Inheritance and Object-Oriented Design
Many people are of the opinion that inheritance is what object-oriented programming is all about. Whether that's so is debatable, but the number of Items in the other sections of this book should convince you that as far as effective C++ programming is concerned, you have a lot more tools at your disposal than simply specifying which classes inherit from which other
Still, designing and implementing class hierarchies is fundamentally different from anything found in the world of C. Certainly it is in the area of inheritance and object-oriented design that you are most likely to radically rethink your approach to the construction of software systems. Furthermore, C++ provides a bewildering assortment of object-oriented building blocks, including public, protected, and private base classes; virtual and nonvirtual base classes; and virtual and nonvirtual member functions. Each of these features interacts not only with one another, but also with the other components of the language. As a result, trying to understand what each feature means, when it should be used, and how it is best combined with the non-object-oriented aspects of C++ can be a daunting
Further complicating the matter is the fact that different features of the language appear to do more or less the same thing.
void*) pointers?
In the Items in this section, I offer guidance on how to answer questions such as these. However, I cannot hope to address every aspect of object-oriented design. Instead, I concentrate on explaining what the different features in C++ really mean, on what you are really saying when you use a particular feature. For example, public inheritance means "isa" (see Item 35), and if you try to make it mean anything else, you will run into trouble. Similarly, a virtual function means "interface must be inherited," while a nonvirtual function means "both interface and implementation must be inherited." Failing to distinguish between these meanings has caused many a C++ programmer untold
If you understand the meanings of C++'s varied features, you'll find that your outlook on object-oriented design shifts. Instead of it being an exercise in differentiating between language constructs, it will properly become a matter of figuring out what it is you want to say about your software system. Once you know what you want to say, you'll be able to translate that into the appropriate C++ features without too much
The importance of saying what you mean and understanding what you're saying cannot be overestimated. The items that follow provide a detailed examination of how to do this effectively. Item 44 summarizes the correspondence between C++'s object-oriented constructs and what they mean. It serves as a nice capstone for this section, as well as a concise reference for future
Item 35: Make sure public inheritance models "isa."
In his book, Some Must Watch While Some Must Sleep (W. H. Freeman and Company, 1974), William Dement relates the story of his attempt to fix in the minds of his students the most important lessons of his course. It is claimed, he told his class, that the average British schoolchild remembers little more history than that the Battle of Hastings was in 1066. If a child remembers little else, Dement emphasized, he or she remembers the date 1066. For the students in his course, Dement went on, there were only a few central messages, including, interestingly enough, the fact that sleeping pills cause insomnia. He implored his students to remember these few critical facts even if they forgot everything else discussed in the course, and he returned to these fundamental precepts repeatedly during the
At the end of the course, the last question on the final exam was, "Write one thing from the course that you will surely remember for the rest of your life." When Dement graded the exams, he was stunned. Nearly everyone had written
It is thus with great trepidation that I proclaim to you now that the single most important rule in object-oriented programming with C++ is this: public inheritance means "isa." Commit this rule to
If you write that class D ("Derived") publicly inherits from class B ("Base"), you are telling C++ compilers (as well as human readers of your code) that every object of type D is also an object of type B, but not vice versa. You are saying that B represents a more general concept than D, that D represents a more specialized concept than B. You are asserting that anywhere an object of type B can be used, an object of type D can be used just as well, because every object of type D is an object of type B. On the other hand, if you need an object of type D, an object of type B will not do: every D isa B, but not vice
C++ enforces this interpretation of public inheritance. Consider this
class Person { ... };
class Student: public Person { ... };
We know from everyday experience that every student is a person, but not every person is a student. That is exactly what this hierarchy asserts. We expect that anything that is true of a person — for example, that he or she has a date of birth — is also true of a student, but we do not expect that everything that is true of a student — that he or she is enrolled in a particular school, for instance — is true of people in general. The notion of a person is more general than is that of a student; a student is a specialized type of
Within the realm of C++, any function that expects an argument of type Person (or pointer-to-Person or reference-to-Person) will instead take a Student object (or pointer-to-Student or reference-to-Student):
void dance(const Person& p); // anyone can dance
void study(const Student& s); // only students study
Person p; // p is a Person Student s; // s is a Student
dance(p); // fine, p is a Person
dance(s); // fine, s is a Student,
// and a Student isa Person
study(s); // fine
study(p); // error! p isn't a Student
This is true only for public inheritance. C++ will behave as I've described only if Student is publicly derived from Person. Private inheritance means something entirely different (see Item 42), and no one seems to know what protected inheritance is supposed to mean. Furthermore, the fact that a Student isa Person does not mean that an array of Student isa array of Person. For more information on that topic, see Item M3.
The equivalence of public inheritance and isa sounds simple, but in practice, things aren't always so straightforward. Sometimes your intuition can mislead you. For example, it is a fact that a penguin is a bird, and it is a fact that birds can fly. If we naively try to express this in C++, our effort
class Bird {
public:
virtual void fly(); // birds can fly
...
};
class Penguin:public Bird { // penguins are birds
...
};
Suddenly we are in trouble, because this hierarchy says that penguins can fly, which we know is not true. What
In this case, we are the victims of an imprecise language (English). When we say that birds can fly, we don't really mean that all birds can fly, only that, in general, birds have the ability to fly. If we were more precise, we'd recognize that there are in fact several types of non-flying birds, and we would come up with the following hierarchy, which models reality much
class Bird {
... // no fly function is
}; // declared
class FlyingBird: public Bird {
public:
virtual void fly();
...
};
class NonFlyingBird: public Bird {
... // no fly function is
// declared
};
class Penguin: public NonFlyingBird {
... // no fly function is
// declared
};
This hierarchy is much more faithful to what we really know than was the original
Even now we're not entirely finished with these fowl matters, because for some software systems, it may be entirely appropriate to say that a penguin isa bird. In particular, if your application has much to do with beaks and wings and nothing to do with flying, the original hierarchy might work out just fine. Irritating though this may seem, it's a simple reflection of the fact that there is no one ideal design for all software. The best design depends on what the system is expected to do, both now and in the future (see Item M32). If your application has no knowledge of flying and isn't expected to ever have any, making Penguin a derived class of Bird may be a perfectly valid design decision. In fact, it may be preferable to a decision that makes a distinction between flying and non-flying birds, because such a distinction would be absent from the world you are trying to model. Adding superfluous classes to a hierarchy can be just as bad a design decision as having the wrong inheritance relationships between
There is another school of thought on how to handle what I call the "All birds can fly, penguins are birds, penguins can't fly, uh oh" problem. That is to redefine the fly function for penguins so that it generates a runtime
void error(const string& msg); // defined elsewhere
class Penguin: public Bird {
public:
virtual void fly() { error("Penguins can't fly!"); }
...
};
Interpreted languages such as Smalltalk tend to adopt this approach, but it's important to recognize that this says something entirely different from what you might think. This does not say, "Penguins can't fly." This says, "Penguins can fly, but it's an error for them to try to do
How can you tell the difference? From the time at which the error is detected. The injunction, "Penguins can't fly," can be enforced by compilers, but violations of the statement, "It's an error for penguins to try to fly," can be detected only at
To express the constraint, "Penguins can't fly," you make sure that no such function is defined for Penguin
class Bird {
... // no fly function is
// declared
};
class NonFlyingBird: public Bird {
... // no fly function is
// declared
};
class Penguin: public NonFlyingBird {
... // no fly function is
// declared
};
If you try to make a penguin fly, compilers will reprimand you for your
Penguin p;
p.fly(); // error!
This is very different from the behavior you get if you use the Smalltalk approach. With that methodology, compilers won't say a
The C++ philosophy is fundamentally different from the Smalltalk philosophy, so you're better off doing things the C++ way as long as you're programming in C++. In addition, there are certain technical advantages to detecting errors during compilation instead of at runtime — see Item 46.
Perhaps you'll concede that your ornithological intuition may be lacking, but you can rely on your mastery of elementary geometry, right? I mean, how complicated can rectangles and squares
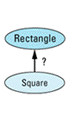
Well, answer this simple question: should class Square publicly inherit from class Rectangle?
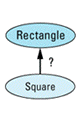
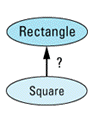
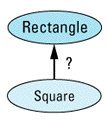
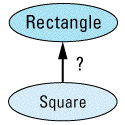
"Duh!" you say, "Of course it should! Everybody knows that a square is a rectangle, but generally not vice versa." True enough, at least in high school. But I don't think we're in high school
class Rectangle {
public:
virtual void setHeight(int newHeight);
virtual void setWidth(int newWidth);
virtual int height() const; // return current virtual int width() const; // values
...
};
void makeBigger(Rectangle& r) // function to
{ // increase r's area
int oldHeight = r.height();
r.setWidth(r.width() + 10); // add 10 to r's width
assert(r.height() == oldHeight); // assert that r's } // height is unchanged
Clearly, the assertion should never fail. makeBigger only changes r's width. Its height is never
Now consider this code, which uses public inheritance to allow squares to be treated like
class Square: public Rectangle { ... };
Square s;
...
assert(s.width() == s.height()); // this must be true
// for all squares
makeBigger(s); // by inheritance, s
// isa Rectangle, so
// we can increase its
// area
assert(s.width() == s.height()); // this must still be
// true for all squares
It's just as clear here as it was above that this last assertion should also never fail. By definition, the width of a square is the same as its
But now we have a problem. How can we reconcile the following
makeBigger, s's height is the same as its width;
makeBigger, s's width is changed, but its height is not;
makeBigger, s's height is again the same as its width. (Note that s is passed to makeBigger by reference, so makeBigger modifies s itself, not a copy of s.)
Welcome to the wonderful world of public inheritance, where the instincts you've developed in other fields of study — including mathematics — may not serve you as well as you expect. The fundamental difficulty in this case is that something applicable to a rectangle (its width may be modified independently of its height) is not applicable to a square (its width and height are constrained to be the same). But public inheritance asserts that everything applicable to base class objects — everything! — is also applicable to derived class objects. In the case of rectangles and squares (and a similar example involving sets and lists in Item 40), that assertion fails to hold, so using public inheritance to model their relationship is just plain wrong. Compilers will let you do it, of course, but as we've just seen, that's no guarantee the code will behave properly. As every programmer must learn (some more often than others), just because the code compiles doesn't mean it will
Now, don't fret that the software intuition you've developed over the years will fail you as you approach object-oriented design. That knowledge is still valuable, but now that you've added inheritance to your arsenal of design alternatives, you'll have to augment your intuition with new insights to guide you in inheritance's proper application. In time, the notion of having Penguin inherit from Bird or Square inherit from Rectangle will give you the same funny feeling you probably get now when somebody shows you a function several pages long. It's possible that it's the right way to approach things, it's just not very
Of course, the isa relationship is not the only one that can exist between classes. Two other common inter-class relationships are "has-a" and "is-implemented-in-terms-of." These relationships are considered in Items 40 and 42. It's not uncommon for C++ designs to go awry because one of these other important relationships was incorrectly modeled as isa, so you should make sure that you understand the differences between these relationships and that you know how they are best modeled in
Item 36: Differentiate between inheritance of interface and inheritance of implementation.
