Often one is interested in finding patterns which appear over time. Such sequential data are ubiquitous and are of interest to many communities and can be found in virtually all application areas of machine learning including computational biology, user modeling, speech recognition, empirical natural language processing, activity recognition, information extractions, etc. Hidden Markov models (HMMs) are among the most popular probabilistic sequence models.
A hidden Markov model is a statistical model where the system being modeled is assumed to be a Markov process. It is called 'hidden' because what we wish to predict is not what we observe - the underlying process is hidden. The challenge is to determine the hidden parameters from the observable parameters.
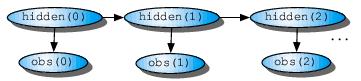
The Figure below shows the general architecture of HMMs viewed as a Bayesian network.
Each oval shape represents a random variable that can adopt a number of
values. The random variable hidden(T) is the value of the hidden variable
atsome time t. The random variable obs(T) is the value of the observed
variable at some time t. The arrows in the diagram denote conditional
dependencies.
From the diagram, it is clear that the value of the hidden variable hidden(T) only depends on the value of the hidden variable hidden(T-1). Similarly, the value of the observed variable obs(t) only depends on the value of the hidden variable hidden(T).
There are three main problems associated with HMMs: