Classes and Functions: Implementation
Because C++ is strongly typed, coming up with appropriate definitions for your classes and templates and appropriate declarations for your functions is the lion's share of the battle. Once you've got those right, it's hard to go wrong with the template, class, and function implementations. Yet, somehow, people manage to do
Some problems arise from inadvertently violating abstraction: accidentally allowing implementation details to peek out from behind the class and function boundaries that are supposed to contain them. Others originate in confusion over the length of an object's lifetime. Still others stem from premature optimization, typically traceable to the seductive nature of the inline keyword. Finally, some implementation strategies, while fine on a local scale, result in levels of coupling between source files that can make it unacceptably costly to rebuild large
Each of these problems, as well as others like them, can be avoided if you know what to watch out for. The items that follow identify some situations in which you need to be especially
Item 29: Avoid returning "handles" to internal data.
A scene from an object-oriented
Yet just as in real life, A wonders, "Can B be trusted?" And just as in real life, the answer often hinges on B's nature: the constitution of its member
Suppose B is a constant String
class String {
public:
String(const char *value); // see Item 11 for pos-
~String(); // sible implementations;
// see Item M5 for comments
// on the first constructor
operator char *() const; // convert String -> char*;
// see also Item M5
...
private:
char *data;
};
const String B("Hello World"); // B is a const object
Because B is const, it had better be the case that the value of B now and evermore is "Hello World". Of course, this supposes that programmers working with B are playing the game in a civilized fashion. In particular, it depends on the fact that nobody is "casting away the constness" of B through nefarious ploys such as this (see Item 21):
String& alsoB = // make alsoB another name
const_cast<String&>(B); // for B, but without the
// constness
Given that no one is doing such evil deeds, however, it seems a safe bet that B will never change. Or does it? Consider this sequence of
char *str = B; // calls B.operator char*()
strcpy(str, "Hi Mom"); // modifies what str
// points to
Does B still have the value "Hello World", or has it suddenly mutated into something you might say to your mother? The answer depends entirely on the implementation of String::operator char*.
Here's a careless implementation, one that does the wrong thing. However, it does it very efficiently, which is why so many programmers fall into this
// a fast, but incorrect implementation
inline String::operator char*() const
{ return data; }
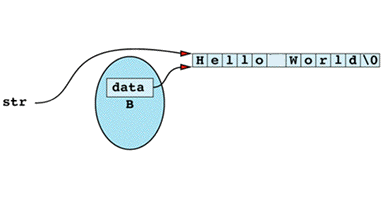
The flaw in this function is that it's returning a "handle" — in this case, a pointer — to information that should be hidden inside the String object on which the function is invoked. That handle gives callers unrestricted access to what the private field data points to. In other words, after the
char *str = B;
the situation looks like
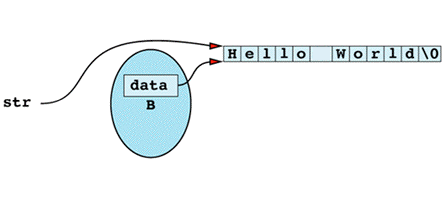
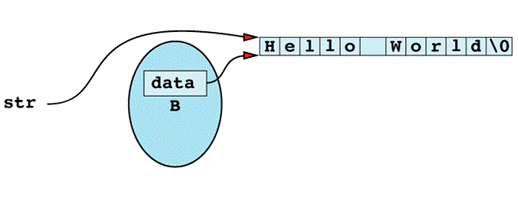
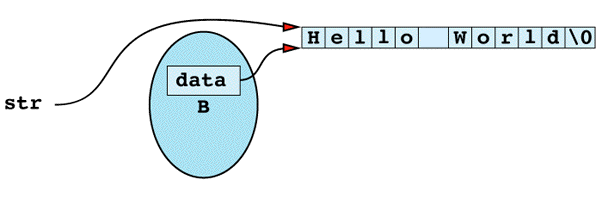
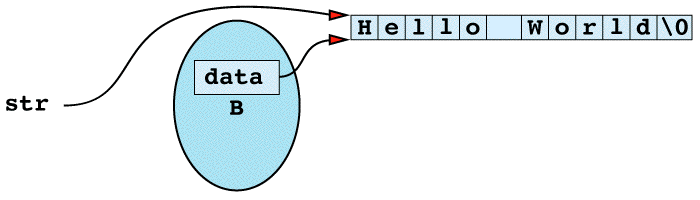
Clearly, any modification to the memory pointed to by str will also change the effective value of B. Thus, even though B is declared const, and even though only const member functions are invoked on B, B might still acquire different values as the program runs. In particular, if str modifies what it points to, B will also
There's nothing inherently wrong with the way String::operator char* is written. What's troublesome is that it can be applied to constant objects. If the function weren't declared const, there would be no problem, because it couldn't be applied to objects like B.
Yet it seems perfectly reasonable to turn a String object, even a constant one, into its equivalent char*, so you'd like to keep this function const. If you want to do that, you must rewrite your implementation to avoid returning a handle to the object's internal
// a slower, but safer implementation
inline String::operator char*() const
{
char *copy = new char[strlen(data) + 1];
strcpy(copy, data);
return copy;
}
This implementation is safe, because it returns a pointer to memory that contains a copy of the data to which the String object points; there is no way to change the value of the String object through the pointer returned by this function. As usual, such safety commands a price: this version of String::operator char* is slower than the simple version above, and callers of this function must remember to use delete on the pointer that's
If you think this version of operator char* is too slow, or if the potential memory leak makes you nervous (as well it should), a slightly different tack is to return a pointer to constant chars:
class String {
public:
operator const char *() const;
... };
inline String::operator const char*() const
{ return data; }
This function is fast and safe, and, though it's not the same as the function you originally specified, it suffices for most applications. It's also the moral equivalent of the string/char* conundrum: the standard string type contains a member function c_str that returns a const char* version of the string in question. For more information on the standard string type, turn to Item 49.
