Item 24: Understand the costs of virtual functions, multiple inheritance, virtual base classes, and RTTI.
C++ compilers must find a way to implement each feature in the language. Such implementation details are, of course, compiler-dependent, and different compilers implement language features in different ways. For the most part, you need not concern yourself with such matters. However, the implementation of some features can have a noticeable impact on the size of objects and the speed at which member functions execute, so for those features, it's important to have a basic understanding of what compilers are likely to be doing under the hood. The foremost example of such a feature is virtual
When a virtual function is called, the code executed must correspond to the dynamic type of the object on which the function is invoked; the type of the pointer or reference to the object is immaterial. How can compilers provide this behavior efficiently? Most implementations use virtual tables and virtual table pointers. Virtual tables and virtual table pointers are commonly referred to as vtbls and vptrs,
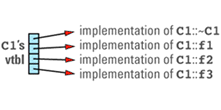
A vtbl is usually an array of pointers to functions. (Some compilers use a form of linked list instead of an array, but the fundamental strategy is the same.) Each class in a program that declares or inherits virtual functions has its own vtbl, and the entries in a class's vtbl are pointers to the implementations of the virtual functions for that class. For example, given a class definition like
class C1 {
public:
C1();
virtual ~C1();
virtual void f1();
virtual int f2(char c) const;
virtual void f3(const string& s);
void f4() const;
...
};
C1's virtual table array will look something like




Note that the nonvirtual function f4 is not in the table, nor is C1's constructor. Nonvirtual functions — including constructors, which are by definition nonvirtual — are implemented just like ordinary C functions, so there are no special performance considerations surrounding their
If a class C2 inherits from C1, redefines some of the virtual functions it inherits, and adds some new ones of its
class C2: public C1 {
public:
C2(); // nonvirtual function
virtual ~C2(); // redefined function
virtual void f1(); // redefined function
virtual void f5(char *str); // new virtual function
...
};
its virtual table entries point to the functions that are appropriate for objects of its type. These entries include pointers to the C1 virtual functions that C2 chose not to
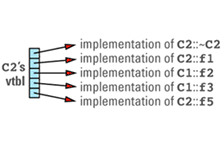
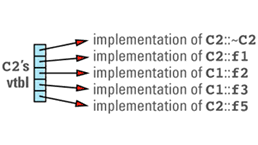
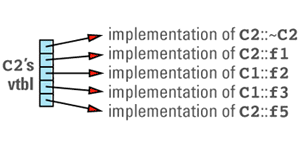


This discussion brings out the first cost of virtual functions: you have to set aside space for a virtual table for each class that contains virtual functions. The size of a class's vtbl is proportional to the number of virtual functions declared for that class (including those it inherits from its base classes). There should be only one virtual table per class, so the total amount of space required for virtual tables is not usually significant, but if you have a large number of classes or a large number of virtual functions in each class, you may find that the vtbls take a significant bite out of your address
Because you need only one copy of a class's vtbl in your programs, compilers must address a tricky problem: where to put it. Most programs and libraries are created by linking together many object files, but each object file is generated independently of the others. Which object file should contain the vtbl for any given class? You might think to put it in the object file containing main, but libraries have no main, and at any rate the source file containing main may make no mention of many of the classes requiring vtbls. How could compilers then know which vtbls they were supposed to
A different strategy must be adopted, and compiler vendors tend to fall into two camps. For vendors who provide an integrated environment containing both compiler and linker, a brute-force strategy is to generate a copy of the vtbl in each object file that might need it. The linker then strips out duplicate copies, leaving only a single instance of each vtbl in the final executable or
A more common design is to employ a heuristic to determine which object file should contain the vtbl for a class. Usually this heuristic is as follows: a class's vtbl is generated in the object file containing the definition (i.e., the body) of the first non-inline non-pure virtual function in that class. Thus, the vtbl for class C1 above would be placed in the object file containing the definition of C1::~C1 (provided that function wasn't inline), and the vtbl for class C2 would be placed in the object file containing the definition of C2::~C2 (again, provided that function wasn't inline).
In practice, this heuristic works well, but you can get into trouble if you go overboard on declaring virtual functions inline (see Item E33). If all virtual functions in a class are declared inline, the heuristic fails, and most heuristic-based implementations then generate a copy of the class's vtbl in every object file that uses it. In large systems, this can lead to programs containing hundreds or thousands of copies of a class's vtbl! Most compilers following this heuristic give you some way to control vtbl generation manually, but a better solution to this problem is to avoid declaring virtual functions inline. As we'll see below, there are good reasons why present compilers typically ignore the inline directive for virtual functions,
Virtual tables are half the implementation machinery for virtual functions, but by themselves they are useless. They become useful only when there is some way of indicating which vtbl corresponds to each object, and it is the job of the virtual table pointer to establish that
Each object whose class declares virtual functions carries with it a hidden data member that points to the virtual table for that class. This hidden data member — the vptr — is added by compilers at a location in the object known only to the compilers. Conceptually, we can think of the layout of an object that has virtual functions as looking like





