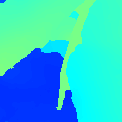
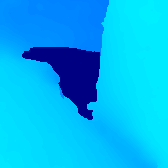
Legend:
- Captured: the actual image captured at that view, which serves as the ground truth
- Interp using SGM depth: interpolated image using the depth map recovered by SGM.
- Interp using our depth: interpolated image using the depth map recovered by our technique
Teddy
 |
|


In the interpolated view using SGM depth, some background pixels near the boundary are missing. For example, both the digit 2 in the top patch and the digit 4 in the bottom patch are missing (compared SGM with the ground truth). This is because depth at those regions is incorrect due to foreground fattening. Such errors do not exist in our result.
Disney-mansion
 |
|


In the interpolated view using depth calculated by SGM, there are haloes around leaves (the top patch) or the spike (the bottom patch) due to the foreground fattening, while the boundary of these objects is much cleaner in our result.
The following results show the synthesized videos using our depth maps. The first and the last frame of each sequence are used as inputs and the rest frames are generated by view interpolation.Teddy
Disney-mansion
Back to top 2. Results on Midd-F Back to top We provide the depth maps recovered by our technique on Midd-F, along with intermediate results (depth of edges and depth of patches), and comparisons with SGM. Please mouse over or click on the labels beneath each image to switch between them (it might take 1-2 seconds to load an image since the images are very large). Two corresponding close-up views are shown besides each sequence.
Legend:
- SGM depth: the estimated depth map with SGM algorithm
- Our depth: the estimated depth map with our algorithm
- SGM error, Our error: black regions are errors in non-occluded regions, and gray regions are errors in occluded regions (threshold=2.0).
- Depth of edges: sparse depth map of edges by edge matching.
- Depth of patches: depth of derived overlapping slanted planes from edges. For all the sequences, the patch size is 32x32. But since different sequences have different size, the size of the patches may look different.
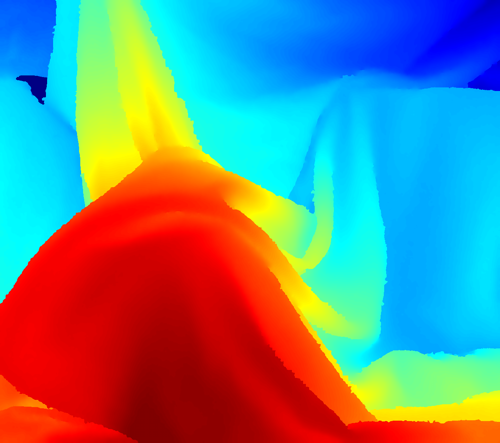
Aloe
Our depth, error rate=2.38
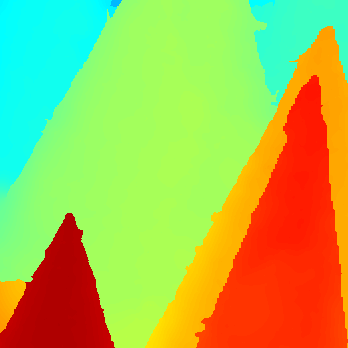
| Art
Our depth, error rate=3.32 In the SGM depth, the leaf shown in the top patch is thicker than it should be (compared with ground truth depth), and there are also errors between two leaves shown in the bottom patches. Those errors do not exist in our depth map. Much of the error in our depth occurs at the bulge of the aloe and one of bottom leaf (see the error map). This is primarily due to the fact that these regions are less textured, and therefore fewer edges were detected (see depth of edges). The boundaries of the three pens shown in the top patch are mostly accurate in our depth map, but are thicker than the ground truth in the SGM depth map. Our algorithm also produces fewer errors on the background (see both patches).
|