A pointer isn't the only way to return a handle to internal data. References are just as easy to abuse. Here's a common way to do it, again using the String
class String {
public:
...
char& operator[](int index) const
{ return data[index]; }
private: char *data; };
String s = "I'm not constant";
s[0] = 'x'; // fine, s isn't const
const String cs = "I'm constant";
cs[0] = 'x'; // this modifies the const
// string, but compilers
// won't notice
Notice how String::operator[] returns its result by reference. That means that the caller of this function gets back another name for the internal element data[index], and that other name can be used to modify the internal data of the supposedly constant object. This is the same problem you saw before, but this time the culprit is a reference as a return value, not a
The general solutions to this kind of problem are the same as they were for pointers: either make the function non-const, or rewrite it so that no handle is returned. For a solution to this particular problem — how to write String::operator[] so that it works for both const and non-const objects — see Item 21.
const member functions aren't the only ones that need to worry about returning handles. Even non-const member functions must reconcile themselves to the fact that the validity of a handle expires at the same time as the object to which it corresponds. This may be sooner than a client expects, especially when the object in question is a compiler-generated temporary
For example, take a look at this function, which returns a String
String someFamousAuthor() // randomly chooses and
{ // returns an author's name
switch (rand() % 3) { // rand() is in <stdlib.h>
// (and <cstdlib> — see
// Item 49)
case 0:
return "Margaret Mitchell"; // Wrote "Gone with the
// Wind," a true classic
case 1:
return "Stephen King"; // His stories have kept
// millions from sleeping
// at night
case 2:
return "Scott Meyers"; // Ahem, one of these
} // things is not like the
// others...
return ""; // we can't get here, but
// all paths in a value-
// returning function must
} // return a value, sigh
Kindly set aside your concerns about how "random" the values returned from rand are, and please humor my delusions of grandeur in associating myself with real writers. Instead, focus on the fact that the return value of someFamousAuthor is a String object, a temporary String object (see Item M19). Such objects are transient — their lifetimes generally extend only until the end of the expression containing the call to the function creating them. In this case, that would be until the end of the expression containing the call to someFamousAuthor.
Now consider this use of someFamousAuthor, in which we assume that String declares an operator const char* member function as described
const char *pc = someFamousAuthor();
cout << pc; // uh oh...
Believe it or not, you can't predict what this code will do, at least not with any certainty. That's because by the time you try to print out the sequence of characters pointed to by pc, that sequence is undefined. The difficulty arises from the events that transpire during the initialization of pc:
String object is created to hold someFamousAuthor's return value.
String is converted to a const char* via String's operator const char* member function, and pc is initialized with the resulting pointer.
String object is destroyed, which means its destructor is called. Within the destructor, its data pointer is deleted (the code is shown in Item 11). However, data points to the same memory as pc does, so pc now points to deleted memory — memory with undefined contents.
Because pc was initialized with a handle into a temporary object and temporary objects are destroyed shortly after they're created, the handle became invalid before pc could do anything with it. For all intents and purposes, pc was dead on arrival. Such is the danger of handles into temporary
For const member functions, then, returning handles is ill-advised, because it violates abstraction. Even for non-const member functions, however, returning handles can lead to trouble, especially when temporary objects get involved. Handles can dangle, just like pointers, and just as you labor to avoid dangling pointers, you should strive to avoid dangling handles,
Still, there's no reason to get fascist about it. It's not possible to stomp out all possible dangling pointers in nontrivial programs, and it's rarely possible to eliminate all possible dangling handles, either. Nevertheless, if you avoid returning handles when there's no compelling need, your programs will benefit, and so will your
Item 30: Avoid member functions that return non-const pointers or references to members less accessible than themselves.
The reason for making a member private or protected is to limit access to it, right? Your overworked, underpaid C++ compilers go to lots of trouble to make sure that your access restrictions aren't circumvented, right? So it doesn't make a lot of sense for you to write functions that give random clients the ability to freely access restricted members, now, does it? If you think it does make sense, please reread this paragraph over and over until you agree that it
It's easy to violate this simple rule. Here's an
class Address { ... }; // where someone lives
class Person {
public:
Address& personAddress() { return address; }
...
private:
Address address;
...
};
The member function personAddress provides the caller with the Address object contained in the Person object, but, probably due to efficiency considerations, the result is returned by reference instead of by value (see Item 22). Unfortunately, the presence of this member function defeats the purpose of making Person::address
Person scott(...); // parameters omitted for
// simplicity
Address& addr = // assume that addr is
scott.personAddress(); // global
Now the global object addr is another name for scott.address, and it can be used to read and write scott.address at will. For all practical purposes, scott.address is no longer private; it is public, and the source of this promotion in accessibility is the member function personAddress. Of course, there is nothing special about the access level private in this example; if address were protected, exactly the same reasoning would
References aren't the only cause for concern. Pointers can play this game, too. Here's the same example, but using pointers this
class Person {
public:
Address * personAddress() { return &address; }
...
private:
Address address;
...