This picture shows the vptr at the end of the object, but don't be fooled: different compilers put them in different places. In the presence of inheritance, an object's vptr is often surrounded by data members. Multiple inheritance complicates this picture, but we'll deal with that a bit later. At this point, simply note the second cost of virtual functions: you have to pay for an extra pointer inside each object that is of a class containing virtual
If your objects are small, this can be a significant cost. If your objects contain, on average, four bytes of member data, for example, the addition of a vptr can double their size (assuming four bytes are devoted to the vptr). On systems with limited memory, this means the number of objects you can create is reduced. Even on systems with unconstrained memory, you may find that the performance of your software decreases, because larger objects mean fewer fit on each cache or virtual memory page, and that means your paging activity will probably
Suppose we have a program with several objects of types C1 and C2. Given the relationships among objects, vptrs, and vtbls that we have just seen, we can envision the objects in our program like
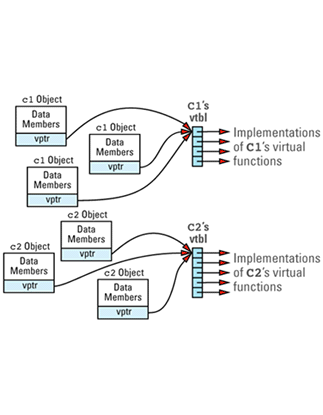
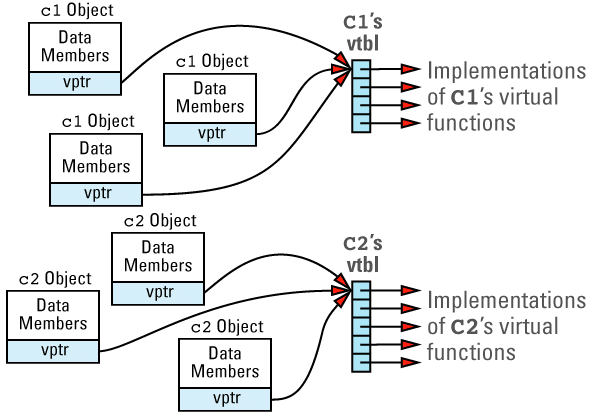
Now consider this program
void makeACall(C1 *pC1)
{
pC1->f1();
}
This is a call to the virtual function f1 through the pointer pC1. By looking only at this code, there is no way to know which f1 function — C1::f1 or C2::f1 — should be invoked, because pC1 might point to a C1 object or to a C2 object. Your compilers must nevertheless generate code for the call to f1 inside makeACall, and they must ensure that the correct function is called, no matter what pC1 points to. They do this by generating code to do the
f1 in this example). This, too, is simple, because compilers assign each virtual function a unique index within the table. The cost of this step is just an offset into the vtbl array.
If we imagine that each object has a hidden member called vptr and that the vtbl index of function f1 is i, the code generated for the
pC1->f1();is
(*pC1->vptr[i])(pC1); // call the function pointed to by the
// i-th entry in the vtbl pointed to
// by pC1->vptr; pC1 is passed to the
// function as the "this" pointer
This is almost as efficient as a non-virtual function call: on most machines it executes only a few more instructions. The cost of calling a virtual function is thus basically the same as that of calling a function through a function pointer. Virtual functions per se are not usually a performance
The real runtime cost of virtual functions has to do with their interaction with inlining. For all practical purposes, virtual functions aren't inlined. That's because "inline" means "during compilation, replace the call site with the body of the called function," but "virtual" means "wait until runtime to see which function is called." If your compilers don't know which function will be called at a particular call site, you can understand why they won't inline that function call. This is the third cost of virtual functions: you effectively give up inlining. (Virtual functions can be inlined when invoked through objects, but most virtual function calls are made through pointers or references to objects, and such calls are not inlined. Because such calls are the norm, virtual functions are effectively not
Everything we've seen so far applies to both single and multiple inheritance, but when multiple inheritance enters the picture, things get more complex (see Item E43). There is no point in dwelling on details, but with multiple inheritance, offset calculations to find vptrs within objects become more complicated; there are multiple vptrs within a single object (one per base class); and special vtbls must be generated for base classes in addition to the stand-alone vtbls we have discussed. As a result, both the per-class and the per-object space overhead for virtual functions increases, and the runtime invocation cost grows slightly,
Multiple inheritance often leads to the need for virtual base classes. Without virtual base classes, if a derived class has more than one inheritance path to a base class, the data members of that base class are replicated within each derived class object, one copy for each path between the derived class and the base class. Such replication is almost never what programmers want, and making base classes virtual eliminates the replication. Virtual base classes may incur a cost of their own, however, because implementations of virtual base classes often use pointers to virtual base class parts as the means for avoiding the replication, and one or more of those pointers may be stored inside your
For example, consider this, which I generally call "the dreaded multiple inheritance





