Smart pointers are objects that are designed to look, act, and feel like built-in pointers, but to offer greater functionality. They have a variety of applications, including resource management (see Items 9, 10, 25, and 31) and the automation of repetitive coding tasks (see Items 17 and 29).
When you use smart pointers in place of C++'s built-in pointers (i.e., dumb pointers), you gain control over the following aspects of pointer
Smart pointers are generated from templates because, like built-in pointers, they must be strongly typed; the template parameter specifies the type of object pointed to. Most smart pointer templates look something like
template<class T> // template for smart
class SmartPtr { // pointer objects
public:
SmartPtr(T* realPtr = 0); // create a smart ptr to an
// obj given a dumb ptr to
// it; uninitialized ptrs
// default to 0 (null)
SmartPtr(const SmartPtr& rhs); // copy a smart ptr
~SmartPtr(); // destroy a smart ptr
// make an assignment to a smart ptr
SmartPtr& operator=(const SmartPtr& rhs);
T* operator->() const; // dereference a smart ptr
// to get at a member of
// what it points to
T& operator*() const; // dereference a smart ptr
private:
T *pointee; // what the smart ptr
}; // points to
The copy constructor and assignment operator are both shown public here. For smart pointer classes where copying and assignment are not allowed, they would typically be declared private (see Item E27). The two dereferencing operators are declared const, because dereferencing a pointer doesn't modify it (though it may lead to modification of what the pointer points to). Finally, each smart pointer-to-T object is implemented by containing a dumb pointer-to-T within it. It is this dumb pointer that does the actual
Before going into the details of smart pointer implementation, it's worth seeing how clients might use smart pointers. Consider a distributed system in which some objects are local and some are remote. Access to local objects is generally simpler and faster than access to remote objects, because remote access may require remote procedure calls or some other way of communicating with a distant
For clients writing application code, the need to handle local and remote objects differently is a nuisance. It is more convenient to have all objects appear to be located in the same place. Smart pointers allow a library to offer this
template<class T> // template for smart ptrs
class DBPtr { // to objects in a
public: // distributed DB
DBPtr(T *realPtr = 0); // create a smart ptr to a
// DB object given a local
// dumb pointer to it
DBPtr(DataBaseID id); // create a smart ptr to a
// DB object given its
// unique DB identifier
... // other smart ptr
}; // functions as above
class Tuple { // class for database
public: // tuples
...
void displayEditDialog(); // present a graphical
// dialog box allowing a
// user to edit the tuple
bool isValid() const; // return whether *this
}; // passes validity check
// class template for making log entries whenever a T
// object is modified; see below for details
template<class T>
class LogEntry {
public:
LogEntry(const T& objectToBeModified);
~LogEntry();
};
void editTuple(DBPtr<Tuple>& pt)
{
LogEntry<Tuple> entry(*pt); // make log entry for this
// editing operation; see
// below for details
// repeatedly display edit dialog until valid values
// are provided
do {
pt->displayEditDialog();
} while (pt->isValid() == false);
}
The tuple to be edited inside editTuple may be physically located on a remote machine, but the programmer writing editTuple need not be concerned with such matters; the smart pointer class hides that aspect of the system. As far as the programmer is concerned, all tuples are accessed through objects that, except for how they're declared, act just like run-of-the-mill built-in
Notice the use of a LogEntry object in editTuple. A more conventional design would have been to surround the call to displayEditDialog with calls to begin and end the log entry. In the approach shown here, the LogEntry's constructor begins the log entry and its destructor ends the log entry. As Item 9 explains, using an object to begin and end logging is more robust in the face of exceptions than explicitly calling functions, so you should accustom yourself to using classes like LogEntry. Besides, it's easier to create a single LogEntry object than to add separate calls to start and stop an
As you can see, using a smart pointer isn't much different from using the dumb pointer it replaces. That's testimony to the effectiveness of encapsulation. Clients of smart pointers are supposed to be able to treat them as dumb pointers. As we shall see, sometimes the substitution is more transparent than
Construction, Assignment, and Destruction of Smart Pointers
Construction of a smart pointer is usually straightforward: locate an object to point to (typically by using the smart pointer's constructor arguments), then make the smart pointer's internal dumb pointer point there. If no object can be located, set the internal pointer to 0 or signal an error (possibly by throwing an
Implementing a smart pointer's copy constructor, assignment operator(s) and destructor is complicated somewhat by the issue of ownership. If a smart pointer owns the object it points to, it is responsible for deleting that object when it (the smart pointer) is destroyed. This assumes the object pointed to by the smart pointer is dynamically allocated. Such an assumption is common when working with smart pointers. (For ideas on how to make sure the assumption is true, see Item 27.)