};
Address *addrPtr =
scott.personAddress(); // same problem as above
With pointers, however, you have to worry not only about data members, but also about member functions. That's because it's possible to return a pointer to a member
class Person; // forward declaration
// PPMF = "pointer to Person member function"
typedef void (Person::*PPMF)();
class Person {
public:
static PPMF verificationFunction()
{ return &Person::verifyAddress; }
...
private:
Address address;
void verifyAddress();
};
If you're not used to socializing with pointers to member functions and typedefs thereof, the declaration for Person::verificationFunction may seem daunting. Don't be intimidated. All it says
verificationFunction is a member function that takes no parameters;
Person class;
verificationFunction's return value) takes no parameters and returns nothing, i.e., void.
As for the word static, that means what it always means in a member declaration: there is only one copy of the member for the entire class, and the member can be accessed without an object. For the complete story, consult your favorite introductory C++ textbook. (If your favorite introductory C++ textbook doesn't discuss static members, carefully tear out all its pages and recycle them. Dispose of the book's cover in an environmentally sound manner, then borrow or buy a better
In this last example, verifyAddress is a private member function, indicating that it's really an implementation detail of the class; only class members should know about it (and friends, too, of course). However, the public member function verificationFunction returns a pointer to verifyAddress, so clients can again pull this kind of
PPMF pmf = scott.verificationFunction();
(scott.*pmf)(); // same as calling
// scott.verifyAddress
Here, pmf has become a synonym for Person::verifyAddress, with the crucial difference that there are no restrictions on its
In spite of the foregoing discussion, you may someday be faced with a situation in which, pressed to achieve performance constraints, you honestly need to write a member function that returns a reference or a pointer to a less-accessible member. At the same time, however, you won't want to sacrifice the access restrictions that private and protected afford you. In those cases, you can almost always achieve both goals by returning a pointer or a reference to a const object. For details, take a look at Item 21.
Item 31: Never return a reference to a local object or to a dereferenced pointer initialized by new within the function.
This Item may sound complicated, but it's not. It's simple common sense. Really. Honest. Trust me.
Consider first the matter of returning a reference to a local object. The problem here is that local objects are just that, local. That means they're constructed when they're defined, and they're destructed when they go out of scope. Their scope, however, is that of the function body in which they're located. When the function returns, control leaves its scope, so the objects local to that function are automatically destructed. As a result, if you return a reference to a local object, that local object has been destructed before the caller of the function ever gets its computational hands on
This problem usually raises its ugly head when you try to improve the efficiency of a function by returning its result by reference instead of by value. The following example is the same as the one in Item 23, which pursues in detail the question of when you can return a reference and when you
class Rational { // class for rational numbers
public:
Rational(int numerator = 0, int denominator = 1);
~Rational();
...
private: int n, d; // numerator and denominator
// notice that operator* (incorrectly) returns a reference
friend const Rational& operator*(const Rational& lhs,
const Rational& rhs);
};
// an incorrect implementation of operator*
inline const Rational& operator*(const Rational& lhs,
const Rational& rhs)
{
Rational result(lhs.n * rhs.n, lhs.d * rhs.d);
return result;
}
Here, the local object result is constructed upon entry into the body of operator*. However, local objects are automatically destroyed when they go out of scope. result will go out of scope after execution of the return statement, so when you write
Rational two = 2;
Rational four = two * two; // same as
// operator*(two, two)
what happens during the function call is result is constructed.
result, and this reference is squirreled away as operator*'s return value.
result is destroyed, and the space it used to occupy on the stack is made available for use by other parts of the program or by other programs.
four is initialized using the reference of step 2.
Everything is fine until step 4, at which point there occurs, as they say in the highest of high-tech circles, "a major lossage." The reference initialized in step 2 ceased to refer to a valid object as of the end of step 3, so the outcome of the initialization of object four is completely
The lesson should be clear: don't return a reference to a local
"Okay," you say, "the problem is that the object I want to use goes out of scope too soon. I can fix that. I'll just call new instead of using a local object." Like
// another incorrect implementation of operator*
inline const Rational& operator*(const Rational& lhs,
const Rational& rhs)
{
// create a new object on the heap
Rational *result =
new Rational(lhs.n * rhs.n, lhs.d * rhs.d);
// return it return *result; }
This approach does indeed avoid the problem of the previous example, but it introduces a new one in its place. To avoid a memory leak in your software, you know you must ensure that delete is applied to every pointer conjured up by new, but ay, there's the rub: who's to make the matching call to delete for this function's use of new?
Clearly, the caller of operator* must see to it that delete is applied. Clear, yes, and even easy to document, but nonetheless the cause is hopeless. There are two reasons for this pessimistic
First, it's well-known that programmers, as a breed, are sloppy. That doesn't mean that you're sloppy or that I'm sloppy, but rare is the programmer who doesn't work with someone who is — shall we say? — a little on the flaky side. What are the odds that such programmers — and we all know that they exist — will remember that whenever they call operator*, they must take the address of the result and then use delete on it? That is, they must use operator* like
const Rational& four = two * two; // get dereferenced
// pointer; store it in
// a reference
...
