Reference counting is a technique that allows multiple objects with the same value to share a single representation of that value. There are two common motivations for the technique. The first is to simplify the bookkeeping surrounding heap objects. Once an object is allocated by calling new, it's crucial to keep track of who owns that object, because the owner — and only the owner — is responsible for calling delete on it. But ownership can be transferred from object to object as a program runs (by passing pointers as parameters, for example), so keeping track of an object's ownership is hard work. Classes like auto_ptr (see Item 9) can help with this task, but experience has shown that most programs still fail to get it right. Reference counting eliminates the burden of tracking object ownership, because when an object employs reference counting, it owns itself. When nobody is using it any longer, it destroys itself automatically. Thus, reference counting constitutes a simple form of garbage
The second motivation for reference counting is simple common sense. If many objects have the same value, it's silly to store that value more than once. Instead, it's better to let all the objects with that value share its representation. Doing so not only saves memory, it also leads to faster-running programs, because there's no need to construct and destruct redundant copies of the same object
Like most simple ideas, this one hovers above a sea of interesting details. God may or may not be in the details, but successful implementations of reference counting certainly are. Before delving into details, however, let us master basics. A good way to begin is by seeing how we might come to have many objects with the same value in the first place. Here's one
class String { // the standard string type may
public: // employ the techniques in this
// Item, but that is not required
String(const char *value = "");
String& operator=(const String& rhs);
...
private:
char *data;
};
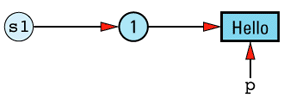
String a, b, c, d, e;
a = b = c = d = e = "Hello";
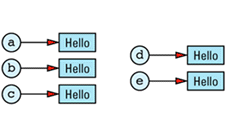
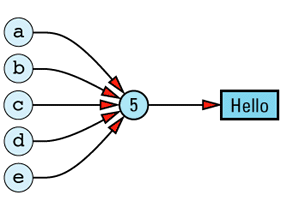
It should be apparent that objects a through e all have the same value, namely "Hello". How that value is represented depends on how the String class is implemented, but a common implementation would have each String object carry its own copy of the value. For example, String's assignment operator might be implemented like
String& String::operator=(const String& rhs)
{
if (this == &rhs) return *this; // see Item E17
delete [] data;
data = new char[strlen(rhs.data) + 1];
strcpy(data, rhs.data);
return *this; // see Item E15
}
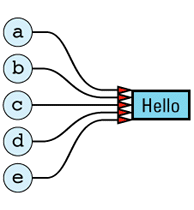
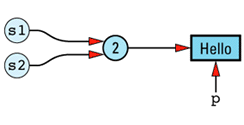
Given this implementation, we can envision the five objects and their values as
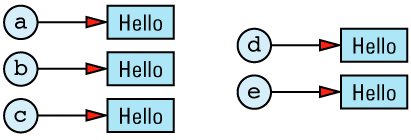
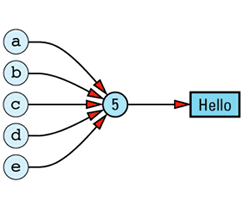
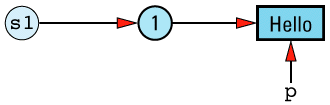
The redundancy in this approach is clear. In an ideal world, we'd like to change the picture to look like
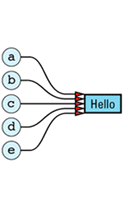
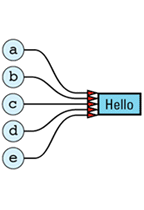
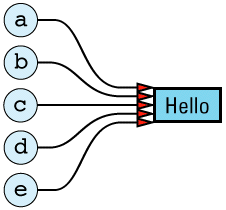
Here only one copy of the value "Hello" is stored, and all the String objects with that value share its
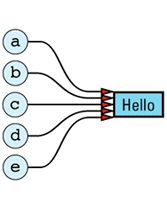
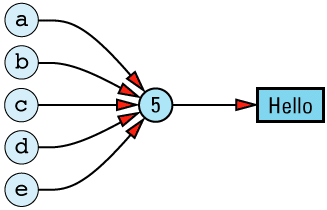
In practice, it isn't possible to achieve this ideal, because we need to keep track of how many objects are sharing a value. If object a above is assigned a different value from "Hello", we can't destroy the value "Hello", because four other objects still need it. On the other hand, if only a single object had the value "Hello" and that object went out of scope, no object would have that value and we'd have to destroy the value to avoid a resource
The need to store information on the number of objects currently sharing — referring to — a value means our ideal picture must be modified somewhat to take into account the existence of a reference count:
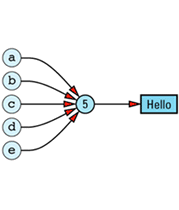
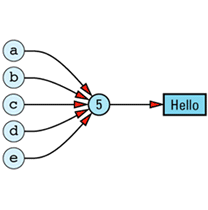
(Some people call this number a use count, but I am not one of them. C++ has enough idiosyncrasies of its own; the last thing it needs is terminological
Implementing Reference Counting
Creating a reference-counted String class isn't difficult, but it does require attention to detail, so we'll walk through the implementation of the most common member functions of such a class. Before we do that, however, it's important to recognize that we need a place to store the reference count for each String value. That place cannot be in a String object, because we need one reference count per string value, not one reference count per string object. That implies a coupling between values and reference counts, so we'll create a class to store reference counts and the values they track. We'll call this class StringValue, and because its only raison d'être is to help implement the String class, we'll nest it inside String's private section. Furthermore, it will be convenient to give all the member functions of String full access to the StringValue data structure, so we'll declare StringValue to be a struct. This is a trick worth knowing: nesting a struct in the private part of a class is a convenient way to give access to the struct to all the members of the class, but to deny access to everybody else (except, of course, friends of the
Our basic design looks like
class String {
public:
... // the usual String member
// functions go here
private:
struct StringValue { ... }; // holds a reference count
// and a string value
StringValue *value; // value of this String
};
We could give this class a different name (RCString, perhaps) to emphasize that it's implemented using reference counting, but the implementation of a class shouldn't be of concern to clients of that class. Rather, clients should interest themselves only in a class's public interface. Our reference-counting implementation of the String interface supports exactly the same operations as a non-reference-counted version, so why muddy the conceptual waters by embedding implementation decisions in the names of classes that correspond to abstract concepts? Why indeed? So we
class String {
private:
struct StringValue {
int refCount;
char *data;
StringValue(const char *initValue);
~StringValue();
};
...