The seemingly straightforward notion of (public) inheritance turns out, upon closer examination, to be composed of two separable parts: inheritance of function interfaces and inheritance of function implementations. The difference between these two kinds of inheritance corresponds exactly to the difference between function declarations and function definitions discussed in the Introduction to this
As a class designer, you sometimes want derived classes to inherit only the interface (declaration) of a member function; sometimes you want derived classes to inherit both the interface and the implementation for a function, but you want to allow them to override the implementation you provide; and sometimes you want them to inherit both interface and implementation without allowing them to override
To get a better feel for the differences among these options, consider a class hierarchy for representing geometric shapes in a graphics
class Shape {
public:
virtual void draw() const = 0;
virtual void error(const string& msg);
int objectID() const;
...
};
class Rectangle: public Shape { ... };
class Ellipse: public Shape { ... };
Shape is an abstract class; its pure virtual function draw marks it as such. As a result, clients cannot create instances of the Shape class, only of the classes derived from it. Nonetheless, Shape exerts a strong influence on all classes that (publicly) inherit from it,
Three functions are declared in the Shape class. The first, draw, draws the current object on an implicit display. The second, error, is called by member functions if they need to report an error. The third, objectID, returns a unique integer identifier for the current object; Item 17 gives an example of how such a function might be used. Each function is declared in a different way: draw is a pure virtual function; error is a simple (impure?) virtual function; and objectID is a nonvirtual function. What are the implications of these different
Consider first the pure virtual function draw. The two most salient features of pure virtual functions are that they must be redeclared by any concrete class that inherits them, and they typically have no definition in abstract classes. Put these two traits together, and you realize
This makes perfect sense for the Shape::draw function, because it is a reasonable demand that all Shape objects must be drawable, but the Shape class can provide no reasonable default implementation for that function. The algorithm for drawing an ellipse is very different from the algorithm for drawing a rectangle, for example. A good way to interpret the declaration of Shape::draw is as saying to designers of subclasses, "You must provide a draw function, but I have no idea how you're going to implement
Incidentally, it is possible to provide a definition for a pure virtual function. That is, you could provide an implementation for Shape::draw, and C++ wouldn't complain, but the only way to call it would be to fully specify the call with the class
Shape *ps = new Shape; // error! Shape is abstract
Shape *ps1 = new Rectangle; // fine ps1->draw(); // calls Rectangle::draw
Shape *ps2 = new Ellipse; // fine ps2->draw(); // calls Ellipse::draw
ps1->Shape::draw(); // calls Shape::draw
ps2->Shape::draw(); // calls Shape::draw
Aside from helping impress fellow programmers at cocktail parties, knowledge of this feature is generally of limited utility. As you'll see below, however, it can be employed as a mechanism for providing a safer-than-usual default implementation for simple (impure) virtual
Sometimes it's useful to declare a class containing nothing but pure virtual functions. Such a Protocol class can provide only function interfaces for derived classes, never implementations. Protocol classes are described in Item 34 and are mentioned again in Item 43.
The story behind simple virtual functions is a bit different from that behind pure virtuals. As usual, derived classes inherit the interface of the function, but simple virtual functions traditionally provide an implementation that derived classes may or may not choose to override. If you think about this for a minute, you'll realize
In the case of Shape::error, the interface says that every class must support a function to be called when an error is encountered, but each class is free to handle errors in whatever way it sees fit. If a class doesn't want to do anything special, it can just fall back on the default error-handling provided in the Shape class. That is, the declaration of Shape::error says to designers of subclasses, "You've got to support an error function, but if you don't want to write your own, you can fall back on the default version in the Shape
It turns out that it can be dangerous to allow simple virtual functions to specify both a function declaration and a default implementation. To see why, consider a hierarchy of airplanes for XYZ Airlines. XYZ has only two kinds of planes, the Model A and the Model B, and both are flown in exactly the same way. Hence, XYZ designs the following
class Airport { ... }; // represents airports
class Airplane {
public:
virtual void fly(const Airport& destination);
...
};
void Airplane::fly(const Airport& destination)
{
default code for flying an airplane to
the given destination
}
class ModelA: public Airplane { ... };
class ModelB: public Airplane { ... };
To express that all planes have to support a fly function, and in recognition of the fact that different models of plane could, in principle, require different implementations for fly, Airplane::fly is declared virtual. However, in order to avoid writing identical code in the ModelA and ModelB classes, the default flying behavior is provided as the body of Airplane::fly, which both ModelA and ModelB
This is a classic object-oriented design. Two classes share a common feature (the way they implement fly), so the common feature is moved into a base class, and the feature is inherited by the two classes. This design makes common features explicit, avoids code duplication, facilitates future enhancements, and eases long-term maintenance — all the things for which object-oriented technology is so highly touted. XYZ Airlines should be
Now suppose that XYZ, its fortunes on the rise, decides to acquire a new type of airplane, the Model C. The Model C differs from the Model A and the Model B. In particular, it is flown
XYZ's programmers add the class for Model C to the hierarchy, but in their haste to get the new model into service, they forget to redefine the fly
class ModelC: public Airplane {
... // no fly function is
// declared
};
In their code, then, they have something akin to the
Airport JFK(...); // JFK is an airport in
// New York City
Airplane *pa = new ModelC;
...
pa->fly(JFK); // calls Airplane::fly!
This is a disaster: an attempt is being made to fly a ModelC object as if it were a ModelA or a ModelB. That's not the kind of behavior that inspires confidence in the traveling
The problem here is not that Airplane::fly has default behavior, but that ModelC was allowed to inherit that behavior without explicitly saying that it wanted to. Fortunately, it's easy to offer default behavior to subclasses, but not give it to them unless they ask for it. The trick is to sever the connection between the interface of the virtual function and its default implementation. Here's one way to do
class Airplane {
public:
virtual void fly(const Airport& destination) = 0;
...
protected: void defaultFly(const Airport& destination); };
void Airplane::defaultFly(const Airport& destination)
{
default code for flying an airplane to
the given destination
}
Notice how Airplane::fly has been turned into a pure virtual function. That provides the interface for flying. The default implementation is also present in the Airplane class, but now it's in the form of an independent function, defaultFly. Classes like ModelA and ModelB that want to use the default behavior simply make an inline call to defaultFly inside their body of fly (but see Item 33 for information on the interaction of inlining and virtual
class ModelA: public Airplane {
public:
virtual void fly(const Airport& destination)
{ defaultFly(destination); }
...
};
class ModelB: public Airplane {
public:
virtual void fly(const Airport& destination)
{ defaultFly(destination); }
...
};
For the ModelC class, there is no possibility of accidentally inheriting the incorrect implementation of fly, because the pure virtual in Airplane forces ModelC to provide its own version of fly.
class ModelC: public Airplane {
public:
virtual void fly(const Airport& destination);
...
};
void ModelC::fly(const Airport& destination)
{
code for flying a ModelC airplane to the given destination
}
This scheme isn't foolproof (programmers can still copy-and-paste themselves into trouble), but it's more reliable than the original design. As for Airplane::defaultFly, it's protected because it's truly an implementation detail of Airplane and its derived classes. Clients using airplanes should care only that they can be flown, not how the flying is
It's also important that Airplane::defaultFly is a nonvirtual function. This is because no subclass should redefine this function, a truth to which Item 37 is devoted. If defaultFly were virtual, you'd have a circular problem: what if some subclass forgets to redefine defaultFly when it's supposed
Some people object to the idea of having separate functions for providing interface and default implementation, such as fly and defaultFly above. For one thing, they note, it pollutes the class namespace with a proliferation of closely-related function names. Yet they still agree that interface and default implementation should be separated. How do they resolve this seeming contradiction? By taking advantage of the fact that pure virtual functions must be redeclared in subclasses, but they may also have implementations of their own. Here's how the Airplane hierarchy could take advantage of the ability to define a pure virtual
class Airplane {
public:
virtual void fly(const Airport& destination) = 0;
...
};
void Airplane::fly(const Airport& destination)
{
default code for flying an airplane to
the given destination
}
class ModelA: public Airplane {
public:
virtual void fly(const Airport& destination)
{ Airplane::fly(destination); }
...
};
class ModelB: public Airplane {
public:
virtual void fly(const Airport& destination)
{ Airplane::fly(destination); }
...
};
class ModelC: public Airplane {
public:
virtual void fly(const Airport& destination);
...
};
void ModelC::fly(const Airport& destination)
{
code for flying a ModelC airplane to the given destination
}
This is almost exactly the same design as before, except that the body of the pure virtual function Airplane::fly takes the place of the independent function Airplane::defaultFly. In essence, fly has been broken into its two fundamental components. Its declaration specifies its interface (which derived classes must use), while its definition specifies its default behavior (which derived classes may use, but only if they explicitly request it). In merging fly and defaultFly, however, you've lost the ability to give the two functions different protection levels: the code that used to be protected (by being in defaultFly) is now public (because it's in fly).
Finally, we come to Shape's nonvirtual function, objectID. When a member function is nonvirtual, it's not supposed to behave differently in derived classes. In fact, a nonvirtual member function specifies an invariant over specialization, because it identifies behavior that is not supposed to change, no matter how specialized a derived class becomes. As
You can think of the declaration for Shape::objectID as saying, "Every Shape object has a function that yields an object identifier, and that object identifier is always computed in the same way. That way is determined by the definition of Shape::objectID, and no derived class should try to change how it's done." Because a nonvirtual function identifies an invariant over specialization, it should never be redefined in a subclass, a point that is discussed in detail in Item 37.
The differences in declarations for pure virtual, simple virtual, and nonvirtual functions allow you to specify with precision what you want derived classes to inherit: interface only, interface and a default implementation, or interface and a mandatory implementation, respectively. Because these different types of declarations mean fundamentally different things, you must choose carefully among them when you declare your member functions. If you do, you should avoid the two most common mistakes made by inexperienced class
The first mistake is to declare all functions nonvirtual. That leaves no room for specialization in derived classes; nonvirtual destructors are particularly problematic (see Item 14). Of course, it's perfectly reasonable to design a class that is not intended to be used as a base class. Item M34 gives an example of a case where you might want to. In that case, a set of exclusively nonvirtual member functions is appropriate. Too often, however, such classes are declared either out of ignorance of the differences between virtual and nonvirtual functions or as a result of an unsubstantiated concern over the performance cost of virtual functions (see Item M24). The fact of the matter is that almost any class that's to be used as a base class will have virtual functions (again, see Item 14).
