIsValid(false) { ... }
...
size_t length() const;
private: char *data;
size_t dataLength; // last calculated length
// of string
bool lengthIsValid; // whether length is
// currently valid
};
size_t String::length() const
{
if (!lengthIsValid) {
dataLength = strlen(data); // error!
lengthIsValid = true; // error!
}
return dataLength; }
This implementation of length is certainly not bitwise const — both dataLength and lengthIsValid may be modified — yet it seems as though it should be valid for const String objects. Compilers, you will find, respectfully disagree; they insist on bitwise constness. What to
The solution is simple: take advantage of the const-related wiggle room the mutable. When applied to nonstatic data members, mutable frees those members from the constraints of bitwise
class String {
public:
... // same as above
private: char *data;
mutable size_t dataLength; // these data members are
// now mutable; they may be
mutable bool lengthIsValid; // modified anywhere, even
// inside const member
}; // functions
size_t String::length() const
{
if (!lengthIsValid) {
dataLength = strlen(data); // now fine
lengthIsValid = true; // also fine
}
return dataLength; }
mutable is a wonderful solution to the bitwise-constness-is-not-quite-what-I-had-in-mind problem, but it was added to C++ relatively late in the standardization process, so your compilers may not support it yet. If that's the case, you must descend into the dark recesses of C++, where life is cheap and constness may be cast
Inside a member function of class C, the this pointer behaves as if it had been declared as
C * const this; // for non-const member
// functions
const C * const this; // for const member
// functions
That being the case, all you have to do to make the problematic version of String::length (i.e., the one you could fix with mutable if your compilers supported it) valid for both const and non-const objects is to change the type of this from const C * const to C * const. You can't do that directly, but you can fake it by initializing a local pointer to point to the same object as this does. Then you can access the members you want to modify through the local
size_t String::length() const
{
// make a local version of this that's
// not a pointer-to-const
String * const localThis =
const_cast<String * const>(this);
if (!lengthIsValid) {
localThis->dataLength = strlen(data);
localThis->lengthIsValid = true;
}
return dataLength; }
Pretty this ain't, but sometimes a programmer's just gotta do what a programmer's gotta
Unless, of course, it's not guaranteed to work, and sometimes the old cast-away-constness trick isn't. In particular, if the object this points to is truly const, i.e., was declared const at its point of definition, the results of casting away its constness are undefined. If you want to cast away constness in one of your member functions, you'd best be sure that the object you're doing the casting on wasn't originally defined to be const.
There is one other time when casting away constness may be both useful and safe. That's when you have a const object you want to pass to a function taking a non-const parameter, and you know the parameter won't be modified inside the function. The second condition is important, because it is always safe to cast away the constness of an object that will only be read — not written — even if that object was originally defined to be const.
For example, some libraries have been known to incorrectly declare the strlen function as
size_t strlen(char *s);
Certainly strlen isn't going to modify what s points to — at least not the strlen I grew up with. Because of this declaration, however, it would be invalid to call it on pointers of type const char *. To get around the problem, you can safely cast away the constness of such pointers when you pass them to strlen:
const char *klingonGreeting = "nuqneH"; // "nuqneH" is
// "Hello" in
// Klingon
size_t length =
strlen(const_cast<char*>(klingonGreeting));
Don't get cavalier about this, though. It is guaranteed to work only if the function being called, strlen in this case, doesn't try to modify what its parameter points
Item 22: Prefer pass-by-reference to pass-by-value.
In C, everything is passed by value, and C++ honors this heritage by adopting the pass-by-value convention as its default. Unless you specify otherwise, function parameters are initialized with copies of the actual arguments, and function callers get back a copy of the value returned by the
As I pointed out in the Introduction to this book, the meaning of passing an object by value is defined by the copy constructor of that object's class. This can make pass-by-value an extremely expensive operation. For example, consider the following (rather contrived) class
class Person {
public:
Person(); // parameters omitted for
// simplicity
~Person();
...
private: string name, address; };
class Student: public Person {
public:
Student(); // parameters omitted for
// simplicity
~Student();
...