delete &four; // retrieve pointer
// and delete it
The odds are vanishingly small. Remember, if only a single caller of operator* fails to follow the rules, you have a memory
Returning dereferenced pointers has a second, more serious, problem, because it persists even in the presence of the most conscientious of programmers. Often, the result of operator* is a temporary intermediate value, an object that exists only for the purposes of evaluating a larger expression. For
Rational one(1), two(2), three(3), four(4); Rational product;
product = one * two * three * four;
Evaluation of the expression to be assigned to product requires three separate calls to operator*, a fact that becomes more evident when you rewrite the expression in its equivalent functional
product = operator*(operator*(operator*(one, two), three), four);
You know that each of the calls to operator* returns an object that needs to be deleted, but there is no possibility of applying delete, because none of the returned objects has been saved
The only solution to this difficulty is to ask clients to code like
const Rational& temp1 = one * two; const Rational& temp2 = temp1 * three; const Rational& temp3 = temp2 * four;
delete &temp1; delete &temp2; delete &temp3;
Do that, and the best you can hope for is that people will ignore you. More realistically, you'd be skinned alive, or possibly sentenced to ten years hard labor writing microcode for waffle irons and toaster
Learn your lesson now, then: writing a function that returns a dereferenced pointer is a memory leak just waiting to
By the way, if you think you've come up with a way to avoid the undefined behavior inherent in returning a reference to a local object and the memory leak haunting the return of a reference to a heap-allocated object, turn to Item 23 and read why returning a reference to a local static object also fails to work correctly. It may save you the trouble of seeking medical care for the arm you're likely to strain trying to pat yourself on the
Item 32: Postpone variable definitions as long as possible.
So you subscribe to the C philosophy that variables should be defined at the beginning of a block. Cancel that subscription! In C++, it's unnecessary, unnatural, and
Remember that when you define a variable of a type with a constructor or destructor, you incur the cost of construction when control reaches the variable's definition, and you incur the cost of destruction when the variable goes out of scope. This means there's a cost associated with unused variables, so you want to avoid them whenever you
Suave and sophisticated in the ways of programming as I know you to be, you're probably thinking you never define unused variables, so this Item's advice is inapplicable to your tight, lean coding style. You may need to think again. Consider the following function, which returns an encrypted version of a password, provided the password is long enough. If the password is too short, the function throws an exception of type logic_error, which is defined in the standard C++ library (see Item 49):
// this function defines the variable "encrypted" too soon
string encryptPassword(const string& password)
{
string encrypted;
if (password.length() < MINIMUM_PASSWORD_LENGTH) {
throw logic_error("Password is too short");
}
do whatever is necessary to place an encrypted version of password in encrypted;
return encrypted; }
The object encrypted isn't completely unused in this function, but it's unused if an exception is thrown. That is, you'll pay for the construction and destruction of encrypted even if encryptPassword throws an exception (see also Item M15). As a result, you're better off postponing encrypted's definition until you know you'll need
// this function postpones "encrypted"'s definition until
// it's truly necessary
string encryptPassword(const string& password)
{
if (password.length() < MINIMUM_PASSWORD_LENGTH) {
throw logic_error("Password is too short");
}
string encrypted;
do whatever is necessary to place an encrypted version of password in encrypted;
return encrypted; }
This code still isn't as tight as it might be, because encrypted is defined without any initialization arguments. That means its default constructor will be used. In many cases, the first thing you'll do to an object is give it some value, often via an assignment. Item 12 explains why default-constructing an object and then assigning to it is a lot less efficient than initializing it with the value you really want it to have. That analysis applies here, too. For example, suppose the hard part of encryptPassword is performed in this
void encrypt(string& s); // encrypts s in place
Then encryptPassword could be implemented like this, though it wouldn't be the best way to do
// this function postpones "encrypted"'s definition until
// it's necessary, but it's still needlessly inefficient
string encryptPassword(const string& password)
{
... // check length as above
string encrypted; // default-construct encrypted encrypted = password; // assign to encrypted encrypt(encrypted); return encrypted; }
A preferable approach is to initialize encrypted with password, thus skipping the (pointless) default
// finally, the best way to define and initialize encrypted
string encryptPassword(const string& password)
{
... // check length
string encrypted(password); // define and initialize
// via copy constructor
encrypt(encrypted); return encrypted; }
This suggests the real meaning of "as long as possible" in this Item's title. Not only should you postpone a variable's definition until right before you have to use the variable, you should try to postpone the definition until you have initialization arguments for it. By doing so, you avoid not only constructing and destructing unneeded objects, you also avoid pointless default constructions. Further, you help document the purpose of variables by initializing them in contexts in which their meaning is clear. Remember how in C you're encouraged to put a short comment after each variable definition to explain what the variable will eventually be used for? Well, combine decent variable names (see also Item 28) with contextually meaningful initialization arguments, and you have every programmer's dream: a solid argument for eliminating some
By postponing variable definitions, you improve program efficiency, increase program clarity, and reduce the need to document variable meanings. It looks like it's time to kiss those block-opening variable definitions
Item 33: Use inlining judiciously.
