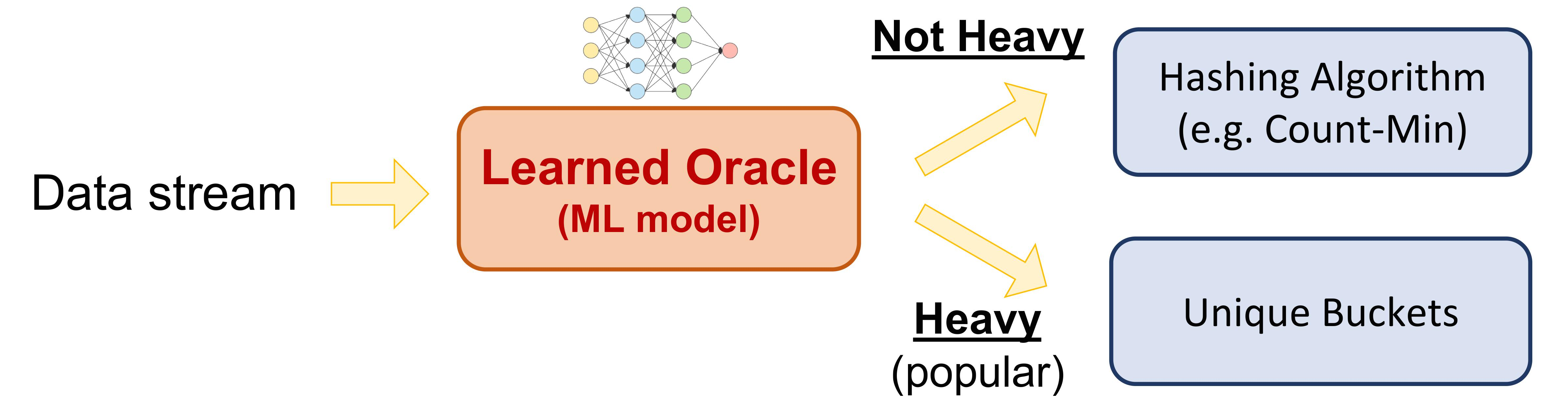
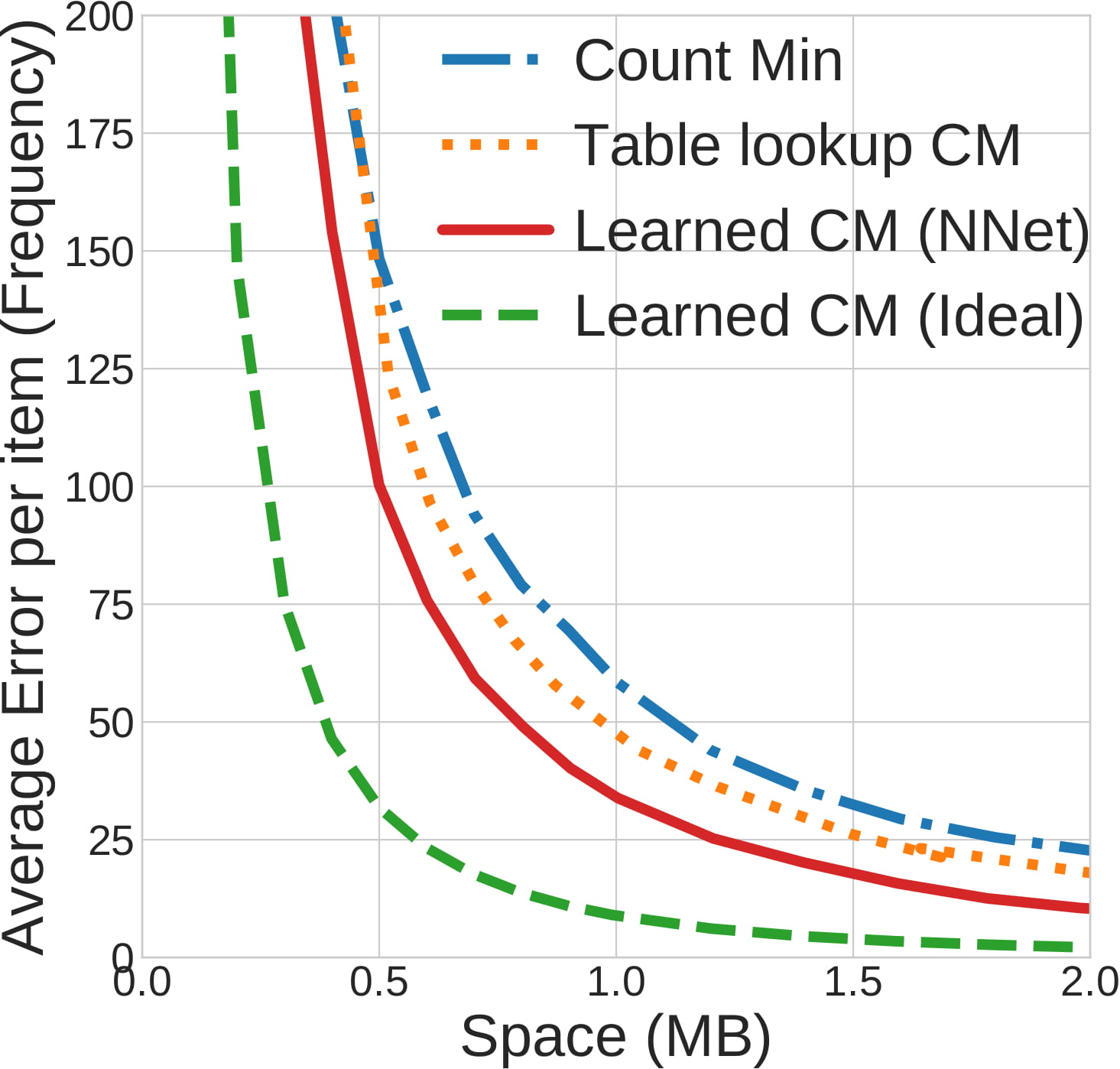
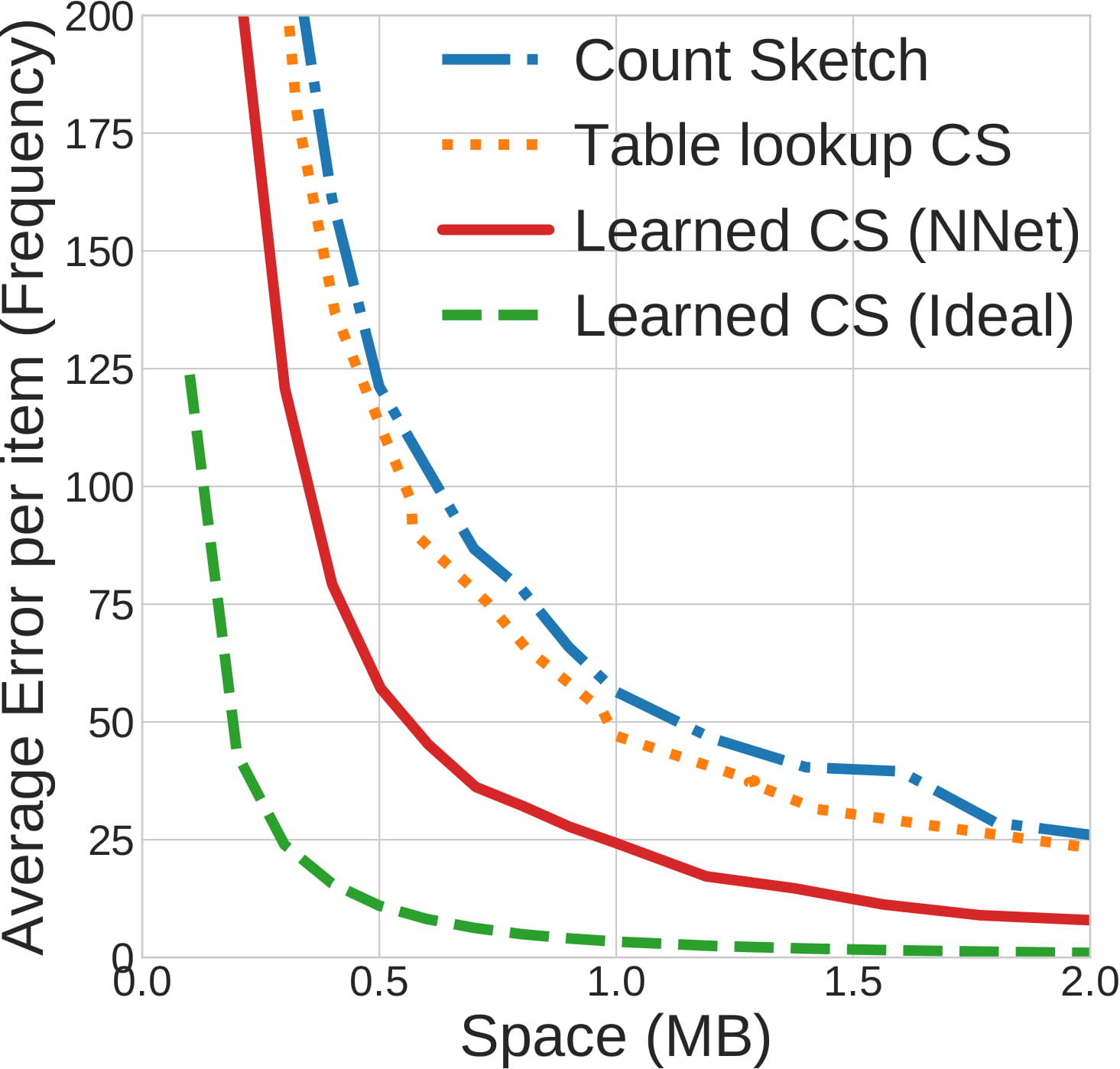
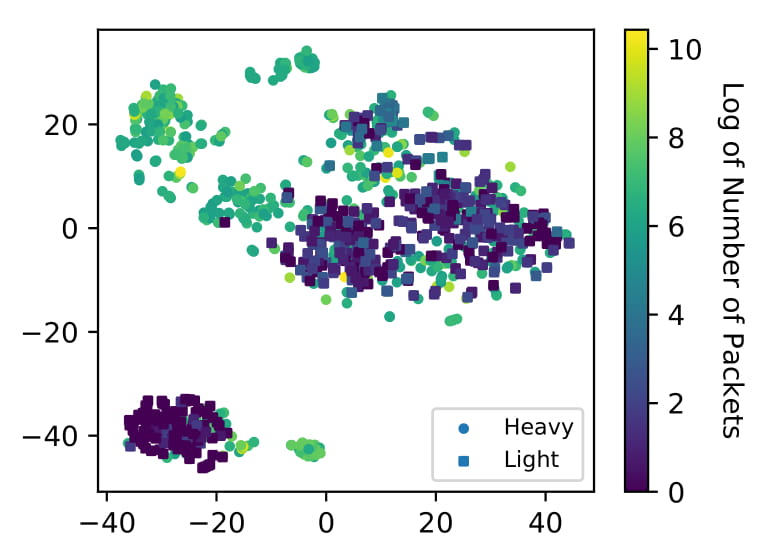
Frequency Estimation in Streaming Data?
Streaming Data is data that is generated continuously by thousands or millions of data sources, such as:
- Internet traffic data across the web or within data centers of large companies
- Search queries entered by users around the world on search engines
- Information from social networks, log files from mobile or web appliacations, etc
The goal of Frequency Estimation is to count the number of times an item appears in the stream.
- Which internet links have the most traffic?
- Which search phrases are trending now?
- What are the trending topics on the social network?
However, in big data applications, the stream is too large (and may be infinite) and cannot be stored.
This challenge has motivated the development of streaming algorithms.