These are heady days for C++ programmers. Commercially available less than a decade, C++ has nevertheless emerged as the language of choice for systems programming on nearly all major computing platforms. Companies and individuals with challenging programming problems increasingly embrace the language, and the question faced by those who do not use C++ is often when they will start, not if. Standardization of C++ is complete, and the breadth and scope of the accompanying library — which both dwarfs and subsumes that of C — makes it possible to write rich, complex programs without sacrificing portability or implementing common algorithms and data structures from scratch. C++ compilers continue to proliferate, the features they offer continue to expand, and the quality of the code they generate continues to improve. Tools and environments for C++ development grow ever more abundant, powerful, and robust. Commercial libraries all but obviate the need to write code in many application
As the language has matured and our experience with it has increased, our needs for information about it have changed. In 1990, people wanted to know what C++ was. By 1992, they wanted to know how to make it work. Now C++ programmers ask higher-level questions: How can I design my software so it will adapt to future demands? How can I improve the efficiency of my code without compromising its correctness or making it harder to use? How can I implement sophisticated functionality not directly supported by the
In this book, I answer these questions and many others like
This book shows how to design and implement C++ software that is more effective: more likely to behave correctly; more robust in the face of exceptions; more efficient; more portable; makes better use of language features; adapts to change more gracefully; works better in a mixed-language environment; is easier to use correctly; is harder to use incorrectly. In short, software that's just better.
The material in this book is divided into 35 Items. Each Item summarizes accumulated wisdom of the C++ programming community on a particular topic. Most Items take the form of guidelines, and the explanation accompanying each guideline describes why the guideline exists, what happens if you fail to follow it, and under what conditions it may make sense to violate the guideline
Items fall into several categories. Some concern particular language features, especially newer features with which you may have little experience. For example, Items 9 through 15 are devoted to exceptions (as are the magazine articles by Tom Cargill, Jack Reeves, and Herb Sutter). Other Items explain how to combine the features of the language to achieve higher-level goals. Items 25 through 31, for instance, describe how to constrain the number or placement of objects, how to create functions that act "virtual" on the type of more than one object, how to create "smart pointers," and more. Still other Items address broader topics; Items 16 through 24 focus on efficiency. No matter what the topic of a particular Item, each takes a no-nonsense approach to the subject. In More Effective C++, you learn how to use C++ more effectively. The descriptions of language features that make up the bulk of most C++ texts are in this book mere background
An implication of this approach is that you should be familiar with C++ before reading this book. I take for granted that you understand classes, protection levels, virtual and nonvirtual functions, etc., and I assume you are acquainted with the concepts behind templates and exceptions. At the same time, I don't expect you to be a language expert, so when poking into lesser-known corners of C++, I always explain what's going
The C++ I describe in this book is the language specified by the
I recognize that just because the standardization committee blesses a feature or endorses a practice, there's no guarantee that the feature is present in current compilers or the practice is applicable to existing environments. When faced with a discrepancy between theory (what the committee says) and practice (what actually works), I discuss both, though my bias is toward things that work. Because I discuss both, this book will aid you as your compilers approach conformance with the standard. It will show you how to use existing constructs to approximate language features your compilers don't yet support, and it will guide you when you decide to transform workarounds into newly- supported
Notice that I refer to your compilers — plural. Different compilers implement varying approximations to the standard, so I encourage you to develop your code under at least two compilers. Doing so will help you avoid inadvertent dependence on one vendor's proprietary language extension or its misinterpretation of the standard. It will also help keep you away from the bleeding edge of compiler technology, e.g., from new features supported by only one vendor. Such features are often poorly implemented (buggy or slow — frequently both), and upon their introduction, the C++ community lacks experience to advise you in their proper use. Blazing trails can be exciting, but when your goal is producing reliable code, it's often best to let others test the waters before jumping
There are two constructs you'll see in this book that may not be familiar to you. Both are relatively recent language extensions. Some compilers support them, but if your compilers don't, you can easily approximate them with features you do
The first construct is the bool type, which has as its values the keywords true and false. If your compilers haven't implemented bool, there are two ways to approximate it. One is to use a global
enum bool { false, true };
This allows you to overload functions on the basis of whether they take a bool or an int, but it has the disadvantage that the built-in comparison operators (i.e., ==, <, >=, etc.) still return ints. As a result, code like the following will not behave the way it's supposed
void f(int); void f(bool);
int x, y;
...
f( x < y ); // calls f(int), but it
// should call f(bool)
The enum approximation may thus lead to code whose behavior changes when you submit it to a compiler that truly supports bool.