Inline functions -- what a wonderful idea! They look like functions, they act like functions, they're ever so much better than macros (see Item 1), and you can call them without having to incur the overhead of a function call. What more could you possibly ask
You actually get more than you might think, because avoiding the cost of a function call is only half the story. Compiler optimization routines are typically designed to concentrate on stretches of code that lack function calls, so when you inline a function, you may enable compilers to perform context-specific optimizations on the body of the function. Such optimizations would be impossible for "normal" function
However, let's not get carried away. In programming, as in life, there is no free lunch, and inline functions are no exception. The whole idea behind an inline function is to replace each call of that function with its code body, and it doesn't take a Ph.D. in statistics to see that this is likely to increase the overall size of your object code. On machines with limited memory, overzealous inlining can give rise to programs that are too big for the available space. Even with virtual memory, inline-induced code bloat can lead to pathological paging behavior (thrashing) that will slow your program to a crawl. (It will, however, provide your disk controller with a nice exercise regimen.) Too much inlining can also reduce your instruction cache hit rate, thus reducing the speed of instruction fetch from that of cache memory to that of primary
On the other hand, if an inline function body is very short, the code generated for the function body may actually be smaller than the code generated for a function call. If that is the case, inlining the function may actually lead to smaller object code and a higher cache hit
Bear in mind that the inline directive, like register, is a hint to compilers, not a command. That means compilers are free to ignore your inline directives whenever they want to, and it's not that hard to make them want to. For example, most compilers refuse to inline "complicated" functions (e.g., those that contain loops or are recursive), and all but the most trivial virtual function calls stop inlining routines dead in their tracks. (This shouldn't be much of a surprise. virtual means "wait until runtime to figure out which function to call," and inline means "during compilation, replace the call site with the called function." If compilers don't know which function will be called, you can hardly blame them for refusing to make an inline call to it.) It all adds up to this: whether a given inline function is actually inlined is dependent on the implementation of the compiler you're using. Fortunately, most compilers have a diagnostic level that will result in a warning (see Item 48) if they fail to inline a function you've asked them
Suppose you've written some function f and you've declared it inline. What happens if a compiler chooses, for whatever reason, not to inline that function? The obvious answer is that f will be treated like a non-inline function: code for f will be generated as if it were a normal "outlined" function, and calls to f will proceed as normal function
In theory, this is precisely what will happen, but this is one of those occasions when theory and practice may go their separate ways. That's because this very tidy solution to the problem of what to do about "outlined inlines" was added to C++ relatively late in the standardization process. Earlier specifications for the language (such as the ARM — see Item 50) told compiler vendors to implement different behavior, and the older behavior is still common enough that you need to understand what it
Think about it for a minute, and you'll realize that inline function definitions are virtually always put in header files. This allows multiple translation units (source files) to include the same header files and reap the advantages of the inline functions that are defined within them. Here's an example, in which I adopt the convention that source files end in ".cpp"; this is probably the most prevalent of the file naming conventions in the world of
// This is file example.h
inline void f() { ... } // definition of f
...
// This is file source1.cpp
#include "example.h" // includes definition of f
... // contains calls to f
// This is file source2.cpp
#include "example.h" // also includes definition
// of f
... // also calls f
Under the old "outlined inline" rules and the assumption that f is not being inlined, when source1.cpp is compiled, the resulting object file will contain a function called f, just as if f had never been declared inline. Similarly, when source2.cpp is compiled, its generated object file will also hold a function called f. When you try to link the two object files together, you can reasonably expect your linker to complain that your program contains two definitions of f, an
To prevent this problem, the old rules decreed that compilers treat an un-inlined inline function as if the function had been declared static — that is, local to the file currently being compiled. In the example you just saw, compilers following the old rules would treat f as if it were static in source1.cpp when that file was being compiled and as if it were static in source2.cpp when that file was being compiled. This strategy eliminates the link-time problem, but at a cost: each translation unit that includes the definition of f (and that calls f) contains its own static copy of f. If f itself defines local static variables, each copy of f gets its own copy of the variables, something sure to astonish programmers who believe that "static" inside a function means "only one
This leads to a stunning realization. Under both new rules and old, if an inline function isn't inlined, you still pay for the cost of a function call at each call site, but under the old rules, you can also suffer an increase in code size, because each translation unit that includes and calls f gets its own copy of f's code and f's static variables! (To make matters worse, each copy of f and each copy of f's static variables tend to end up on different virtual memory pages, so two calls to different copies of f are likely to entail one or more page
There's more. Sometimes your poor, embattled compilers have to generate a function body for an inline function even when they are perfectly willing to inline the function. In particular, if your program ever takes the address of an inline function, compilers must generate a function body for it. How can they come up with a pointer to a function that doesn't
inline void f() {...} // as above
void (*pf)() = f; // pf points to f
int main()
{
f(); // an inline call to f
pf(); // a non-inline call to f
// through pf
...
}
In this case, you end up in the seemingly paradoxical situation whereby calls to f are inlined, but — under the old rules — each translation unit that takes f's address still generates a static copy of the function. (Under the new rules, only a single out-of-line copy of f will be generated, regardless of the number of translation units
This aspect of un-inlined inline functions can affect you even if you never use function pointers, because programmers aren't necessarily the only ones asking for pointers to functions. Sometimes compilers do it. In particular, compilers sometimes generate out-of-line copies of constructors and destructors so that they can get pointers to those functions for use in constructing and destructing arrays of objects of a class (see also Item M8).
In fact, constructors and destructors are often worse candidates for inlining than a casual examination would indicate. For example, consider the constructor for class Derived
class Base {
public:
...
private: string bm1, bm2; // base members 1 and 2 };
class Derived: public Base {
public:
Derived() {} // Derived's ctor is
... // empty -- or is it?
