Miscellany
Some guidelines for effective C++ programming defy convenient categorization. This section is where such guidelines come to roost. Not that that diminishes their importance. If you are to write effective software, you must understand what compilers are doing for you (to you?) behind your back, how to ensure that non-local static objects are initialized before they are used, what you can expect from the standard library, and where to go for insights into the language's underlying design philosophy. In this final section of the book, I expound on these issues, and more.
Item 45: Know what functions C++ silently writes and calls.
When is an empty class not an empty class? When C++ gets through with it. If you don't declare them yourself, your thoughtful compilers will declare their own versions of a copy constructor, an assignment operator, a destructor, and a pair of address-of operators. Furthermore, if you don't declare any constructors, they will declare a default constructor for you, too. All these functions will be public. In other words, if you write this,
class Empty{};
it's the same as if you'd written this:
class Empty {
public:
Empty(); // default constructor
Empty(const Empty& rhs); // copy constructor
~Empty(); // destructor — see
// below for whether
// it's virtual
Empty&
operator=(const Empty& rhs); // assignment operator
Empty* operator&(); // address-of operators
const Empty* operator&() const;
};
Now these functions are generated only if they are needed, but it doesn't take much to need them. The following code will cause each function to be generated:
const Empty e1; // default constructor;
// destructor
Empty e2(e1); // copy constructor
e2 = e1; // assignment operator
Empty *pe2 = &e2; // address-of
// operator (non-const)
const Empty *pe1 = &e1; // address-of
// operator (const)
Given that compilers are writing functions for you, what do the functions do? Well, the default constructor and the destructor don't really do anything. They just enable you to create and destroy objects of the class. (They also provide a convenient place for implementers to place code whose execution takes care of "behind the scenes" behavior — see Items 33 and M24.) Note that the generated destructor is nonvirtual (see Item 14) unless it's for a class inheriting from a base class that itself declares a virtual destructor. The default address-of operators just return the address of the object. These functions are effectively defined like this:
inline Empty::Empty() {}
inline Empty::~Empty() {}
inline Empty * Empty::operator&() { return this; }
inline const Empty * Empty::operator&() const
{ return this; }
As for the copy constructor and the assignment operator, the official rule is this: the default copy constructor (assignment operator) performs memberwise copy construction (assignment) of the nonstatic data members of the class. That is, if m is a nonstatic data member of type T in a class C and C declares no copy constructor (assignment operator), m will be copy constructed (assigned) using the copy constructor (assignment operator) defined for T, if there is one. If there isn't, this rule will be recursively applied to m's data members until a copy constructor (assignment operator) or built-in type (e.g., int, double, pointer, etc.) is found. By default, objects of built-in types are copy constructed (assigned) using bitwise copy from the source object to the destination object. For classes that inherit from other classes, this rule is applied to each level of the inheritance hierarchy, so user-defined copy constructors and assignment operators are called at whatever level they are declared.
I hope that's crystal clear.
But just in case it's not, here's an example. Consider the definition of a NamedObject template, whose instances are classes allowing you to associate names with objects:
template<class T>
class NamedObject {
public:
NamedObject(const char *name, const T& value);
NamedObject(const string& name, const T& value);
...
private:
string nameValue;
T objectValue;
};
Because the NamedObject classes declare at least one constructor, compilers won't generate default constructors, but because the classes fail to declare copy constructors or assignment operators, compilers will generate those functions (if they are needed).
Consider the following call to a copy constructor:
NamedObject<int> no1("Smallest Prime Number", 2);
NamedObject<int> no2(no1); // calls copy constructor
The copy constructor generated by your compilers must initialize no2.nameValue and no2.objectValue using no1.nameValue and no1.objectValue, respectively. The type of nameValue is string, and string has a copy constructor (which you can verify by examining string in the standard library — see Item 49), so no2.nameValue will be initialized by calling the string copy constructor with no1.nameValue as its argument. On the other hand, the type of NamedObject<int>::objectValue is int (because T is int for this template instantiation), and no copy constructor is defined for ints, so no2.objectValue will be initialized by copying the bits over from no1.objectValue.
The compiler-generated assignment operator for NamedObject<int> would behave the same way, but in general, compiler-generated assignment operators behave as I've described only when the resulting code is both legal and has a reasonable chance of making sense. If either of these tests fails, compilers will refuse to generate an operator= for your class, and you'll receive some lovely diagnostic during compilation.
For example, suppose NamedObject were defined like this, where nameValue is a reference to a string and objectValue is a const T:
template<class T>
class NamedObject {
public:
// this ctor no longer takes a const name, because name-
// Value is now a reference-to-non-const string. The char*
// ctor is gone, because we must have a string to refer to
NamedObject(string& name, const T& value);
... // as above, assume no
// operator= is declared
private:
string& nameValue; // this is now a reference
const T objectValue; // this is now const
};
Now consider what should happen here:
string newDog("Persephone");
string oldDog("Satch");
NamedObject<int> p(newDog, 2); // as I write this, our dog
// °Persephone is about to
// have her second birthday
NamedObject<int> s(oldDog, 29); // the family dog Satch
// (from my childhood)
// would be 29 if she were
// still alive
p = s; // what should happen to
// the data members in p?
Before the assignment, p.nameValue refers to some string object and s.nameValue also refers to a string, though not the same one. How should the assignment affect p.nameValue? After the assignment, should p.nameValue refer to the string referred to by s.nameValue, i.e., should the reference itself be modified? If so, that breaks new ground, because C++ doesn't provide a way to make a reference refer to a different object (see Item M1). Alternatively, should the string object to which p.nameValue refers be modified, thus affecting other objects that hold pointers or references to that string, i.e., objects not directly involved in the assignment? Is that what the compiler-generated assignment operator should do?