Consider the auto_ptr template from the standard C++ library. As Item 9 explains, an auto_ptr object is a smart pointer that points to a heap-based object until it (the auto_ptr) is destroyed. When that happens, the auto_ptr's destructor deletes the pointed-to object. The auto_ptr template might be implemented like
template<class T>
class auto_ptr {
public:
auto_ptr(T *ptr = 0): pointee(ptr) {}
~auto_ptr() { delete pointee; }
...
private:
T *pointee;
};
This works fine provided only one auto_ptr owns an object. But what should happen when an auto_ptr is copied or
auto_ptr<TreeNode> ptn1(new TreeNode);
auto_ptr<TreeNode> ptn2 = ptn1; // call to copy ctor;
// what should happen?
auto_ptr<TreeNode> ptn3;
ptn3 = ptn2; // call to operator=;
// what should happen?
If we just copied the internal dumb pointer, we'd end up with two auto_ptrs pointing to the same object. This would lead to grief, because each auto_ptr would delete what it pointed to when the auto_ptr was destroyed. That would mean we'd delete an object more than once. The results of such double-deletes are undefined (and are frequently
An alternative would be to create a new copy of what was pointed to by calling new. That would guarantee we didn't have too many auto_ptrs pointing to a single object, but it might engender an unacceptable performance hit for the creation (and later destruction) of the new object. Furthermore, we wouldn't necessarily know what type of object to create, because an auto_ptr<T> object need not point to an object of type T; it might point to an object of a type derived from T. Virtual constructors (see Item 25) can help solve this problem, but it seems inappropriate to require their use in a general-purpose class like auto_ptr.
The problems would vanish if auto_ptr prohibited copying and assignment, but a more flexible solution was adopted for the auto_ptr classes: object ownership is transferred when an auto_ptr is copied or
template<class T>
class auto_ptr {
public:
...
auto_ptr(auto_ptr<T>& rhs); // copy constructor
auto_ptr<T>& // assignment
operator=(auto_ptr<T>& rhs); // operator
...
};
template<class T>
auto_ptr<T>::auto_ptr(auto_ptr<T>& rhs)
{
pointee = rhs.pointee; // transfer ownership of
// *pointee to *this
rhs.pointee = 0; // rhs no longer owns
} // anything
template<class T>
auto_ptr<T>& auto_ptr<T>::operator=(auto_ptr<T>& rhs)
{
if (this == &rhs) // do nothing if this
return *this; // object is being assigned
// to itself
delete pointee; // delete currently owned
// object
pointee = rhs.pointee; // transfer ownership of
rhs.pointee = 0; // *pointee from rhs to *this
return *this;
}
Notice that the assignment operator must delete the object it owns before assuming ownership of a new object. If it failed to do this, the object would never be deleted. Remember, nobody but the auto_ptr object owns the object the auto_ptr points
Because object ownership is transferred when auto_ptr's copy constructor is called, passing auto_ptrs by value is often a very bad idea. Here's why:
// this function will often lead to disaster
void printTreeNode(ostream& s, auto_ptr<TreeNode> p)
{ s << *p; }
int main()
{
auto_ptr<TreeNode> ptn(new TreeNode);
...
printTreeNode(cout, ptn); // pass auto_ptr by value
...
}
When printTreeNode's parameter p is initialized (by calling auto_ptr's copy constructor), ownership of the object pointed to by ptn is transferred to p. When printTreeNode finishes executing, p goes out of scope and its destructor deletes what it points to (which is what ptn used to point to). ptn, however, no longer points to anything (its underlying dumb pointer is null), so just about any attempt to use it after the call to printTreeNode will yield undefined behavior. Passing auto_ptrs by value, then, is something to be done only if you're sure you want to transfer ownership of an object to a (transient) function parameter. Only rarely will you want to do
This doesn't mean you can't pass auto_ptrs as parameters, it just means that pass-by-value is not the way to do it. Pass-by-reference-to-const
// this function behaves much more intuitively
void printTreeNode(ostream& s,
const auto_ptr<TreeNode>& p)
{ s << *p; }
In this function, p is a reference, not an object, so no constructor is called to initialize p. When ptn is passed to this version of printTreeNode, it retains ownership of the object it points to, and ptn can safely be used after the call to printTreeNode. Thus, passing auto_ptrs by reference-to-const avoids the hazards arising from pass-by-value. (For other reasons to prefer pass-by-reference to pass-by-value, check out Item E22.)
The notion of transferring ownership from one smart pointer to another during copying and assignment is interesting, but you may have been at least as interested in the unconventional declarations of the copy constructor and assignment operator. These functions normally take const parameters, but above they do not. In fact, the code above changes these parameters during the copy or the assignment. In other words, auto_ptr objects are modified if they are copied or are the source of an
Yes, that's exactly what's happening. Isn't it nice that C++ is flexible enough to let you do this? If the language required that copy constructors and assignment operators take const parameters, you'd probably have to cast away the parameters' constness (see Item E21) or play other games to implement ownership transferral. Instead, you get to say exactly what you want to say: when an object is copied or is the source of an assignment, that object is changed. This may not seem intuitive, but it's simple, direct, and, in this case,
If you find this examination of auto_ptr member functions interesting, you may wish to see a complete implementation. You'll find one on pages 291-294, where you'll also see that the auto_ptr template in the standard C++ library has copy constructors and assignment operators that are more flexible than those described here. In the standard auto_ptr template, those functions are member function templates, not just member functions. (Member function templates are described later in this Item. You can also read about them in Item E25.)
A smart pointer's destructor often looks like this:
template<class T>
SmartPtr<T>::~SmartPtr()
{
if (*this owns *pointee) {
delete pointee;
}
}
Sometimes there is no need for the test. An auto_ptr always owns what it points to, for example. At other times the test is a bit more complicated. A smart pointer that employs reference counting (see Item 29) must adjust a reference count before determining whether it has the right to delete what it points to. Of course, some smart pointers are like dumb pointers: they have no effect on the object they point to when they themselves are
Implementing the Dereferencing Operators
Let us now turn our attention to the very heart of smart pointers, the operator* and operator-> functions. The former returns the object pointed to. Conceptually, this is
template<class T>
T& SmartPtr<T>::operator*() const
{
perform "smart pointer" processing;
return *pointee;
}
First the function does whatever processing is needed to initialize or otherwise make pointee valid. For example, if lazy fetching is being used (see Item 17), the function may have to conjure up a new object for pointee to point to. Once pointee is valid, the operator* function just returns a reference to the pointed-to
Note that the return type is a reference. It would be disastrous to return an object instead, though compilers will let you do it. Bear in mind that pointee need not point to an object of type T; it may point to an object of a class derived from T. If that is the case and your operator* function returns a T object instead of a reference to the actual derived class object, your function will return an object of the wrong type! (This is the slicing problem. See Item E22 and Item 13.) Virtual functions invoked on the object returned from your star-crossed operator* will not invoke the function corresponding to the dynamic type of the pointed-to object. In essence, your smart pointer will not properly support virtual functions, and how smart is a pointer like that? Besides, returning a reference is more efficient anyway, because there is no need to construct a temporary object (see Item 19). This is one of those happy occasions when correctness and efficiency go hand in
If you're the kind who likes to worry, you may wonder what you should do if somebody invokes operator* on a null smart pointer, i.e., one whose embedded dumb pointer is null. Relax. You can do anything you want. The result of dereferencing a null pointer is undefined, so there is no "wrong" behavior. Wanna throw an exception? Go ahead, throw it. Wanna call abort (possibly by having an assert call fail)? Fine, call it. Wanna walk through memory setting every byte to your birth date modulo 256? That's okay, too. It's not nice, but as far as the language is concerned, you are completely
The story with operator-> is similar to that for operator*, but before examining operator->, let us remind ourselves of the unusual meaning of a call to this function. Consider again the editTuple function that uses a smart pointer-to-Tuple
void editTuple(DBPtr<Tuple>& pt)
{
LogEntry<Tuple> entry(*pt);
do {
pt->displayEditDialog();
} while (pt->isValid() == false);
}
pt->displayEditDialog();is interpreted by compilers as:
(pt.operator->())->displayEditDialog();
That means that whatever operator-> returns, it must be legal to apply the member-selection operator (->) to it. There are thus only two things operator-> can return: a dumb pointer to an object or another smart pointer object. Most of the time, you'll want to return an ordinary dumb pointer. In those cases, you implement operator-> as
template<class T>
T* SmartPtr<T>::operator->() const
{
perform "smart pointer" processing;
return pointee;
}
This will work fine. Because this function returns a pointer, virtual function calls via operator-> will behave the way they're supposed
For many applications, this is all you need to know about smart pointers. The reference-counting code of Item 29, for example, draws on no more functionality than we've discussed here. If you want to push your smart pointers further, however, you must know more about dumb pointer behavior and how smart pointers can and cannot emulate it. If your motto is "Most people stop at the Z — but not me!", the material that follows is for
Testing Smart Pointers for Nullness
With the functions we have discussed so far, we can create, destroy, copy, assign, and dereference smart pointers. One of the things we cannot do, however, is find out if a smart pointer is
SmartPtr<TreeNode> ptn; ... if (ptn == 0) ... // error! if (ptn) ... // error! if (!ptn) ... // error!