private: string schoolName, schoolAddress; };
Now consider a simple function returnStudent that takes a Student argument (by value) and immediately returns it (also by value), plus a call to that
Student returnStudent(Student s) { return s; }
Student plato; // Plato studied under
// Socrates
returnStudent(plato); // call returnStudent
What happens during the course of this innocuous-looking function
The simple explanation is this: the Student copy constructor is called to initialize s with plato. Then the Student copy constructor is called again to initialize the object returned by the function with s. Next, the destructor is called for s. Finally, the destructor is called for the object returned by returnStudent. So the cost of this do-nothing function is two calls to the Student copy constructor and two calls to the Student
But wait, there's more! A Student object has two string objects within it, so every time you construct a Student object you must also construct two string objects. A Student object also inherits from a Person object, so every time you construct a Student object you must also construct a Person object. A Person object has two additional string objects inside it, so each Person construction also entails two more string constructions. The end result is that passing a Student object by value leads to one call to the Student copy constructor, one call to the Person copy constructor, and four calls to the string copy constructor. When the copy of the Student object is destroyed, each constructor call is matched by a destructor call, so the overall cost of passing a Student by value is six constructors and six destructors. Because the function returnStudent uses pass-by-value twice (once for the parameter, once for the return value), the complete cost of a call to that function is twelve constructors and twelve
In fairness to the C++ compiler-writers of the world, this is a worst-case scenario. Compilers are allowed to eliminate some of these calls to copy constructors. (The
To avoid this potentially exorbitant cost, you need to pass things not by value, but by
const Student& returnStudent(const Student& s)
{ return s; }
This is much more efficient: no constructors or destructors are called, because no new objects are being
Passing parameters by reference has another advantage: it avoids what is sometimes called the "slicing problem." When a derived class object is passed as a base class object, all the specialized features that make it behave like a derived class object are "sliced" off, and you're left with a simple base class object. This is almost never what you want. For example, suppose you're working on a set of classes for implementing a graphical window
class Window {
public:
string name() const; // return name of window
virtual void display() const; // draw window and contents
};
class WindowWithScrollBars: public Window {
public:
virtual void display() const;
};
All Window objects have a name, which you can get at through the name function, and all windows can be displayed, which you can bring about by invoking the display function. The fact that display is virtual tells you that the way in which simple base class Window objects are displayed is apt to differ from the way in which the fancy, high-priced WindowWithScrollBars objects are displayed (see Items 36, 37, and M33).
Now suppose you'd like to write a function to print out a window's name and then display the window. Here's the wrong way to write such a
// a function that suffers from the slicing problem
void printNameAndDisplay(Window w)
{
cout << w.name();
w.display();
}
Consider what happens when you call this function with a WindowWithScrollBars
WindowWithScrollBars wwsb;
printNameAndDisplay(wwsb);
The parameter w will be constructed — it's passed by value, remember? — as a Window object, and all the specialized information that made wwsb act like a WindowWithScrollBars object will be sliced off. Inside printNameAndDisplay, w will always act like an object of class Window (because it is an object of class Window), regardless of the type of object that is passed to the function. In particular, the call to display inside printNameAndDisplay will always call Window::display, never WindowWithScrollBars::display.
The way around the slicing problem is to pass w by
// a function that doesn't suffer from the slicing problem
void printNameAndDisplay(const Window& w)
{
cout << w.name();
w.display();
}
Now w will act like whatever kind of window is actually passed in. To emphasize that w isn't modified by this function even though it's passed by reference, you've followed the advice of Item 21 and carefully declared it to be const; how good of
Passing by reference is a wonderful thing, but it leads to certain complications of its own, the most notorious of which is aliasing, a topic that is discussed in Item 17. In addition, it's important to recognize that you sometimes can't pass things by reference; see Item 23. Finally, the brutal fact of the matter is that references are almost always implemented as pointers, so passing something by reference usually means really passing a pointer. As a result, if you have a small object — an int, for example — it may actually be more efficient to pass it by value than to pass it by
Item 23: Don't try to return a reference when you must return an object.
It is said that Albert Einstein once offered this advice: make things as simple as possible, but no simpler. The C++ analogue might well be to make things as efficient as possible, but no more
Once programmers grasp the efficiency implications of pass-by-value for objects (see Item 22), they become crusaders, determined to root out the evil of pass-by-value wherever it may hide. Unrelenting in their pursuit of pass-by-reference purity, they invariably make a fatal mistake: they start to pass references to objects that don't exist. This is not a good
Consider a class for representing rational numbers, including a friend function (see Item 19) for multiplying two rationals
class Rational {
public:
Rational(int numerator = 0, int denominator = 1);
...
private: int n, d; // numerator and denominator
friend
const Rational // see Item 21 for why
operator*(const Rational& lhs, // the return value is
const Rational& rhs) // const
};
inline const Rational operator*(const Rational& lhs,
const Rational& rhs)
{
return Rational(lhs.n * rhs.n, lhs.d * rhs.d);
}
Clearly, this version of operator* is returning its result object by value, and you'd be shirking your professional duties if you failed to worry about the cost of that object's construction and destruction. Another thing that's clear is that you're cheap and you don't want to pay for such a temporary object (see Item M19) if you don't have to. So the question is this: do you have to
Well, you don't have to if you can return a reference instead. But remember that a reference is just a name, a name for some existing object. Whenever you see the declaration for a reference, you should immediately ask yourself what it is another name for, because it must be another name for something (see Item M1). In the case of operator*, if the function is to return a reference, it must return a reference to some other Rational object that already exists and that contains the product of the two objects that are to be multiplied
There is certainly no reason to expect that such an object exists prior to the call to operator*. That is, if you
Rational a(1, 2); // a = 1/2 Rational b(3, 5); // b = 3/5 Rational c = a * b; // c should be 3/10
it seems unreasonable to expect that there already exists a rational number with the value three-tenths. No, if operator* is to return a reference to such a number, it must create that number object
A function can create a new object in only two ways: on the stack or on the heap. Creation on the stack is accomplished by defining a local variable. Using that strategy, you might try to write your operator* as
// the first wrong way to write this function
inline const Rational& operator*(const Rational& lhs,
const Rational& rhs)
{
Rational result(lhs.n * rhs.n, lhs.d * rhs.d);
return result;
}
You can reject this approach out of hand, because your goal was to avoid a constructor call, and result will have to be constructed just like any other object. In addition, this function has a more serious problem in that it returns a reference to a local object, an error that is discussed in depth in Item 31.