private: string dm1, dm2, dm3; // derived members 1-3 };
This constructor certainly looks like an excellent candidate for inlining, since it contains no code. But looks can be deceiving. Just because it contains no code doesn't necessarily mean it contains no code. In fact, it may contain a fair amount of
C++ makes various guarantees about things that happen when objects are created and destroyed. Items 5 and M8 describes how when you use new, your dynamically created objects are automatically initialized by their constructors, and how when you use delete, the corresponding destructors are invoked. Item 13 explains that when you create an object, each base class of and each data member in that object is automatically constructed, and the reverse process regarding destruction automatically occurs when an object is destroyed. Those items describe what C++ says must happen, but C++ does not say how they happen. That's up to compiler implementers, but it should be clear that those things don't just happen by themselves. There has to be some code in your program to make those things happen, and that code — the code written by compiler implementers and inserted into your program during compilation — has to go somewhere. Sometimes, it ends up in your constructors and destructors, so some implementations will generate code equivalent to the following for the allegedly empty Derived constructor
// possible implementation of Derived constructor
Derived::Derived()
{
// allocate heap memory for this object if it's supposed
// to be on the heap; see Item 8 for info on operator new
if (this object is on the heap)
this = ::operator new(sizeof(Derived));
Base::Base(); // initialize Base part dm1.string(); // construct dm1 dm2.string(); // construct dm2 dm3.string(); // construct dm3 }
You could never hope to get code like this to compile, because it's not legal C++ — not for you, anyway. For one thing, you have no way of asking whether an object is on the heap from inside its constructor. (For an examination of what it takes to reliably determine whether an object is on the heap, see Item M27.) For another, you're forbidden from assigning to this. And you can't invoke constructors via function calls, either. Your compilers, however, labor under no such constraints — they can do whatever they like. But the legality of the code is not the point. The point is that code to call operator new (if necessary), to construct base class parts, and to construct data members may be silently inserted into your constructors, and when it is, those constructors increase in size, thus making them less attractive candidates for inlining. Of course, the same reasoning applies to the Base constructor, so if it's inlined, all the code inserted into it is also inserted into the Derived constructor (via the Derived constructor's call to the Base constructor). And if the string constructor also happens to be inlined, the Derived constructor will gain five copies of that function's code, one for each of the five strings in a Derived object (the two it inherits plus the three it declares itself). Now do you see why it's not necessarily a no-brain decision whether to inline Derived's constructor? Of course, similar considerations apply to Derived's destructor, which, one way or another, must see to it that all the objects initialized by Derived's constructor are properly destroyed. It may also need to free the dynamically allocated memory formerly occupied by the just-destroyed Derived
Library designers must evaluate the impact of declaring functions inline, because inline functions make it impossible to provide binary upgrades to the inline functions in a library. In other words, if f is an inline function in a library, clients of the library compile the body of f into their applications. If a library implementer later decides to change f, all clients who've used f must recompile. This is often highly undesirable (see also Item 34). On the other hand, if f is a non-inline function, a modification to f requires only that clients relink. This is a substantially less onerous burden than recompiling and, if the library containing the function is dynamically linked, one that may be absorbed in a way that's completely transparent to
Static objects inside inline functions often exhibit counterintuitive behavior. For this reason, it's generally a good idea to avoid declaring functions inline if those functions contain static objects. For details, consult Item M26.
For purposes of program development, it is important to keep all these considerations in mind, but from a purely practical point of view during coding, one fact dominates all others: most debuggers have trouble with inline
This should be no great revelation. How do you set a breakpoint in a function that isn't there? How do you step through such a function? How do you trap calls to it? Without being unreasonably clever (or deviously underhanded), you simply can't. Happily, this leads to a logical strategy for determining which functions should be declared inline and which should
Initially, don't inline anything, or at least limit your inlining to those functions that are truly trivial, such as age
class Person {
public:
int age() const { return personAge; }
...
private:
int personAge;
...
};
By employing inlines cautiously, you facilitate your use of a debugger, but you also put inlining in its proper place: as a hand-applied optimization. Don't forget the empirically determined rule of 80-20 (see Item M16), which states that a typical program spends 80 percent of its time executing only 20 percent of its code. It's an important rule, because it reminds you that your goal as a software developer is to identify the 20 percent of your code that is actually capable of increasing your program's overall performance. You can inline and otherwise tweak your functions until the cows come home, but it's all wasted effort unless you're focusing on the right
Once you've identified the set of important functions in your application, the ones whose inlining will actually make a difference (a set that is itself dependent on the architecture on which you're running), don't hesitate to declare them inline. At the same time, however, be on the lookout for problems caused by code bloat, and watch out for compiler warnings (see Item 48) that indicate that your inline functions haven't been
Used judiciously, inline functions are an invaluable component of every C++ programmer's toolbox, but, as the foregoing discussion has revealed, they're not quite as simple and straightforward as you might have
Item 34: Minimize compilation dependencies between files.
So you go into your C++ program and you make a minor change to the implementation of a class. Not the class interface, mind you, just the implementation; only the private stuff. Then you get set to rebuild the program, figuring that the compilation and linking should take only a few seconds. After all, only one class has been modified. You click on Rebuild or type make (or its moral equivalent), and you are astonished, then mortified, as you realize that the whole world is being recompiled and
Don't you just hate it when that
The problem is that C++ doesn't do a very good job of separating interfaces from implementations. In particular, class definitions include not only the interface specification, but also a fair number of implementation details. For
class Person {
public:
Person(const string& name, const Date& birthday,
const Address& addr, const Country& country);
virtual ~Person();
... // copy constructor and assignment
// operator omitted for simplicity
string name() const;
string birthDate() const;
string address() const;
string nationality() const;
private: string name_; // implementation detail Date birthDate_; // implementation detail Address address_; // implementation detail Country citizenship_; // implementation detail };
This is hardly a Nobel Prize-winning class design, although it does illustrate an interesting naming convention for distinguishing private data from public functions when the same name makes sense for both: the former are tagged with a trailing underbar. The important thing to observe is that class Person can't be compiled unless the compiler also has access to definitions for the classes in terms of which Person is implemented, namely, string, Date, Address, and Country. Such definitions are typically provided through #include directives, so at the top of the file defining the Person class, you are likely to find something like
#include <string> // for type string (see Item 49) #include "date.h" #include "address.h" #include "country.h"
Unfortunately, this sets up a compilation dependency between the file defining Person and these include files. As a result, if any of these auxiliary classes changes its implementation, or if any of the classes on which it depends changes its implementation, the file containing the Person class must be recompiled, as must any files that use the Person class. For clients of Person, this can be more than annoying. It can be downright
You might wonder why C++ insists on putting the implementation details of a class in the class definition. For example, why can't you define Person this
class string; // "conceptual" forward declaration for the
// string type. See Item 49 for details.