It would be easy to add an isNull member function to our smart pointer classes, but that wouldn't address the problem that smart pointers don't act like dumb pointers when testing for nullness. A different approach is to provide an implicit conversion operator that allows the tests above to compile. The conversion traditionally employed for this purpose is to void*:
template<class T>
class SmartPtr {
public:
...
operator void*(); // returns 0 if the smart
... // ptr is null, nonzero
}; // otherwise
SmartPtr<TreeNode> ptn;
...
if (ptn == 0) ... // now fine
if (ptn) ... // also fine
if (!ptn) ... // fine
This is similar to a conversion provided by the iostream classes, and it explains why it's possible to write code like
ifstream inputFile("datafile.dat");
if (inputFile) ... // test to see if inputFile
// was successfully
// opened
Like all type conversion functions, this one has the drawback of letting function calls succeed that most programmers would expect to fail (see Item 5). In particular, it allows comparisons of smart pointers of completely different
SmartPtr<Apple> pa; SmartPtr<Orange> po; ... if (pa == po) ... // this compiles!
Even if there is no operator== taking a SmartPtr<Apple> and a SmartPtr<Orange>, this compiles, because both smart pointers can be implicitly converted into void* pointers, and there is a built-in comparison function for built-in pointers. This kind of behavior makes implicit conversion functions dangerous. (Again, see Item 5, and keep seeing it over and over until you can see it in the
There are variations on the conversion-to-void* motif. Some designers advocate conversion to const void*, others embrace conversion to bool. Neither of these variations eliminates the problem of allowing mixed-type
There is a middle ground that allows you to offer a reasonable syntactic form for testing for nullness while minimizing the chances of accidentally comparing smart pointers of different types. It is to overload operator! for your smart pointer classes so that operator! returns true if and only if the smart pointer on which it's invoked is
template<class T>
class SmartPtr {
public:
...
bool operator!() const; // returns true if and only
... // if the smart ptr is null
};
This lets your clients program like
SmartPtr<TreeNode> ptn;
...
if (!ptn) { // fine
... // ptn is null
}
else {
... // ptn is not null
}
but not like this:
if (ptn == 0) ... // still an error if (ptn) ... // also an error
The only risk for mixed-type comparisons is statements such as
SmartPtr<Apple> pa; SmartPtr<Orange> po; ... if (!pa == !po) ... // alas, this compiles
Fortunately, programmers don't write code like this very often. Interestingly, iostream library implementations provide an operator! in addition to the implicit conversion to void*, but these two functions typically test for slightly different stream states. (In the C++ library standard (see Item E49 and Item 35), the implicit conversion to void* has been replaced by an implicit conversion to bool, and operator bool always returns the negation of operator!.)
Converting Smart Pointers to Dumb Pointers
Sometimes you'd like to add smart pointers to an application or library that already uses dumb pointers. For example, your distributed database system may not originally have been distributed, so you may have some old library functions that aren't designed to use smart
class Tuple { ... }; // as before
void normalize(Tuple *pt); // put *pt into canonical
// form; note use of dumb
// pointer
Consider what will happen if you try to call normalize with a smart pointer-to-Tuple:
DBPtr<Tuple> pt; ... normalize(pt); // error!
The call will fail to compile, because there is no way to convert a DBPtr<Tuple> to a Tuple*. You can make it work by doing
normalize(&*pt); // gross, but legal
but I hope you'll agree this is
The call can be made to succeed by adding to the smart pointer-to-T template an implicit conversion operator to a dumb
template<class T> // as before
class DBPtr {
public:
...
operator T*() { return pointee; }
...
};
DBPtr<Tuple> pt;
...
normalize(pt); // this now works
Addition of this function also eliminates the problem of testing for
if (pt == 0) ... // fine, converts pt to a
// Tuple*
if (pt) ... // ditto
if (!pt) ... // ditto (reprise)
However, there is a dark side to such conversion functions. (There almost always is. Have you been seeing Item 5?) They make it easy for clients to program directly with dumb pointers, thus bypassing the smarts your pointer-like objects are designed to
void processTuple(DBPtr<Tuple>& pt)
{
Tuple *rawTuplePtr = pt; // converts DBPtr<Tuple> to
// Tuple*
use rawTuplePtr to modify the tuple;
}
Usually, the "smart" behavior provided by a smart pointer is an essential component of your design, so allowing clients to use dumb pointers typically leads to disaster. For example, if DBPtr implements the reference-counting strategy of Item 29, allowing clients to manipulate dumb pointers directly will almost certainly lead to bookkeeping errors that corrupt the reference-counting data
Even if you provide an implicit conversion operator to go from a smart pointer to the dumb pointer it's built on, your smart pointer will never be truly interchangeable with the dumb pointer. That's because the conversion from a smart pointer to a dumb pointer is a user-defined conversion, and compilers are forbidden from applying more than one such conversion at a time. For example, suppose you have a class representing all the clients who have accessed a particular
class TupleAccessors {
public:
TupleAccessors(const Tuple *pt); // pt identifies the
... // tuple whose accessors
}; // we care about
As usual, TupleAccessors' single-argument constructor also acts as a type-conversion operator from Tuple* to TupleAccessors (see Item 5). Now consider a function for merging the information in two TupleAccessors
TupleAccessors merge(const TupleAccessors& ta1,
const TupleAccessors& ta2);
Because a Tuple* may be implicitly converted to a TupleAccessors, calling merge with two dumb Tuple* pointers is
Tuple *pt1, *pt2;
...