};
String::StringValue::StringValue(const char *initValue)
: refCount(1)
{
data = new char[strlen(initValue) + 1];
strcpy(data, initValue);
}
String::StringValue::~StringValue()
{
delete [] data;
}
That's all there is to it, and it should be clear that's nowhere near enough to implement the full functionality of a reference-counted string. For one thing, there's neither a copy constructor nor an assignment operator (see Item E11), and for another, there's no manipulation of the refCount field. Worry not — the missing functionality will be provided by the String class. The primary purpose of StringValue is to give us a place to associate a particular value with a count of the number of String objects sharing that value. StringValue gives us that, and that's
We're now ready to walk our way through String's member functions. We'll begin with the
class String {
public:
String(const char *initValue = "");
String(const String& rhs);
...
};
The first constructor is implemented about as simply as possible. We use the passed-in char* string to create a new StringValue object, then we make the String object we're constructing point to the newly-minted StringValue:
String::String(const char *initValue)
: value(new StringValue(initValue))
{}
For client code that looks like
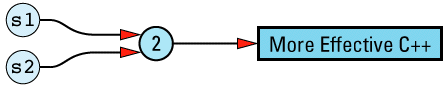
String s("More Effective C++");
we end up with a data structure that looks like





String objects constructed separately, but with the same initial value do not share a data structure, so client code of this
String s1("More Effective C++");
String s2("More Effective C++");
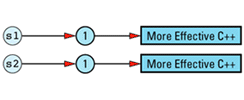
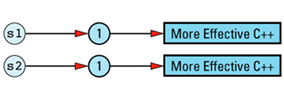
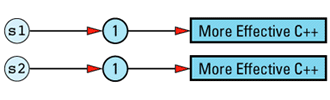
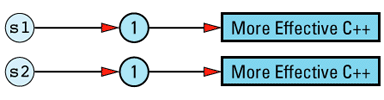
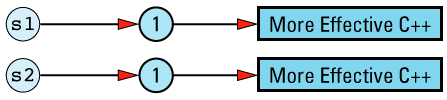
It is possible to eliminate such duplication by having String (or StringValue) keep track of existing StringValue objects and create new ones only for truly unique strings, but such refinements on reference counting are somewhat off the beaten path. As a result, I'll leave them in the form of the feared and hated exercise for the
The String copy constructor is not only unfeared and unhated, it's also efficient: the newly created String object shares the same StringValue object as the String object that's being
String::String(const String& rhs)
: value(rhs.value)
{
++value->refCount;
}
String s1("More Effective C++");
String s2 = s1;
results in this data
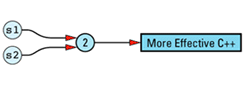
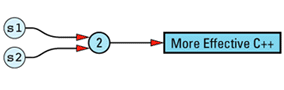
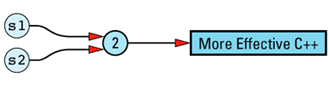
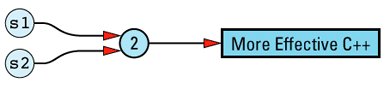
This is substantially more efficient than a conventional (non-reference-counted) String class, because there is no need to allocate memory for the second copy of the string value, no need to deallocate that memory later, and no need to copy the value that would go in that memory. Instead, we merely copy a pointer and increment a reference
The String destructor is also easy to implement, because most of the time it doesn't do anything. As long as the reference count for a StringValue is non-zero, at least one String object is using the value; it must therefore not be destroyed. Only when the String being destructed is the sole user of the value — i.e., when the value's reference count is 1 — should the String destructor destroy the StringValue
class String {
public:
~String();
...
};
String::~String()
{
if (--value->refCount == 0) delete value;
}
Compare the efficiency of this function with that of the destructor for a non-reference-counted implementation. Such a function would always call delete and would almost certainly have a nontrivial runtime cost. Provided that different String objects do in fact sometimes have the same values, the implementation above will sometimes do nothing more than decrement a counter and compare it to
If, at this point, the appeal of reference counting is not becoming apparent, you're just not paying
That's all there is to String construction and destruction, so we'll move on to consideration of the String assignment
class String {
public:
String& operator=(const String& rhs);
...
};
When a client writes code like
s1 = s2; // s1 and s2 are both String objects
the result of the assignment should be that s1 and s2 both point to the same StringValue object. That object's reference count should therefore be incremented during the assignment. Furthermore, the StringValue object that s1 pointed to prior to the assignment should have its reference count decremented, because s1 will no longer have that value. If s1 was the only String with that value, the value should be destroyed. In C++, all that looks like
String& String::operator=(const String& rhs)
{
if (value == rhs.value) { // do nothing if the values
return *this; // are already the same; this
} // subsumes the usual test of
// this against &rhs (see Item E17)
if (--value->refCount == 0) { // destroy *this's value if
delete value; // no one else is using it
}
value = rhs.value; // have *this share rhs's
++value->refCount; // value
return *this;
}
To round out our examination of reference-counted strings, consider an array-bracket operator ([]), which allows individual characters within strings to be read and
class String {
public:
const char&
operator[](int index) const; // for const Strings
char& operator[](int index); // for non-const Strings
...
};
Implementation of the const version of this function is straightforward, because it's a read-only operation; the value of the string can't be
const char& String::operator[](int index) const
{
return value->data[index];
}
(This function performs sanity checking on index in the grand C++ tradition, which is to say not at all. As usual, if you'd like a greater degree of parameter validation, it's easy to
The non-const version of operator[] is a completely different story. This function may be called to read a character, but it might be called to write one,
String s; ... cout << s[3]; // this is a read s[5] = 'x'; // this is a write
We'd like to deal with reads and writes differently. A simple read can be dealt with in the same way as the const version of operator[] above, but a write must be implemented in quite a different
When we modify a String's value, we have to be careful to avoid modifying the value of other String objects that happen to be sharing the same StringValue object. Unfortunately, there is no way for C++ compilers to tell us whether a particular use of operator[] is for a read or a write, so we must be pessimistic and assume that all calls to the non-const operator[] are for writes. (Proxy classes can help us differentiate reads from writes — see Item 30.)