If you're concerned about the cost of virtual functions, allow me to bring up the rule of 80-20 (see Item M16), which states that in a typical program, 80 percent of the runtime will be spent executing just 20 percent of the code. This rule is important, because it means that, on average, 80 percent of your function calls can be virtual without having the slightest detectable impact on your program's overall performance. Before you go gray worrying about whether you can afford the cost of a virtual function, then, take the simple precaution of making sure that you're focusing on the 20 percent of your program where the decision might really make a
The other common problem is to declare all member functions virtual. Sometimes this is the right thing to do — witness Protocol classes (see Item 34), for example. However, it can also be a sign of a class designer who lacks the backbone to take a firm stand. Some functions should not be redefinable in derived classes, and whenever that's the case, you've got to say so by making those functions nonvirtual. It serves no one to pretend that your class can be all things to all people if they'll just take the time to redefine all your functions. Remember that if you have a base class B, a derived class D, and a member function mf, then each of the following calls to mf must work
D *pd = new D; B *pb = pd;
pb->mf(); // call mf through a
// pointer-to-base
pd->mf(); // call mf through a
// pointer-to-derived
Sometimes, you must make mf a nonvirtual function to ensure that everything behaves the way it's supposed to (see Item 37). If you have an invariant over specialization, don't be afraid to say
Item 37: Never redefine an inherited nonvirtual function.
There are two ways of looking at this issue: the theoretical way and the pragmatic way. Let's start with the pragmatic way. After all, theoreticians are used to being
Suppose I tell you that a class D is publicly derived from a class B and that there is a public member function mf defined in class B. The parameters and return type of mf are unimportant, so let's just assume they're both void. In other words, I say
class B {
public:
void mf();
...
};
class D: public B { ... };
Even without knowing anything about B, D, or mf, given an object x of type D,
D x; // x is an object of type D
you would probably be quite surprised if
B *pB = &x; // get pointer to x
pB->mf(); // call mf through pointer
behaved differently from
D *pD = &x; // get pointer to x
pD->mf(); // call mf through pointer
That's because in both cases you're invoking the member function mf on the object x. Because it's the same function and the same object in both cases, it should behave the same way,
Right, it should. But it might not. In particular, it won't if mf is nonvirtual and D has defined its own version of mf:
class D: public B {
public:
void mf(); // hides B::mf; see Item 50
...
};
pB->mf(); // calls B::mf
pD->mf(); // calls D::mf
The reason for this two-faced behavior is that nonvirtual functions like B::mf and D::mf are statically bound (see Item 38). That means that because pB is declared to be of type pointer-to-B, nonvirtual functions invoked through pB will always be those defined for class B, even if pB points to an object of a class derived from B, as it does in this
Virtual functions, on the other hand, are dynamically bound (again, see Item 38), so they don't suffer from this problem. If mf were a virtual function, a call to mf through either pB or pD would result in an invocation of D::mf, because what pB and pD really point to is an object of type D.
The bottom line, then, is that if you are writing class D and you redefine a nonvirtual function mf that you inherit from class B, D objects will likely exhibit schizophrenic behavior. In particular, any given D object may act like either a B or a D when mf is called, and the determining factor will have nothing to do with the object itself, but with the declared type of the pointer that points to it. References exhibit the same baffling behavior as do
So much for the pragmatic argument. What you want now, I know, is some kind of theoretical justification for not redefining inherited nonvirtual functions. I am pleased to
Item 35 explains that public inheritance means isa, and Item 36 describes why declaring a nonvirtual function in a class establishes an invariant over specialization for that class. If you apply these observations to the classes B and D and to the nonvirtual member function B::mf,
B objects is also applicable to D objects, because every D object isa B object;
B must inherit both the interface and the implementation of mf, because mf is nonvirtual in B.
Now, if D redefines mf, there is a contradiction in your design. If D really needs to implement mf differently from B, and if every B object — no matter how specialized — really has to use the B implementation for mf, then it's simply not true that every D isa B. In that case, D shouldn't publicly inherit from B. On the other hand, if D really has to publicly inherit from B, and if D really needs to implement mf differently from B, then it's just not true that mf reflects an invariant over specialization for B. In that case, mf should be virtual. Finally, if every D really isa B, and if mf really corresponds to an invariant over specialization for B, then D can't honestly need to redefine mf, and it shouldn't try to do
Regardless of which argument applies, something has to give, and under no conditions is it the prohibition on redefining an inherited nonvirtual
Item 38: Never redefine an inherited default parameter value.
Let's simplify this discussion right from the start. A default parameter can exist only as part of a function, and you can inherit only two kinds of functions: virtual and nonvirtual. Therefore, the only way to redefine a default parameter value is to redefine an inherited function. However, it's always a mistake to redefine an inherited nonvirtual function (see Item 37), so we can safely limit our discussion here to the situation in which you inherit a virtual function with a default parameter
That being the case, the justification for this Item becomes quite straightforward: virtual functions are dynamically bound, but default parameter values are statically
What's that? You say you're not up on the latest object-oriented lingo, or perhaps the difference between static and dynamic binding has slipped your already overburdened mind? Let's review,
An object's static type is the type you declare it to have in the program text. Consider this class
enum ShapeColor { RED, GREEN, BLUE };
// a class for geometric shapes
class Shape {
public:
// all shapes must offer a function to draw themselves
virtual void draw(ShapeColor color = RED) const = 0;
...
};
class Rectangle: public Shape {
public:
// notice the different default parameter value - bad!
virtual void draw(ShapeColor color = GREEN) const;
...
};
class Circle: public Shape {
public:
virtual void draw(ShapeColor color) const;
...
};
Graphically, it looks like this:
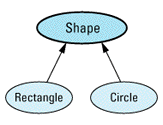
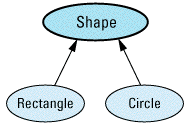
Shape *ps; // static type = Shape*
Shape *pc = new Circle; // static type = Shape*
Shape *pr = new Rectangle; // static type = Shape*
In this example, ps, pc, and pr are all declared to be of type pointer-to-Shape, so they all have that as their static type. Notice that it makes absolutely no difference what they're really pointing to — their static type is Shape*
An object's dynamic type is determined by the type of the object to which it currently refers. That is, its dynamic type indicates how it will behave. In the example above, pc's dynamic type is Circle*, and pr's dynamic type is Rectangle*. As for ps, it doesn't really have a dynamic type, because it doesn't refer to any object
Dynamic types, as their name suggests, can change as a program runs, typically through
ps = pc; // ps's dynamic type is
// now Circle*
ps = pr; // ps's dynamic type is
// now Rectangle*
Virtual functions are dynamically bound, meaning that the particular function called is determined by the dynamic type of the object through which it's
pc->draw(RED); // calls Circle::draw(RED)
pr->draw(RED); // calls Rectangle::draw(RED)
This is all old hat, I know; you surely understand virtual functions. (If you'd like to understand how they're implemented, turn to Item M24.) The twist comes in when you consider virtual functions with default parameter values, because, as I said above, virtual functions are dynamically bound, but default parameters are statically bound. That means that you may end up invoking a virtual function defined in a derived class but using a default parameter value from a base class:
pr->draw(); // calls Rectangle::draw(RED)!
In this case, pr's dynamic type is Rectangle*, so the Rectangle virtual function is called, just as you would expect. In Rectangle::draw, the default parameter value is GREEN. Because pr's static type is Shape*, however, the default parameter value for this function call is taken from the Shape class, not the Rectangle class! The result is a call consisting of a strange and almost certainly unanticipated combination of the declarations for draw in both the Shape and Rectangle classes. Trust me when I tell you that you don't want your software to behave this way, or at least believe me when I tell you that your clients won't want your software to behave this
Needless to say, the fact that ps, pc, and pr are pointers is of no consequence in this matter. Were they references, the problem would persist. The only important things are that draw is a virtual function, and one of its default parameter values is redefined in a
Why does C++ insist on acting in this perverse manner? The answer has to do with runtime efficiency. If default parameter values were dynamically bound, compilers would have to come up with a way of determining the appropriate default value(s) for parameters of virtual functions at runtime, which would be slower and more complicated than the current mechanism of determining them during compilation. The decision was made to err on the side of speed and simplicity of implementation, and the result is that you now enjoy execution behavior that is efficient, but, if you fail to heed the advice of this Item,
Item 39: Avoid casts down the inheritance hierarchy.
In these tumultuous economic times, it's a good idea to keep an eye on our financial institutions, so consider a Protocol class (see Item 34) for bank
class Person { ... };
class BankAccount {
public:
BankAccount(const Person *primaryOwner,
const Person *jointOwner);
virtual ~BankAccount();
virtual void makeDeposit(double amount) = 0; virtual void makeWithdrawal(double amount) = 0;
virtual double balance() const = 0;
...
};
Many banks now offer a bewildering array of account types, but to keep things simple, let's assume there is only one type of bank account, namely, a savings
class SavingsAccount: public BankAccount {
public:
SavingsAccount(const Person *primaryOwner,
const Person *jointOwner);
~SavingsAccount();
void creditInterest(); // add interest to account
...
};
This isn't much of a savings account, but then again, what is these days? At any rate, it's enough for our
A bank is likely to keep a list of all its accounts, perhaps implemented via the list class template from the standard library (see Item 49). Suppose this list is imaginatively named allAccounts:
list<BankAccount*> allAccounts; // all accounts at the
// bank
Like all standard containers, lists store copies of the things placed into them, so to avoid storing multiple copies of each BankAccount, the bank has decided to have allAccounts hold pointers to BankAccounts instead of BankAccounts
Now imagine you're supposed to write the code to iterate over all the accounts, crediting the interest due each one. You might try
// a loop that won't compile (see below if you've never
// seen code using "iterators" before)
for (list<BankAccount*>::iterator p = allAccounts.begin();
p != allAccounts.end();
++p) {
(*p)->creditInterest(); // error!
}
but your compilers would quickly bring you to your senses: allAccounts contains pointers to BankAccount objects, not to SavingsAccount objects, so each time around the loop, p points to a BankAccount. That makes the call to creditInterest invalid, because creditInterest is declared only for SavingsAccount objects, not BankAccounts.
If "list<BankAccount*>::iterator p = allAccounts.begin()" looks to you more like transmission line noise than C++, you've apparently never had the pleasure of meeting the container class templates in the standard library. This part of the library is usually known as the Standard Template Library (the "STL"), and you can get an overview of it in Items 49 and M35. For the time being, all you need to know is that the variable p acts like a pointer that loops through the elements of allAccounts from beginning to end. That is, p acts as if its type were BankAccount** and the list elements were stored in an
It's frustrating that the loop above won't compile. Sure, allAccounts is defined as holding BankAccount*s, but you know that it actually holds SavingsAccount*s in the loop above, because SavingsAccount is the only class that can be instantiated. Stupid compilers! You decide to tell them what you know to be obvious and what they are too dense to figure out on their own: allAccounts really contains SavingsAccount*s:
// a loop that will compile, but that is nonetheless evil
for (list<BankAccount*>::iterator p = allAccounts.begin();
p != allAccounts.end();
++p) {
static_cast<SavingsAccount*>(*p)->creditInterest();
}
All your problems are solved! Solved clearly, solved elegantly, solved concisely, all by the simple use of a cast. You know what type of pointer allAccounts really holds, your dopey compilers don't, so you use a cast to tell them. What could be more
There is a biblical analogy I'd like to draw here. Casts are to C++ programmers what the apple was to
This kind of cast — from a base class pointer to a derived class pointer — is called a downcast, because you're casting down the inheritance hierarchy. In the example you just looked at, downcasting happens to work, but it leads to a maintenance nightmare, as you will soon
But back to the bank. Buoyed by the success of its savings accounts, let's suppose the bank decides to offer checking accounts, too. Furthermore, assume that checking accounts also bear interest, just like savings
class CheckingAccount: public BankAccount {
public:
void creditInterest(); // add interest to account
...