An alternative is to use a typedef for bool and constant objects for true and false:
typedef int bool;
const bool false = 0; const bool true = 1;
This is compatible with the traditional semantics of C and C++, and the behavior of programs using this approximation won't change when they're ported to bool-supporting compilers. The drawback is that you can't differentiate between bool and int when overloading functions. Both approximations are reasonable. Choose the one that best fits your
The second new construct is really four constructs, the casting forms static_cast, const_cast, dynamic_cast, and reinterpret_cast. If you're not familiar with these casts, you'll want to turn to Item 2 and read all about them. Not only do they do more than the C-style casts they replace, they do it better. I use these new casting forms whenever I need to perform a cast in this
There is more to C++ than the language itself. There is also the standard library (see Item E49). Where possible, I employ the standard string type instead of using raw char* pointers, and I encourage you to do the same. string objects are no more difficult to manipulate than char*-based strings, and they relieve you of most memory-management concerns. Furthermore, string objects are less susceptible to memory leaks if an exception is thrown (see Items 9 and 10). A well-implemented string type can hold its own in an efficiency contest with its char* equivalent, and it may even do better. (For insight into how this could be, see Item 29.) If you don't have access to an implementation of the standard string type, you almost certainly have access to some string-like class. Use it. Just about anything is preferable to raw char*s.
I use data structures from the standard library whenever I can. Such data structures are drawn from the Standard Template Library (the "STL" — see Item 35). The STL includes bitsets, vectors, lists, queues, stacks, maps, sets, and more, and you should prefer these standardized data structures to the ad hoc equivalents you might otherwise be tempted to write. Your compilers may not have the STL bundled in, but don't let that keep you from using it. Thanks to Silicon Graphics, you can download a free copy that works with many compilers from the
If you currently use a library of algorithms and data structures and are happy with it, there's no need to switch to the STL just because it's "standard." However, if you have a choice between using an STL component or writing your own code from scratch, you should lean toward using the STL. Remember code reuse? STL (and the rest of the standard library) has lots of code that is very much worth
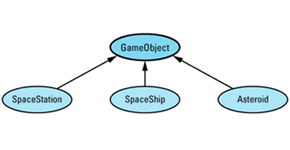
Any time I mention inheritance in this book, I mean public inheritance (see Item E35). If I don't mean public inheritance, I'll say so explicitly. When drawing inheritance hierarchies, I depict base-derived relationships by drawing arrows from derived classes to base classes. For example, here is a hierarchy from Item 31:
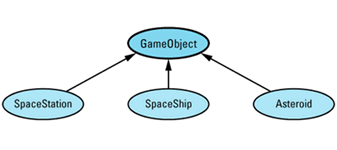
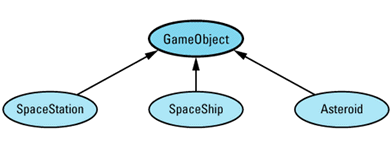
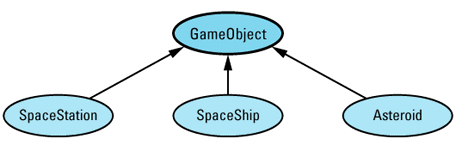
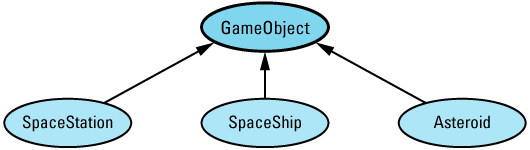
This notation is the reverse of the convention I employed in the first (but not the second) edition of Effective C++. I'm now convinced that most C++ practitioners draw inheritance arrows from derived to base classes, and I am happy to follow suit. Within such diagrams, abstract classes (e.g., GameObject) are shaded and concrete classes (e.g., SpaceShip) are
Inheritance gives rise to pointers and references with two different types, a static type and a dynamic type. The static type of a pointer or reference is its declared type. The dynamic type is determined by the type of object it actually refers to. Here are some examples based on the classes
GameObject *pgo = // static type of pgo is
new SpaceShip; // GameObject*, dynamic
// type is SpaceShip*
Asteroid *pa = new Asteroid; // static type of pa is
// Asteroid*. So is its
// dynamic type
pgo = pa; // static type of pgo is
// still (and always)
// GameObject*. Its
// dynamic type is now
// Asteroid*
GameObject& rgo = *pa; // static type of rgo is
// GameObject, dynamic
// type is Asteroid
These examples also demonstrate a naming convention I like. pgo is a pointer-to-GameObject; pa is a pointer-to-Asteroid; rgo is a reference-to-GameObject. I often concoct pointer and reference names in this
Two of my favorite parameter names are lhs and rhs, abbreviations for "left-hand side" and "right-hand side," respectively. To understand the rationale behind these names, consider a class for representing rational
class Rational { ... };
If I wanted a function to compare pairs of Rational objects, I'd declare it like
bool operator==(const Rational& lhs, const Rational& rhs);
That would let me write this kind of
Rational r1, r2;
...