Faced with such a conundrum, C++ refuses to compile the code. If you want to support assignment in a class containing a reference member, you must define the assignment operator yourself. Compilers behave similarly for classes containing const members (such as objectValue in the modified class above); it's not legal to modify const members, so compilers are unsure how to treat them during an implicitly generated assignment function. Finally, compilers refuse to generate assignment operators for derived classes that inherit from base classes declaring the standard assignment operator private. After all, compiler-generated assignment operators for derived classes are supposed to handle base class parts, too (see Items 16 and M33), but in doing so, they certainly shouldn't invoke member functions the derived class has no right to call.
All this talk of compiler-generated functions gives rise to the question, what do you do if you want to disallow use of those functions? That is, what if you deliberately don't declare, for example, an operator= because you never ever want to allow assignment of objects in your class? The solution to that little teaser is the subject of Item 27. For a discussion of the often-overlooked interactions between pointer members and compiler-generated copy constructors and assignment operators, check out Item 11.
Item 46: Prefer compile-time and link-time errors to runtime errors.
Other than in the few situations that cause C++ to throw exceptions (e.g., running out of memory — see Item 7), the notion of a runtime error is as foreign to C++ as it is to C. There's no detection of underflow, overflow, division by zero, no checking for array bounds violations, etc. Once your program gets past a compiler and linker, you're on your own — there's no safety net of any consequence. Much as with skydiving, some people are exhilarated by this state of affairs, others are paralyzed with fear. The motivation behind the philosophy, of course, is efficiency: without runtime checks, programs are smaller and faster.
There is a different way to approach things. Languages like Smalltalk and LISP generally detect fewer kinds of errors during compilation and linking, but they provide hefty runtime systems that catch errors during execution. Unlike C++, these languages are almost always interpreted, and you pay a performance penalty for the extra flexibility they offer.
Never forget that you are programming in C++. Even if you find the Smalltalk/LISP philosophy appealing, put it out of your mind. There's a lot to be said for adhering to the party line, and in this case, that means eschewing runtime errors. Whenever you can, push the detection of an error back from runtime to link-time, or, ideally, to compile-time.
Such a methodology pays dividends not only in terms of program size and speed, but also in terms of reliability. If your program gets through compilers and a linker without eliciting error messages, you may be confident there aren't any compiler- or linker-detectable errors in your program, period. (The other possibility, of course, is that there are bugs in your compilers or linkers, but let us not depress ourselves by admitting to such possibilities.)
With runtime errors, the situation is very different. Just because your program doesn't generate any runtime errors during a particular run, how can you be sure it won't generate errors during a different run, when you do things in a different order, use different data, or run for a longer or shorter period of time? You can test your program until you're blue in the face, but you'll still never cover all the possibilities. As a result, detecting errors at runtime is simply less secure than is catching them during compilation or linking.
Often, by making relatively minor changes to your design, you can catch during compilation what might otherwise be a runtime error. This frequently involves the addition of new types to the program. (See also Item M33.) For example, suppose you are writing a class to represent dates in time. Your first cut might look like this:
class Date {
public:
Date(int day, int month, int year);
...
};
If you were to implement this constructor, one of the problems you'd face would be that of sanity checking on the values for the day and the month. Let's see how you can eliminate the need to validate the value passed in for the month.
One obvious approach is to employ an enumerated type instead of an integer:
enum Month { Jan = 1, Feb = 2, ... , Nov = 11, Dec = 12 };
class Date {
public:
Date(int day, Month month, int year);
...
};
Unfortunately, this doesn't buy you that much, because enums don't have to be initialized:
Month m;
Date d(22, m, 1857); // m is undefined
As a result, the Date constructor would still have to validate the value of the month parameter.
To achieve enough security to dispense with runtime checks, you've got to use a class to represent months, and you must ensure that only valid months are created:
class Month {
public:
static const Month Jan() { return 1; }
static const Month Feb() { return 2; }
...
static const Month Dec() { return 12; }
int asInt() const // for convenience, make
{ return monthNumber; } // it possible to convert
// a Month to an int
private:
Month(int number): monthNumber(number) {}
const int monthNumber;
};
class Date {
public:
Date(int day, const Month& month, int year);
...
};
Several aspects of this design combine to make it work the way it does. First, the Month constructor is private. This prevents clients from creating new months. The only ones available are those returned by Month's static member functions, plus copies thereof. Second, each Month object is const, so it can't be changed. (Otherwise the temptation to transform January into June might sometimes prove overwhelming, at least in northern latitudes.) Finally, the only way to get a Month object is by calling a function or by copying an existing Month (via the implicit Month copy constructor — see Item 45). This makes it possible to use Month objects anywhere and anytime; there's no need to worry about accidently using one before it's been initialized. (Item 47 explains why this might otherwise be a problem.)
Given these classes, it is all but impossible for a client to specify an invalid month. It would be completely impossible were it not for the following abomination:
Month *pm; // define uninitialized ptr
Date d(1, *pm, 1997); // arghhh! use it!
However, this involves dereferencing an uninitialized pointer, the results of which are undefined. (See Item 3 for my feelings about undefined behavior.) Unfortunately, I know of no way to prevent or detect this kind of heresy. However, if we assume this never happens, or if we don't care how our software behaves if it does, the Date constructor can dispense with sanity checking on its Month parameter. On the other hand, the constructor must still check the day parameter for validity — how many days hath September, April, June, and November?
This Date example replaces runtime checks with compile-time checks. You may be wondering when it is possible to use link-time checks. In truth, not very often. C++ uses the linker to ensure that needed functions are defined exactly once (see Item 45 for a description of what it takes to "need" a function). It also uses the linker to ensure that static objects (see Item 47) are defined exactly once. You'll tend to use the linker in the same way. For example, Item 27 describes how the linker's checks can make it useful to deliberately avoid defining a function you explicitly declare.
Now don't get carried away. It's impractical to eliminate the need for all runtime checking. Any program that accepts interactive input, for example, is likely to have to validate that input. Similarly, a class implementing arrays that perform bounds checking (see Item 18) is usually going to have to validate the array index against the bounds every time an array access is made. Nonetheless, shifting checks from runtime to compile- or link-time is always a worthwhile goal, and you should pursue that goal whenever it is practical. Your reward for doing so is programs that are smaller, faster, and more reliable.
Item 47: Ensure that non-local static objects are initialized before they're used.
You're an adult now, so you don't need me to tell you it's foolhardy to use an object before it's been initialized. In fact, the whole notion may strike you as absurd; constructors make sure objects are initialized when they're created, n'est-ce pas?
Well, yes and no. Within a particular translation unit (i.e., source file), everything works fine, but things get trickier when the initialization of an object in one translation unit depends on the value of another object in a different translation unit and that second object itself requires initialization.
For example, suppose you've authored a library offering an abstraction of a file system, possibly including such capabilities as making files on the Internet look like they're local. Since your library makes the world look like a single file system, you might create a special object, theFileSystem, within your library's namespace (see Item 28) for clients to use whenever they need to interact with the file system abstraction your library provides:
class FileSystem { ... }; // this class is in your
// library
FileSystem theFileSystem; // this is the object
// with which library
// clients interact
Because theFileSystem represents something complicated, it's no surprise that its construction is both nontrivial and essential; use of theFileSystem before it had been constructed would yield very undefined behavior. (However, consult Item M17 for ideas on how the effective initialization of objects like theFileSystem can safely be delayed.)
Now suppose some client of your library creates a class for directories in a file system. Naturally, their class uses theFileSystem:
class Directory { // created by library client
public:
Directory();
...
};
Directory::Directory()
{
create a Directory object by invoking member
functions on theFileSystem;
}
Further suppose this client decides to create a distinguished global Directory object for temporary files:
Directory tempDir; // directory for temporary
// files
Now the problem of initialization order becomes apparent: unless theFileSystem is initialized before tempDir, tempDir's constructor will attempt to use theFileSystem before it's been initialized. But theFileSystem and tempDir were created by different people at different times in different files. How can you be sure that theFileSystem will be created before tempDir?
This kind of question arises anytime you have non-local static objects that are defined in different translation units and whose correct behavior is dependent on their being initialized in a particular order. Non-local static objects are objects that are
- defined at global or namespace scope (e.g.,
theFileSystem and tempDir),
- declared
static in a class, or
- defined
static at file scope.
Regrettably, there is no shorthand term for "non-local static objects," so you should accustom yourself to this somewhat awkward phrase.
You do not want the behavior of your software to be dependent on the initialization order of non-local static objects in different translation units, because you have no control over that order. Let me repeat that. You have absolutely no control over the order in which non-local static objects in different translation units are initialized.
It is reasonable to wonder why this is the case.
It is the case because determining the "proper" order in which to initialize non-local static objects is hard. Very hard. Halting-Problem hard. In its most general form — with multiple translation units and non-local static objects generated through implicit template instantiations (which may themselves arise via implicit template instantiations) — it's not only impossible to determine the right order of initialization, it's typically not even worth looking for special cases where it is possible to determine the right order.
In the field of Chaos Theory, there is a principle known as the "Butterfly Effect." This principle asserts that the tiny atmospheric disturbance caused by the beating of a butterfly's wings in one part of the world can lead to profound changes in weather patterns in places far distant. Somewhat more rigorously, it asserts that for some types of systems, minute perturbations in inputs can lead to radical changes in outputs.
The development of software systems can exhibit a Butterfly Effect of its own. Some systems are highly sensitive to the particulars of their requirements, and small changes in requirements can significantly affect the ease with which a system can be implemented. For example, Item 29 describes how changing the specification for an implicit conversion from String-to-char* to String-to-const-char* makes it possible to replace a slow or error-prone function with a fast, safe one.
The problem of ensuring that non-local static objects are initialized before use is similarly sensitive to the details of what you want to achieve. If, instead of demanding access to non-local static objects, you're willing to settle for access to objects that act like non-local static objects (except for the initialization headaches), the hard problem vanishes. In its stead is left a problem so easy to solve, it's hardly worth calling a problem any longer.
The technique — sometimes known as the Singleton pattern — is simplicity itself. First, you move each non-local static object into its own function, where you declare it static. Next, you have the function return a reference to the object it contains. Clients call the function instead of referring to the object. In other words, you replace non-local static objects with objects that are static inside functions. (See also Item M26.)
The basis of this approach is the observation that although C++ says next to nothing about when a non-local static object is initialized, it specifies quite precisely when a static object inside a function (i.e. a local static object) is initialized: it's when the object's definition is first encountered during a call to that function. So if you replace direct accesses to non-local static objects with calls to functions that return references to local static objects inside them, you're guaranteed that the references you get back from the functions will refer to initialized objects. As a bonus, if you never call a function emulating a non-local static object, you never incur the cost of constructing and destructing the object, something that can't be said for true non-local static objects.