To implement the non-const operator[] safely, we must ensure that no other String object shares the StringValue to be modified by the presumed write. In short, we must ensure that the reference count for a String's StringValue object is exactly one any time we return a reference to a character inside that StringValue object. Here's how we do
char& String::operator[](int index)
{
// if we're sharing a value with other String objects,
// break off a separate copy of the value for ourselves
if (value->refCount > 1) {
--value->refCount; // decrement current value's
// refCount, because we won't
// be using that value any more
value = // make a copy of the
new StringValue(value->data); // value for ourselves
}
// return a reference to a character inside our
// unshared StringValue object
return value->data[index];
}
This idea — that of sharing a value with other objects until we have to write on our own copy of the value — has a long and distinguished history in Computer Science, especially in operating systems, where processes are routinely allowed to share pages until they want to modify data on their own copy of a page. The technique is common enough to have a name: copy-on-write. It's a specific example of a more general approach to efficiency, that of lazy evaluation (see Item 17).
Pointers, References, and Copy-on-Write
This implementation of copy-on-write allows us to preserve both efficiency and correctness — almost. There is one lingering problem. Consider this
String s1 = "Hello";
char *p = &s1[1];
Our data structure at this point looks like
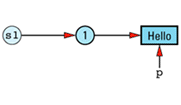
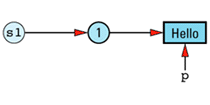
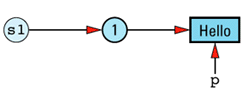
Now consider an additional
String s2 = s1;
The String copy constructor will make s2 share s1's StringValue, so the resulting data structure will be this
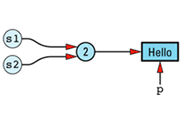
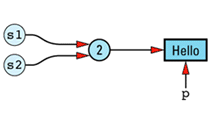
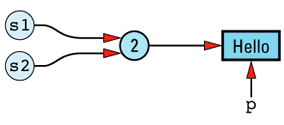
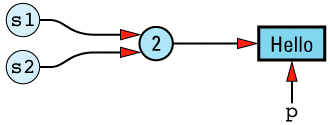
The implications of a statement such as the following, then, are not pleasant to
*p = 'x'; // modifies both s1 and s2!
There is no way the String copy constructor can detect this problem, because it has no way to know that a pointer into s1's StringValue object exists. And this problem isn't limited to pointers: it would exist if someone had saved a reference to the result of a call to String's non-const operator[].
There are at least three ways of dealing with this problem. The first is to ignore it, to pretend it doesn't exist. This approach turns out to be distressingly common in class libraries that implement reference-counted strings. If you have access to a reference-counted string, try the above example and see if you're distressed, too. If you're not sure if you have access to a reference-counted string, try the example anyway. Through the wonder of encapsulation, you may be using such a type without knowing
Not all implementations ignore such problems. A slightly more sophisticated way of dealing with such difficulties is to define them out of existence. Implementations adopting this strategy typically put something in their documentation that says, more or less, "Don't do that. If you do, results are undefined." If you then do it anyway — wittingly or no — and complain about the results, they respond, "Well, we told you not to do that." Such implementations are often efficient, but they leave much to be desired in the usability
There is a third solution, and that's to eliminate the problem. It's not difficult to implement, but it can reduce the amount of value sharing between objects. Its essence is this: add a flag to each StringValue object indicating whether that object is shareable. Turn the flag on initially (the object is shareable), but turn it off whenever the non-const operator[] is invoked on the value represented by that object. Once the flag is set to false, it stays that way forever.10
Here's a modified version of StringValue that includes a shareability
class String {
private:
struct StringValue {
int refCount;
bool shareable; // add this
char *data;
StringValue(const char *initValue);
~StringValue();
};
...
};
String::StringValue::StringValue(const char *initValue)
: refCount(1),
shareable(true) // add this
{
data = new char[strlen(initValue) + 1];
strcpy(data, initValue);
}
String::StringValue::~StringValue()
{
delete [] data;
}
As you can see, not much needs to change; the two lines that require modification are flagged with comments. Of course, String's member functions must be updated to take the shareable field into account. Here's how the copy constructor would do
String::String(const String& rhs)
{
if (rhs.value->shareable) {
value = rhs.value;
++value->refCount;
}
else {
value = new StringValue(rhs.value->data);
}
}
All the other String member functions would have to check the shareable field in an analogous fashion. The non-const version of operator[] would be the only function to set the shareable flag to false:
char& String::operator[](int index)
{
if (value->refCount > 1) {
--value->refCount;
value = new StringValue(value->data);
}
value->shareable = false; // add this
return value->data[index]; }
If you use the proxy class technique of Item 30 to distinguish read usage from write usage in operator[], you can usually reduce the number of StringValue objects that must be marked
A Reference-Counting Base Class
Reference counting is useful for more than just strings. Any class in which different objects may have values in common is a legitimate candidate for reference counting. Rewriting a class to take advantage of reference counting can be a lot of work, however, and most of us already have more than enough to do. Wouldn't it be nice if we could somehow write (and test and document) the reference counting code in a context-independent manner, then just graft it onto classes when needed? Of course it would. In a curious twist of fate, there's a way to do it (or at least to do most of
The first step is to create a base class, RCObject, for reference-counted objects. Any class wishing to take advantage of automatic reference counting must inherit from this class. RCObject encapsulates the reference count itself, as well as functions for incrementing and decrementing that count. It also contains the code for destroying a value when it is no longer in use, i.e., when its reference count becomes 0. Finally, it contains a field that keeps track of whether this value is shareable, and it provides functions to query this value and set it to false. There is no need for a function to set the shareability field to true, because all values are shareable by default. As noted above, once an object has been tagged unshareable, there is no way to make it shareable
RCObject's class definition looks like
class RCObject {
public:
RCObject();
RCObject(const RCObject& rhs);
RCObject& operator=(const RCObject& rhs);
virtual ~RCObject() = 0;
void addReference(); void removeReference();
void markUnshareable(); bool isShareable() const;
bool isShared() const;
private: int refCount; bool shareable; };
RCObjects can be created (as the base class parts of more derived objects) and destroyed; they can have new references added to them and can have current references removed; their shareability status can be queried and can be disabled; and they can report whether they are currently being shared. That's all they offer. As a class encapsulating the notion of being reference-countable, that's really all we have a right to expect them to do. Note the tell-tale virtual destructor, a sure sign this class is designed for use as a base class (see Item E14). Note also how the destructor is a pure virtual function, a sure sign this class is designed to be used only as a base
The code to implement RCObject is, if nothing else,
RCObject::RCObject()
: refCount(0), shareable(true) {}
RCObject::RCObject(const RCObject&)
: refCount(0), shareable(true) {}
RCObject& RCObject::operator=(const RCObject&)
{ return *this; }
RCObject::~RCObject() {} // virtual dtors must always
// be implemented, even if
// they are pure virtual
// and do nothing (see also
// Item 33 and Item E14)
void RCObject::addReference() { ++refCount; }
void RCObject::removeReference()
{ if (--refCount == 0) delete this; }
void RCObject::markUnshareable()
{ shareable = false; }
bool RCObject::isShareable() const
{ return shareable; }
bool RCObject::isShared() const
{ return refCount > 1; }
Curiously, we set refCount to 0 inside both constructors. This seems counterintuitive. Surely at least the creator of the new RCObject is referring to it! As it turns out, it simplifies things for the creators of RCObjects to set refCount to 1 themselves, so we oblige them here by not getting in their way. We'll get a chance to see the resulting code simplification
Another curious thing is that the copy constructor always sets refCount to 0, regardless of the value of refCount for the RCObject we're copying. That's because we're creating a new object representing a value, and new values are always unshared and referenced only by their creator. Again, the creator is responsible for setting the refCount to its proper
The RCObject assignment operator looks downright subversive: it does nothing. Frankly, it's unlikely this operator will ever be called. RCObject is a base class for a shared value object, and in a system based on reference counting, such objects are not assigned to one another, objects pointing to them are. In our case, we don't expect StringValue objects to be assigned to one another, we expect only String objects to be involved in assignments. In such assignments, no change is made to the value of a StringValue — only the StringValue reference count is
Nevertheless, it is conceivable that some as-yet-unwritten class might someday inherit from RCObject and might wish to allow assignment of reference-counted values (see Item 32 and Item E16). If so, RCObject's assignment operator should do the right thing, and the right thing is to do nothing. To see why, imagine that we wished to allow assignments between StringValue objects. Given StringValue objects sv1 and sv2, what should happen to sv1's and sv2's reference counts in an
sv1 = sv2; // how are sv1's and sv2's reference
// counts affected?