};
Needless to say, allAccounts will now be a list containing pointers to both savings and checking accounts. Suddenly, the interest-crediting loop you wrote above is in serious
Your first problem is that it will continue to compile without your changing it to reflect the existence of CheckingAccount objects. This is because compilers will foolishly believe you when you tell them (through the static_cast) that *p really points to a SavingsAccount*. After all, you're the boss. That's Maintenance Nightmare Number One. Maintenance Nightmare Number Two is what you're tempted to do to fix the problem, which is typically to write code like
for (list<BankAccount*>::iterator p = allAccounts.begin();
p != allAccounts.end();
++p) {
if (*p points to a SavingsAccount)
static_cast<SavingsAccount*>(*p)->creditInterest();
else
static_cast<CheckingAccount*>(*p)->creditInterest();
}
Anytime you find yourself writing code of the form, "if the object is of type T1, then do something, but if it's of type T2, then do something else," slap yourself. That isn't The C++ Way. Yes, it's a reasonable strategy in C, in Pascal, even in Smalltalk, but not in C++. In C++, you use virtual
Remember that with a virtual function, compilers are responsible for making sure that the right function is called, depending on the type of the object being used. Don't litter your code with conditionals or switch statements; let your compilers do the work for you. Here's
class BankAccount { ... }; // as above
// new class representing accounts that bear interest
class InterestBearingAccount: public BankAccount {
public:
virtual void creditInterest() = 0;
...
};
class SavingsAccount: public InterestBearingAccount {
... // as above
};
class CheckingAccount: public InterestBearingAccount {
... // as above
};
Graphically, it looks like
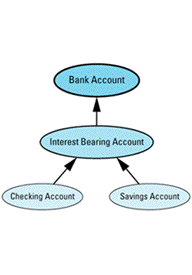
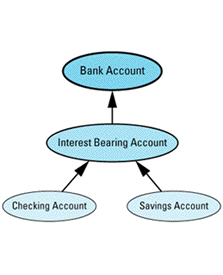
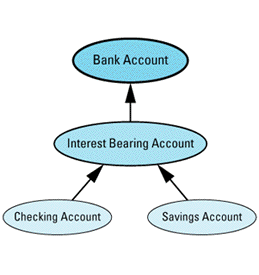
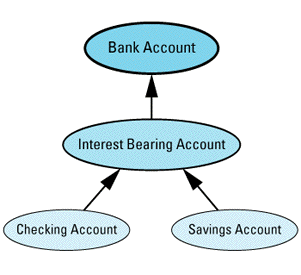
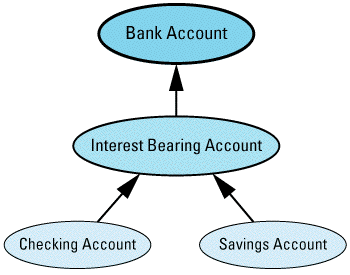
Because both savings and checking accounts earn interest, you'd naturally like to move that common behavior up into a common base class. However, under the assumption that not all accounts in the bank will necessarily bear interest (certainly a valid assumption in my experience), you can't move it into the BankAccount class. As a result, you've introduced a new subclass of BankAccount called InterestBearingAccount, and you've made SavingsAccount and CheckingAccount inherit from
The fact that both savings and checking accounts bear interest is indicated by the InterestBearingAccount pure virtual function creditInterest, which is presumably redefined in its subclasses SavingsAccount and CheckingAccount.
This new class hierarchy allows you to rewrite your loop as
// better, but still not perfect
for (list<BankAccount*>::iterator p = allAccounts.begin();
p != allAccounts.end();
++p) {
static_cast<InterestBearingAccount*>(*p)->creditInterest();
}
Although this loop still contains a nasty little cast, it's much more robust than it used to be, because it will continue to work even if new subclasses of InterestBearingAccount are added to your
To get rid of the cast entirely, you must make some additional changes to your design. One approach is to tighten up the specification of your list of accounts. If you could get a list of InterestBearingAccount objects instead of BankAccount objects, everything would be
// all interest-bearing accounts in the bank list<InterestBearingAccount*> allIBAccounts;
// a loop that compiles and works, both now and forever
for (list<InterestBearingAccount*>::iterator p =
allIBAccounts.begin();
p != allIBAccounts.end();
++p) {
(*p)->creditInterest();
}
If getting a more specialized list isn't an option, it might make sense to say that the creditInterest operation applies to all bank accounts, but that for non-interest-bearing accounts, it's just a no-op. That could be expressed this
class BankAccount {
public:
virtual void creditInterest() {}
...
};
class SavingsAccount: public BankAccount { ... };
class CheckingAccount: public BankAccount { ... };
list<BankAccount*> allAccounts;
// look ma, no cast!
for (list<BankAccount*>::iterator p = allAccounts.begin();
p != allAccounts.end();
++p) {
(*p)->creditInterest();
}
Notice that the virtual function BankAccount::creditInterest provides an empty default implementation. This is a convenient way to specify that its behavior is a no-op by default, but it can lead to unforeseen difficulties in its own right. For the inside story on why, as well as how to eliminate the danger, consult Item 36. Notice also that creditInterest is (implicitly) an inline function. There's nothing wrong with that, but because it's also virtual, the inline directive will probably be ignored. Item 33 explains
As you have seen, downcasts can be eliminated in a number of ways. The best way is to replace such casts with calls to virtual functions, possibly also making each virtual function a no-op for any classes to which it doesn't truly apply. A second method is to tighten up the typing so that there is no ambiguity between the declared type of a pointer and the pointer type that you know is really there. Whatever the effort required to get rid of downcasts, it's effort well spent, because downcasts are ugly and error-prone, and they lead to code that's difficult to understand, enhance, and maintain (see Item M32).
What I've just written is the truth and nothing but the truth. It is not, however, the whole truth. There are occasions when you really do have to perform a
For example, suppose you faced the situation we considered at the outset of this Item, i.e., allAccounts holds BankAccount pointers, creditInterest is defined only for SavingsAccount objects, and you must write a loop to credit interest to every account. Further suppose that all those things are beyond your control; you can't change the definitions for BankAccount, SavingsAccount, or allAccounts. (This would happen if they were defined in a library to which you had read-only access.) If that were the case, you'd have to use downcasting, no matter how distasteful you found the
Nevertheless, there is a better way to do it than through a raw cast such as we saw above. The better way is called "safe downcasting," and it's implemented via C++'s dynamic_cast operator (see Item M2). When you use dynamic_cast on a pointer, the cast is attempted, and if it succeeds (i.e., if the dynamic type of the pointer (see Item 38) is consistent with the type to which it's being cast), a valid pointer of the new type is returned. If the dynamic_cast fails, the null pointer is
Here's the banking example with safe downcasting
class BankAccount { ... }; // as at the beginning of
// this Item
class SavingsAccount: // ditto
public BankAccount { ... };
class CheckingAccount: // ditto again
public BankAccount { ... };
list<BankAccount*> allAccounts; // this should look
// familiar...
void error(const string& msg); // error-handling function;
// see below
// well, ma, at least the casts are safe...
for (list<BankAccount*>::iterator p = allAccounts.begin();
p != allAccounts.end();
++p) {
// try safe-downcasting *p to a SavingsAccount*; see
// below for information on the definition of psa
if (SavingsAccount *psa =
dynamic_cast<SavingsAccount*>(*p)) {
psa->creditInterest();
}
// try safe-downcasting it to a CheckingAccount
else if (CheckingAccount *pca =
dynamic_cast<CheckingAccount*>(*p)) {
pca->creditInterest();
}
// uh oh — unknown account type
else {
error("Unknown account type!");
}
}
This scheme is far from ideal, but at least you can detect when your downcasts fail, something that's impossible without the use of dynamic_cast. Note, however, that prudence dictates you also check for the case where all the downcasts fail. That's the purpose of the final else clause in the code above. With virtual functions, there'd be no need for such a test, because every virtual call must resolve to some function. When you start downcasting, however, all bets are off. If somebody added a new type of account to the hierarchy, for example, but failed to update the code above, all the downcasts would fail. That's why it's important you handle that possibility. In all likelihood, it's not supposed to be the case that all the casts can fail, but when you allow downcasting, bad things start to happen to good
Did you check your glasses in a panic when you noticed what looks like variable definitions in the conditions of the if statements above? If so, worry not; your vision's fine. The ability to define such variables was added to the language at the same time as dynamic_cast. This feature lets you write neater code, because you don't really need psa or pca unless the dynamic_casts that initialize them succeed, and with the new syntax, you don't have to define those variables outside the conditionals containing the casts. (Item 32 explains why you generally want to avoid superfluous variable definitions, anyway.) If your compilers don't yet support this new way of defining variables, you can do it the old
for (list<BankAccount*>::iterator p = allAccounts.begin();
p != allAccounts.end();
++p) {
SavingsAccount *psa; // traditional definition CheckingAccount *pca; // traditional definition
if (psa = dynamic_cast<SavingsAccount*>(*p)) {
psa->creditInterest();
}
else if (pca = dynamic_cast<CheckingAccount*>(*p)) {
pca->creditInterest();
}
else {
error("Unknown account type!");
}
}
In the grand scheme of things, of course, where you place your definitions for variables like psa and pca is of little consequence. The important thing is this: the if-then-else style of programming that downcasting invariably leads to is vastly inferior to the use of virtual functions, and you should reserve it for situations in which you truly have no alternative. With any luck, you will never face such a bleak and desolate programming
Item 40: Model "has-a" or "is-implemented-in-terms-of" through layering.
Layering is the process of building one class on top of another class by having the layering class contain an object of the layered class as a data member. For
class Address { ... }; // where someone lives
class PhoneNumber { ... };
class Person {
public:
...
private: string name; // layered object Address address; // ditto PhoneNumber voiceNumber; // ditto PhoneNumber faxNumber; // ditto };
In this example, the Person class is said to be layered on top of the string, Address, and PhoneNumber classes, because it contains data members of those types. The term layering has lots of synonyms. It's also known as composition, containment, and embedding.