merge(pt1, pt2); // fine, both pointers are converted
// to TupleAccessors objects
The corresponding call with smart DBPtr<Tuple> pointers, however, fails to
DBPtr<Tuple> pt1, pt2;
...
merge(pt1, pt2); // error! No way to convert pt1 and
// pt2 to TupleAccessors objects
That's because a conversion from DBPtr<Tuple> to TupleAccessors calls for two user-defined conversions (one from DBPtr<Tuple> to Tuple* and one from Tuple* to TupleAccessors), and such sequences of conversions are prohibited by the
Smart pointer classes that provide an implicit conversion to a dumb pointer open the door to a particularly nasty bug. Consider this
DBPtr<Tuple> pt = new Tuple; ... delete pt;
This should not compile. After all, pt is not a pointer, it's an object, and you can't delete an object. Only pointers can be deleted,
Right. But remember from Item 5 that compilers use implicit type conversions to make function calls succeed whenever they can, and recall from Item 8 that use of the delete operator leads to calls to a destructor and to operator delete, both of which are functions. Compilers want these function calls to succeed, so in the delete statement above, they implicitly convert pt to a Tuple*, then they delete that. This will almost certainly break your
If pt owns the object it points to, that object is now deleted twice, once at the point where delete is called, a second time when pt's destructor is invoked. If pt doesn't own the object, somebody else does. That somebody may be the person who deleted pt, in which case all is well. If, however, the owner of the object pointed to by pt is not the person who deleted pt, we can expect the rightful owner to delete that object again later. The first and last of these scenarios leads to an object being deleted twice, and deleting an object more than once yields undefined
This bug is especially pernicious because the whole idea behind smart pointers is to make them look and feel as much like dumb pointers as possible. The closer you get to this ideal, the more likely your clients are to forget they are using smart pointers. If they do, who can blame them if they continue to think that in order to avoid resource leaks, they must call delete if they called new?
The bottom line is simple: don't provide implicit conversion operators to dumb pointers unless there is a compelling reason to do
Smart Pointers and Inheritance-Based Type Conversions
Suppose we have a public inheritance hierarchy modeling consumer products for storing
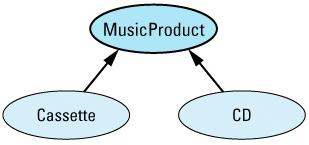
class MusicProduct {
public:
MusicProduct(const string& title);
virtual void play() const = 0;
virtual void displayTitle() const = 0;
...
};
class Cassette: public MusicProduct {
public:
Cassette(const string& title);
virtual void play() const;
virtual void displayTitle() const;
...
};
class CD: public MusicProduct {
public:
CD(const string& title);
virtual void play() const;
virtual void displayTitle() const;
...
};
Further suppose we have a function that, given a MusicProduct object, displays the title of the product and then plays
void displayAndPlay(const MusicProduct* pmp, int numTimes)
{
for (int i = 1; i <= numTimes; ++i) {
pmp->displayTitle();
pmp->play();
}
}
Such a function might be used like this:
Cassette *funMusic = new Cassette("Alapalooza");
CD *nightmareMusic = new CD("Disco Hits of the 70s");
displayAndPlay(funMusic, 10);
displayAndPlay(nightmareMusic, 0);
There are no surprises here, but look what happens if we replace the dumb pointers with their allegedly smart
void displayAndPlay(const SmartPtr<MusicProduct>& pmp,
int numTimes);
SmartPtr<Cassette> funMusic(new Cassette("Alapalooza"));
SmartPtr<CD> nightmareMusic(new CD("Disco Hits of the 70s"));
displayAndPlay(funMusic, 10); // error!
displayAndPlay(nightmareMusic, 0); // error!
If smart pointers are so brainy, why won't these
They won't compile because there is no conversion from a SmartPtr<CD> or a SmartPtr<Cassette> to a SmartPtr<MusicProduct>. As far as compilers are concerned, these are three separate classes — they have no relationship to one another. Why should compilers think otherwise? After all, it's not like SmartPtr<CD> or SmartPtr<Cassette> inherits from SmartPtr<MusicProduct>. With no inheritance relationship between these classes, we can hardly expect compilers to run around converting objects of one type to objects of other
Fortunately, there is a way to get around this limitation, and the idea (if not the practice) is simple: give each smart pointer class an implicit type conversion operator (see Item 5) for each smart pointer class to which it should be implicitly convertible. For example, in the music hierarchy, you'd add an operator SmartPtr<MusicProduct> to the smart pointer classes for Cassette and CD:
class SmartPtr<Cassette> {
public:
operator SmartPtr<MusicProduct>()
{ return SmartPtr<MusicProduct>(pointee); }
...