Before the assignment, some number of String objects are pointing to sv1. That number is unchanged by the assignment, because only sv1's value changes. Similarly, some number of String objects are pointing to sv2 prior to the assignment, and after the assignment, exactly the same String objects point to sv2. sv2's reference count is also unchanged. When RCObjects are involved in an assignment, then, the number of objects pointing to those objects is unaffected, hence RCObject::operator= should change no reference counts. That's exactly what the implementation above does. Counterintuitive? Perhaps, but it's still
The code for RCObject::removeReference is responsible not only for decrementing the object's refCount, but also for destroying the object if the new value of refCount is 0. It accomplishes this latter task by deleteing this, which, as Item 27 explains, is safe only if we know that *this is a heap object. For this class to be successful, we must engineer things so that RCObjects can be created only on the heap. General approaches to achieving that end are discussed in Item 27, but the specific measures we'll employ in this case are described at the conclusion of this
To take advantage of our new reference-counting base class, we modify StringValue to inherit its reference counting capabilities from RCObject:
class String {
private:
struct StringValue: public RCObject {
char *data;
StringValue(const char *initValue);
~StringValue();
};
...
};
String::StringValue::StringValue(const char *initValue)
{
data = new char[strlen(initValue) + 1];
strcpy(data, initValue);
}
String::StringValue::~StringValue()
{
delete [] data;
}
This version of StringValue is almost identical to the one we saw earlier. The only thing that's changed is that StringValue's member functions no longer manipulate the refCount field. RCObject now handles what they used to
Don't feel bad if you blanched at the sight of a nested class (StringValue) inheriting from a class (RCObject) that's unrelated to the nesting class (String). It looks weird to everybody at first, but it's perfectly kosher. A nested class is just as much a class as any other, so it has the freedom to inherit from whatever other classes it likes. In time, you won't think twice about such inheritance
Automating Reference Count Manipulations
The RCObject class gives us a place to store a reference count, and it gives us member functions through which that reference count can be manipulated, but the calls to those functions must still be manually inserted in other classes. It is still up to the String copy constructor and the String assignment operator to call addReference and removeReference on StringValue objects. This is clumsy. We'd like to move those calls out into a reusable class, too, thus freeing authors of classes like String from worrying about any of the details of reference counting. Can it be done? Isn't C++ supposed to support
It can, and it does. There's no easy way to arrange things so that all reference-counting considerations can be moved out of application classes, but there is a way to eliminate most of them for most classes. (In some application classes, you can eliminate all reference-counting code, but our String class, alas, isn't one of them. One member function spoils the party, and I suspect you won't be too surprised to hear it's our old nemesis, the non-const version of operator[]. Take heart, however; we'll tame that miscreant in the
Notice that each String object contains a pointer to the StringValue object representing that String's
class String {
private:
struct StringValue: public RCObject { ... };
StringValue *value; // value of this String
...
};
We have to manipulate the refCount field of the StringValue object anytime anything interesting happens to one of the pointers pointing to it. "Interesting happenings" include copying a pointer, reassigning one, and destroying one. If we could somehow make the pointer itself detect these happenings and automatically perform the necessary manipulations of the refCount field, we'd be home free. Unfortunately, pointers are rather dense creatures, and the chances of them detecting anything, much less automatically reacting to things they detect, are pretty slim. Fortunately, there's a way to smarten them up: replace them with objects that act like pointers, but that do
Such objects are called smart pointers, and you can read about them in more detail than you probably care to in Item 28. For our purposes here, it's enough to know that smart pointer objects support the member selection (->) and dereferencing (*) operations, just like real pointers (which, in this context, are generally referred to as dumb pointers), and, like dumb pointers, they are strongly typed: you can't make a smart pointer-to-T point to an object that isn't of type
Here's a template for objects that act as smart pointers to reference-counted
// template class for smart pointers-to-T objects. T must
// support the RCObject interface, typically by inheriting
// from RCObject
template<class T>
class RCPtr {
public:
RCPtr(T* realPtr = 0);
RCPtr(const RCPtr& rhs);
~RCPtr();
RCPtr& operator=(const RCPtr& rhs);
T* operator->() const; // see Item 28 T& operator*() const; // see Item 28
private:
T *pointee; // dumb pointer this
// object is emulating
void init(); // common initialization }; // code
This template gives smart pointer objects control over what happens during their construction, assignment, and destruction. When such events occur, these objects can automatically perform the appropriate manipulations of the refCount field in the objects to which they
For example, when an RCPtr is created, the object it points to needs to have its reference count increased. There's no need to burden application developers with the requirement to tend to this irksome detail manually, because RCPtr constructors can handle it themselves. The code in the two constructors is all but identical — only the member initialization lists differ — so rather than write it twice, we put it in a private member function called init and have both constructors call
template<class T>
RCPtr<T>::RCPtr(T* realPtr): pointee(realPtr)
{
init();
}
template<class T>
RCPtr<T>::RCPtr(const RCPtr& rhs): pointee(rhs.pointee)
{
init();
}
template<class T>
void RCPtr<T>::init()
{
if (pointee == 0) { // if the dumb pointer is
return; // null, so is the smart one
}
if (pointee->isShareable() == false) { // if the value
pointee = new T(*pointee); // isn't shareable,
} // copy it
pointee->addReference(); // note that there is now a } // new reference to the value
Moving common code into a separate function like init is exemplary software engineering, but its luster dims when, as in this case, the function doesn't behave
The problem is this. When init needs to create a new copy of a value (because the existing copy isn't shareable), it executes the following
pointee = new T(*pointee);
The type of pointee is pointer-to-T, so this statement creates a new T object and initializes it by calling T's copy constructor. In the case of an RCPtr in the String class, T will be String::StringValue, so the statement above will call String::StringValue's copy constructor. We haven't declared a copy constructor for that class, however, so our compilers will generate one for us. The copy constructor so generated will, in accordance with the rules for automatically generated copy constructors in C++, copy only StringValue's data pointer; it will not copy the char* string data points to. Such behavior is disastrous in nearly any class (not just reference-counted classes), and that's why you should get into the habit of writing a copy constructor (and an assignment operator) for all your classes that contain pointers (see Item E11).