Item 35 explains that public inheritance means "isa." In contrast, layering means either "has-a" or
The Person class above demonstrates the has-a relationship. A Person object has a name, an address, and telephone numbers for voice and FAX communication. You wouldn't say that a person is a name or that a person is an address. You would say that a person has a name and has an address, etc. Most people have little difficulty with this distinction, so confusion between the roles of isa and has-a is relatively
Somewhat more troublesome is the difference between isa and is-implemented-in-terms-of. For example, suppose you need a template for classes representing sets of arbitrary objects, i.e., collections without duplicates. Because reuse is a wonderful thing, and because you wisely read Item 49's overview of the standard C++ library, your first instinct is to employ the library's set template. After all, why write a new template when you can use an established one written by somebody
As you delve into set's documentation, however, you discover a limitation your application can't live with: a set requires that the elements contained within it be totally ordered, i.e., for every pair of objects a and b in the set, it must be possible to determine whether a<b or b<a. For many types, this requirement is easy to satisfy, and having a total ordering among objects allows set to offer certain attractive guarantees regarding its performance. (See Item 49 for more on performance guarantees in the standard library.) Your need, however, is for something more general: a set-like class where objects need not be totally ordered, they need only be what the a==b for objects a and b of the same type. This more modest requirement is better suited to types representing things like colors. Is red less than green or is green less than red? For your application, it seems you'll need to write your own template after
Still, reuse is a wonderful thing. Being the data structure maven you are, you know that of the nearly limitless choices for implementing sets, one particularly simple way is to employ linked lists. But guess what? The list template (which generates linked list classes) is just sitting there in the standard library! You decide to (re)use
In particular, you decide to have your nascent Set template inherit from list. That is, Set<T> will inherit from list<T>. After all, in your implementation, a Set object will in fact be a list object. You thus declare your Set template like
// the wrong way to use list for Set
template<class T>
class Set: public list<T> { ... };
Everything may seem fine and dandy at this point, but in fact there is something quite wrong. As Item 35 explains, if D isa B, everything true of B is also true of D. However, a list object may contain duplicates, so if the value 3051 is inserted into a list<int> twice, that list will contain two copies of 3051. In contrast, a Set may not contain duplicates, so if the value 3051 is inserted into a Set<int> twice, the set contains only one copy of the value. It is thus a vicious lie that a Set isa list, because some of the things that are true for list objects are not true for Set
Because the relationship between these two classes isn't isa, public inheritance is the wrong way to model that relationship. The right way is to realize that a Set object can be implemented in terms of a list
// the right way to use list for Set
template<class T>
class Set {
public:
bool member(const T& item) const;
void insert(const T& item); void remove(const T& item);
int cardinality() const;
private: list<T> rep; // representation for a set };
Set's member functions can lean heavily on functionality already offered by list and other parts of the standard library, so the implementation is neither difficult to write nor thrilling to
template<class T>
bool Set<T>::member(const T& item) const
{ return find(rep.begin(), rep.end(), item) != rep.end(); }
template<class T>
void Set<T>::insert(const T& item)
{ if (!member(item)) rep.push_back(item); }
template<class T>
void Set<T>::remove(const T& item)
{
list<T>::iterator it =
find(rep.begin(), rep.end(), item);
if (it != rep.end()) rep.erase(it); }
template<class T>
int Set<T>::cardinality() const
{ return rep.size(); }
These functions are simple enough that they make reasonable candidates for inlining, though I know you'd want to review the discussion in Item 33 before making any firm inlining decisions. (In the code above, functions like find, begin, end, push_back, etc., are part of the standard library's framework for working with container templates like list. You'll find an overview of this framework in Item 49 and M35.)
It's worth remarking that the Set class interface fails the test of being complete and minimal (see Item 18). In terms of completeness, the primary omission is that of a way to iterate over the contents of a set, something that might well be necessary for many applications (and that is provided by all members of the standard library, including set). An additional drawback is that Set fails to follow the container class conventions embraced by the standard library (see Items 49 and M35), and that makes it more difficult to take advantage of other parts of the library when working with Sets.
Nits about Set's interface, however, shouldn't be allowed to overshadow what Set got indisputably right: the relationship between Set and list. That relationship is not isa (though it initially looked like it might be), it's "is-implemented-in-terms-of," and the use of layering to implement that relationship is something of which any class designer may be justly
Incidentally, when you use layering to relate two classes, you create a compile-time dependency between those classes. For information on why this should concern you, as well as what you can do to allay your worries, turn to Item 34.
Item 41: Differentiate between inheritance and templates.
Consider the following two design
ints, a second class for stacks of strings, a third for stacks of stacks of strings, etc. You're interested only in supporting a minimal interface to the class (see Item 18), so you'll limit your operations to stack creation, stack destruction, pushing objects onto the stack, popping objects off the stack, and determining whether the stack is empty. For this exercise, you'll ignore the classes in the standard library (including stack — see Item 49), because you crave the experience of writing the code yourself. Reuse is a wonderful thing, but when your goal is a deep understanding of how something works, there's nothing quite like diving in and getting your hands dirty.
These two problem specifications sound similar, yet they result in utterly different software designs.
The answer has to do with the relationship between each class's behavior and the type of object being manipulated. With both stacks and cats, you're dealing with a variety of different types (stacks containing objects of type T, cats of breed T), but the question you must ask yourself is this: does the type T affect the behavior of the class? If T does not affect the behavior, you can use a template. If T does affect the behavior, you'll need virtual functions, and you'll therefore use
Here's how you might define a linked-list implementation of a Stack class, assuming that the objects to be stacked are of type T:
class Stack {
public:
Stack();
~Stack();
void push(const T& object); T pop();
bool empty() const; // is stack empty?
private:
struct StackNode { // linked list node
T data; // data at this node
StackNode *next; // next node in list
// StackNode constructor initializes both fields
StackNode(const T& newData, StackNode *nextNode)
: data(newData), next(nextNode) {}
};
StackNode *top; // top of stack
Stack(const Stack& rhs); // prevent copying and Stack& operator=(const Stack& rhs); // assignment (see Item 27) };
Stack objects would thus build data structures that look like
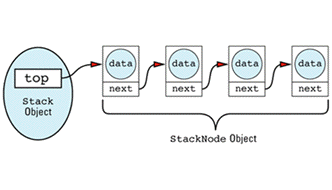
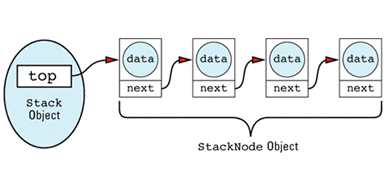
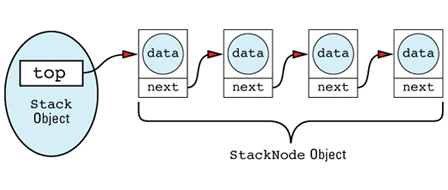
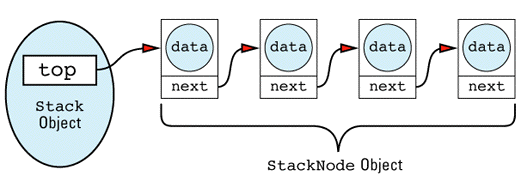
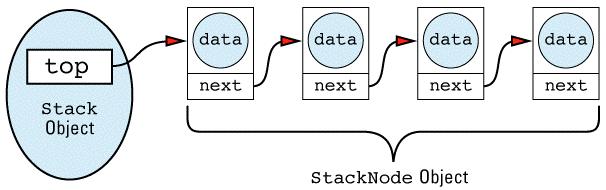
The linked list itself is made up of StackNode objects, but that's an implementation detail of the Stack class, so StackNode has been declared a private type of Stack. Notice that StackNode has a constructor to make sure all its fields are initialized properly. Just because you can write linked lists in your sleep is no reason to omit technological advances such as
Here's a reasonable first cut at how you might implement the Stack member functions. As with many prototype implementations (and far too much production software), there's no checking for errors, because in a prototypical world, nothing ever goes
Stack::Stack(): top(0) {} // initialize top to null
void Stack::push(const T& object)
{
top = new StackNode(object, top); // put new node at
} // front of list
T Stack::pop()
{
StackNode *topOfStack = top; // remember top node
top = top->next;
T data = topOfStack->data; // remember node data delete topOfStack;
return data; }
Stack::~Stack() // delete all in stack
{
while (top) {
StackNode *toDie = top; // get ptr to top node
top = top->next; // move to next node
delete toDie; // delete former top node
}
}
bool Stack::empty() const
{ return top == 0; }
There's nothing riveting about these implementations. In fact, the only interesting thing about them is this: you are able to write each member function knowing essentially nothing about T. (You assume you can call T's copy constructor, but, as Item 45 explains, that's a pretty reasonable assumption.) The code you write for construction, destruction, pushing, popping, and determining whether the stack is empty is the same, no matter what T is. Except for the assumption that you can call T's copy constructor, the behavior of a stack does not depend on T in any way. That's the hallmark of a template class: the behavior doesn't depend on the
Turning your Stack class into a template, by the way, is so simple, even
template<class T> class Stack {
... // exactly the same as above
};
But on to cats. Why won't templates work with
Reread the specification and note the requirement that "each breed of cat eats and sleeps in its own endearing way." That means you're going to have to implement different behavior for each type of cat. You can't just write a single function to handle all cats, all you can do is specify an interface for a function that each type of cat must implement. Aha! The way to propagate a function interface only is to declare a pure virtual function (see Item 36):
class Cat {
public:
virtual ~Cat(); // see Item 14
virtual void eat() = 0; // all cats eat virtual void sleep() = 0; // all cats sleep };
Subclasses of Cat — say, Siamese and BritishShortHairedTabby — must of course redefine the eat and sleep function interfaces they
class Siamese: public Cat {
public:
void eat();
void sleep();
...
};
class BritishShortHairedTabby: public Cat {
public:
void eat();
void sleep();
...
};
Okay, you now know why templates work for the Stack class and why they won't work for the Cat class. You also know why inheritance works for the Cat class. The only remaining question is why inheritance won't work for the Stack class. To see why, try to declare the root class of a Stack hierarchy, the single class from which all other stack classes would
class Stack { // a stack of anything
public:
virtual void push(const ??? object) = 0;
virtual ??? pop() = 0;
...
};
Now the difficulty becomes clear. What types are you going to declare for the pure virtual functions push and pop? Remember that each subclass must redeclare the virtual functions it inherits with exactly the same parameter types and with return types consistent with the base class declarations. Unfortunately, a stack of ints will want to push and pop int objects, whereas a stack of, say, Cats, will want to push and pop Cat objects. How can the Stack class declare its pure virtual functions in such a way that clients can create both stacks of ints and stacks of Cats? The cold, hard truth is that it can't, and that's why inheritance is unsuitable for creating
But maybe you're the sneaky type. Maybe you think you can outsmart your compilers by using generic (void*) pointers. As it turns out, generic pointers don't help you here. You simply can't get around the requirement that a virtual function's declarations in derived classes must never contradict its declaration in the base class. However, generic pointers can help with a different problem, one related to the efficiency of classes generated from templates. For details, see Item 42.
Now that we've dispensed with stacks and cats, we can summarize the lessons of this Item as
Internalize these two little bullet points, and you'll be well on your way to mastering the choice between inheritance and
Item 42: Use private inheritance judiciously.