if (r1 == r2) ...
Within the call to operator==, r1 appears on the left-hand side of the "==" and is bound to lhs, while r2 appears on the right-hand side of the "==" and is bound to rhs.
Other abbreviations I employ include ctor for "constructor," dtor for "destructor," and RTTI for C++'s support for runtime type identification (of which dynamic_cast is the most commonly used
When you allocate memory and fail to free it, you have a memory leak. Memory leaks arise in both C and C++, but in C++, memory leaks leak more than just memory. That's because C++ automatically calls constructors when objects are created, and constructors may themselves allocate resources. For example, consider this
class Widget { ... }; // some class — it doesn't
// matter what it is
Widget *pw = new Widget; // dynamically allocate a
// Widget object
... // assume pw is never
// deleted
This code leaks memory, because the Widget pointed to by pw is never deleted. However, if the Widget constructor allocates additional resources that are to be released when the Widget is destroyed (such as file descriptors, semaphores, window handles, database locks, etc.), those resources are lost just as surely as the memory is. To emphasize that memory leaks in C++ often leak other resources, too, I usually speak of resource leaks in this book rather than memory
You won't see many inline functions in this book. That's not because I dislike inlining. Far from it, I believe that inline functions are an important feature of C++. However, the criteria for determining whether a function should be inlined can be complex, subtle, and platform-dependent (see Item E33). As a result, I avoid inlining unless there is a point about inlining I wish to make. When you see a non-inline function in More Effective C++, that doesn't mean I think it would be a bad idea to declare the function inline, it just means the decision to inline that function is independent of the material I'm examining at that point in the
A few C++ features have been deprecated by the
A client is somebody (a programmer) or something (a class or function, typically) that uses the code you write. For example, if you write a Date class (for representing birthdays, deadlines, when the Second Coming occurs, etc.), anybody using that class is your client. Furthermore, any sections of code that use the Date class are your clients as well. Clients are important. In fact, clients are the name of the game! If nobody uses the software you write, why write it? You will find I worry a lot about making things easier for clients, often at the expense of making things more difficult for you, because good software is "clientcentric" — it revolves around clients. If this strikes you as unreasonably philanthropic, view it instead through a lens of self-interest. Do you ever use the classes or functions you write? If so, you're your own client, so making things easier for clients in general also makes them easier for
When discussing class or function templates and the classes or functions generated from them, I reserve the right to be sloppy about the difference between the templates and their instantiations. For example, if Array is a class template taking a type parameter T, I may refer to a particular instantiation of the template as an Array, even though Array<T> is really the name of the class. Similarly, if swap is a function template taking a type parameter T, I may refer to an instantiation as swap instead of swap<T>. In cases where this kind of shorthand might be unclear, I include template parameters when referring to template
Reporting Bugs, Making Suggestions, Getting Book Updates
I have tried to make this book as accurate, readable, and useful as possible, but I know there is room for improvement. If you find an error of any kind — technical, grammatical, typographical, whatever — please tell me about it. I will try to correct the mistake in future printings of the book, and if you are the first person to report it, I will gladly add your name to the book's acknowledgments. If you have other suggestions for improvement, I welcome those,
I continue to collect guidelines for effective programming in C++. If you have ideas for new guidelines, I'd be delighted if you'd share them with me. Send your guidelines, your comments, your criticisms, and your bug reports
Alternatively, you may send electronic mail to mec++@awl.com.
I maintain a list of changes to this book since its first printing, including bug-fixes, clarifications, and technical updates. This list, along with other book-related information, is available from the ftp.awl.comcp/mec++. If you would like a copy of the list of changes to this book, but you lack access to the Internet, please send a request to one of the addresses above, and I will see that the list is sent to