The correct behavior of the RCPtr<T> template depends on T containing a copy constructor that makes a truly independent copy (i.e., a deep copy) of the value represented by T. We must augment StringValue with such a constructor before we can use it with the RCPtr
class String {
private:
struct StringValue: public RCObject {
StringValue(const StringValue& rhs);
...
};
...
};
String::StringValue::StringValue(const StringValue& rhs)
{
data = new char[strlen(rhs.data) + 1];
strcpy(data, rhs.data);
}
The existence of a deep-copying copy constructor is not the only assumption RCPtr<T> makes about T. It also requires that T inherit from RCObject, or at least that T provide all the functionality that RCObject does. In view of the fact that RCPtr objects are designed to point only to reference-counted objects, this is hardly an unreasonable assumption. Nevertheless, the assumption must be
A final assumption in RCPtr<T> is that the type of the object pointed to is T. This seems obvious enough. After all, pointee is declared to be of type T*. But pointee might really point to a class derived from T. For example, if we had a class SpecialStringValue that inherited from String::StringValue,
class String {
private:
struct StringValue: public RCObject { ... };
struct SpecialStringValue: public StringValue { ... };
...
};
we could end up with a String containing a RCPtr<StringValue> pointing to a SpecialStringValue object. In that case, we'd want this part of init,
pointee = new T(*pointee); // T is StringValue, but
// pointee really points to
// a SpecialStringValue
to call SpecialStringValue's copy constructor, not StringValue's. We can arrange for this to happen by using a virtual copy constructor (see Item 25). In the case of our String class, we don't expect classes to derive from StringValue, so we'll disregard this
With RCPtr's constructors out of the way, the rest of the class's functions can be dispatched with considerably greater alacrity. Assignment of an RCPtr is straightforward, though the need to test whether the newly assigned value is shareable complicates matters slightly. Fortunately, such complications have already been handled by the init function that was created for RCPtr's constructors. We take advantage of that fact by using it again
template<class T>
RCPtr<T>& RCPtr<T>::operator=(const RCPtr& rhs)
{
if (pointee != rhs.pointee) { // skip assignments
// where the value
// doesn't change
if (pointee) {
pointee->removeReference(); // remove reference to
} // current value
pointee = rhs.pointee; // point to new value
init(); // if possible, share it
} // else make own copy
return *this; }
The destructor is easier. When an RCPtr is destroyed, it simply removes its reference to the reference-counted
template<class T>
RCPtr<T>::~RCPtr()
{
if (pointee)pointee->removeReference();
}
If the RCPtr that just expired was the last reference to the object, that object will be destroyed inside RCObject's removeReference member function. Hence RCPtr objects never need to worry about destroying the values they point
Finally, RCPtr's pointer-emulating operators are part of the smart pointer boilerplate you can read about in Item 28:
template<class T>
T* RCPtr<T>::operator->() const { return pointee; }
template<class T>
T& RCPtr<T>::operator*() const { return *pointee; }
Enough! Finis! At long last we are in a position to put all the pieces together and build a reference-counted String class based on the reusable RCObject and RCPtr classes. With luck, you haven't forgotten that that was our original
Each reference-counted string is implemented via this data
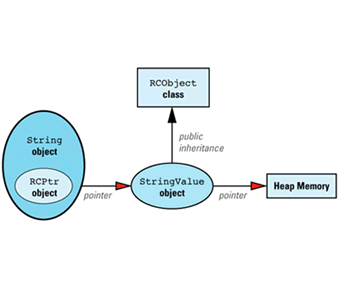
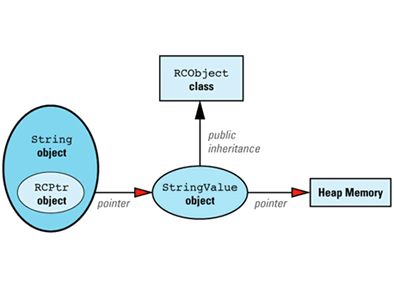
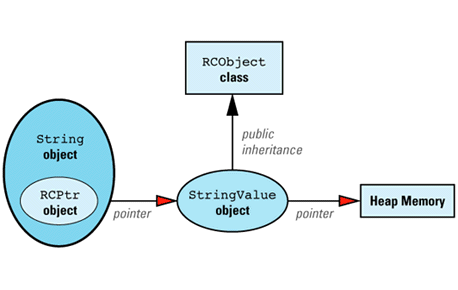
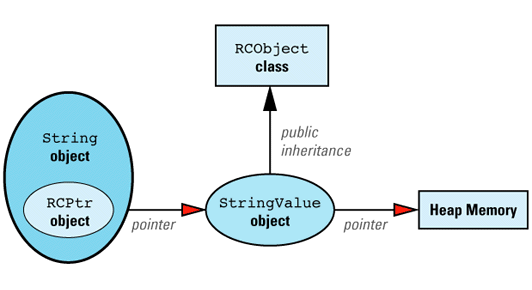
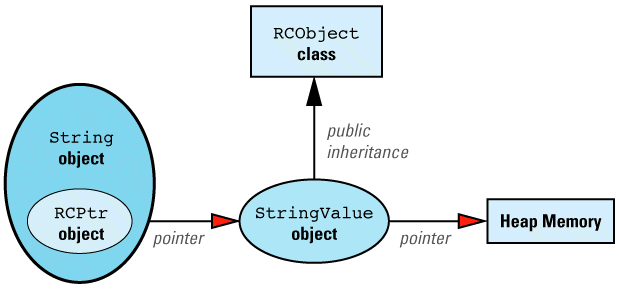
The classes making up this data structure are defined like
template<class T> // template class for smart
class RCPtr { // pointers-to-T objects; T
public: // must inherit from RCObject
RCPtr(T* realPtr = 0);
RCPtr(const RCPtr& rhs);
~RCPtr();
RCPtr& operator=(const RCPtr& rhs);
T* operator->() const;
T& operator*() const;
private:
T *pointee;
void init();
};
class RCObject { // base class for reference-
public: // counted objects
void addReference();
void removeReference();
void markUnshareable();
bool isShareable() const;
bool isShared() const;
protected:
RCObject();
RCObject(const RCObject& rhs);
RCObject& operator=(const RCObject& rhs);
virtual ~RCObject() = 0;
private:
int refCount;
bool shareable;
};
class String { // class to be used by
public: // application developers
String(const char *value = "");
const char& operator[](int index) const;
char& operator[](int index);
private:
// class representing string values
struct StringValue: public RCObject {
char *data;
StringValue(const char *initValue);
StringValue(const StringValue& rhs);
void init(const char *initValue);
~StringValue();
};
RCPtr<StringValue> value;
};
For the most part, this is just a recap of what we've already developed, so nothing should be much of a surprise. Close examination reveals we've added an init function to String::StringValue, but, as we'll see below, that serves the same purpose as the corresponding function in RCPtr: it prevents code duplication in the
There is a significant difference between the public interface of this String class and the one we used at the beginning of this Item. Where is the copy constructor? Where is the assignment operator? Where is the destructor? Something is definitely amiss