Item 35 demonstrates that C++ treats public inheritance as an isa relationship. It does this by showing that compilers, when given a hierarchy in which a class Student publicly inherits from a class Person, implicitly convert Students to Persons when that is necessary for a function call to succeed. It's worth repeating a portion of that example using private inheritance instead of public
class Person { ... };
class Student: // this time we use
private Person { ... }; // private inheritance
void dance(const Person& p); // anyone can dance
void study(const Student& s); // only students study
Person p; // p is a Person Student s; // s is a Student
dance(p); // fine, p is a Person
dance(s); // error! a Student isn't
// a Person
Clearly, private inheritance doesn't mean isa. What does it mean
"Whoa!" you say. "Before we get to the meaning, let's cover the behavior. How does private inheritance behave?" Well, the first rule governing private inheritance you've just seen in action: in contrast to public inheritance, compilers will generally not convert a derived class object (such as Student) into a base class object (such as Person) if the inheritance relationship between the classes is private. That's why the call to dance fails for the object s. The second rule is that members inherited from a private base class become private members of the derived class, even if they were protected or public in the base class. So much for
That brings us to meaning. Private inheritance means is-implemented-in-terms-of. If you make a class D privately inherit from a class B, you do so because you are interested in taking advantage of some of the code that has already been written for class B, not because there is any conceptual relationship between objects of type B and objects of type D. As such, private inheritance is purely an implementation technique. Using the terms introduced in Item 36, private inheritance means that implementation only should be inherited; interface should be ignored. If D privately inherits from B, it means that D objects are implemented in terms of B objects, nothing more. Private inheritance means nothing during software design, only during software implementation.
The fact that private inheritance means is-implemented-in-terms-of is a little disturbing, because Item 40 points out that layering can mean the same thing. How are you supposed to choose between them? The answer is simple: use layering whenever you can, use private inheritance whenever you must. When must you? When protected members and/or virtual functions enter the picture — but more on that in a
Item 41 shows a way to write a Stack template that generates classes holding objects of different types. You may wish to familiarize yourself with that Item now. Templates are one of the most useful features in C++, but once you start using them regularly, you'll discover that if you instantiate a template a dozen times, you are likely to instantiate the code for the template a dozen times. In the case of the Stack template, the code making up Stack<int>'s member functions will be completely separate from the code making up Stack<double>'s member functions. Sometimes this is unavoidable, but such code replication is likely to exist even if the template functions could in fact share code. There is a name for the resultant increase in object code size: template-induced code bloat. It is not a good
For certain kinds of classes, you can use generic pointers to avoid it. The classes to which this approach is applicable store pointers instead of objects, and they are implemented
void* pointers to objects.
Here's an example using the non-template Stack class of Item 41, except here it stores generic pointers instead of
class GenericStack {
public:
GenericStack();
~GenericStack();
void push(void *object); void * pop();
bool empty() const;
private:
struct StackNode {
void *data; // data at this node
StackNode *next; // next node in list
StackNode(void *newData, StackNode *nextNode)
: data(newData), next(nextNode) {}
};
StackNode *top; // top of stack
GenericStack(const GenericStack& rhs); // prevent copying and
GenericStack& // assignment (see
operator=(const GenericStack& rhs); // Item 27)
};
Because this class stores pointers instead of objects, it is possible that an object is pointed to by more than one stack (i.e., has been pushed onto multiple stacks). It is thus of critical importance that pop and the class destructor not delete the data pointer of any StackNode object they destroy, although they must continue to delete the StackNode object itself. After all, the StackNode objects are allocated inside the GenericStack class, so they must also be deallocated inside that class. As a result, the implementation of the Stack class in Item 41 suffices almost perfectly for the GenericStack class. The only changes you need to make involve substitutions of void* for T.
The GenericStack class by itself is of little utility — it's too easy to misuse. For example, a client could mistakenly push a pointer to a Cat object onto a stack meant to hold only pointers to ints, and compilers would merrily accept it. After all, a pointer's a pointer when it comes to void*
To regain the type safety to which you have become accustomed, you create interface classes to GenericStack, like
class IntStack { // interface class for ints
public:
void push(int *intPtr) { s.push(intPtr); }
int * pop() { return static_cast<int*>(s.pop()); }
bool empty() const { return s.empty(); }
private: GenericStack s; // implementation };
class CatStack { // interface class for cats
public:
void push(Cat *catPtr) { s.push(catPtr); }
Cat * pop() { return static_cast<Cat*>(s.pop()); }
bool empty() const { return s.empty(); }
private: GenericStack s; // implementation };
As you can see, the IntStack and CatStack classes serve only to enforce strong typing. Only int pointers can be pushed onto an IntStack or popped from it, and only Cat pointers can be pushed onto a CatStack or popped from it. Both IntStack and CatStack are implemented in terms of the class GenericStack, a relationship that is expressed through layering (see Item 40), and IntStack and CatStack will share the code for the functions in GenericStack that actually implement their behavior. Furthermore, the fact that all IntStack and CatStack member functions are (implicitly) inline means that the runtime cost of using these interface classes is zip, zero, nada,
But what if potential clients don't realize that? What if they mistakenly believe that use of GenericStack is more efficient, or what if they're just wild and reckless and think only wimps need type-safety nets? What's to keep them from bypassing IntStack and CatStack and going straight to GenericStack, where they'll be free to make the kinds of type errors C++ was specifically designed to
Nothing. Nothing prevents that. But maybe something
I mentioned at the outset of this Item that an alternative way to assert an is-implemented-in-terms-of relationship between classes is through private inheritance. In this case, that technique offers an advantage over layering, because it allows you to express the idea that GenericStack is too unsafe for general use, that it should be used only to implement other classes. You say that by protecting GenericStack's member
class GenericStack {
protected:
GenericStack();
~GenericStack();
void push(void *object); void * pop();
bool empty() const;
private: ... // same as above };
GenericStack s; // error! constructor is
// protected
class IntStack: private GenericStack {
public:
void push(int *intPtr) { GenericStack::push(intPtr); }
int * pop() { return static_cast<int*>(GenericStack::pop()); }
bool empty() const { return GenericStack::empty(); }
};
class CatStack: private GenericStack {
public:
void push(Cat *catPtr) { GenericStack::push(catPtr); }
Cat * pop() { return static_cast<Cat*>(GenericStack::pop()); }
bool empty() const { return GenericStack::empty(); }
};
IntStack is; // fine
CatStack cs; // also fine
Like the layering approach, the implementation based on private inheritance avoids code duplication, because the type-safe interface classes consist of nothing but inline calls to the underlying GenericStack
Building type-safe interfaces on top of the GenericStack class is a pretty slick maneuver, but it's awfully unpleasant to have to type in all those interface classes by hand. Fortunately, you don't have to. You can use templates to generate them automatically. Here's a template to generate type-safe stack interfaces using private
template<class T>
class Stack: private GenericStack {
public:
void push(T *objectPtr) { GenericStack::push(objectPtr); }
T * pop() { return static_cast<T*>(GenericStack::pop()); }
bool empty() const { return GenericStack::empty(); }
};
This is amazing code, though you may not realize it right away. Because of the template, compilers will automatically generate as many interface classes as you need. Because those classes are type-safe, client type errors are detected during compilation. Because GenericStack's member functions are protected and interface classes use it as a private base class, clients are unable to bypass the interface classes. Because each interface class member function is (implicitly) declared inline, no runtime cost is incurred by use of the type-safe classes; the generated code is exactly the same as if clients programmed with GenericStack directly (assuming compilers respect the inline request — see Item 33). And because GenericStack uses void* pointers, you pay for only one copy of the code for manipulating stacks, no matter how many different types of stack you use in your program. In short, this design gives you code that's both maximally efficient and maximally type safe. It's difficult to do better than
One of the precepts of this book is that C++'s features interact in remarkable ways. This example, I hope you'll agree, is pretty
The insight to carry away from this example is that it could not have been achieved using layering. Only inheritance gives access to protected members, and only inheritance allows for virtual functions to be redefined. (For an example of how the existence of virtual functions can motivate the use of private inheritance, see Item 43.) Because virtual functions and protected members exist, private inheritance is sometimes the only practical way to express an is-implemented-in-terms-of relationship between classes. As a result, you shouldn't be afraid to use private inheritance when it's the most appropriate implementation technique at your disposal. At the same time, however, layering is the preferable technique in general, so you should employ it whenever you
Item 43: Use multiple inheritance judiciously.
Depending on who's doing the talking, multiple inheritance (MI) is either the product of divine inspiration or the manifest work of the devil. Proponents hail it as essential to the natural modeling of real-world problems, while critics argue that it is slow, difficult to implement, and no more powerful than single inheritance. Disconcertingly, the world of object-oriented programming languages remains split on the issue: C++, Eiffel, and the Common LISP Object System (CLOS) offer MI; Smalltalk, Objective C, and Object Pascal do not; and Java supports only a restricted form of it. What's a poor, struggling programmer to
Before you believe anything, you need to get your facts straight. The one indisputable fact about MI in C++ is that it opens up a Pandora's box of complexities that simply do not exist under single inheritance. Of these, the most basic is ambiguity (see Item 26). If a derived class inherits a member name from more than one base class, any reference to that name is ambiguous; you must explicitly say which member you mean. Here's an example that's based on a discussion in the ARM (see Item 50):
class Lottery {
public:
virtual int draw();
...
};
class GraphicalObject {
public:
virtual int draw();
...
};
class LotterySimulation: public Lottery,
public GraphicalObject {
... // doesn't declare draw
};
LotterySimulation *pls = new LotterySimulation;
pls->draw(); // error! — ambiguous pls->Lottery::draw(); // fine pls->GraphicalObject::draw(); // fine
This looks clumsy, but at least it works. Unfortunately, the clumsiness is difficult to eliminate. Even if one of the inherited draw functions were private and hence inaccessible, the ambiguity would remain. (There's a good reason for that, but a complete explanation of the situation is provided in Item 26, so I won't repeat it
Explicitly qualifying members is more than clumsy, however, it's also limiting. When you explicitly qualify a virtual function with a class name, the function doesn't act virtual any longer. Instead, the function called is precisely the one you specify, even if the object on which it's invoked is of a derived
class SpecialLotterySimulation: public LotterySimulation {
public:
virtual int draw();
...
};
pls = new SpecialLotterySimulation;
pls->draw(); // error! — still ambiguous pls->Lottery::draw(); // calls Lottery::draw pls->GraphicalObject::draw(); // calls GraphicalObject::draw
In this case, notice that even though pls points to a SpecialLotterySimulation object, there is no way (short of a downcast — see Item 39) to invoke the draw function defined in that
But wait, there's more. The draw functions in both Lottery and GraphicalObject are declared virtual so that subclasses can redefine them (see Item 36), but what if LotterySimulation would like to redefine both of them? The unpleasant truth is that it can't, because a class is allowed to have only a single function called draw that takes no arguments. (There is a special exception to this rule if one of the functions is const and one is not — see Item 21.)
At one point, this difficulty was considered a serious enough problem to justify a change in the language. The ARM discusses the possibility of allowing inherited virtual functions to be "renamed," but then it was discovered that the problem can be circumvented by the addition of a pair of new
class AuxLottery: public Lottery {
public:
virtual int lotteryDraw() = 0;
virtual int draw() { return lotteryDraw(); }
};
class AuxGraphicalObject: public GraphicalObject {
public:
virtual int graphicalObjectDraw() = 0;
virtual int draw() { return graphicalObjectDraw(); }
};
class LotterySimulation: public AuxLottery,
public AuxGraphicalObject {
public:
virtual int lotteryDraw();
virtual int graphicalObjectDraw();
...