Here's the technique applied to both theFileSystem and tempDir:
class FileSystem { ... }; // same as before
FileSystem& theFileSystem() // this function replaces
{ // the theFileSystem object
static FileSystem tfs; // define and initialize
// a local static object
// (tfs = "the file system")
return tfs; // return a reference to it
}
class Directory { ... }; // same as before
Directory::Directory()
{
same as before, except references to theFileSystem are
replaced by references to theFileSystem();
}
Directory& tempDir() // this function replaces
{ // the tempDir object
static Directory td; // define/initialize local
// static object
return td; // return reference to it
}
Clients of this modified system program exactly as they used to, except they now refer to theFileSystem() and tempDir() instead of theFileSystem and tempDir. That is, they refer only to functions returning references to those objects, never to the objects themselves.
The reference-returning functions dictated by this scheme are always simple: define and initialize a local static object on line 1, return it on line 2. That's it. Because they're so simple, you may be tempted to declare them inline. Item 33 explains that late-breaking revisions to the C++ language specification make this a perfectly valid implementation strategy, but it also explains why you'll want to confirm your compilers' conformance with this aspect of °the standard before putting it to use. If you try it with a compiler not yet in accord with the relevant parts of the standard, you risk getting multiple copies of both the access function and the static object defined within it. That's enough to make a grown programmer cry.
Now, there's no magic going on here. For this technique to be effective, it must be possible to come up with a reasonable initialization order for your objects. If you set things up such that object A must be initialized before object B, and you also make A's initialization dependent on B's having already been initialized, you are going to get in trouble, and frankly, you deserve it. If you steer shy of such pathological situations, however, the scheme described in this Item should serve you quite nicely.
Item 48: Pay attention to compiler warnings.
Many programmers routinely ignore compiler warnings. After all, if the problem were serious, it'd be an error, right? This kind of thinking may be relatively harmless in other languages, but in C++, it's a good bet compiler writers have a better grasp of what's going on than you do. For example, here's an error everybody makes at one time or another:
class B {
public:
virtual void f() const;
};
class D: public B {
public:
virtual void f();
};
The idea is for D::f to redefine the virtual function B::f, but there's a mistake: in B, f is a const member function, but in D it's not declared const. One compiler I know says this about that:
warning: D::f() hides virtual B::f()
Too many inexperienced programmers respond to this message by saying to themselves, "Of course D::f hides B::f — that's what it's supposed to do!" Wrong. What this compiler is trying to tell you is that the f declared in B has not been redeclared in D, it's been hidden entirely (see Item 50 for a description of why this is so). Ignoring this compiler warning will almost certainly lead to erroneous program behavior, followed by a lot of debugging to find out about something that this compiler detected in the first place.
After you gain experience with the warning messages from a particular compiler, of course, you'll learn to understand what the different messages mean (which is often very different from what they seem to mean, alas). Once you have that experience, there may be a whole range of warnings you'll choose to ignore. That's fine, but it's important to make sure that before you dismiss a warning, you understand exactly what it's trying to tell you.
As long as we're on the topic of warnings, recall that warnings are inherently implementation-dependent, so it's not a good idea to get sloppy in your programming, relying on compilers to spot your mistakes for you. The function-hiding code above, for instance, goes through a different (but widely used) compiler with nary a squawk. Compilers are supposed to translate C++ into an executable format, not act as your personal safety net. You want that kind of safety? Program in Ada.
Item 49: Familiarize yourself with the standard library.
C++'s standard library is big. Very big. Incredibly big. How big? Let me put it this way: the specification takes over 300 closely-packed pages in the °C++ standard, and that all but excludes the standard C library, which is included in the C++ library "by reference." (That's the term they use, honest.)
Bigger isn't always better, of course, but in this case, bigger is better, because a big library contains lots of functionality. The more functionality in the standard library, the more functionality you can lean on as you develop your applications. The C++ library doesn't offer everything (support for concurrency and for graphical user interfaces is notably absent), but it does offer a lot. You can lean almost anything against it.
Before summarizing what's in the library, I need to tell you a bit about how it's organized. Because the library has so much in it, there's a reasonable chance you (or someone like you) may choose a class or function name that's the same as a name in the standard library. To shield you from the name conflicts that would result, virtually everything in the standard library is nestled in the namespace std (see Item 28). But that leads to a new problem. Gazillions of lines of existing C++ rely on functionality in the pseudo-standard library that's been in use for years, e.g., functionality declared in the headers <iostream.h>, <complex.h>, <limits.h>, etc. That existing software isn't designed to use namespaces, and it would be a shame if wrapping the standard library by std caused the existing code to break. (Authors of the broken code would likely use somewhat harsher language than "shame" to describe their feelings about having the library rug pulled out from underneath them.)
Mindful of the destructive power of rioting bands of incensed programmers, the °standardization committee decided to create new header names for the std-wrapped components. The algorithm they chose for generating the new header names is as trivial as the results it produces are jarring: the .h on the existing C++ headers was simply dropped. So <iostream.h> became <iostream>, <complex.h> became <complex>, etc. For C headers, the same algorithm was applied, but a c was prepended to each result. Hence C's <string.h> became <cstring>, <stdio.h> became <cstdio>, etc. For a final twist, the old C++ headers were officially deprecated (i.e., listed as no longer supported), but the old C headers were not (to maintain C compatibility). In practice, compiler vendors have no incentive to disavow their customers' legacy software, so you can expect the old C++ headers to be supported for many years.
Practically speaking, then, this is the C++ header situation:
- Old C++ header names like
<iostream.h> are likely to continue to be supported, even though they aren't in the °official standard. The contents of such headers are not in namespace std.
- New C++ header names like
<iostream> contain the same basic functionality as the corresponding old headers, but the contents of the headers are in namespace std. (During standardization, the details of some of the library components were modified, so there isn't necessarily an exact match between the entities in an old C++ header and those in a new one.)
