A fault-tolerant key/value service
- using a form of primary/backup replication.
- ensure that all parties (clients and servers) agree on which server is the
primary, and which is the backup
- introduce a kind of master server, called the viewservice.
- the viewservice monitors whether each available server is alive or dead.
- if the current primary or backup becomes dead, viewservice selects a server
to replace it
- a client checks with the viewservice to find the current primary
- the servers cooperate with the viewservice to ensure that at most one
primary is active at a time.
Key/value service will allow replacement of failed servers
- if primary fails, viewservice will promote backup to be primary
- if the backup fails, or is promoted, and there is an idle server available
the viewservice will cause it to be the backup
- the primary will send its complete database to the new backup
- and then send subsequent
Puts to the backup to ensure that the backup's
key/value database remains identical to the primary's.
It turns out the primary must send Gets as well as Puts to the backup
(if there is one), and must wait for the backup to reply before responding to
the client.
This helps prevent two servers from acting as primary (a "split brain").
An example:
S1 is the primary and S2 is the backup. - The view service decides (incorrectly) that
S1 is dead, and promotes S2 to
be primary.
- If a client thinks
S1 is still the primary and sends it an operation, S1
will forward the operation to S2, and S2 will reply with an error
indicating that it is no longer the backup (assuming S2 obtained the new
view from the viewservice).
S1 can then return an error to the client indicating that S1 might no
longer be the primary (reasoning that, since S2 rejected the operation,
a new view must have been formed); the client can then ask the view service
for the correct primary (S2) and send it the operation
A failed key/value server may restart, but it will do so without a copy of the
replicated data (i.e. the keys and values). That is, your key/value server will
keep the data in memory, not on disk. One consequence of keeping data only
in memory is that if there's no backup, and the primary fails, and then restarts,
it cannot then act as primary.
Only RPC may be used for interaction:
- between clients and servers,
- between different servers, and
- between different clients.
For example, different instances of your server are not allowed to share Go
variables or files.
Design limitations
The design outlined here has some fault-tolerance and performance limitations
which make it too weak for real-world use:
- The view service is vulnerable to failures, since it's not replicated.
- The primary and backup must process operations one at a time, limiting their
performance.
- A recovering server must copy a complete database of key/value pairs from the
primary, which will be slow, even if the recovering server has an almost
up-to-date copy of the data already (e.g. only missed a few minutes of
updates while its network connection was temporarily broken).
- The servers don't store the key/value database on disk, so they can't survive
simultaneous crashes (e.g., a site-wide power failure).
- If a temporary problem prevents primary to backup communication, the system
has only two remedies:
- change the view to eliminate the backup
- or keep trying
- neither performs well if such problems are frequent
- If a primary fails before acknowledging the view in which it is primary, the
view service cannot make progress---it will spin forever and not perform
a view change.
We will address these limitations in later labs by using better designs and
protocols. This lab will help you understand the problems that you'll solve in
the succeeding labs.
Must work out the details
The primary/backup scheme in this lab is not based on any published protocol.
- In fact, this lab doesn't specify a complete protocol; you must work out the
details.
The protocol has similarities with Flat Datacenter Storage (the viewservice is
like FDS's metadata server, and the primary/backup servers are like FDS's
tractservers), though FDS pays far more attention to performance.
It's also a bit like a MongoDB replica set (though MongoDB selects the leader with a Paxos-like
election).
For a detailed description of a (different) primary-backup-like protocol, see
Chain Replication. Chain Replication has higher performance than this lab's
design, though it assumes that the view service never declares a server dead
when it is merely partitioned. See Harp and Viewstamped Replication for a detailed
treatment of high-performance primary/backup and reconstruction of system state
after various kinds of failures.
The viewservice
- implement a viewservice
- make sure it passes our tests
- viewservice won't itself be replicated
- relatively straightforward.
- Part B is harderd because the K/V service is replicated and you have to design much of the replication protocol.
Viewservice:
- view service goes through a sequence of numbered views
- each has a primary and (if possible) a backup
- a view consists of a view number and the identity (network port name) of the view's primary and backup servers.
Primary/backup:
- primary in a view must always be either the primary or the backup of the previous view
- helps ensure that the key/value service's state is preserved
- an exception: when the viewservice first starts, accept any server at all as the first primary.
- the backup in a view can be any server (other than the primary)
- or can be altogether missing, if no server is available (represented by an empty string, "").
Key/value servers
- Each key/value server sends a
Ping RPC once per PingInterval (see viewservice/common.go)
- I don't need to do this. Done in the test cases for the viewservice.
- The view service replies to the
Ping with a description of the current view
- A
Ping lets the view service know that the key/value server is alive;
- informs the key/value server of the current view;
- informs the view service of the most recent view that the key/value server knows about
- If viewservice doesn't receive a
Ping from a server for DeadPings PingIntervals, the
viewservice considers the server to be dead.
- When a server re-starts after a crash, it should send one or more
Pings with an argument of
zero to inform the view service that it crashed.