class Date; // forward declaration class Address; // forward declaration class Country; // forward declaration
class Person {
public:
Person(const string& name, const Date& birthday,
const Address& addr, const Country& country);
virtual ~Person();
... // copy ctor, operator=
string name() const; string birthDate() const; string address() const; string nationality() const; };
specifying the implementation details of the class separately? If that were possible, clients of Person would have to recompile only if the interface to the class changed. Because interfaces tend to stabilize before implementations do, such a separation of interface from implementation could save untold hours of recompilation and linking over the course of a large software
Alas, the real world intrudes on this idyllic scenario, as you will appreciate when you consider something like
int main()
{
int x; // define an int
Person p(...); // define a Person
// (arguments omitted for
... // simplicity)
}
When compilers see the definition for x, they know they must allocate enough space to hold an int. No problem. Each compiler knows how big an int is. When compilers see the definition for p, however, they know they have to allocate enough space for a Person, but how are they supposed to know how big a Person object is? The only way they can get that information is to consult the class definition, but if it were legal for a class definition to omit the implementation details, how would compilers know how much space to
In principle, this is no insuperable problem. Languages such as Smalltalk, Eiffel, and Java get around it all the time. The way they do it is by allocating only enough space for a pointer to an object when an object is defined. That is, they handle the code above as if it had been written like
int main()
{
int x; // define an int
Person *p; // define a pointer
// to a Person
...
}
It may have occurred to you that this is in fact legal C++, and it turns out that you can play the "hide the object implementation behind a pointer" game
Here's how you employ the technique to decouple Person's interface from its implementation. First, you put only the following in the header file declaring the Person
// compilers still need to know about these type
// names for the Person constructor
class string; // again, see Item 49 for information
// on why this isn't correct for string
class Date;
class Address;
class Country;
// class PersonImpl will contain the implementation // details of a Person object; this is just a // forward declaration of the class name class PersonImpl;
class Person {
public:
Person(const string& name, const Date& birthday,
const Address& addr, const Country& country);
virtual ~Person();
... // copy ctor, operator=
string name() const; string birthDate() const; string address() const; string nationality() const;
private: PersonImpl *impl; // pointer to implementation };
Now clients of Person are completely divorced from the details of strings, dates, addresses, countries, and persons. Those classes can be modified at will, but Person clients may remain blissfully unaware. More to the point, they may remain blissfully un-recompiled. In addition, because they're unable to see the details of Person's implementation, clients are unlikely to write code that somehow depends on those details. This is a true separation of interface and
The key to this separation is replacement of dependencies on class definitions with dependencies on class declarations. That's all you need to know about minimizing compilation dependencies: make your header files self-sufficient whenever it's practical, and when it's not practical, be dependent on class declarations, not class definitions. Everything else flows from this simple design
There are three immediate
class Date; // class declaration
Date returnADate(); // fine — no definition void takeADate(Date d); // of Date is neededOf course, pass-by-value is generally a bad idea (see Item 22), but if you find yourself forced to use it for some reason, there's still no justification for introducing unnecessary compilation
If you're surprised that the declarations for returnADate and takeADate compile without a definition for Date, join the club; so was I. It's not as curious as it seems, however, because if anybody calls those functions, Date's definition must be visible. Oh, I know what you're thinking: why bother to declare functions that nobody calls? Simple. It's not that nobody calls them, it's that not everybody calls them. For example, if you have a library containing hundreds of function declarations (possibly spread over several namespaces — see Item 28), it's unlikely that every client calls every function. By moving the onus of providing class definitions (via #include directives) from your header file of function declarations to clients' files containing function calls, you eliminate artificial client dependencies on type definitions they don't really
#include header files in your header files unless your headers won't compile without them.#include the additional headers necessary to make their code compile. A few clients may grumble that this is inconvenient, but rest assured that you are saving them much more pain than you're inflicting. In fact, this technique is so well-regarded, it's enshrined in the standard C++ library (see Item 49); the header <iosfwd> contains declarations (and only declarations) for the types in the iostream library.