- Standard C headers like
<stdio.h> continue to be supported. The contents of such headers are not in std.
- New C++ headers for the functionality in the C library have names like
<cstdio>. They offer the same contents as the corresponding old C headers, but the contents are in std.
All this seems a little weird at first, but it's really not that hard to get used to. The biggest challenge is keeping all the string headers straight: <string.h> is the old C header for char*-based string manipulation functions, <string> is the std-wrapped C++ header for the new string classes (see below), and <cstring> is the std-wrapped version of the old C header. If you can master that (and I know you can), the rest of the library is easy.
The next thing you need to know about the standard library is that almost everything in it is a template. Consider your old friend iostreams. (If you and iostreams aren't friends, turn to Item 2 to find out why you should cultivate a relationship.) Iostreams help you manipulate streams of characters, but what's a character? Is it a char? A wchar_t? A Unicode character? Some other multi-byte character? There's no obviously right answer, so the library lets you choose. All the stream classes are really class templates, and you specify the character type when you instantiate a stream class. For example, the standard library defines the type of cout to be ostream, but ostream is really a typedef for basic_ostream<char>.
Similar considerations apply to most of the other classes in the standard library. string isn't a class, it's a class template: a type parameter defines the type of characters in each string class. complex isn't a class, it's a class template: a type parameter defines the type of the real and imaginary components in each complex class. vector isn't a class, it's a class template. On and on it goes.
You can't escape the templates in the standard library, but if you're used to working with only streams and strings of chars, you can mostly ignore them. That's because the library defines typedefs for char instantiations for these components of the library, thus letting you continue to program in terms of the objects cin, cout, cerr, etc., and the types istream, ostream, string, etc., without having to worry about the fact that cin's real type is basic_istream<char> and string's is basic_string<char>.
Many components in the standard library are templatized much more than this suggests. Consider again the seemingly straightforward notion of a string. Sure, it can be parameterized based on the type of characters it holds, but different character sets differ in details, e.g., special end-of-file characters, most efficient way of copying arrays of them, etc. Such characteristics are known in the standard as traits, and they are specified for string instantiations by an additional template parameter. In addition, string objects are likely to perform dynamic memory allocation and deallocation, but there are lots of different ways to approach that task (see Item 10). Which is best? You get to choose: the string template takes an Allocator parameter, and objects of type Allocator are used to allocate and deallocate the memory used by string objects.
Here's a full-blown declaration for the basic_string template and the string typedef that builds on it; you can find this (or something equivalent to it) in the header <string>:
namespace std {
template<class charT,
class traits = char_traits<charT>,
class Allocator = allocator<charT> >
class basic_string;
typedef basic_string<char> string;
}
Notice how basic_string has default values for its traits and Allocator parameters. This is typical of the standard library. It offers flexibility to those who need it, but "typical" clients who just want to do the "normal" thing can ignore the complexity that makes possible the flexibility. In other words, if you just want string objects that act more or less like C strings, you can use string objects and remain merrily ignorant of the fact that you're really using objects of type basic_string<char, char_traits<char>, allocator<char> >.
Well, usually you can. Sometimes you have to peek under the hood a bit. For example, Item 34 discusses the advantages of declaring a class without providing its definition, and it remarks that the following is the wrong way to declare the string type:
class string; // this will compile, but
// you don't want to do it
Setting aside namespace considerations for a moment, the real problem here is that string isn't a class, it's a typedef. It would be nice if you could solve the problem this way:
typedef basic_string<char> string;
but that won't compile. "What is this basic_string of which you speak?," your compilers will wonder, though they'll probably phrase the question rather differently. No, to declare string, you would first have to declare all the templates on which it depends. If you could do it, it would look something like this:
template<class charT> struct char_traits;
template<class T> class allocator;
template<class charT,
class traits = char_traits<charT>,
class Allocator = allocator<charT> >
class basic_string;
typedef basic_string<char> string;
However, you can't declare string. At least you shouldn't. That's because library implementers are allowed to declare string (or anything else in the std namespace) differently from what's specified in °the standard as long as the result offers standard-conforming behavior. For example, a basic_string implementation could add a fourth template parameter, but that parameter's default value would have to yield code that acts as the standard says an unadorned basic_string must.
End result? Don't try to manually declare string (or any other part of the standard library). Instead, just include the appropriate header, e.g. <string>.
With this background on headers and templates under our belts, we're in a position to survey the primary components of the standard C++ library:
- The standard C library. It's still there, and you can still use it. A few minor things have been tweaked here and there, but for all intents and purposes, it's the same C library that's been around for years.
- Iostreams. Compared to "traditional" iostream implementations, it's been templatized, its inheritance hierarchy has been modified, it's been augmented with the ability to throw exceptions, and it's been updated to support strings (via the
stringstream classes) and internationalization (via locales — see below). Still, most everything you've come to expect from the iostream library continues to exist. In particular, it still supports stream buffers, formatters, manipulators, and files, plus the objects cin, cout, cerr, and clog. That means you can treat strings and files as streams, and you have extensive control over stream behavior, including buffering and formatting.
- Strings.
string objects were designed to eliminate the need to use char* pointers in most applications. They support the operations you'd expect (e.g., concatenation, constant-time access to individual characters via operator[], etc.), they're convertible to char*s for compatibility with legacy code, and they handle memory management automatically. Some string implementations employ reference counting (see Item M29), which can lead to better performance (in both time and space) than char*-based strings.