Actually, no. Nothing is amiss. In fact, some things are working perfectly. If you don't see what they are, prepare yourself for a C++
We don't need those functions anymore. Sure, copying of String objects is still supported, and yes, the copying will correctly handle the underlying reference-counted StringValue objects, but the String class doesn't have to provide a single line of code to make this happen. That's because the compiler-generated copy constructor for String will automatically call the copy constructor for String's RCPtr member, and the copy constructor for that class will perform all the necessary manipulations of the StringValue object, including its reference count. An RCPtr is a smart pointer, remember? We designed it to take care of the details of reference counting, so that's what it does. It also handles assignment and destruction, and that's why String doesn't need to write those functions, either. Our original goal was to move the unreusable reference-counting code out of our hand-written String class and into context-independent classes where it would be available for use with any class. Now we've done it (in the form of the RCObject and RCPtr classes), so don't be so surprised when it suddenly starts working. It's supposed to
Just so you have everything in one place, here's the implementation of RCObject:
RCObject::RCObject()
: refCount(0), shareable(true) {}
RCObject::RCObject(const RCObject&)
: refCount(0), shareable(true) {}
RCObject& RCObject::operator=(const RCObject&)
{ return *this; }
RCObject::~RCObject() {}
void RCObject::addReference() { ++refCount; }
void RCObject::removeReference()
{ if (--refCount == 0) delete this; }
void RCObject::markUnshareable()
{ shareable = false; }
bool RCObject::isShareable() const
{ return shareable; }
bool RCObject::isShared() const
{ return refCount > 1; }
And here's the implementation of RCPtr:
template<class T>
void RCPtr<T>::init()
{
if (pointee == 0) return;
if (pointee->isShareable() == false) {
pointee = new T(*pointee);
}
pointee->addReference(); }
template<class T>
RCPtr<T>::RCPtr(T* realPtr)
: pointee(realPtr)
{ init(); }
template<class T>
RCPtr<T>::RCPtr(const RCPtr& rhs)
: pointee(rhs.pointee)
{ init(); }
template<class T>
RCPtr<T>::~RCPtr()
{ if (pointee)pointee->removeReference(); }
template<class T>
RCPtr<T>& RCPtr<T>::operator=(const RCPtr& rhs)
{
if (pointee != rhs.pointee) {
if (pointee) pointee->removeReference();
pointee = rhs.pointee;
init();
}
return *this; }
template<class T>
T* RCPtr<T>::operator->() const { return pointee; }
template<class T>
T& RCPtr<T>::operator*() const { return *pointee; }
The implementation of String::StringValue looks like
void String::StringValue::init(const char *initValue)
{
data = new char[strlen(initValue) + 1];
strcpy(data, initValue);
}
String::StringValue::StringValue(const char *initValue)
{ init(initValue); }
String::StringValue::StringValue(const StringValue& rhs)
{ init(rhs.data); }
String::StringValue::~StringValue()
{ delete [] data; }
Ultimately, all roads lead to String, and that class is implemented this
String::String(const char *initValue)
: value(new StringValue(initValue)) {}
const char& String::operator[](int index) const
{ return value->data[index]; }
char& String::operator[](int index)
{
if (value->isShared()) {
value = new StringValue(value->data);
}
value->markUnshareable();
return value->data[index]; }
If you compare the code for this String class with that we developed for the String class using dumb pointers, you'll be struck by two things. First, there's a lot less of it here than there. That's because RCPtr has assumed much of the reference-counting burden that used to fall on String. Second, the code that remains in String is nearly unchanged: the smart pointer replaced the dumb pointer essentially seamlessly. In fact, the only changes are in operator[], where we call isShared instead of checking the value of refCount directly and where our use of the smart RCPtr object eliminates the need to manually manipulate the reference count during a
This is all very nice, of course. Who can object to less code? Who can oppose encapsulation success stories? The bottom line, however, is determined more by the impact of this newfangled String class on its clients than by any of its implementation details, and it is here that things really shine. If no news is good news, the news here is very good indeed. The String interface has not changed. We added reference counting, we added the ability to mark individual string values as unshareable, we moved the notion of reference countability into a new base class, we added smart pointers to automate the manipulation of reference counts, yet not one line of client code needs to be changed. Sure, we changed the String class definition, so clients who want to take advantage of reference-counted strings must recompile and relink, but their investment in code is completely and utterly preserved. You see? Encapsulation really is a wonderful
Adding Reference Counting to Existing Classes
Everything we've discussed so far assumes we have access to the source code of the classes we're interested in. But what if we'd like to apply the benefits of reference counting to some class Widget that's in a library we can't modify? There's no way to make Widget inherit from RCObject, so we can't use smart RCPtrs with it. Are we out of
We're not. With some minor modifications to our design, we can add reference counting to any
