


Next: Extensions
Up: Efficiently propagating probability masses
Previous: Monte Carlo trials
Observing that the computation is burdened by storing the sheer amount
of probability mass entries when there are many targets and
observations, an obvious simplification is to resample the
entries and keep the important ones. For example, we may choose to
retain the first 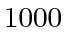 probability mass entries of largest
value. With each step of processing looking at each entry once, the
processing time per step becomes a constant, albeit a large one. With
this approximation, the earlier algorithm then runs in time linear in
the number of observations. We call this heuristic basic truncation.
probability mass entries of largest
value. With each step of processing looking at each entry once, the
processing time per step becomes a constant, albeit a large one. With
this approximation, the earlier algorithm then runs in time linear in
the number of observations. We call this heuristic basic truncation.
The problem with basic truncation, however, is that the trimmed away
entries may turn out to be important. Take the processing in Table
V for example, if the fourth entry after the merge step,
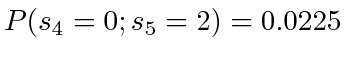 , is truncated, then the second entry in
the end,
, is truncated, then the second entry in
the end,
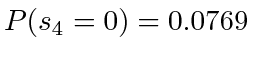 , will be lost, which is
significant. The issue becomes problematic very quickly as the number
of coexisting shadows increases, since each shadow creates one
dimension in the joint distribution and sampling a high dimensional
space is inherently inefficient. To alleviate this problem, in
addition to the basic truncation approach of keeping fixed amount of
entries with highest probability after each update, we also employ the
following:
, will be lost, which is
significant. The issue becomes problematic very quickly as the number
of coexisting shadows increases, since each shadow creates one
dimension in the joint distribution and sampling a high dimensional
space is inherently inefficient. To alleviate this problem, in
addition to the basic truncation approach of keeping fixed amount of
entries with highest probability after each update, we also employ the
following:
- 1)
- Randomly allow probability mass entries with low value to
survive truncation. In doing this, we hope to allow enough low
probability yet important entires to survive truncation. We denote
this heuristic as random truncation.
- 2)
- Retain more entries during update steps right before
merge and disappear events. Since disappear events usually cause the
the number of probability mass entires to decrease dramatically
(concentrating the distribution, or reducing the uncertainty), we
can afford to keep more entries right before these events, without
incur much extra computational cost. Merge events also cause the
number to decrease as some entries can be combined after merging. We
combine this with random truncation and denote the resulting heuristic random truncation with event lookahead.
By construction, it is straightforward to see that the additional
heuristics do not need asymptotically more time. There is a clear
similarity between these heuristics and particle filtering: They all
begin with a discrete set of probability masses, push the set through
an update rule, and resample when necessary. They also share the same
weakness: If the key sample points with low probabilities are
truncated, the end result may be severely skewed. Unlike in typical
particle filter problems, the number of random variables in our
problem keeps changing with split and merge events.
Next: Extensions
Up: Efficiently propagating probability masses
Previous: Monte Carlo trials
Jingjin Yu
2011-01-18