- Containers. Stop writing your own basic container classes! The library offers efficient implementations of vectors (they act like dynamically extensible arrays), lists (doubly-linked), queues, stacks, deques, maps, sets, and bitsets. Alas, there are no hash tables in the library (though many vendors offer them as extensions), but compensating somewhat is the fact that
strings are containers. That's important, because it means anything you can do to a container (see below), you can also do to a string.
What's that? You want to know how I know the library implementations are efficient? Easy: the library specifies each class's interface, and part of each interface specification is a set of performance guarantees. So, for example, no matter how vector is implemented, it's not enough to offer just access to its elements, it must offer constant-time access. If it doesn't, it's not a valid vector implementation.
In many C++ programs, dynamically allocated strings and arrays account for most uses of new and delete, and new/delete errors — especially leaks caused by failure to delete newed memory — are distressingly common. If you use string and vector objects (both of which perform their own memory management) instead of char*s and pointers to dynamically allocated arrays, many of your news and deletes will vanish, and so will the difficulties that frequently accompany their use (e.g., Items 6 and 11).
- Algorithms. Having standard containers is nice, but it's even nicer when there's an easy way to do things with them. The standard library offers over two dozen easy ways (i.e., predefined functions, officially known as algorithms — they're really function templates), most of which work with all the containers in the library — as well as with built-in arrays!
Algorithms treat the contents of a container as a sequence, and each algorithm may be applied to either the sequence corresponding to all the values in a container or to a subsequence. Among the standard algorithms are for_each (apply a function to each element of a sequence), find (find the first location in a sequence holding a given value — Item M35 shows its implementation), count_if (count the number of elements in a sequence for which a given predicate is true), equal (determine whether two sequences hold equal-valued elements), search (find the first position in one sequence where a second sequence occurs as a subsequence), copy (copy one sequence into another), unique (remove duplicate values from a sequence), rotate (rotate the values in a sequence) and sort (sort the values in a sequence). Note that this is just a sampling of the algorithms available; the library contains many others.
Just as container operations come with performance guarantees, so do algorithms. For example, the stable_sort algorithm is required to perform no more than O(N log N) comparisons. (If the "Big O" notation in the previous sentence is foreign to you, don't sweat it. What it really means is that, broadly speaking, stable_sort must offer performance at the same level as the most efficient general-purpose serial sorting algorithms.)
- Support for internationalization. Different cultures do things in different ways. Like the C library, the C++ library offers features to facilitate the production of internationalized software, but the C++ approach, though conceptually akin to that of C, is different. It should not surprise you, for example, to learn that C++'s support for internationalization makes extensive use of templates, and it takes advantage of inheritance and virtual functions, too.
The primary library components supporting internationalization are facets and locales. Facets describe how particular characteristics of a culture should be handled, including collation rules (i.e., how strings in the local character set should be sorted), how dates and times should be expressed, how numeric and monetary values should be presented, how to map from message identifiers to (natural) language-specific messages, etc. Locales bundle together sets of facets. For example, a locale for the United States would include facets describing how to sort strings in American English, read and write dates and times, read and write monetary and numeric values, etc., in a way appropriate for people in the USA. A locale for France, on the other hand, would describe how to perform these tasks in a manner to which the French are accustomed. C++ allows multiple locales to be active within a single program, so different parts of an application may employ different conventions.
- Support for numeric processing. The end for FORTRAN may finally be near. The C++ library offers a template for complex number classes (the precision of the real and imaginary parts may be
float, double, or long double) as well as for special array types specifically designed to facilitate numeric programming. Objects of type valarray, for example, are defined to hold elements that are free from aliasing. This allows compilers to be much more aggressive in their optimizations, especially for vector machines. The library also offers support for two different types of array slices, as well as providing algorithms to compute inner products, partial sums, adjacent differences, and more.
