
Recursive Segmentation and Recognition Templates for 2D Parsing
Long Zhu, Yuanhao Chen, Yuan Lin, Chenxi Lin, Alan Yuille
Introduction
Language and image understanding are two major tasks in
artificial intelligence. Natural language researchers have formalized this task
in terms of parsing an input signal into a hierarchical representation. They
have made great progress in both representation and inference (i.e. parsing).
Firstly, they have developed probabilistic grammars (e.g. stochastic context
free grammar (SCFG) \cite{jelinek91cl} and beyond \cite{collins99}) which are
capable of representing complex syntactic and semantic language phenomena. For
example, speech contains elementary constituents, such as nouns and verbs, that
can be recursively composed into a hierarchy of (e.g. noun phrase or verb
phrase) of increasing complexity. Secondly, they have exploited the
one-dimensional structure of language to obtain efficient polynomial-time
parsing algorithms (e.g. the inside-outside algorithm \cite{lari90csl}).
By contrast, the nature of images makes it much harder to design efficient image
parsers which are capable of simultaneously performing segmentation (parsing an
image into regions) and recognition (labeling the regions). Firstly, it is
unclear what hierarchical representations should be used to model images and
there are no direct analogies to the syntactic categories and phrase structures
that occur in speech. Secondly, the inference problem is formidable due to the
well-known complexity and ambiguity of segmentation and recognition. Unlike most
languages (Chinese is an exception), whose constituents are well-separated
words, the boundaries between different image regions are usually highly
unclear. Exploring all the different image partitions results in combinatorial
explosions because of the two-dimensional nature of images (which makes it
impossible to order these partitions to enable dynamic programming). Overall it
has been hard to adapt methods from natural language parsing and apply them to
vision despite the high-level conceptual similarities (except for restricted
problems such as text \cite{shilman05iccv}).
Attempts at image parsing must make trade-offs between the complexity of the
models and the complexity of the computation (for inference and learning).
Broadly speaking, recent attempts can be divided into two different styles. The
first style emphasizes the modeling problem and develops stochastic grammars
\cite{tu02pami, tu03iccv} capable of representing a rich class of visual
relationships and conceptual knowledge about objects, scenes, and images. This
style of research pays less attention to the complexity of computation. Learning
is usually performed, if at all, only for individual components of the models.
Parsing is performed by MCMC sampling and is only efficient provided effective
proposal probabilities can be designed \cite{tu03iccv}. The second style builds
on the success of conditional random fields (CRF's) \cite{lafferty01icml} and
emphasizes efficient computation. This yields simpler (discriminative) models
which are less capable of representing complex image structures and long range
interactions. Efficient inference (e.g. belief propagation and graph-cuts) and
learning (e.g. AdaBoost, MLE) are available for basic CRF's and make these
methods attractive. But these inference algorithms become less effective, and
can fail, if we attempt to make the CRF models more powerful. For example,
TextonBoost \cite{shotton06eccv} requires the parameters of the CRF to be tuned
manually. Overall, it seems hard to extend the CRF style methods to include
long-range relationships and contextual knowledge without significantly altering
the models and the algorithms.
In this paper, we introduce Hierarchical Image Models (HIM)'s for image parsing.
HIM's balance the trade-off between model and inference complexity by
introducing a hierarchy of hidden states. In particular, we introduce \emph{recursive
segmentation and recognition templates} which represent complex image knowledge
and serve as elementary constituents analogous to those used in speech. As in
speech, we can recursively compose these constituents at lower levels to form
more complex constituents at higher level. Each node of the hierarchy
corresponds to an image region (whose size depends on the level in the
hierarchy). The state of each node represents both the partitioning of the
corresponding region into segments and the labeling of these segments (i.e. in
terms of objects). Segmentations at the top levels of the hierarchy give
coarse descriptions of the image which are refined by the segmentations at the
lower levels. Learning and inference (parsing) are made efficient by exploiting
the hierarchical structure (and the absence of loops). In short, this novel
architecture offers two advantages: (I) Representation -- the hierarchical model
using segmentation templates is able to capture long-range dependency and
exploiting different levels of contextual information, (II) Computation -- the
hierarchical tree structure enables rapid inference (polynomial time) and
learning by variants of dynamic programming (with pruning) and the use of
machine learning (e.g. structured perceptrons \cite{collins02emnlp}).
To illustrate the HIM we implement it for parsing images and we evaluate it on
the public MSRC image dataset \cite{shotton06eccv}. Our results show that the
HIM outperforms the other state-of-the-art approaches. We discuss ways that
HIM's can be extended naturally to model more complex image phenomena.
Figure 1: The left panel shows the structure of the Hierarchical Image Model. The grey circles are the nodes of the hierarchy. All nodes, except the top node, have only one parent nodes. All nodes except the leafs are connected to four child nodes. The middle panel shows a dictionary of
30 segmentation templates. The color of the sub-parts of each template indicates the object class. Different sub-parts may share the same label. For example, three sub-parts may have only two distinct labels. The last panel shows that the ground truth pixel labels (upper right panel) can be well approximated by composing a set of labeled segmentation templates (bottom right panel).
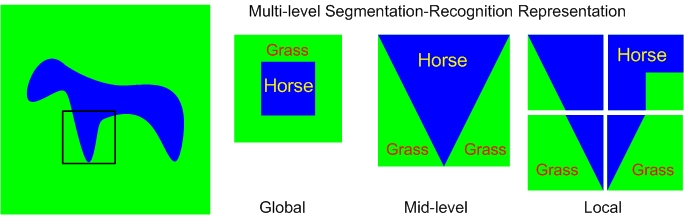
Figure 2: This figure illustrates how the segmentation templates and object labels (S-R pair) represent image regions in a coarse-to-fine way. The left figure is the input image which is followed by global, mid-level and local S-R pairs. The global S-R pair gives a coarse description of the object identity (horse), its background (grass), and its position in the image (central). The mid-level S-R pair corresponds to the region bounded by the black box in the input image. It represents (roughly) the shape of the horse's leg. The four S-R pairs at the lower level combine to represent the same leg more accurately.

Figure 4: This figure is best viewed in color. The colors indicate the labels of 21 object classes as in [8]. The columns (except the fourth "accuracy" column) show the input images, ground truth, the labels obtained by HIM and the boosting classifier respectively. The "accuracy" column shows the global accuracy obtained by HIM (left) and the boosting classifier (right). In these 7 examples, HIM improves boosting by 1%, -1% (an outlier!), 1%, 10%, 18%, 20% and 32% in terms of global accuracy.