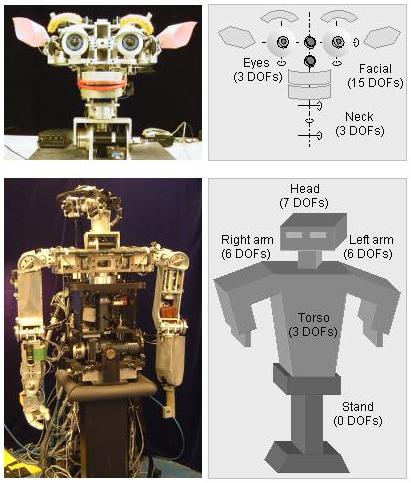
|
One of the things Cog can do is learn about objects by poking them
and seeing what happens. If can identify the boundaries of objects
by pushing them a little and see what parts move together (the
object) and what stays still (the background).
This is called active segmentation.
Once Cog can reliably segment objects, then it can learn about
their appearance and how they move.
(A paper on this topic,
also see thesis chapter 3).

Active segmentation in action. Cog resolves visual ambiguity by poking around and seeing what happens.
| Video: Active segmentation |
|
Cog taps a toy with his flipper and uses the motion to segment
the object from the background.
Quicktime -- (2.0 MB)
Length: approximately 20 seconds
|

|
Cog can learn to recognize new objects by interacting with them.
Open Object Recognition is the ability to recognize a
flexible set of objects, where new objects can be introduced at
any time. Conventional object recognition systems do not
need to be open - for example, the set of objects an
industrial robot needs to interact with is likely to
be fixed. But a humanoid robot in an unconstrained
environment could be presented with just about anything,
so it needs to have an open object recognition system.
The alternative would be to enumerate and train for all
the possible objects the robot might encounter, which is
not practical.
(A paper on this topic,
also see thesis chapter 5).
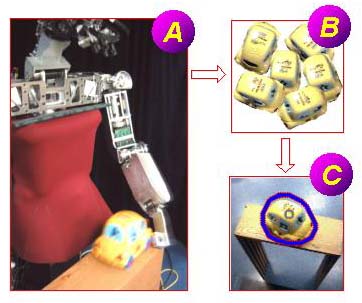
Cog pokes objects (A), learns their appearance (B), and then recognizes
them if it sees them again (C).
| Video: Open object recognition |
|
In this video, Cog is confronted with a new object (a red ball).
Since it has limited experience at this point, it confuses the ball
with another object (a cube) which has similar color.
Once Cog pokes the object, after about 5 seconds processing it can
correctly distinguish between these objects based on shape.
Quicktime -- (6.7 MB)
Length: approximately 1 minute
|

|
|
|
Role transfer is a mechanism for incremently passing control for more
and more of a task over to a robot.
The instructor demonstrates the task while providing verbal
annotation. The vocal stream is used to construct a model of the
task. Generic machine learning methods are then used to ground this
model in the robot's perceptual network, guided by feature selection
input from the human. The idea is to avoid ever presenting the robot
with a hard learning problem; the learning algorithms are intended to
be decoders allowing the human to communicate changes in
representation, rather than to learn in the conventional sense.
(A paper on this topic,
also see thesis chapter
10).
Role transfer. Kismet watches human sorting green objects to one
side and yellow objects to other. When prompted, robot says the
direction it expects a new object to go.
Quicktime -- (1.5 MB)
Length: approximately 1.5 minutes
|

|
| Video: Learning through activity |
|
In this video, the operator tells Cog they are going to "find" a "toma".
Then they look at several objects in turn, saying "no" to each.
Finally the operator shows Cog a bottle and says "yes".
Cog then associates the name "toma" with the bottle, by
analogy with previous search episodes.
Quicktime -- (23.5 MB)
Length: 1.5 minutes
|

|
Many classical vision problems can be addressed in an empirical manner
on a robot -- instead of building complete models, it suffices to
build partial models, and behaviors that can collect the training
data necessary to complete those models.
I have used this approach for orientation detection,
affordance characterization
(poster,
paper), and
object recognition.
(See thesis chapters
4,
7, and
5
respectively).
|
|
I collaborate with Charlie Kemp on
Platform Shoe, a project to find
innovative camera placements for wearable computing. Shoes are a good
spot since, during walking, they are pressed quite firmly against
the ground, giving a relatively stable view of the environment.

"Platform Shoe" - (more information)
|
|
I collaborate with Artur Arsenio on
multimodal recognition, an effort
to recognize periodically moving objects by the relationship between
their visual trajectories and the sound they generate.
|
|
|