- Diagnostic support. The standard library offers support for three ways to report errors: via C's assertions (see Item 7), via error numbers, and via exceptions. To help provide some structure to exception types, the library defines the following hierarchy of exception classes:
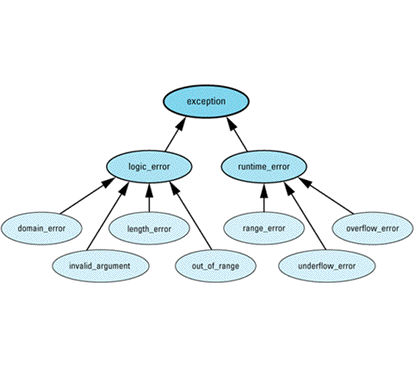
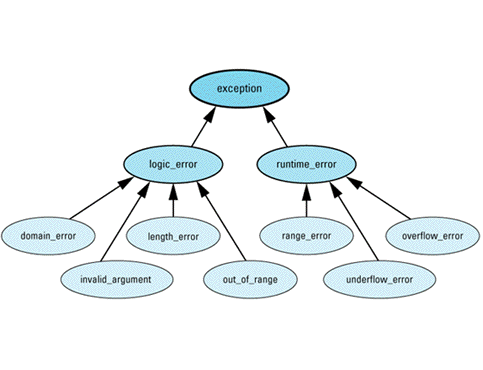
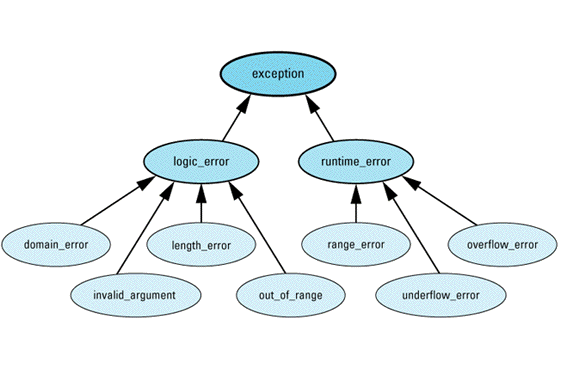
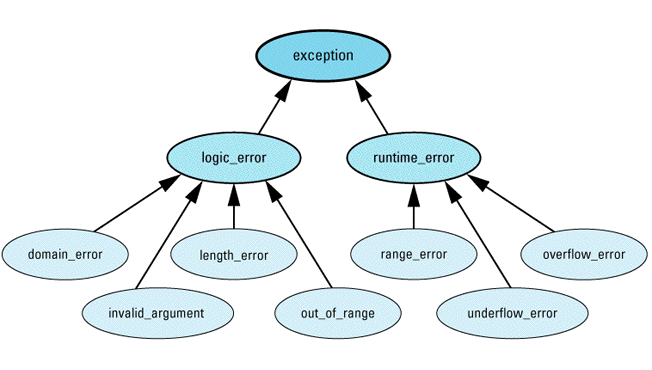
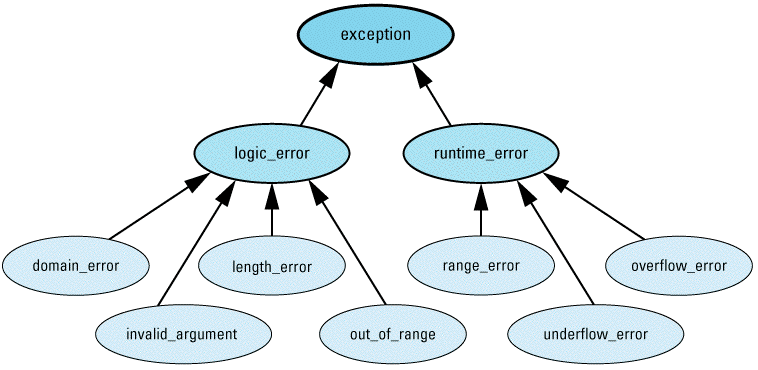
Exceptions of type logic_error (or its subclasses) represent errors in the logic of software. In theory, such errors could have been prevented by more careful programming. Exceptions of type runtime_error (or its derived classes) represent errors detectable only at runtime.
You may use these classes as is, you may inherit from them to create your own exception classes, or you may ignore them. Their use is not mandatory.
This list doesn't describe everything in the standard library. Remember, the specification runs over 300 pages. Still, it should give you the basic lay of the land.
The part of the library pertaining to containers and algorithms is commonly known as Standard Template Library (the STL — see Item M35). There is actually a third component to the STL — Iterators — that I haven't described. Iterators are pointer-like objects that allow STL algorithms and containers to work together. You need not understand iterators for the high-level description of the standard library I give here. If you're interested in them, however, you can find examples of their use in Items 39 and M35.
The STL is the most revolutionary part of the standard library, not because of the containers and algorithms it offers (though they are undeniably useful), but because of its architecture. Simply put, the architecture is extensible: you can add to the STL. Of course, the components of the standard library itself are fixed, but if you follow the conventions on which the STL is built, you can write your own containers, algorithms, and iterators that work as well with the standard STL components as the STL components work with one another. You can also take advantage of STL-compliant containers, algorithms, and iterators written by others, just as they can take advantage of yours. What makes the STL revolutionary is that it's not really software, it's a set of conventions. The STL components in the standard library are simply manifestations of the good that can come from following those conventions.
By using the components in the standard library, you can generally dispense with designing your own from-the-ground-up mechanisms for stream I/O, strings, containers (including iteration and common manipulations), internationalization, numeric data structures, and diagnostics. That leaves you a lot more time and energy for the really important part of software development: implementing the things that distinguish your wares from those of your competitors.
Item 50: Improve your understanding of C++.
There's a lot of stuff in C++. C stuff. Overloading stuff. Object-oriented stuff. Template stuff. Exception stuff. Namespace stuff. Stuff, stuff, stuff! Sometimes it can be overwhelming. How do you make sense of all that stuff?
It's not that hard once you understand the design goals that forged C++ into what it is. Foremost amongst those goals are the following:
- Compatibility with C. Lots and lots of C exists, as do lots and lots of C programmers. C++ takes advantage of and builds on — er, I mean it "leverages" — that base.
- Efficiency. °Bjarne Stroustrup, the designer and first implementer of C++, knew from the outset that the C programmers he hoped to win over wouldn't look twice if they had to pay a performance penalty for switching languages. As a result, he made sure C++ was competitive with C when it came to efficiency — like within 5%.
- Compatibility with traditional tools and environments. Fancy development environments run here and there, but compilers, linkers, and editors run almost everywhere. C++ is designed to work in environments from mice to mainframes, so it brings along as little baggage as possible. You want to port C++? You port a language and take advantage of existing tools on the target platform. (However, it is often possible to provide a better implementation if, for example, the linker can be modified to address some of the more demanding aspects of inlining and templates.)
- Applicability to real problems. C++ wasn't designed to be a nice, pure language, good for teaching students how to program, it was designed to be a powerful tool for professional programmers solving real problems in diverse domains. The real world has some rough edges, so it's no surprise there's the occasional scratch marring the finish of the tools on which the pros rely.