First, let's consider what our design would look like if we could have Widget inherit from RCObject. In that case, we'd have to add a class, RCWidget, for clients to use, but everything would then be analogous to our String/StringValue example, with RCWidget playing the role of String and Widget playing the role of StringValue. The design would look like
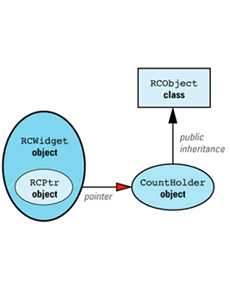
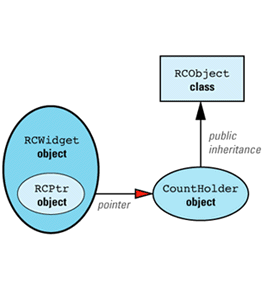
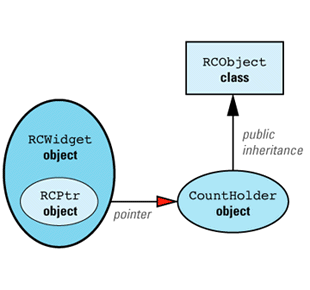
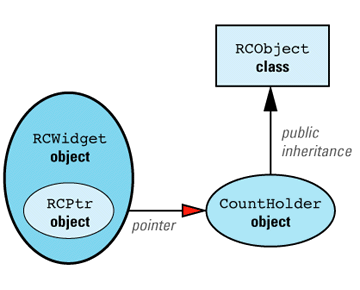
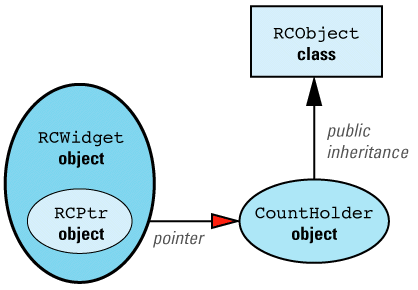
We can now apply the maxim that most problems in Computer Science can be solved with an additional level of indirection. We add a new class, CountHolder, to hold the reference count, and we have CountHolder inherit from RCObject. We also have CountHolder contain a pointer to a Widget. We then replace the smart RCPtr template with an equally smart RCIPtr template that knows about the existence of the CountHolder class. (The "I" in RCIPtr stands for "indirect.") The modified design looks like
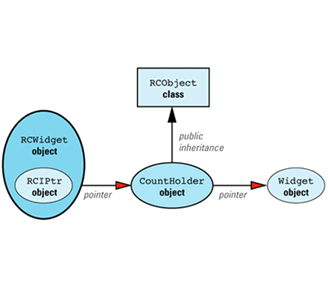
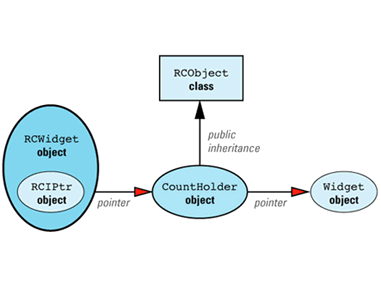
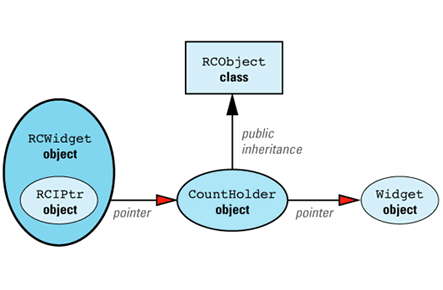
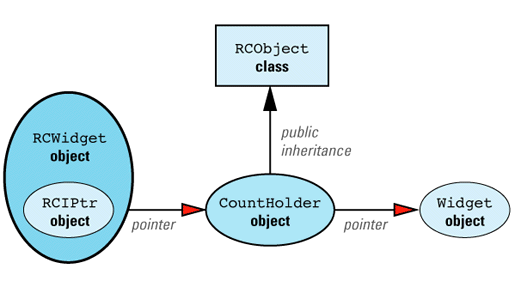
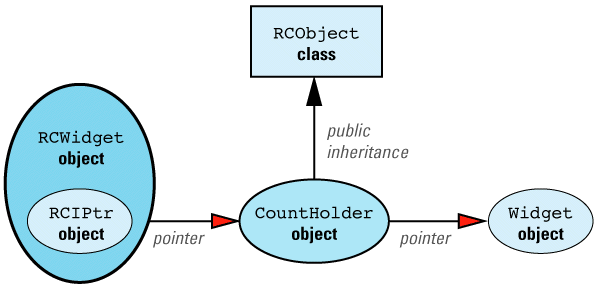
Just as StringValue was an implementation detail hidden from clients of String, CountHolder is an implementation detail hidden from clients of RCWidget. In fact, it's an implementation detail of RCIPtr, so it's nested inside that class. RCIPtr is implemented this
template<class T>
class RCIPtr {
public:
RCIPtr(T* realPtr = 0);
RCIPtr(const RCIPtr& rhs);
~RCIPtr();
RCIPtr& operator=(const RCIPtr& rhs);
const T* operator->() const; // see below for an
T* operator->(); // explanation of why
const T& operator*() const; // these functions are
T& operator*(); // declared this way
private:
struct CountHolder: public RCObject {
~CountHolder() { delete pointee; }
T *pointee;
};
CountHolder *counter;
void init();
void makeCopy(); // see below
};
template<class T>
void RCIPtr<T>::init()
{
if (counter->isShareable() == false) {
T *oldValue = counter->pointee;
counter = new CountHolder;
counter->pointee = new T(*oldValue);
}
counter->addReference();
}
template<class T>
RCIPtr<T>::RCIPtr(T* realPtr)
: counter(new CountHolder)
{
counter->pointee = realPtr;
init();
}
template<class T>
RCIPtr<T>::RCIPtr(const RCIPtr& rhs)
: counter(rhs.counter)
{ init(); }
template<class T>
RCIPtr<T>::~RCIPtr()
{ counter->removeReference(); }
template<class T>
RCIPtr<T>& RCIPtr<T>::operator=(const RCIPtr& rhs)
{
if (counter != rhs.counter) {
counter->removeReference();
counter = rhs.counter;
init();
}
return *this;
}
template<class T> // implement the copy
void RCIPtr<T>::makeCopy() // part of copy-on-
{ // write (COW)
if (counter->isShared()) {
T *oldValue = counter->pointee;
counter->removeReference();
counter = new CountHolder;
counter->pointee = new T(*oldValue);
counter->addReference();
}
}
template<class T> // const access;
const T* RCIPtr<T>::operator->() const // no COW needed
{ return counter->pointee; }
template<class T> // non-const
T* RCIPtr<T>::operator->() // access; COW
{ makeCopy(); return counter->pointee; } // needed
template<class T> // const access;
const T& RCIPtr<T>::operator*() const // no COW needed
{ return *(counter->pointee); }
template<class T> // non-const
T& RCIPtr<T>::operator*() // access; do the
{ makeCopy(); return *(counter->pointee); } // COW thing
RCIPtr differs from RCPtr in only two ways. First, RCPtr objects point to values directly, while RCIPtr objects point to values through intervening CountHolder objects. Second, RCIPtr overloads operator-> and operator* so that a copy-on-write is automatically performed whenever a non-const access is made to a pointed-to
Given RCIPtr, it's easy to implement RCWidget, because each function in RCWidget is implemented by forwarding the call through the underlying RCIPtr to a Widget object. For example, if Widget looks like
class Widget {
public:
Widget(int size);
Widget(const Widget& rhs);
~Widget();
Widget& operator=(const Widget& rhs);
void doThis(); int showThat() const; };
RCWidget will be defined this
class RCWidget {
public:
RCWidget(int size): value(new Widget(size)) {}
void doThis() { value->doThis(); }
int showThat() const { return value->showThat(); }
private: RCIPtr<Widget> value; };
Note how the RCWidget constructor calls the Widget constructor (via the new operator — see Item 8) with the argument it was passed; how RCWidget's doThis calls doThis in the Widget class; and how RCWidget::showThat returns whatever its Widget counterpart returns. Notice also how RCWidget declares no copy constructor, no assignment operator, and no destructor. As with the String class, there is no need to write these functions. Thanks to the behavior of the RCIPtr class, the default versions do the right
If the thought occurs to you that creation of RCWidget is so mechanical, it could be automated, you're right. It would not be difficult to write a program that takes a class like Widget as input and produces a class like RCWidget as output. If you write such a program, please let me
Let us disentangle ourselves from the details of widgets, strings, values, smart pointers, and reference-counting base classes. That gives us an opportunity to step back and view reference counting in a broader context. In that more general context, we must address a higher-level question, namely, when is reference counting an appropriate