Classes like Person that contain only a pointer to an unspecified implementation are often called Handle classes or Envelope classes. (In the former case, the classes they point to are called Body classes; in latter case, the pointed-to classes are known as Letter classes.) Occasionally, you may hear people refer to such classes as Cheshire Cat classes, an allusion to the cat in Alice in Wonderland that could, when it chose, leave behind only its smile after the rest of it had
Lest you wonder how Handle classes actually do anything, the answer is simple: they forward all their function calls to the corresponding Body classes, and those classes do the real work. For example, here's how two of Person's member functions would be
#include "Person.h" // because we're implementing
// the Person class, we must
// #include its class definition
#include "PersonImpl.h" // we must also #include
// PersonImpl's class definition,
// otherwise we couldn't call
// its member functions. Note
// that PersonImpl has exactly
// the same member functions as
// Person — their interfaces
// are identical
Person::Person(const string& name, const Date& birthday,
const Address& addr, const Country& country)
{
impl = new PersonImpl(name, birthday, addr, country);
}
string Person::name() const
{
return impl->name();
}
Note how the Person constructor calls the PersonImpl constructor (implicitly, by using new — see Items 5 and M8) and how Person::name calls PersonImpl::name. This is important. Making Person a handle class doesn't change what Person does, it just changes where it does
An alternative to the Handle class approach is to make Person a special kind of abstract base class called a Protocol class. By definition, a Protocol class has no implementation; its raison d'être is to specify an interface for derived classes (see Item 36). As a result, it typically has no data members, no constructors, a virtual destructor (see Item 14), and a set of pure virtual functions that specify the interface. A Protocol class for Person might look like
class Person {
public:
virtual ~Person();
virtual string name() const = 0; virtual string birthDate() const = 0; virtual string address() const = 0; virtual string nationality() const = 0; };
Clients of this Person class must program in terms of Person pointers and references, because it's not possible to instantiate classes containing pure virtual functions. (It is, however, possible to instantiate classes derived from Person — see below.) Like clients of Handle classes, clients of Protocol classes need not recompile unless the Protocol class's interface is
Of course, clients of a Protocol class must have some way of creating new objects. They typically do it by calling a function that plays the role of the constructor for the hidden (derived) classes that are actually instantiated. Such functions go by several names (among them factory functions and virtual constructors), but they all behave the same way: they return pointers to dynamically allocated objects that support the Protocol class's interface (see also Item M25). Such a function might be declared like
// makePerson is a "virtual constructor" (aka, a "factory
// function") for objects supporting the Person interface
Person*
makePerson(const string& name, // return a ptr to
const Date& birthday, // a new Person
const Address& addr, // initialized with
const Country& country); // the given params
and used by clients like this:
string name;
Date dateOfBirth;
Address address;
Country nation;
...
// create an object supporting the Person interface
Person *pp = makePerson(name, dateOfBirth, address, nation);
...
cout << pp->name() // use the object via the
<< " was born on " // Person interface
<< pp->birthDate()
<< " and now lives at "
<< pp->address();
...
delete pp; // delete the object when
// it's no longer needed
Because functions like makePerson are closely associated with the Protocol class whose interface is supported by the objects they create, it's good style to declare them static inside the Protocol
class Person {
public:
... // as above
// makePerson is now a member of the class
static Person * makePerson(const string& name,
const Date& birthday,
const Address& addr,
const Country& country);
};
This avoids cluttering the global namespace (or any other namespace) with lots of functions of this nature (see also Item 28).
At some point, of course, concrete classes supporting the Protocol class's interface must be defined and real constructors must be called. That all happens behind the scenes inside the implementation files for the virtual constructors. For example, the Protocol class Person might have a concrete derived class RealPerson that provides implementations for the virtual functions it
class RealPerson: public Person {
public:
RealPerson(const string& name, const Date& birthday,
const Address& addr, const Country& country)
: name_(name), birthday_(birthday),
address_(addr), country_(country)
{}
virtual ~RealPerson() {}
string name() const; // implementations of string birthDate() const; // these functions are not string address() const; // shown, but they are string nationality() const; // easy to imagine
private: string name_; Date birthday_; Address address_; Country country_; };
Given RealPerson, it is truly trivial to write Person::makePerson:
Person * Person::makePerson(const string& name,
const Date& birthday,
const Address& addr,
const Country& country)
{
return new RealPerson(name, birthday, addr, country);
}
RealPerson demonstrates one of the two most common mechanisms for implementing a Protocol class: it inherits its interface specification from the Protocol class (Person), then it implements the functions in the interface. A second way to implement a Protocol class involves multiple inheritance, a topic explored in Item 43.
Okay, so Handle classes and Protocol classes decouple interfaces from implementations, thereby reducing compilation dependencies between files. Cynic that you are, I know you're waiting for the fine print. "What does all this hocus-pocus cost me?" you mutter. The answer is the usual one in Computer Science: it costs you some speed at runtime, plus some additional memory per
In the case of Handle classes, member functions have to go through the implementation pointer to get to the object's data. That adds one level of indirection per access. And you must add the size of this implementation pointer to the amount of memory required to store each object. Finally, the implementation pointer has to be initialized (in the Handle class's constructors) to point to a dynamically allocated implementation object, so you incur the overhead inherent in dynamic memory allocation (and subsequent deallocation) — see Item 10.
For Protocol classes, every function call is virtual, so you pay the cost of an indirect jump each time you make a function call (see Items 14 and M24). Also, objects derived from the Protocol class must contain a virtual pointer (again, see Items 14 and M24). This pointer may increase the amount of memory needed to store an object, depending on whether the Protocol class is the exclusive source of virtual functions for the
Finally, neither Handle classes nor Protocol classes can get much use out of inline functions. All practical uses of inlines require access to implementation details, and that's the very thing that Handle classes and Protocol classes are designed to avoid in the first
It would be a serious mistake, however, to dismiss Handle classes and Protocol classes simply because they have a cost associated with them. So do virtual functions, and you wouldn't want to forgo those, would you? (If so, you're reading the wrong book.) Instead, consider using these techniques in an evolutionary manner. Use Handle classes and Protocol classes during development to minimize the impact on clients when implementations change. Replace Handle classes and Protocol classes with concrete classes for production use when it can be shown that the difference in speed and/or size is significant enough to justify the increased coupling between classes. Someday, we may hope, tools will be available to perform this kind of transformation
A skillful blending of Handle classes, Protocol classes, and concrete classes will allow you to develop software systems that execute efficiently and are easy to evolve, but there is a serious disadvantage: you may have to cut down on the long breaks you've been taking while your programs