That leaves you with the possibility of constructing an object on the heap and then returning a reference to it. Heap-based objects come into being through the use of new. This is how you might write operator* in that
// the second wrong way to write this function
inline const Rational& operator*(const Rational& lhs,
const Rational& rhs)
{
Rational *result =
new Rational(lhs.n * rhs.n, lhs.d * rhs.d);
return *result;
}
Well, you still have to pay for a constructor call, because the memory allocated by new is initialized by calling an appropriate constructor (see Items 5 and M8), but now you have a different problem: who will apply delete to the object that was conjured up by your use of new?
In fact, this is a guaranteed memory leak. Even if callers of operator* could be persuaded to take the address of the function's result and use delete on it (astronomically unlikely — Item 31 shows what the code would have to look like), complicated expressions would yield unnamed temporaries that programmers would never be able to get at. For example,
Rational w, x, y, z;
w = x * y * z;
both calls to operator* yield unnamed temporaries that the programmer never sees, hence can never delete. (Again, see Item 31.)
But perhaps you think you're smarter than the average bear — or the average programmer. Perhaps you notice that both the on-the-stack and the on-the-heap approaches suffer from having to call a constructor for each result returned from operator*. Perhaps you recall that our initial goal was to avoid such constructor invocations. Perhaps you think you know of a way to avoid all but one constructor call. Perhaps the following implementation occurs to you, an implementation based on operator* returning a reference to a static Rational object, one defined inside the
// the third wrong way to write this function
inline const Rational& operator*(const Rational& lhs,
const Rational& rhs)
{
static Rational result; // static object to which a
// reference will be returned
somehow multiply lhs and rhs and put the resulting value inside result;
return result; }
This looks promising, though when you try to compose real C++ for the italicized pseudocode above, you'll find that it's all but impossible to give result the correct value without invoking a Rational constructor, and avoiding such a call is the whole reason for this game. Let us posit that you manage to find a way, however, because no amount of cleverness can ultimately save this star-crossed
To see why, consider this perfectly reasonable client
bool operator==(const Rational& lhs, // an operator==
const Rational& rhs); // for Rationals
Rational a, b, c, d;
...
if ((a * b) == (c * d)) {
do whatever's appropriate when the products are equal;
} else {
do whatever's appropriate when they're not;
}
Now ponder this: the expression ((a*b) == (c*d)) will always evaluate to true, regardless of the values of a, b, c, and d!
It's easiest to understand this vexing behavior by rewriting the test for equality in its equivalent functional
if (operator==(operator*(a, b), operator*(c, d)))
Notice that when operator== is called, there will already be two active calls to operator*, each of which will return a reference to the static Rational object inside operator*. Thus, operator== will be asked to compare the value of the static Rational object inside operator* with the value of the static Rational object inside operator*. It would be surprising indeed if they did not compare equal.
With luck, this is enough to convince you that returning a reference from a function like operator* is a waste of time, but I'm not so naive as to believe that luck is always sufficient. Some of you — and you know who you are — are at this very moment thinking, "Well, if one static isn't enough, maybe a static array will do the
Stop. Please. Haven't we suffered enough
I can't bring myself to dignify this design with example code, but I can sketch why even entertaining the notion should cause you to blush in shame. First, you must choose n, the size of the array. If n is too small, you may run out of places to store function return values, in which case you'll have gained nothing over the single-static design we just discredited. But if n is too big, you'll decrease the performance of your program, because every object in the array will be constructed the first time the function is called. That will cost you n constructors and n destructors, even if the function in question is called only once. If "optimization" is the process of improving software performance, this kind of thing should be called "pessimization." Finally, think about how you'd put the values you need into the array's objects and what it would cost you to do it. The most direct way to move a value between objects is via assignment, but what is the cost of an assignment? In general, it's about the same as a call to a destructor (to destroy the old value) plus a call to a constructor (to copy over the new value). But your goal is to avoid the costs of construction and destruction! Face it: this approach just isn't going to pan
No, the right way to write a function that must return a new object is to have that function return a new object. For Rational's operator*, that means either the following code (which we first saw back on page 102) or something essentially
inline const Rational operator*(const Rational& lhs,
const Rational& rhs)
{
return Rational(lhs.n * rhs.n, lhs.d * rhs.d);
}
Sure, you may incur the cost of constructing and destructing operator*'s return value, but in the long run, that's a small price to pay for correct behavior. Besides, the bill that so terrifies you may never arrive. Like all programming languages, C++ allows compiler implementers to apply certain optimizations to improve the performance of the generated code, and it turns out that in some cases, operator*'s return value can be safely eliminated (see Item M20). When compilers take advantage of that fact (and current compilers often do), your program continues to behave the way it's supposed to, it just does it faster than you
It all boils down to this: when deciding between returning a reference and returning an object, your job is to make the choice that does the right thing. Let your compiler vendors wrestle with figuring out how to make that choice as inexpensive as
Item 24: Choose carefully between function overloading and parameter defaulting.