Reference-counting implementations are not without cost. Each reference-counted value carries a reference count with it, and most operations require that this reference count be examined or manipulated in some way. Object values therefore require more memory, and we sometimes execute more code when we work with them. Furthermore, the underlying source code is considerably more complex for a reference-counted class than for a less elaborate implementation. An un-reference-counted string class typically stands on its own, while our final String class is useless unless it's augmented with three auxiliary classes (StringValue, RCObject, and RCPtr). True, our more complicated design holds out the promise of greater efficiency when values can be shared, it eliminates the need to track object ownership, and it promotes reusability of the reference counting idea and implementation. Nevertheless, that quartet of classes has to be written, tested, documented, and maintained, and that's going to be more work than writing, testing, documenting, and maintaining a single class. Even a manager can see
Reference counting is an optimization technique predicated on the assumption that objects will commonly share values (see also Item 18). If this assumption fails to hold, reference counting will use more memory than a more conventional implementation and it will execute more code. On the other hand, if your objects do tend to have common values, reference counting should save you both time and space. The bigger your object values and the more objects that can simultaneously share values, the more memory you'll save. The more you copy and assign values between objects, the more time you'll save. The more expensive it is to create and destroy a value, the more time you'll save there, too. In short, reference counting is most useful for improving efficiency under the following
There is only one sure way to tell whether these conditions are satisfied, and that way is not to guess or rely on your programmer's intuition (see Item 16). The reliable way to find out whether your program can benefit from reference counting is to profile or instrument it. That way you can find out if creating and destroying values is a performance bottleneck, and you can measure the objects/values ratio. Only when you have such data in hand are you in a position to determine whether the benefits of reference counting (of which there are many) outweigh the disadvantages (of which there are also
Even when the conditions above are satisfied, a design employing reference counting may still be inappropriate. Some data structures (e.g., directed graphs) lead to self-referential or circular dependency structures. Such data structures have a tendency to spawn isolated collections of objects, used by no one, whose reference counts never drop to zero. That's because each object in the unused structure is pointed to by at least one other object in the same structure. Industrial-strength garbage collectors use special techniques to find such structures and eliminate them, but the simple reference-counting approach we've examined here is not easily extended to include such
Reference counting can be attractive even if efficiency is not your primary concern. If you find yourself weighed down with uncertainty over who's allowed to delete what, reference counting could be just the technique you need to ease your burden. Many programmers are devoted to reference counting for this reason
Let us close this discussion on a technical note by tying up one remaining loose end. When RCObject::removeReference decrements an object's reference count, it checks to see if the new count is 0. If it is, removeReference destroys the object by deleteing this. This is a safe operation only if the object was allocated by calling new, so we need some way of ensuring that RCObjects are created only in that
In this case we do it by convention. RCObject is designed for use as a base class of reference-counted value objects, and those value objects should be referred to only by smart RCPtr pointers. Furthermore, the value objects should be instantiated only by application objects that realize values are being shared; the classes describing the value objects should never be available for general use. In our example, the class for value objects is StringValue, and we limit its use by making it private in String. Only String can create StringValue objects, so it is up to the author of the String class to ensure that all such objects are allocated via new.
Our approach to the constraint that RCObjects be created only on the heap, then, is to assign responsibility for conformance to this constraint to a well-defined set of classes and to ensure that only that set of classes can create RCObjects. There is no possibility that random clients can accidently (or maliciously) create RCObjects in an inappropriate manner. We limit the right to create reference-counted objects, and when we do hand out the right, we make it clear that it's accompanied by the concomitant responsibility to follow the rules governing object
string type in the standard C++ library (see Item E49 and Item 35) uses a combination of solutions two and three. The reference returned from the non-const operator[] is guaranteed to be valid until the next function call that might modify the string. After that, use of the reference (or the character to which it refers) yields undefined results. This allows the string's shareability flag to be reset to true whenever a function is called that might modify the string.