};Each of the two new classes,
AuxLottery and AuxGraphicalObject, essentially declares a new name for the draw function that each inherits. This new name takes the form of a pure virtual function, in this case lotteryDraw and graphicalObjectDraw; the functions are pure virtual so that concrete subclasses must redefine them. Furthermore, each class redefines the draw that it inherits to itself invoke the new pure virtual function. The net effect is that within this class hierarchy, the single, ambiguous name draw has effectively been split into two unambiguous, but operationally equivalent, names: lotteryDraw and graphicalObjectDraw:
LotterySimulation *pls = new LotterySimulation;
Lottery *pl = pls; GraphicalObject *pgo = pls;
// this calls LotterySimulation::lotteryDraw pl->draw();
// this calls LotterySimulation::graphicalObjectDraw pgo->draw();
This strategy, replete as it is with the clever application of pure virtual, simple virtual, and inline functions (see Item 33), should be committed to memory. In the first place, it solves a problem that you may encounter some day. In the second, it can serve to remind you of the complications that can arise in the presence of multiple inheritance. Yes, this tactic works, but do you really want to be forced to introduce new classes just so you can redefine a virtual function? The classes AuxLottery and AuxGraphicalObject are essential to the correct operation of this hierarchy, but they correspond neither to an abstraction in the problem domain nor to an abstraction in the implementation domain. They exist purely as an implementation device — nothing more. You already know that good software is "device independent." That rule of thumb applies here,
The ambiguity problem, interesting though it is, hardly begins to scratch the surface of the issues you'll confront when you flirt with MI. Another one grows out of the empirical observation that an inheritance hierarchy that starts out looking like





has a distressing tendency to evolve into one that looks like
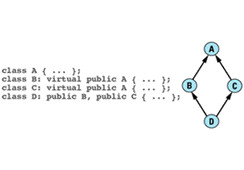




Now, it may or may not be true that diamonds are a girl's best friend, but it is certainly true that a diamond-shaped inheritance hierarchy such as this is not very friendly. If you create a hierarchy such as this, you are immediately confronted with the question of whether to make A a virtual base class, i.e., whether inheritance from A should be virtual. In practice, the answer is almost invariably that it should; only rarely will you want an object of type D to contain multiple copies of the data members of A. In recognition of this truth, B and C above declare A as a virtual base
Unfortunately, at the time you define B and C, you may not know whether any class will decide to inherit from both of them, and in fact you shouldn't need to know this in order to define them correctly. As a class designer, this puts you in a dreadful quandary. If you do not declare A as a virtual base of B and C, a later designer of D may need to modify the definitions of B and C in order to use them effectively. Frequently, this is unacceptable, often because the definitions of A, B, and C are read-only. This would be the case if A, B, and C were in a library, for example, and D was written by a library
On the other hand, if you do declare A as a virtual base of B and C, you typically impose an additional cost in both space and time on clients of those classes. That is because virtual base classes are often implemented as pointers to objects, rather than as objects themselves. It goes without saying that the layout of objects in memory is compiler-dependent, but the fact remains that the memory layout for an object of type D with A as a nonvirtual base is typically a contiguous series of memory locations, whereas the memory layout for an object of type D with A as a virtual base is sometimes a contiguous series of memory locations, two of which contain pointers to the memory locations containing the data members of the virtual base
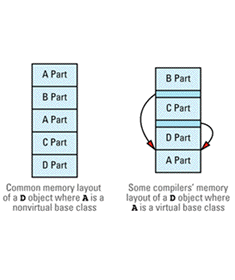
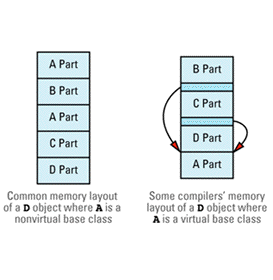
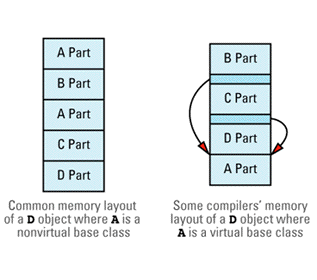
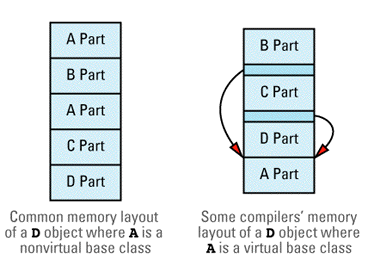
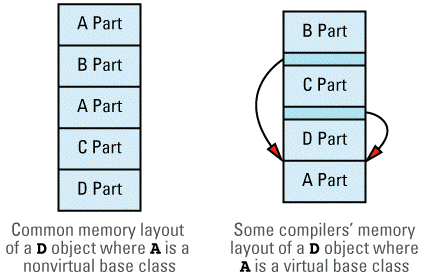
Even compilers that don't use this particular implementation strategy generally impose some kind of space penalty for using virtual
In view of these considerations, it would seem that effective class design in the presence of MI calls for clairvoyance on the part of library designers. Seeing as how run-of-the-mill common sense is an increasingly rare commodity these days, you would be ill-advised to rely too heavily on a language feature that calls for designers to be not only anticipatory of future needs, but downright prophetic (see also M32).
Of course, this could also be said of the choice between virtual and nonvirtual functions in a base class, but there is a crucial difference. Item 36 explains that a virtual function has a well-defined high-level meaning that is distinct from the equally well-defined high-level meaning of a nonvirtual function, so it is possible to choose between the two based on what you want to communicate to writers of subclasses. However, the decision whether a base class should be virtual or nonvirtual lacks a well-defined high-level meaning. Rather, that decision is usually based on the structure of the entire inheritance hierarchy, and as such it cannot be made until the entire hierarchy is known. If you need to know exactly how your class is going to be used before you can define it correctly, it becomes very difficult to design effective
Once you're past the problem of ambiguity and you've settled the question of whether inheritance from your base class(es) should be virtual, still more complications confront you. Rather than belaboring things, I'll simply mention two other issues you need to keep in
A, B, C, and D. Suppose that A defines a virtual member function mf, and C redefines it; B and D, however, do not redefine mf:
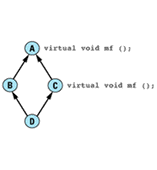
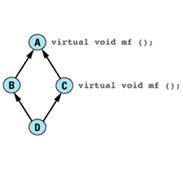
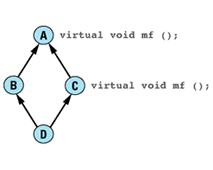
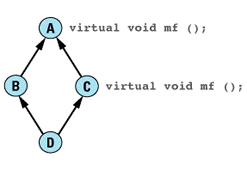
From our earlier discussion, you'd expect this to be
D *pd = new D; pd->mf(); // A::mf or C::mf?
Which mf should be called for a D object, the one directly inherited from C or the one indirectly inherited (via B) from A? The answer is that it depends on how B and C inherit from A. In particular, if A is a nonvirtual base of B or C, the call is ambiguous, but if A is a virtual base of both B and C, the redefinition of mf in C is said to dominate the original definition in A, and the call to mf through pd will resolve (unambiguously) to C::mf. If you sit down and work it all out, it emerges that this is the behavior you want, but it's kind of a pain to have to sit down and work it all out before it makes
Perhaps you are being too
Bear in mind that the designer of C++ didn't set out to make multiple inheritance hard to use, it just turned out that making all the pieces work together in a more or less reasonable fashion inherently entailed the introduction of certain complexities. In the above discussion, you may have noticed that the bulk of these complexities arise in conjunction with the use of virtual base classes. If you can avoid the use of virtual bases — that is, if you can avoid the creation of the deadly diamond inheritance graph — things become much more
For example, Item 34 describes how a Protocol class exists only to specify an interface for derived classes; it has no data members, no constructors, a virtual destructor (see Item 14), and a set of pure virtual functions that specify the interface. A Protocol Person class might look like
class Person {
public:
virtual ~Person();
virtual string name() const = 0; virtual string birthDate() const = 0; virtual string address() const = 0; virtual string nationality() const = 0; };
Clients of this class must program in terms of Person pointers and references, because abstract classes cannot be
To create objects that can be manipulated as Person objects, clients of Person use factory functions (see Item 34) to instantiate concrete subclasses of that
// factory function to create a Person object from a // unique database ID Person * makePerson(DatabaseID personIdentifier);
DatabaseID askUserForDatabaseID();
DatabaseID pid = askUserForDatabaseID();
Person *pp = makePerson(pid); // create object supporting
// the Person interface
... // manipulate *pp via
// Person's member functions
delete pp; // delete the object when
// it's no longer needed
This just begs the question: how does makePerson create the objects to which it returns pointers? Clearly, there must be some concrete class derived from Person that makePerson can
Suppose this class is called MyPerson. As a concrete class, MyPerson must provide implementations for the pure virtual functions it inherits from Person. It could write these from scratch, but it would be better software engineering to take advantage of existing components that already do most or all of what's necessary. For example, let's suppose a creaky old database-specific class PersonInfo already exists that provides the essence of what MyPerson
class PersonInfo {
public:
PersonInfo(DatabaseID pid);
virtual ~PersonInfo();
virtual const char * theName() const; virtual const char * theBirthDate() const; virtual const char * theAddress() const; virtual const char * theNationality() const;
virtual const char * valueDelimOpen() const; // see virtual const char * valueDelimClose() const; // below
...
};
You can tell this is an old class, because the member functions return const char*s instead of string objects. Still, if the shoe fits, why not wear it? The names of this class's member functions suggest that the result is likely to be pretty
You come to discover that PersonInfo, however, was designed to facilitate the process of printing database fields in various formats, with the beginning and end of each field value delimited by special strings. By default, the opening and closing delimiters for field values are braces, so the field value "Ring-tailed Lemur" would be formatted this
[Ring-tailed Lemur]
In recognition of the fact that braces are not universally desired by clients of PersonInfo, the virtual functions valueDelimOpen and valueDelimClose allow derived classes to specify their own opening and closing delimiter strings. The implementations of PersonInfo's theName, theBirthDate, theAddress, and theNationality call these virtual functions to add the appropriate delimiters to the values they return. Using PersonInfo::name as an example, the code looks like
const char * PersonInfo::valueDelimOpen() const
{
return "["; // default opening delimiter
}
const char * PersonInfo::valueDelimClose() const
{
return "]"; // default closing delimiter
}
const char * PersonInfo::theName() const
{
// reserve buffer for return value. Because this is
// static, it's automatically initialized to all zeros
static char value[MAX_FORMATTED_FIELD_VALUE_LENGTH];
// write opening delimiter strcpy(value, valueDelimOpen());
append to the string in value this object's name field
// write closing delimiter strcat(value, valueDelimClose());
return value; }
One might quibble with the design of PersonInfo::theName (especially the use of a fixed-size static buffer — see Item 23), but set your quibbles aside and focus instead on this: theName calls valueDelimOpen to generate the opening delimiter of the string it will return, then it generates the name value itself, then it calls valueDelimClose. Because valueDelimOpen and valueDelimClose are virtual functions, the result returned by theName is dependent not only on PersonInfo, but also on the classes derived from PersonInfo.