private:
Cassette *pointee;
};
class SmartPtr<CD> {
public:
operator SmartPtr<MusicProduct>()
{ return SmartPtr<MusicProduct>(pointee); }
...
private:
CD *pointee;
};
The drawbacks to this approach are twofold. First, you must manually specialize the SmartPtr class instantiations so you can add the necessary implicit type conversion operators, but that pretty much defeats the purpose of templates. Second, you may have to add many such conversion operators, because your pointed-to object may be deep in an inheritance hierarchy, and you must provide a conversion operator for each base class from which that object directly or indirectly inherits. (If you think you can get around this by providing only an implicit type conversion operator for each direct base class, think again. Because compilers are prohibited from employing more than one user-defined type conversion function at a time, they can't convert a smart pointer-to-T to a smart pointer-to-indirect-base-class-of-T unless they can do it in a single
It would be quite the time-saver if you could somehow get compilers to write all these implicit type conversion functions for you. Thanks to a recent language extension, you can. The extension in question is the ability to declare (nonvirtual) member function templates (usually just called member templates), and you use it to generate smart pointer conversion functions like
template<class T> // template class for smart
class SmartPtr { // pointers-to-T objects
public:
SmartPtr(T* realPtr = 0);
T* operator->() const;
T& operator*() const;
template<class newType> // template function for
operator SmartPtr<newType>() // implicit conversion ops.
{
return SmartPtr<newType>(pointee);
}
...
};
Now hold on to your headlights, this isn't magic — but it's close. It works as follows. (I'll give a specific example in a moment, so don't despair if the remainder of this paragraph reads like so much gobbledygook. After you've seen the example, it'll make more sense, I promise.) Suppose a compiler has a smart pointer-to-T object, and it's faced with the need to convert that object into a smart pointer-to-base-class-of-T. The compiler checks the class definition for SmartPtr<T> to see if the requisite conversion operator is declared, but it is not. (It can't be: no conversion operators are declared in the template above.) The compiler then checks to see if there's a member function template it can instantiate that would let it perform the conversion it's looking for. It finds such a template (the one taking the formal type parameter newType), so it instantiates the template with newType bound to the base class of T that's the target of the conversion. At that point, the only question is whether the code for the instantiated member function will compile. In order for it to compile, it must be legal to pass the (dumb) pointer pointee to the constructor for the smart pointer-to-base-of-T. pointee is of type T, so it is certainly legal to convert it into a pointer to its (public or protected) base classes. Hence, the code for the type conversion operator will compile, and the implicit conversion from smart pointer-to-T to smart pointer-to-base-of-T will
An example will help. Let us return to the music hierarchy of CDs, cassettes, and music products. We saw earlier that the following code wouldn't compile, because there was no way for compilers to convert the smart pointers to CDs or cassettes into smart pointers to music
void displayAndPlay(const SmartPtr<MusicProduct>& pmp,
int howMany);
SmartPtr<Cassette> funMusic(new Cassette("Alapalooza"));
SmartPtr<CD> nightmareMusic(new CD("Disco Hits of the 70s"));
displayAndPlay(funMusic, 10); // used to be an error
displayAndPlay(nightmareMusic, 0); // used to be an error
With the revised smart pointer class containing the member function template for implicit type conversion operators, this code will succeed. To see why, look at this
displayAndPlay(funMusic, 10);
The object funMusic is of type SmartPtr<Cassette>. The function displayAndPlay expects a SmartPtr<MusicProduct> object. Compilers detect the type mismatch and seek a way to convert funMusic into a SmartPtr<MusicProduct> object. They look for a single-argument constructor (see Item 5) in the SmartPtr<MusicProduct> class that takes a SmartPtr<Cassette>, but they find none. They look for an implicit type conversion operator in the SmartPtr<Cassette> class that yields a SmartPtr<MusicProduct> class, but that search also fails. They then look for a member function template they can instantiate to yield one of these functions. They discover that the template inside SmartPtr<Cassette>, when instantiated with newType bound to MusicProduct, generates the necessary function. They instantiate the function, yielding the following
SmartPtr<Cassette>:: operator SmartPtr<MusicProduct>()
{
return SmartPtr<MusicProduct>(pointee);
}
Will this compile? For all intents and purposes, nothing is happening here except the calling of the SmartPtr<MusicProduct> constructor with pointee as its argument, so the real question is whether one can construct a SmartPtr<MusicProduct> object with a Cassette* pointer. The SmartPtr<MusicProduct> constructor expects a MusicProduct* pointer, but now we're on the familiar ground of conversions between dumb pointer types, and it's clear that Cassette* can be passed in where a MusicProduct* is expected. The construction of the SmartPtr<MusicProduct> is therefore successful, and the conversion of the SmartPtr<Cassette> to SmartPtr<MusicProduct> is equally successful. Voilà! Implicit conversion of smart pointer types. What could be
Furthermore, what could be more powerful? Don't be misled by this example into assuming that this works only for pointer conversions up an inheritance hierarchy. The method shown succeeds for any legal implicit conversion between pointer types. If you've got a dumb pointer type T1* and another dumb pointer type T2*, you can implicitly convert a smart pointer-to-T1 to a smart pointer-to-T2 if and only if you can implicitly convert a T1* to a T2*.