These goals explain a multitude of language details that might otherwise merely chafe. Why do implicitly-generated copy constructors and assignment operators behave the way they do, especially for pointers (see Items 11 and 45)? Because that's how C copies and assigns structs, and compatibility with C is important. Why aren't destructors automatically virtual (see Item 14), and why must implementation details appear in class definitions (see Item 34)? Because doing otherwise would impose a performance penalty, and efficiency is important. Why can't C++ detect initialization dependencies between non-local static objects (see Item 47)? Because C++ supports separate translation (i.e., the ability to compile source modules separately, then link several object files together to form an executable), relies on existing linkers, and doesn't mandate the existence of program databases. As a result, C++ compilers almost never know everything about an entire program. Finally, why doesn't C++ free programmers from tiresome duties like memory management (see Items 5-10) and low-level pointer manipulations? Because some programmers need those capabilities, and the needs of real programmers are of paramount importance.
This barely hints at how the design goals behind C++ shape the behavior of the language. To cover everything would take an entire book, so it's convenient that Stroustrup wrote one. That book is °The Design and Evolution of C++ (Addison-Wesley, 1994), sometimes known as simply "D&E." Read it, and you'll see what features were added to C++, in what order, and why. You'll also learn about features that were rejected, and why. You'll even get the inside story on how the dynamic_cast feature (see Items 39 and M2) was considered, rejected, reconsidered, then accepted — and why. If you're having trouble making sense of C++, D&E should dispel much of your confusion.
The Design and Evolution of C++ offers a wealth of insights into how C++ came to be what it is, but it's nothing like a formal specification for the language. For that you must turn to the °international standard for C++, an impressive exercise in formalese running some 700 pages. There you can read such riveting prose as this:
A virtual function call uses the default arguments in the declaration of the virtual function determined by the static type of the pointer or reference denoting the object. An overriding function in a derived class does not acquire default arguments from the function it overrides.
This paragraph is the basis for Item 38 ("Never redefine an inherited default parameter value"), but I hope my treatment of the topic is somewhat more accessible than the text above.
The standard is hardly bedtime reading, but it's your best recourse — your standard recourse — if you and someone else (a compiler vendor, say, or a developer of some other tool that processes source code) disagree on what is and isn't C++. The whole purpose of a standard is to provide definitive information that settles arguments like that.
The standard's official title is a mouthful, but if you need to know it, you need to know it. Here it is: International Standard for Information Systems—Programming Language C++. It's published by Working Group 21 of the °International Organization for Standardization (ISO). (If you insist on being picky about it, it's really published by — I am not making this up — ISO/IEC JTC1/SC22/WG21.) You can order a copy of the official standard from your national standards body (in the United States, that's ANSI, the °American National Standards Institute), but copies of late drafts of the standard — which are quite similar (though not identical) to the final document — are freely available on the World Wide Web. A good place to look for a copy is at °the Cygnus Solutions Draft Standard C++ Page, but given the pace of change in cyberspace, don't be surprised if this link is broken by the time you try it. If it is, your favorite Web search engine will doubtless turn up a URL that works.
As I said, The Design and Evolution of C++ is fine for insights into the language's design, and the standard is great for nailing down language details, but it would be nice if there were a comfortable middle ground between D&E's view from 10,000 meters and the standard's micron-level examination. Textbooks are supposed to fill this niche, but they generally drift toward the standard's perspective, whereby what the language is receives a lot more attention than why it's that way.
Enter the ARM. The ARM is another book, °The Annotated C++ Reference Manual, by Margaret Ellis and °Bjarne Stroustrup (Addison-Wesley, 1990). Upon its publication, it became the authority on C++, and the international standard started with the ARM (along with the existing C standard) as its basis. In the intervening years, the language specified by the standard has in some ways parted company with that described by the ARM, so the ARM is no longer the authority it once was. It's still a useful reference, however, because most of what it says is still true, and it's not uncommon for vendors to adhere to the ARM specification in areas of C++ where the standard has only recently settled down.
What makes the ARM really useful, however, isn't the RM part (the Reference Manual), it's the A part: the annotations. The ARM provides extensive commentary on why many features of C++ behave the way they do. Some of this information is in D&E, but much of it isn't, and you do want to know it. For instance, here's something that drives most people crazy when they first encounter it:
class Base {
public:
virtual void f(int x);
};
class Derived: public Base {
public:
virtual void f(double *pd);
};
Derived *pd = new Derived;
pd->f(10); // error!
The problem is that Derived::f hides Base::f, even though they take different parameter types, so compilers demand that the call to f take a double*, which the literal 10 most certainly is not.
This is inconvenient, but the ARM provides an explanation for this behavior. Suppose that when you called f, you really did want to call the version in Derived, but you accidentally used the wrong parameter type. Further suppose that Derived is way down in an inheritance hierarchy and that you were unaware that Derived indirectly inherits from some base class BaseClass, and that BaseClass declares a virtual function f that takes an int. In that case, you would have inadvertently called BaseClass::f, a function you didn't even know existed! This kind of error could occur frequently where large class hierarchies are used, so Stroustrup decided to nip it in the bud by having derived class members hide base class members on a per-name basis.
Note, by the way, that if the writer of Derived wants to allow clients to access Base::f, this is easily accomplished via a simple using declaration:
class Derived: public Base {
public:
using Base::f; // import Base::f into
// Derived's scope
virtual void f(double *pd);
};
Derived *pd = new Derived;
pd->f(10); // fine, calls Base::f
For compilers not yet supporting using declarations, an alternative is to employ an inline function:
class Derived: public Base {
public:
virtual void f(int x) { Base::f(x); }
virtual void f(double *pd);
};
Derived *pd = new Derived;
pd->f(10); // fine, calls Derived::f(int),
// which calls Base::f(int)
Between D&E and the ARM, you'll gain insights into the design and implementation of C++ that make it possible to appreciate the sound, no-nonsense architecture behind a sometimes baroque-looking facade. Fortify those insights with the detailed information in the standard, and you've got a foundation for software development that leads to truly effective C++.