The confusion over function overloading and parameter defaulting stems from the fact that they both allow a single function name to be called in more than one
void f(); // f is overloaded void f(int x);
f(); // calls f() f(10); // calls f(int)
void g(int x = 0); // g has a default
// parameter value
g(); // calls g(0) g(10); // calls g(10)
The answer depends on two other questions. First, is there a value you can use for a default? Second, how many algorithms do you want to use? In general, if you can choose a reasonable default value and you want to employ only a single algorithm, you'll use default parameters (see also Item 38). Otherwise you'll use function
Here's a function to compute the maximum of up to five ints. This function uses — take a deep breath and steel yourself — std::numeric_limits<int>::min() as a default parameter value. I'll have more to say about that in a moment, but first, here's the
int max(int a,
int b = std::numeric_limits<int>::min(),
int c = std::numeric_limits<int>::min(),
int d = std::numeric_limits<int>::min(),
int e = std::numeric_limits<int>::min())
{
int temp = a > b ? a : b;
temp = temp > c ? temp : c;
temp = temp > d ? temp : d;
return temp > e ? temp : e;
}
Now, calm yourself. std::numeric_limits<int>::min() is just the fancy new-fangled way the standard C++ library says what C says via the INT_MIN macro in <limits.h>: it's the minimum possible value for an int in whatever compiler happens to be processing your C++ source code. True, it's a deviation from the terseness for which C is renowned, but there's a method behind all those colons and other syntactic
Suppose you'd like to write a function template taking any built-in numeric type as its parameter, and you'd like the functions generated from the template to print the minimum value representable by their instantiation type. Your template would look something like
template<class T>
void printMinimumValue()
{
cout << the minimum value representable by T;
}
This is a difficult function to write if all you have to work with is <limits.h> and <float.h>. You don't know what T is, so you don't know whether to print out INT_MIN or DBL_MIN or
To sidestep these difficulties, the standard C++ library (see Item 49) defines in the header <limits> a class template, numeric_limits, which itself defines several static member functions. Each function returns information about the type instantiating the template. That is, the functions in numeric_limits<int> return information about type int, the functions in numeric_limits<double> return information about type double, etc. Among the functions in numeric_limits is min. min returns the minimum representable value for the instantiating type, so numeric_limits<int>::min() returns the minimum representable integer
Given numeric_limits (which, like nearly everything in the standard library, is in namespace std — see Item 28; numeric_limits itself is in the header <limits>), writing printMinimumValue is as easy as can
template<class T>
void printMinimumValue()
{
cout << std::numeric_limits<T>::min();
}
This numeric_limits-based approach to specifying type-dependent constants may look expensive, but it's not. That's because the long-windedness of the source code fails to be reflected in the resultant object code. In fact, calls to functions in numeric_limits generate no instructions at all. To see how that can be, consider the following, which is an obvious way to implement numeric_limits<int>::min:
#include <limits.h>
namespace std {
inline int numeric_limits<int>::min() throw ()
{ return INT_MIN; }
}
Because this function is declared inline, calls to it should be replaced by its body (see Item 33). That's just INT_MIN, which is itself a simple #define for some implementation-defined constant. So even though the max function at the beginning of this Item looks like it's making a function call for each default parameter value, it's just using a clever way of referring to a type-dependent constant, in this case the value of INT_MIN. Such efficient cleverness abounds in C++'s standard library. You really should read Item 49.
Getting back to the max function, the crucial observation is that max uses the same (rather inefficient) algorithm to compute its result, regardless of the number of arguments provided by the caller. Nowhere in the function do you attempt to figure out which parameters are "real" and which are defaults. Instead, you have chosen a default value that cannot possibly affect the validity of the computation for the algorithm you're using. That's what makes the use of default parameter values a viable
For many functions, there is no reasonable default value. For example, suppose you want to write a function to compute the average of up to five ints. You can't use default parameter values here, because the result of the function is dependent on the number of parameters passed in: if 3 values are passed in, you'll divide their sum by 3; if 5 values are passed in, you'll divide their sum by 5. Furthermore, there is no "magic number" you can use as a default to indicate that a parameter wasn't actually provided by the client, because all possible ints are valid values for the parameters. In this case, you have no choice: you must use overloaded
double avg(int a); double avg(int a, int b); double avg(int a, int b, int c); double avg(int a, int b, int c, int d); double avg(int a, int b, int c, int d, int e);
The other case in which you need to use overloaded functions occurs when you want to accomplish a particular task, but the algorithm that you use depends on the inputs that are given. This is commonly the case with constructors: a default constructor will construct an object from scratch, whereas a copy constructor will construct one from an existing
// A class for representing natural numbers
class Natural {
public:
Natural(int initValue);
Natural(const Natural& rhs);
private: unsigned int value;
void init(int initValue); void error(const string& msg); };
inline
void Natural::init(int initValue) { value = initValue; }
Natural::Natural(int initValue)
{
if (initValue > 0) init(initValue);
else error("Illegal initial value");
}
inline Natural::Natural(const Natural& x)
{ init(x.value); }
The constructor taking an int has to perform error checking, but the copy constructor doesn't, so two different functions are needed. That means overloading. However, note that both functions must assign an initial value for the new object. This could lead to code duplication in the two constructors, so you maneuver around that problem by writing a private member function init that contains the code common to the two constructors. This tactic — using overloaded functions that call a common underlying function for some of their work — is worth remembering, because it's frequently useful (see e.g., Item 12).