Views
- view service proceeds to a new view if:
- it hasn't received recent
Pings from both primary and backup, or
- if the primary or backup crashed and restarted, or
- if there is no backup and there is an idle server (a server that's been Pinging but is
neither the primary nor the backup).
- the view service must not change views (i.e., return a different view to callers) until
the primary from the current view acknowledges that it is operating in the current view
(by sending a Ping with the current view number).
- if the view service has not yet received an acknowledgment for the current view from the primary
of the current view, the view service should not change views even if it thinks that the primary
or backup has died.
- that is, the view service may not proceed from view X to view X+1 if it has not received
a
Ping(X) from the primary of view X.
Why?
- the acknowledgment rule prevents the view service from getting more than one view ahead of the
key/value servers
- if the view service could get arbitrarily far ahead, then it would need a more complex design
in which it kept a history of views, allowed key/value servers to ask about old views, and
garbage-collected information about old views when appropriate.
Downside of the acknowledgement rule:
- if the primary fails before it acknowledges the view in which it is primary, then the
view service cannot ever change views again.
Example
An example sequence of view changes:
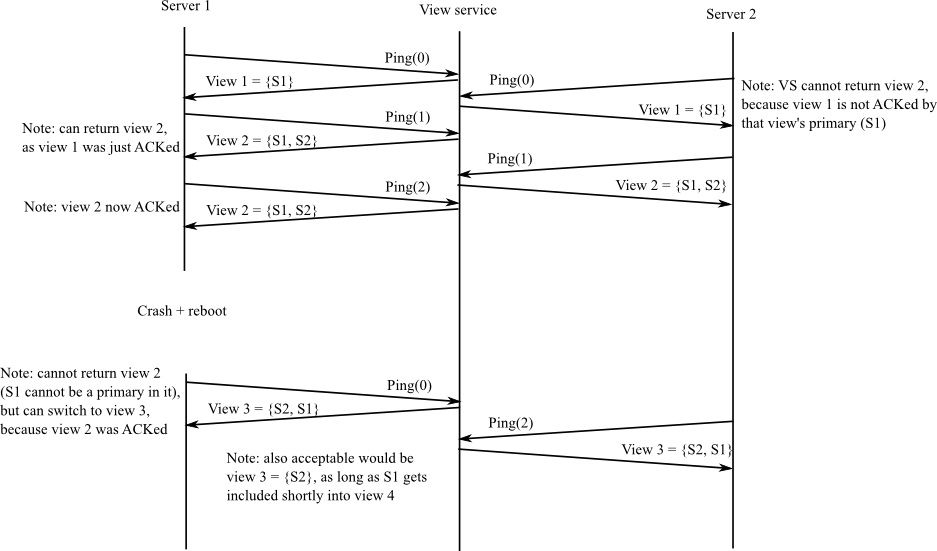
The above example is overspecified; for example, when the view server gets Ping(1) from S1 for the first time, it is also OK for it to return view 1, as long as it eventually switches to view 2 (which includes S2).
Questions
- Are we doing 1 primary server with 1 backup or
n primary servers with n backups?
Hints
Hint: You'll want to add field(s) to ViewServer in server.go in order to keep track of the
most recent time at which the viewservice has heard a Ping from each server. Perhaps a map from
server names to time.Time. You can find the current time with time.Now().
- We'll need this to measure if any servers have died
Hint: Add field(s) to ViewServer to keep track of the current view.
- Keep track of the view #, the primary, the backup
- Q: What else?
Hint: You'll need to keep track of whether the primary for the current view has acknowledged it
(in PingArgs.Viewnum).
- Every time we get a
Ping it includes the view # (just like TCP ACKs kind of)
- Where's the best place to store this? In the "last heard of" map?
Hint: Your viewservice needs to make periodic decisions, for example to promote the backup if the
viewservice has missed DeadPings pings from the primary. Add this code to the tick() function,
which is called once per PingInterval.
- So basically verify if primary is alive, backup is alive, by checking last ping
- Should probably also verify if the idles are alive
Hint: There may be more than two servers sending Pings. The extra ones (beyond primary and
backup) are volunteering to be backup if needed.
Hint: The viewservice needs a way to detect that a primary or backup has failed and re-started.
For example, the primary may crash and quickly restart without missing sending a single Ping.
- The view number in the
Ping tells us if the server restarted: if(rcvd view num < stored view num) then server crashed
- This basically tells us that we can't just rely on
tick() to detect
the failed servers
- We also need code in the
Ping handler
- Actually, not always
- It's possible that a
Ping packet was delayed and that could be why we're seeing older pings
- Thus, I think we should assume that when we see a
Ping(0) the server restarted
- Not clear how we should deal with delayed
Ping(0)
Hint: Study the test cases before you start programming. If you fail a test, you may have to look
at the test code in test_test.go to figure out the failure scenario is.
The easiest way to track down bugs is to insert log.Printf() statements, collect the output in a
file with go test > out, and then think about whether the output matches your understanding of how
your code should behave.