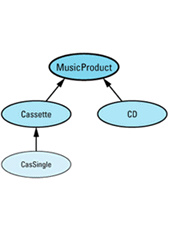
This technique gives you exactly the behavior you want — almost. Suppose we augment our MusicProduct hierarchy with a new class, CasSingle, for representing cassette singles. The revised hierarchy looks like
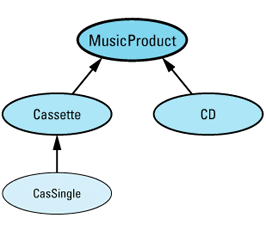
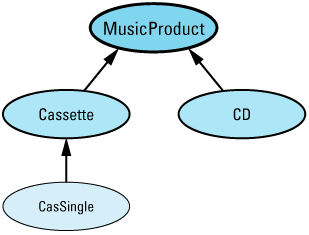
template<class T> // as above, including member tem-
class SmartPtr { ... }; // plate for conversion operators
void displayAndPlay(const SmartPtr<MusicProduct>& pmp,
int howMany);
void displayAndPlay(const SmartPtr<Cassette>& pc,
int howMany);
SmartPtr<CasSingle> dumbMusic(new CasSingle("Achy Breaky Heart"));
displayAndPlay(dumbMusic, 1); // error!
In this example, displayAndPlay is overloaded, with one function taking a SmartPtr<MusicProduct> object and the other taking a SmartPtr<Cassette> object. When we invoke displayAndPlay with a SmartPtr<CasSingle>, we expect the SmartPtr<Cassette> function to be chosen, because CasSingle inherits directly from Cassette and only indirectly from MusicProduct. Certainly that's how it would work with dumb pointers. Alas, our smart pointers aren't that smart. They employ member functions as conversion operators, and as far as C++ compilers are concerned, all calls to conversion functions are equally good. As a result, the call to displayAndPlay is ambiguous, because the conversion from SmartPtr<CasSingle> to SmartPtr<Cassette> is no better than the conversion to SmartPtr<MusicProduct>.
Implementing smart pointer conversions through member templates has two additional drawbacks. First, support for member templates is rare, so this technique is currently anything but portable. In the future, that will change, but nobody knows just how far in the future that will be. Second, the mechanics of why this works are far from transparent, relying as they do on a detailed understanding of argument-matching rules for function calls, implicit type conversion functions, implicit instantiation of template functions, and the existence of member function templates. Pity the poor programmer who has never seen this trick before and is then asked to maintain or enhance code that relies on it. The technique is clever, that's for sure, but too much cleverness can be a dangerous
Let's stop beating around the bush. What we really want to know is how we can make smart pointer classes behave just like dumb pointers for purposes of inheritance-based type conversions. The answer is simple: we can't. As Daniel Edelson has noted, smart pointers are smart, but they're not pointers. The best we can do is to use member templates to generate conversion functions, then use casts (see Item 2) in those cases where ambiguity results. This isn't a perfect state of affairs, but it's pretty good, and having to cast away ambiguity in a few cases is a small price to pay for the sophisticated functionality smart pointers can
Recall that for dumb pointers, const can refer to the thing pointed to, to the pointer itself, or both (see Item E21):
CD goodCD("Flood");
const CD *p; // p is a non-const pointer
// to a const CD object
CD * const p = &goodCD; // p is a const pointer to
// a non-const CD object;
// because p is const, it
// must be initialized
const CD * const p = &goodCD; // p is a const pointer to
// a const CD object
Naturally, we'd like to have the same flexibility with smart pointers. Unfortunately, there's only one place to put the const, and there it applies to the pointer, not to the object pointed
const SmartPtr<CD> p = // p is a const smart ptr &goodCD; // to a non-const CD object
This seems simple enough to remedy — just create a smart pointer to a const CD:
SmartPtr<const CD> p = // p is a non-const smart ptr &goodCD; // to a const CD object
Now we can create the four combinations of const and non-const objects and pointers we
SmartPtr<CD> p; // non-const object,
// non-const pointer
SmartPtr<const CD> p; // const object,
// non-const pointer
const SmartPtr<CD> p = &goodCD; // non-const object,
// const pointer
const SmartPtr<const CD> p = &goodCD; // const object,
// const pointer
Alas, this ointment has a fly in it. Using dumb pointers, we can initialize const pointers with non-const pointers and we can initialize pointers to const objects with pointers to non-consts; the rules for assignments are analogous. For
CD *pCD = new CD("Famous Movie Themes");
const CD * pConstCD = pCD; // fine
But look what happens if we try the same thing with smart
SmartPtr<CD> pCD = new CD("Famous Movie Themes");
SmartPtr<const CD> pConstCD = pCD; // fine?