Item 25: Avoid overloading on a pointer and a numerical type.
Trivia question for the day: what is
More specifically, what will happen
void f(int x); void f(string *ps);
f(0); // calls f(int) or f(string*)?
The answer is that 0 is an int — a literal integer constant, to be precise — so f(int) will always be called. Therein lies the problem, because that's not what people always want. This is a situation unique in the world of C++: a place where people think a call should be ambiguous, but compilers do
It would be nice if you could somehow tiptoe around this problem by use of a symbolic name, say, NULL for null pointers, but that turns out to be a lot tougher than you might
Your first inclination might be to declare a constant called NULL, but constants have types, and what type should NULL have? It needs to be compatible with all pointer types, but the only type satisfying that requirement is void*, and you can't pass void* pointers to typed pointers without an explicit cast. Not only is that ugly, at first glance it's not a whole lot better than the original
void * const NULL = 0; // potential NULL definition
f(0); // still calls f(int) f(static_cast<string*>(NULL)); // calls f(string*) f(static_cast<string*>(0)); // calls f(string*)
On second thought, however, the use of NULL as a void* constant is a shade better than what you started with, because you avoid ambiguity if you use only NULL to indicate null
f(0); // calls f(int) f(NULL); // error! — type mis-match f(static_cast<string*>(NULL)); // okay, calls f(string*)
At least now you've traded a runtime error (the call to the "wrong" f for 0) for a compile-time error (the attempt to pass a void* into a string* parameter). This improves matters somewhat (see Item 46), but the cast is still
If you shamefacedly crawl back to the preprocessor, you find that it doesn't really offer a way out, either, because the obvious choices seem to
#define NULL 0and
#define NULL ((void*) 0)
and the first possibility is just the literal 0, which is fundamentally an integer constant (your original problem, as you'll recall), while the second possibility gets you back into the trouble with passing void* pointers to typed
If you've boned up on the rules governing type conversions, you may know that C++ views a conversion from a long int to an int as neither better nor worse than a conversion from the long int 0 to the null pointer. You can take advantage of that to introduce the ambiguity into the int/pointer question you probably believe should be there in the first
#define NULL 0L // NULL is now a long int
void f(int x); void f(string *p);
f(NULL); // error! — ambiguous
However, this fails to help if you overload on a long int and a
#define NULL 0L
void f(long int x); // this f now takes a long void f(string *p);
f(NULL); // fine, calls f(long int)
In practice, this is probably safer than defining NULL to be an int, but it's more a way of moving the problem around than of eliminating
The problem can be exterminated, but it requires the use of a late-breaking addition to the language: member function templates (often simply called member templates). Member function templates are exactly what they sound like: templates within classes that generate member functions for those classes. In the case of NULL, you want an object that acts like the expression static_cast<T*>(0) for every type T. That suggests that NULL should be an object of a class containing an implicit conversion operator for every possible pointer type. That's a lot of conversion operators, but a member template lets you force C++ into generating them for
// a first cut at a class yielding NULL pointer objects
class NullClass {
public:
template<class T> // generates
operator T*() const { return 0; } // operator T* for
}; // all types T; each
// function returns
// the null pointer
const NullClass NULL; // NULL is an object of
// type NullClass
void f(int x); // same as we originally had
void f(string *p); // ditto
f(NULL); // fine, converts NULL to
// string*, then calls f(string*)
This is a good initial draft, but it can be refined in several ways. First, we don't really need more than one NullClass object, so there's no reason to give the class a name; we can just use an anonymous class and make NULL of that type. Second, as long as we're making it possible to convert NULL to any type of pointer, we should handle pointers to members, too. That calls for a second member template, one to convert 0 to type T C::* ("pointer to member of type T in class C") for all classes C and all types T. (If that makes no sense to you, or if you've never heard of — much less used — pointers to members, relax. Pointers to members are uncommon beasts, rarely seen in the wild, and you'll probably never have to deal with them. The terminally curious may wish to consult Item 30, which discusses pointers to members in a bit more detail.) Finally, we should prevent clients from taking the address of NULL, because NULL isn't supposed to act like a pointer, it's supposed to act like a pointer value, and pointer values (e.g., 0x453AB002) don't have
The jazzed-up NULL definition looks like
const // this is a const object...
class {
public:
template<class T> // convertible to any type
operator T*() const // of null non-member
{ return 0; } // pointer...
template<class C, class T> // or any type of null
operator T C::*() const // member pointer...