As the implementer of MyPerson, that's good news, because while perusing the fine print in the Person documentation, you discover that name and its sister member functions are required to return unadorned values, i.e., no delimiters are allowed. That is, if a person is from Madagascar, a call to that person's nationality function should return "Madagascar", not
The relationship between MyPerson and PersonInfo is that PersonInfo happens to have some functions that make MyPerson easier to implement. That's all. There's no isa or has-a relationship anywhere in sight. Their relationship is thus is-implemented-in-terms-of, and we know that can be represented in two ways: via layering (see Item 40) and via private inheritance (see Item 42). Item 42 points out that layering is the generally preferred approach, but private inheritance is necessary if virtual functions are to be redefined. In this case, MyPerson needs to redefine valueDelimOpen and valueDelimClose, so layering won't do and private inheritance it must be: MyPerson must privately inherit from PersonInfo.
But MyPerson must also implement the Person interface, and that calls for public inheritance. This leads to one reasonable application of multiple inheritance: combine public inheritance of an interface with private inheritance of an
class Person { // this class specifies
public: // the interface to be
virtual ~Person(); // implemented
virtual string name() const = 0; virtual string birthDate() const = 0; virtual string address() const = 0; virtual string nationality() const = 0; };
class DatabaseID { ... }; // used below; details
// are unimportant
class PersonInfo { // this class has functions
public: // useful in implementing
PersonInfo(DatabaseID pid); // the Person interface
virtual ~PersonInfo();
virtual const char * theName() const; virtual const char * theBirthDate() const; virtual const char * theAddress() const; virtual const char * theNationality() const;
virtual const char * valueDelimOpen() const; virtual const char * valueDelimClose() const;
...
};
class MyPerson: public Person, // note use of
private PersonInfo { // multiple inheritance
public:
MyPerson(DatabaseID pid): PersonInfo(pid) {}
// redefinitions of inherited virtual delimiter functions
const char * valueDelimOpen() const { return ""; }
const char * valueDelimClose() const { return ""; }
// implementations of the required Person member functions
string name() const
{ return PersonInfo::theName(); }
string birthDate() const
{ return PersonInfo::theBirthDate(); }
string address() const
{ return PersonInfo::theAddress(); }
string nationality() const
{ return PersonInfo::theNationality(); }
};
Graphically, it looks like
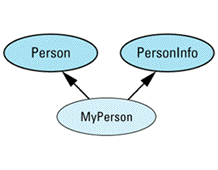
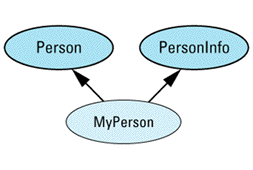
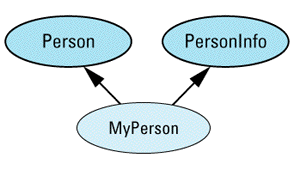
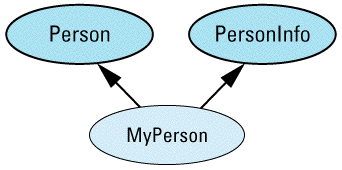
This kind of example demonstrates that MI can be both useful and comprehensible, although it's no accident that the dreaded diamond-shaped inheritance graph is conspicuously
Still, you must guard against temptation. Sometimes you can fall into the trap of using MI to make a quick fix to an inheritance hierarchy that would be better served by a more fundamental redesign. For example, suppose you're working with a hierarchy for animated cartoon characters. At least conceptually, it makes sense for any kind of character to dance and sing, but the way in which each type of character performs these activities differs. Furthermore, the default behavior for singing and dancing is to do
The way to say all that in C++ is like
class CartoonCharacter {
public:
virtual void dance() {}
virtual void sing() {}
};
Virtual functions naturally model the constraint that dancing and singing make sense for all CartoonCharacter objects. Do-nothing default behavior is expressed by the empty definitions of those functions in the class (see Item 36).
Suppose a particular type of cartoon character is a grasshopper, which dances and sings in its own particular way:
class Grasshopper: public CartoonCharacter {
public:
virtual void dance(); // definition is elsewhere
virtual void sing(); // definition is elsewhere
};
Now suppose that after implementing the Grasshopper class, you decide you also need a class for
class Cricket: public CartoonCharacter {
public:
virtual void dance();
virtual void sing();
};
As you sit down to implement the Cricket class, you realize that a lot of the code you wrote for the Grasshopper class can be reused. However, it needs to be tweaked a bit here and there to account for the differences in singing and dancing between grasshoppers and crickets. You are suddenly struck by a clever way to reuse your existing code: you'll implement the Cricket class in terms of the Grasshopper class, and you'll use virtual functions to allow the Cricket class to customize Grasshopper
You immediately recognize that these twin requirements — an is-implemented-in-terms-of relationship and the ability to redefine virtual functions — mean that Cricket will have to privately inherit from Grasshopper, but of course a cricket is still a cartoon character, so you redefine Cricket to inherit from both Grasshopper and CartoonCharacter:
class Cricket: public CartoonCharacter,
private Grasshopper {
public:
virtual void dance();
virtual void sing();
};
You then set out to make the necessary modifications to the Grasshopper class. In particular, you need to declare some new virtual functions for Cricket to
class Grasshopper: public CartoonCharacter {
public:
virtual void dance();
virtual void sing();
protected: virtual void danceCustomization1(); virtual void danceCustomization2();
virtual void singCustomization(); };Dancing for grasshoppers is now defined like this:
void Grasshopper::dance()
{
perform common dancing actions;
danceCustomization1();
perform more common dancing actions;
danceCustomization2();
perform final common dancing actions; }
Grasshopper singing is similarly
Clearly, the Cricket class must be updated to take into account the new virtual functions it must
class Cricket:public CartoonCharacter,
private Grasshopper {
public:
virtual void dance() { Grasshopper::dance(); }
virtual void sing() { Grasshopper::sing(); }
protected: virtual void danceCustomization1(); virtual void danceCustomization2();
virtual void singCustomization(); };
This seems to work fine. When a Cricket object is told to dance, it will execute the common dance code in the Grasshopper class, then execute the dance customization code in the Cricket class, then continue with the code in Grasshopper::dance,
There is a serious flaw in your design, however, and that is that you have run headlong into Occam's razor, a bad idea with a razor of any kind, and especially so when it belongs to William of Occam. Occamism preaches that entities should not be multiplied beyond necessity, and in this case, the entities in question are inheritance relationships. If you believe that multiple inheritance is more complicated than single inheritance (and I hope that you do), then the design of the Cricket class is needlessly
Fundamentally, the problem is that it is not true that the Cricket class is-implemented-in-terms-of the Grasshopper class. Rather, the Cricket class and the Grasshopper class share common code. In particular, they share the code that determines the dancing and singing behavior that grasshoppers and crickets have in
The way to say that two classes have something in common is not to have one class inherit from the other, but to have both of them inherit from a common base class. The common code for grasshoppers and crickets doesn't belong in the Grasshopper class, nor does it belong in the Cricket class. It belongs in a new class from which they both inherit, say, Insect:
class CartoonCharacter { ... };
class Insect: public CartoonCharacter {
public:
virtual void dance(); // common code for both
virtual void sing(); // grasshoppers and crickets
protected: virtual void danceCustomization1() = 0; virtual void danceCustomization2() = 0;
virtual void singCustomization() = 0; };
class Grasshopper: public Insect {
protected:
virtual void danceCustomization1();
virtual void danceCustomization2();
virtual void singCustomization(); };
class Cricket: public Insect {
protected:
virtual void danceCustomization1();
virtual void danceCustomization2();
virtual void singCustomization(); };
Notice how much cleaner this design is. Only single inheritance is involved, and furthermore, only public inheritance is used. Grasshopper and Cricket define only customization functions; they inherit the dance and sing functions unchanged from Insect. William of Occam would be
Although this design is cleaner than the one involving MI, it may initially have appeared to be inferior. After all, compared to the MI approach, this single-inheritance architecture calls for the introduction of a brand new class, a class unnecessary if MI is used. Why introduce an extra class if you don't have
This brings you face to face with the seductive nature of multiple inheritance. On the surface, MI seems to be the easier course of action. It adds no new classes, and though it calls for the addition of some new virtual functions to the Grasshopper class, those functions have to be added somewhere in any
Imagine now a programmer maintaining a large C++ class library, one in which a new class has to be added, much as the Cricket class had to be added to the existing CartoonCharacter/Grasshopper hierarchy. The programmer knows that a large number of clients use the existing hierarchy, so the bigger the change to the library, the greater the disruption to clients. The programmer is determined to minimize that kind of disruption. Mulling over the options, the programmer realizes that if a single private inheritance link from Grasshopper to Cricket is added, no other change to the hierarchy will be needed. The programmer smiles at the thought, pleased with the prospect of a large increase in functionality at the cost of only a slight increase in
Imagine now that that maintenance programmer is you. Resist the
Item 44: Say what you mean; understand what you're saying.
In the introduction to this section on inheritance and object-oriented design, I emphasized the importance of understanding what different object-oriented constructs in C++ mean. This is quite different from just knowing the rules of the language. For example, the rules of C++ say that if class D publicly inherits from class B, there is a standard conversion from a D pointer to a B pointer; that the public member functions of B are inherited as public member functions of D, etc. That's all true, but it's close to useless if you're trying to translate your design into C++. Instead, you need to understand that public inheritance means isa, that if D publicly inherits from B, every object of type D isa object of type B, too. Thus, if you mean isa in your design, you know you have to use public
Saying what you mean is only half the battle. The flip side of the coin is understanding what you're saying, and it's just as important. For example, it's irresponsible, if not downright immoral, to run around declaring member functions nonvirtual without recognizing that in so doing you are imposing constraints on subclasses. In declaring a nonvirtual member function, what you're really saying is that the function represents an invariant over specialization, and it would be disastrous if you didn't know
The equivalence of public inheritance and isa, and of nonvirtual member functions and invariance over specialization, are examples of how certain C++ constructs correspond to design-level ideas. The list below summarizes the most important of these
D1 and class D2 both declare class B as a base, D1 and D2 inherit common data members and/or common member functions from B. See Item 43.
D publicly inherits from class B, every object of type D is also an object of type B, but not vice versa. See Item 35.
D privately inherits from class B, objects of type D are simply implemented in terms of objects of type B; no conceptual relationship exists between objects of types B and D. See Item 42.
A contains a data member of type B, objects of type A either have a component of type B or are implemented in terms of objects of type B. See Item 40.
The following mappings apply only when public inheritance is
C declares a pure virtual member function mf, subclasses of C must inherit the interface for mf, and concrete subclasses of C must supply their own implementations for it. See Item 36.
C declares a simple (not pure) virtual function mf, subclasses of C must inherit the interface for mf, and they may also inherit a default implementation, if they choose. See Item 36.
C declares a nonvirtual member function mf, subclasses of C must inherit both the interface for mf and its implementation. In effect, mf defines an invariant over specialization of C. See Item 36.