Remember: The Go RPC server framework starts a new thread for each received RPC request.
- multiple RPCs arrive at the same time (from multiple clients) => may be multiple threads running
concurrently in the server.
TODO: The tests kill a server by setting its dead flag. You must make sure that your server terminates when
that flag is set, otherwise you may fail to complete the test cases.
The primary/backup key/value service
- server code in
pbservice/
- part of the server in
pbservice/server.go
- part of the client interface in
pbservice/client.go
- clients use the service by creating a
Clerk object (see pbservice/client.go) and calling its methods
- Goal: service should:
- operate correctly as long as there has never been a time at which no server was alive
- TODO: You mean primary and backup? Or primary and backup and viewservice?
- operate correctly with network partitions
- server suffers network failure without crashing
- can talk to some but not others
- be able to incorporate idles as backups, if operating with one primary only
- provide at-most-once semantics for all operations
- Definition: correct operation means
Clerk.Get(k) return the latest value set by successful
calls to Clerk.Put(k,v) or Clerk.Append(k.v) or empty string if no such calls were made
- assume viewserver never crashes
- have a clear story for why there can only be one primary in your design
- Example:
- in view #1, S1 is primary
- viewserver changes views so that S2 is the primary
- S1 does not hear about it, thinks it's still primary
- some clients talk to S1, others to S2 and don't see each other's
Put() calls
- Solution:
- if viewserver made S2 primary, then S2 was the backup of S1 in the previous view (view #1)
- then when S1 gets a call, thinking it's still the primary, it will have to talk to its backup
(S2) and tell it about the new call it saw (this is why we have to replicate
Get() calls too).
- then, S2 will realize S1 didn't get updated and will tell it that the view has changed.
- S1 will then probably return an error to the caller and inform it about the new view.
- this also explains why the viewserver cannot advance the view further ahead unless the primary
acknowledges the previous view
- suppose S2 fails as the primary in view #2 and the viewserver moves to view #3 where some
server S3 is made primary (assuming S3 was backup in view #2)
- then S2 comes back up and it's a backup again (in view #4, S2 is a backup for S3)
- now, S1 still thinks he's in view #1 with S2 as a backup and S2 does think it's a backup
but he's in view #4 (and is a backup for S3)
- unless S2 can distinguish between ops coming from S3 and S1, we're in trouble because
S1 and S3 client ops will both be sent to S2 and screw each other up
Clerk.Get/Put/Append should only return when they have completed the op
- keep trying until success
- server must filter out duplicate RPCs (ensure at-most-once semantics)
- Note: assume each cleark has only one outstanding
Put or Get
- TODO: does this mean one op at a time for clients?
- Note: think carefully about what the commit point is for a
Put
- TODO: not sure what this means?
- neither clients nor servers should talk to viewservice for every op (performance issues)
- servers just ping periodically to get view updates
- clients cache current primary and talk to the viewserver when primary seems dead
- ensure backup is up-to-date
- primary initializes it with the complete key/value db
- then forwards subsequent client ops
- primary only forwards
Append() args, not the full resulting value (could be too large)
- TODO: do we need to worry about out-of-order here?
Plan of attack
- Start by modifying
pbservice/server.go to ping the viewservice and get curr. view
- do this in the
tick() function
- Implement
Get, Put, Append handlers in pbservice/server.go
- store keys and values in a
map[string]string
- Implement
pbservice/client.go RPC stubs
- Modify
pbservice/server.go handlers to forward updates to backup
- New backup in view
=> primary sends it complete key/value DB
- TODO: would take a while. does primary accept new ops? if it does, maybe puts them
in another new map that it starts syncing to the backup once the first map is transferred?
this would assume that new ops are coming at a slow-enough rate to allow the primary to catch
up
- Modify
pbservice/client.go to keep retrying
- include enough info in
PutAppendArgs and GetArgs (xid?) (see common.go) for the
server to detect duplicates
- Modify the key value service (
pbservice/server.go?) to handle duplicates correctly
- TODO: look at
Get/PutAppendArgs for xid? cache responses by xid
- Modify
pbservice/client.go to handle failed primary
- primary seems dead or doesn't think it's the primary
=> client asks viewserver and tries again
- sleep for
viewservice.PingInterval to avoid wasting CPU time
- wtf, networking calls will sleep the thread for long enough
Hints
- create new RPCs for:
- primary to forward client requests to backup
- primary to transfer the complete key value DB to backup
- include the
map[string]string as an argument to the RPC call
- the state used to filter duplicates (XIDs) must be replicated along with the key/value state
- RPC replies are lost in "unreliable" tst cases
=> servers execute the op, but client's won't
know it => use XIDs to remember op results on the server and in the client args
- see the
nrand PRNG code for generating XIDs
- make sure servers terminate correctly when the
dead flag is set
- WARNING: part A bugs that somehow passed the part A tests could screw up your part B test cases
- study the test cases before coding