{ return 0; }
private:
void operator&() const; // whose address can't be
// taken (see Item 27)...
} NULL; // and whose name is NULL
This is truly a sight to behold, though you may wish to make a minor concession to practicality by giving the class a name after all. If you don't, compiler messages referring to NULL's type are likely to be pretty
For another example of how member templates can be useful, take a look at Item M28.
An important point about all these attempts to come up with a workable NULL is that they help only if you're the caller. If you're the author of the functions being called, having a foolproof NULL won't help you at all, because you can't compel your callers to use it. For example, even if you offer your clients the space-age NULL we just developed, you still can't keep them from doing
f(0); // still calls f(int),
// because 0 is still an int
and that's just as problematic now as it was at the beginning of this
As a designer of overloaded functions, then, the bottom line is that you're best off avoiding overloading on a numerical and a pointer type if you can possibly avoid
Item 26: Guard against potential ambiguity.
Everybody has to have a philosophy. Some people believe in laissez faire economics, others believe in reincarnation. Some people even believe that COBOL is a real programming language. C++ has a philosophy, too: it believes that potential ambiguity is not an
Here's an example of potential
class B; // forward declaration for
// class B
class A {
public:
A(const B&); // an A can be
// constructed from a B
};
class B {
public:
operator A() const; // a B can be
// converted to an A
};
There's nothing wrong with these class declarations — they can coexist in the same program without the slightest trouble. However, look what happens when you combine these classes with a function that takes an A object, but is actually passed a B
void f(const A&);
B b;
f(b); // error! — ambiguous
Seeing the call to f, compilers know they must somehow come up with an object of type A, even though what they have in hand is an object of type B. There are two equally good ways to do this (see Item M5). On one hand, the class A constructor could be called; this would construct a new A object using b as an argument. On the other hand, b could be converted into an A object by calling the client-defined conversion operator in class B. Because these two approaches are considered equally good, compilers refuse to choose between
Of course, you could use this program for some time without ever running across the ambiguity. That's the insidious peril of potential ambiguity. It can lie dormant in a program for long periods of time, undetected and inactive, until the day when some unsuspecting programmer does something that actually is ambiguous, at which point pandemonium breaks out. This gives rise to the disconcerting possibility that you might release a library that can be called ambiguously without even being aware that you're doing
A similar form of ambiguity arises from standard conversions in the language — you don't even need any
void f(int); void f(char);
double d = 6.02;
f(d); // error! — ambiguous
Should d be converted into an int or a char? The conversions are equally good, so compilers won't judge. Fortunately, you can get around this problem by using an explicit
f(static_cast<int>(d)); // fine, calls f(int) f(static_cast<char>(d)); // fine, calls f(char)
Multiple inheritance (see Item 43) is rife with possibilities for potential ambiguity. The most straightforward case occurs when a derived class inherits the same member name from more than one base
class Base1 {
public:
int doIt();
};
class Base2 {
public:
void doIt();
};
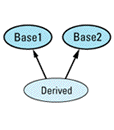
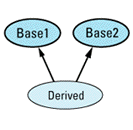
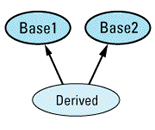
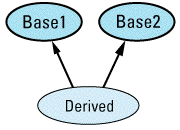
class Derived: public Base1, // Derived doesn't declare
public Base2 { // a function called doIt
...
};
Derived d;
d.doIt(); // error! — ambiguous
When class Derived inherits two functions with the same name, C++ utters not a whimper; at this point the ambiguity is only potential. However, the call to doIt forces compilers to face the issue, and unless you explicitly disambiguate the call by specifying which base class function you want, the call is an
d.Base1::doIt(); // fine, calls Base1::doIt
d.Base2::doIt(); // fine, calls Base2::doIt
That doesn't upset too many people, but the fact that accessibility restrictions don't enter into the picture has caused more than one otherwise pacifistic soul to contemplate distinctly unpacifistic
class Base1 { ... }; // same as above
class Base2 {
private:
void doIt(); // this function is now
}; // private
class Derived: public Base1, public Base2
{ ... }; // same as above
Derived d;
int i = d.doIt(); // error! — still ambiguous!
