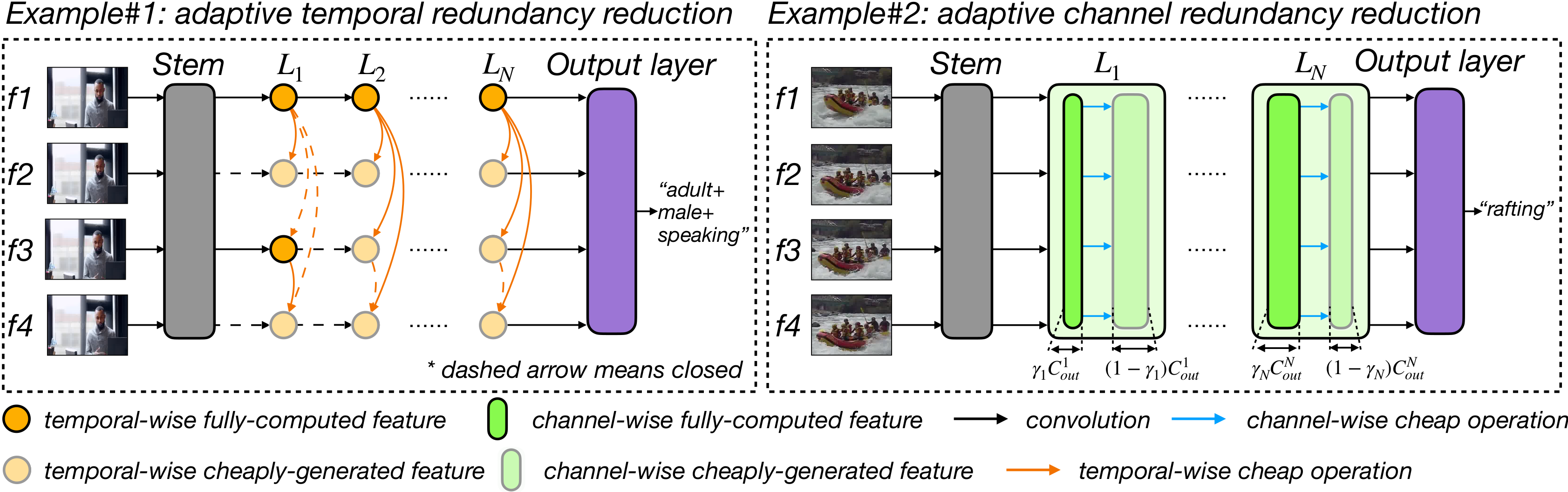
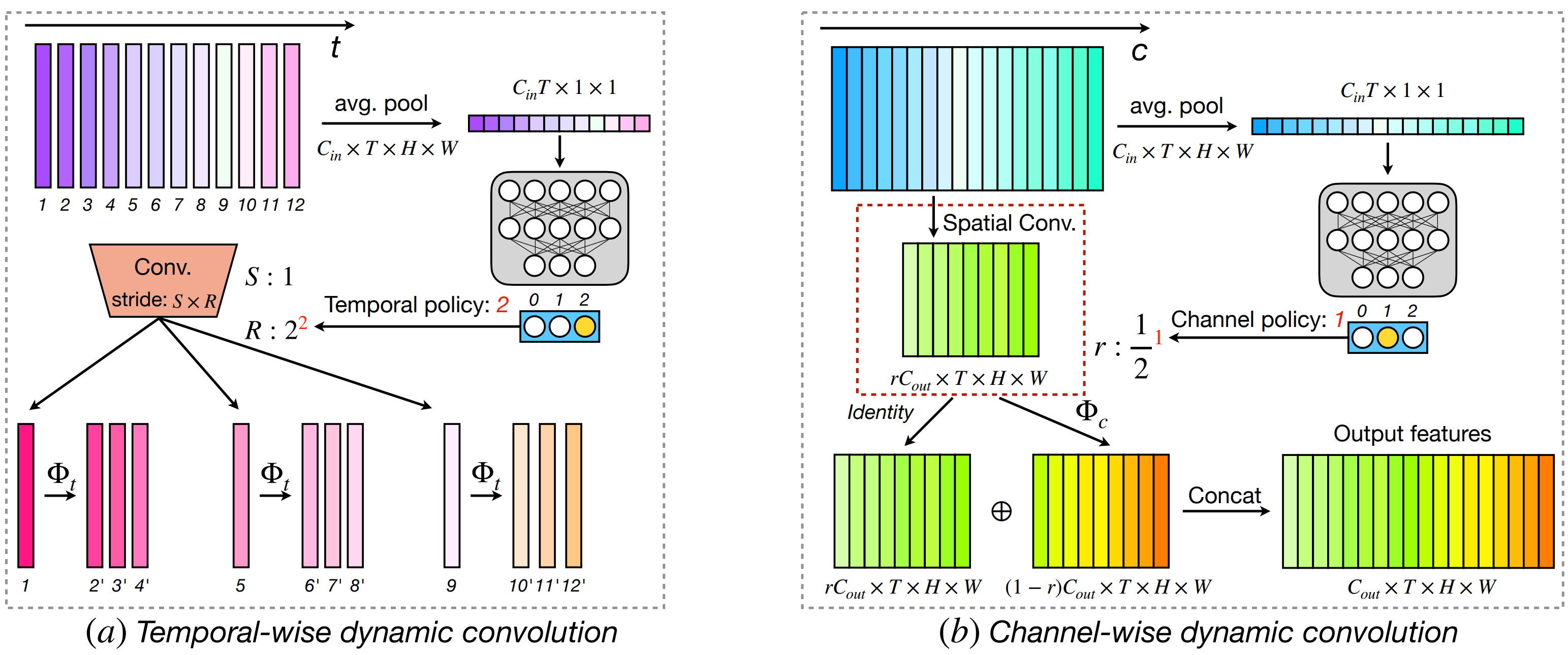
Our VA-RED2 framework dynamically reduces the redundancy in two dimensions. Example 1 (left) shows a case where the input video has little movement. The features in the temporal dimension are highly redundant, so our framework fully computes a subset of features, and reconstructs the rest with cheap linear operations. In the second example, we show that our framework can reduce computational complexity by performing a similar operation over channels: only part of the features along the channel dimension are computed, and cheap operations are used to generate the rest.
VA-RED2: Video Adaptive Redundancy Reduction |
||
Bowen Pan1, Rameswar Panda2, Camilo Fosco1, Chung-Ching Lin3, Alex Andonian1, Yue Meng2,Kate Saenko2,4, Aude Oliva1,2, Rogerio Feris2 |
||
1 MIT CSAIL, 2 MIT-IBM Watson AI Lab, 3 Microsoft, 4 Boston University |
||
[Paper] [Code (coming soon)] |
||