SmartPtr<CD> and SmartPtr<const CD> are completely different types. As far as your compilers know, they are unrelated, so they have no reason to believe they are assignment-compatible. In what must be an old story by now, the only way these two types will be considered assignment-compatible is if you've provided a function to convert objects of type SmartPtr<CD> to objects of type SmartPtr<const CD>. If you've got a compiler that supports member templates, you can use the technique shown above for automatically generating the implicit type conversion operators you need. (I remarked earlier that the technique worked anytime the corresponding conversion for dumb pointers would work, and I wasn't kidding. Conversions involving const are no exception.) If you don't have such a compiler, you have to jump through one more
Conversions involving const are a one-way street: it's safe to go from non-const to const, but it's not safe to go from const to non-const. Furthermore, anything you can do with a const pointer you can do with a non-const pointer, but with non-const pointers you can do other things, too (for example, assignment). Similarly, anything you can do with a pointer-to-const is legal for a pointer-to-non-const, but you can do some things (such as assignment) with pointers-to-non-consts that you can't do with pointers-to-consts.
These rules sound like the rules for public inheritance (see Item E35). You can convert from a derived class object to a base class object, but not vice versa, and you can do anything to a derived class object you can do to a base class object, but you can typically do additional things to a derived class object, as well. We can take advantage of this similarity when implementing smart pointers by having each smart pointer-to-T class publicly inherit from a corresponding smart pointer-to-const-T
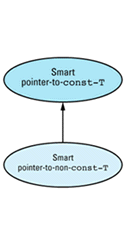
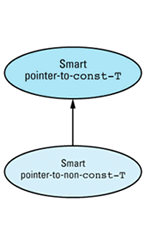
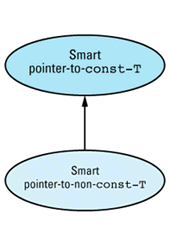
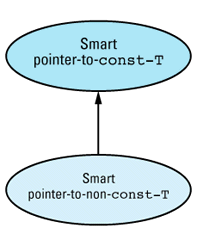
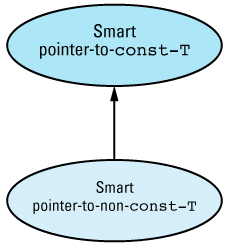
template<class T> // smart pointers to const
class SmartPtrToConst { // objects
... // the usual smart pointer
// member functions
protected:
union {
const T* constPointee; // for SmartPtrToConst access
T* pointee; // for SmartPtr access
};
};
template<class T> // smart pointers to
class SmartPtr: // non-const objects
public SmartPtrToConst<T> {
... // no data members
};
With this design, the smart pointer-to-non-const-T object needs to contain a dumb pointer-to-non-const-T, and the smart pointer-to-const-T needs to contain a dumb pointer-to-const-T. The naive way to handle this would be to put a dumb pointer-to-const-T in the base class and a dumb pointer-to-non-const-T in the derived class. That would be wasteful, however, because SmartPtr objects would contain two dumb pointers: the one they inherited from SmartPtrToConst and the one in SmartPtr
This problem is resolved by employing that old battle axe of the C world, a union, which can be as useful in C++ as it is in C. The union is protected, so both classes have access to it, and it contains both of the necessary dumb pointer types. SmartPtrToConst<T> objects use the constPointee pointer, SmartPtr<T> objects use the pointee pointer. We therefore get the advantages of two different pointers without having to allocate space for more than one. (See Item E10 for another example of this.) Such is the beauty of a union. Of course, the member functions of the two classes must constrain themselves to using only the appropriate pointer, and you'll get no help from compilers in enforcing that constraint. Such is the risk of a
With this new design, we get the behavior we
SmartPtr<CD> pCD = new CD("Famous Movie Themes");
SmartPtrToConst<CD> pConstCD = pCD; // fine
That wraps up the subject of smart pointers, but before we leave the topic, we should ask this question: are they worth the trouble, especially if your compilers lack support for member function
Often they are. The reference-counting code of Item 29, for example, is greatly simplified by using smart pointers. Furthermore, as that example demonstrates, some uses of smart pointers are sufficiently limited in scope that things like testing for nullness, conversion to dumb pointers, inheritance-based conversions, and support for pointers-to-consts are irrelevant. At the same time, smart pointers can be tricky to implement, understand, and maintain. Debugging code using smart pointers is more difficult than debugging code using dumb pointers. Try as you may, you will never succeed in designing a general-purpose smart pointer that can seamlessly replace its dumb pointer
Smart pointers nevertheless make it possible to achieve effects in your code that would otherwise be difficult to implement. Smart pointers should be used judiciously, but every C++ programmer will find them useful at one time or