The call to doIt continues to be ambiguous, even though only the function in Base1 is accessible! The fact that only Base1::doIt returns a value that can be used to initialize an int is also irrelevant — the call remains ambiguous. If you want to make this call, you simply must specify which class's doIt is the one you
As is the case for most initially unintuitive rules in C++, there is a good reason why access restrictions are not taken into account when disambiguating references to multiply inherited members. It boils down to this: changing the accessibility of a class member should never change the meaning of a
For example, assume that in the previous example, access restrictions were taken into account. Then the expression d.doIt() would resolve to a call to Base1::doIt, because Base2's version was inaccessible. Now assume that Base1 was changed so that its version of doIt was protected instead of public, and Base2 was changed so that its version was public instead of
Suddenly the same expression, d.doIt(), would result in a completely different function call, even though neither the calling code nor the functions had been modified! Now that's unintuitive, and there would be no way for compilers to issue even a warning. Considering your choices, you may decide that having to explicitly disambiguate references to multiply inherited members isn't quite as unreasonable as you originally
Given that there are all these different ways to write programs and libraries harboring potential ambiguity, what's a good software developer to do? Primarily, you need to keep an eye out for it. It's next to impossible to root out all the sources of potential ambiguity, particularly when programmers combine libraries that were developed independently (see also Item 28), but by understanding the situations that often lead to potential ambiguity, you're in a better position to minimize its presence in the software you design and
Item 27: Explicitly disallow use of implicitly generated member functions you don't want.
Suppose you want to write a class template, Array, whose generated classes behave like built-in C++ arrays in every way, except they perform bounds checking. One of the design problems you would face is how to prohibit assignment between Array objects, because assignment isn't legal for C++
double values1[10]; double values2[10];
values1 = values2; // error!
For most functions, this wouldn't be a problem. If you didn't want to allow a function, you simply wouldn't put it in the class. However, the assignment operator is one of those distinguished member functions that C++, always the helpful servant, writes for you if you neglect to write it yourself (see Item 45). What then to
The solution is to declare the function, operator= in this case, private. By declaring a member function explicitly, you prevent compilers from generating their own version, and by making the function private, you keep people from calling
However, the scheme isn't foolproof; member and friend functions can still call your private function. Unless, that is, you are clever enough not to define the function. Then if you inadvertently call the function, you'll get an error at link-time (see Item 46).
For Array, your template definition would start out like
template<class T>
class Array {
private:
// Don't define this function!
Array& operator=(const Array& rhs);
...
};
Now if a client tries to perform assignments on Array objects, compilers will thwart the attempt, and if you inadvertently try it in a member or a friend function, the linker will
Don't assume from this example that this Item applies only to assignment operators. It doesn't. It applies to each of the compiler-generated functions described in Item 45. In practice, you'll find that the behavioral similarities between assignment and copy construction (see Items 11 and 16) almost always mean that anytime you want to disallow use of one, you'll want to disallow use of the other,
Item 28: Partition the global namespace.
The biggest problem with the global scope is that there's only one of them. In a large software project, there is usually a bevy of people putting names in this singular scope, and invariably this leads to name conflicts. For example, library1.h might define a number of constants, including the
const double LIB_VERSION = 1.204;
const int LIB_VERSION = 3;
It doesn't take great insight to see that there is going to be a problem if a program tries to include both library1.h and library2.h. Unfortunately, outside of cursing under your breath, sending hate mail to the library authors, and editing the header files until the name conflicts are eliminated, there is little you can do about this kind of
You can, however, take pity on the poor souls who'll have your libraries foisted on them. You probably already prepend some hopefully-unique prefix to each of your global symbols, but surely you must admit that the resulting identifiers are less than pleasing to gaze
A better solution is to use a C++ namespace. Boiled down to its essence, a namespace is just a fancy way of letting you use the prefixes you know and love without making people look at them all the time. So instead of
const double sdmBOOK_VERSION = 2.0; // in this library,
// each symbol begins
class sdmHandle { ... }; // with "sdm"
sdmHandle& sdmGetHandle(); // see Item 47 for why you
// might want to declare
// a function like this
you write namespace sdm {
const double BOOK_VERSION = 2.0;
class Handle { ... };
Handle& getHandle();
}
Clients then access symbols in your namespace in any of the usual three ways: by importing all the symbols in a namespace into a scope, by importing individual symbols into a scope, or by explicitly qualifying a symbol for one-time use. Here are some
void f1()
{
using namespace sdm; // make all symbols in sdm
// available w/o qualification
// in this scope
cout << BOOK_VERSION; // okay, resolves to
// sdm::BOOK_VERSION
...
Handle h = getHandle(); // okay, Handle resolves to
// sdm::Handle, getHandle
... // resolves to sdm::getHandle
}
void f2()
{
using sdm::BOOK_VERSION; // make only BOOK_VERSION
// available w/o qualification
// in this scope
cout << BOOK_VERSION; // okay, resolves to
// sdm::BOOK_VERSION
...
Handle h = getHandle(); // error! neither Handle
// nor getHandle were
... // imported into this scope
}
void f3()
{
cout << sdm::BOOK_VERSION; // okay, makes BOOK_VERSION
// available for this one use
... // only
double d = BOOK_VERSION; // error! BOOK_VERSION is
// not in scope
Handle h = getHandle(); // error! neither Handle
// nor getHandle were
... // imported into this scope
}
(Some namespaces have no names. Such unnamed namespaces are used to limit the visibility of the elements inside the namespace. For details, see Item M31.)