Here A is a virtual base class because B and C virtually inherit from it. With some compilers (especially older compilers), the layout for an object of type D is likely to look like
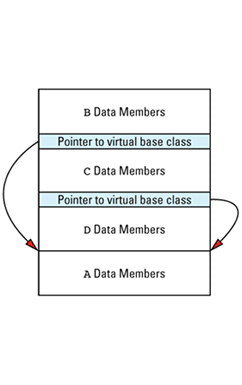
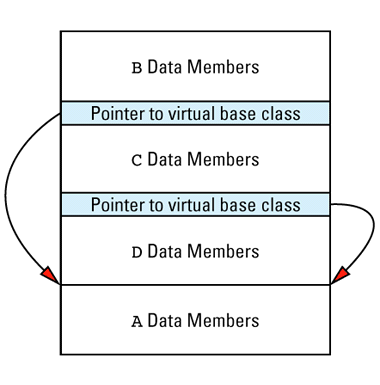
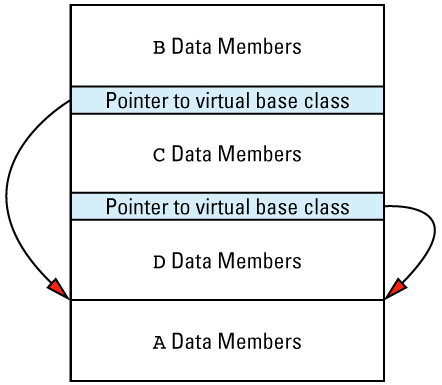
It seems a little strange to place the base class data members at the end of the object, but that's often how it's done. Of course, implementations are free to organize memory any way they like, so you should never rely on this picture for anything more than a conceptual overview of how virtual base classes may lead to the addition of hidden pointers to your objects. Some implementations add fewer pointers, and some find ways to add none at all. (Such implementations make the vptr and vtbl serve double
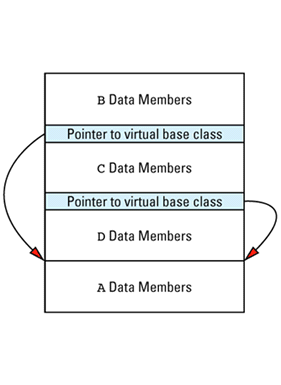
If we combine this picture with the earlier one showing how virtual table pointers are added to objects, we realize that if the base class A in the hierarchy on page 119 has any virtual functions, the memory layout for an object of type D could look like this:


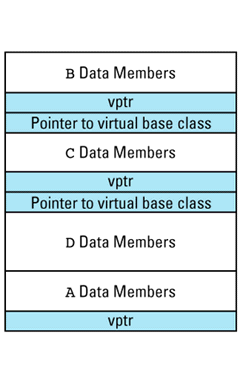

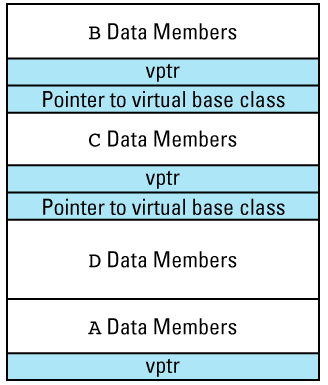
Here I've shaded the parts of the object that are added by compilers. The picture may be misleading, because the ratio of shaded to unshaded areas is determined by the amount of data in your classes. For small classes, the relative overhead is large. For classes with more data, the relative overhead is less significant, though it is typically
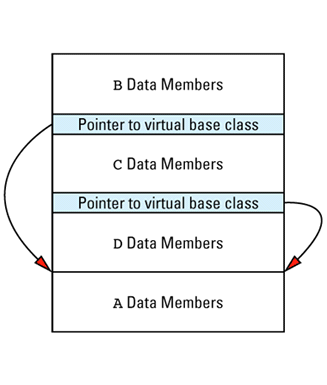
An oddity in the above diagram is that there are only three vptrs even though four classes are involved. Implementations are free to generate four vptrs if they like, but three suffice (it turns out that B and D can share a vptr), and most implementations take advantage of this opportunity to reduce the compiler-generated
We've now seen how virtual functions make objects larger and preclude inlining, and we've examined how multiple inheritance and virtual base classes can also increase the size of objects. Let us therefore turn to our final topic, the cost of runtime type identification
RTTI lets us discover information about objects and classes at runtime, so there has to be a place to store the information we're allowed to query. That information is stored in an object of type type_info, and you can access the type_info object for a class by using the typeid
There only needs to be a single copy of the RTTI information for each class, but there must be a way to get to that information for any object. Actually, that's not quite true. The language specification states that we're guaranteed accurate information on an object's dynamic type only if that type has at least one virtual function. This makes RTTI data sound a lot like a virtual function table. We need only one copy of the information per class, and we need a way to get to the appropriate information from any object containing a virtual function. This parallel between RTTI and virtual function tables is no accident: RTTI was designed to be implementable in terms of a class's
For example, index 0 of a vtbl array might contain a pointer to the type_info object for the class corresponding to that vtbl. The vtbl for class C1 on page 114 would then look like
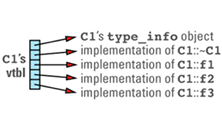




With this implementation, the space cost of RTTI is an additional entry in each class vtbl plus the cost of the storage for the type_info object for each class. Just as the memory for virtual tables is unlikely to be noticeable for most applications, however, you're unlikely to run into problems due to the size of type_info
The following table summarizes the primary costs of virtual functions, multiple inheritance, virtual base classes, and
| Feature | Increases Size of Objects |
Increases Per-Class Data |
Reduces Inlining |
|---|---|---|---|
| Virtual Functions | Yes | Yes | Yes |
| Multiple Inheritance | Yes | Yes | No |
| Virtual Base Classes | Often | Sometimes | No |
| RTTI | No | Yes | No |
Some people look at this table and are aghast. "I'm sticking with C!", they declare. Fair enough. But remember that each of these features offers functionality you'd otherwise have to code by hand. In most cases, your manual approximation would probably be less efficient and less robust than the compiler-generated code. Using nested switch statements or cascading if-then-elses to emulate virtual function calls, for example, yields more code than virtual function calls do, and the code runs more slowly, too. Furthermore, you must manually track object types yourself, which means your objects carry around type tags of their own; you thus often fail to gain even the benefit of smaller
It is important to understand the costs of virtual functions, multiple inheritance, virtual base classes, and RTTI, but it is equally important to understand that if you need the functionality these features offer, you will pay for it, one way or another. Sometimes you have legitimate reasons for bypassing the compiler-generated services. For example, hidden vptrs and pointers to virtual base classes can make it difficult to store C++ objects in databases or to move them across process boundaries, so you may wish to emulate these features in a way that makes it easier to accomplish these other tasks. From the point of view of efficiency, however, you are unlikely to do better than the compiler-generated implementations by coding these features