One of the nicest things about namespaces is that potential ambiguity is not an error (see Item 26). As a result, you can import the same symbol from more than one namespace, yet still live a carefree life (provided you never actually use the symbol). For instance, if, in addition to namespace sdm, you had need to make use of this
namespace AcmeWindowSystem {
...
typedef int Handle;
...
}
you could use both sdm and AcmeWindowSystem without conflict, provided you never referenced the symbol Handle. If you did refer to it, you'd have to explicitly say which namespace's Handle you
void f()
{
using namespace sdm; // import sdm symbols
using namespace AcmeWindowSystem; // import Acme symbols
... // freely refer to sdm
// and Acme symbols
// other than Handle
Handle h; // error! which Handle?
sdm::Handle h1; // fine, no ambiguity
AcmeWindowSystem::Handle h2; // also no ambiguity
...
}
Contrast this with the conventional header-file-based approach, where the mere inclusion of both sdm.h and acme.h would cause compilers to complain about multiple definitions of the symbol Handle.
Namespaces were added to C++ relatively late in the standardization game, so perhaps you think they're not that important and you can live without them. You can't. You can't, because almost everything in the standard library (see Item 49) lives inside the namespace std. That may strike you as a minor detail, but it affects you in a very direct manner: it's why C++ now sports funny-looking extensionless header names like <iostream>, <string>, etc. For details, turn to Item 49.
Because namespaces were introduced comparatively recently, your compilers might not yet support them. If that's the case, there's still no reason to pollute the global namespace, because you can approximate namespaces with structs. You do it by creating a struct to hold your global names, then putting your global names inside this struct as static
// definition of a struct emulating a namespace
struct sdm {
static const double BOOK_VERSION;
class Handle { ... };
static Handle& getHandle();
};
const double sdm::BOOK_VERSION = 2.0; // obligatory defn
// of static data
// member
Now when people want to access your global names, they simply prefix them with the struct
void f()
{
cout << sdm::BOOK_VERSION;
...
sdm::Handle h = sdm::getHandle();
... }
If there are no name conflicts at the global level, clients of your library may find it cumbersome to use the fully qualified names. Fortunately, there is a way you can let them have their scopes and ignore them,
For your type names, provide typedefs that remove the need for explicit scoping. That is, for a type name T in your namespace-like struct S, provide a (global) typedef such that T is a synonym for S::T:
typedef sdm::Handle Handle;
For each (static) object X in your struct, provide a (global) reference X that is initialized with S::X:
const double& BOOK_VERSION = sdm::BOOK_VERSION;
Frankly, after you've read Item 47, the thought of defining a non-local static object like BOOK_VERSION will probably make you queasy. (You'll want to replace such objects with the functions described in Item 47.)
Functions are treated much like objects, but even though it's legal to define references to functions, future maintainers of your code will dislike you a lot less if you employ pointers to functions
sdm::Handle& (* const getHandle)() = // getHandle is a
sdm::getHandle; // const pointer (see
// Item 21) to
// sdm::getHandle
Note that getHandle is a const pointer. You don't really want to let clients make it point to something other than sdm::getHandle, do
(If you're dying to know how to define a reference to a function, this should revitalize
sdm::Handle& (&getHandle)() = // getHandle is a reference sdm::getHandle; // to sdm::getHandle
Personally, I think this is kind of cool, but there's a reason you've probably never seen this before. Except for how they're initialized, references to functions and const pointers to functions behave identically, and pointers to functions are much more readily
Given these typedefs and references, clients not suffering from global name conflicts can just use the unqualified type and object names, while clients who do have conflicts can ignore the typedef and reference definitions and use fully qualified names. It's unlikely that all your clients will want to use the shorthand names, so you should be sure to put the typedefs and references in a different header file from the one containing your namespace-emulating
structs are a nice approximation to namespaces, but they're a long trek from the real thing. They fall short in a variety of ways, one of the most obvious of which is their treatment of operators. Simply put, operators defined as static member functions of structs can be invoked only through a function call, never via the natural infix syntax that operators are designed to
// define a namespace-emulating struct containing
// types and functions for Widgets. Widget objects
// support addition via operator+
struct widgets {
class Widget { ... };
// see Item 21 for why the return value is const
static const Widget operator+(const Widget& lhs,
const Widget& rhs);
...
};
// attempt to set up global (unqualified) names for // Widget and operator+ as described above
typedef widgets::Widget Widget;
const Widget (* const operator+)(const Widget&, // error!
const Widget&); // operator+
// can't be a
// pointer name
Widget w1, w2, sum;
sum = w1 + w2; // error! no operator+
// taking Widgets is
// declared at this
// scope
sum = widgets::operator+(w1, w2); // legal, but hardly
// "natural" syntax
Such limitations should spur you to adopt real namespaces as soon as your compilers make it
"Hello" is const char [], a type that's almost always treated as const char*. We'd therefore expect it to be a violation of const correctness to initialize a char* variable with a string literal like "Hello". The practice is so common in C, however, that the standard grants a special dispensation for initializations like this. Nevertheless, you should try to avoid them, because they're deprecated.