Learning Latent Representations for Speech Generation and Transformation
(this work is to appear in Interspeech 2017. the paper can be found here)
What This Work Is About?
- apply a convolutional VAE to model the generative process of natural speech.
- derive latent space arithmetic operations to disentangle learned latent representations.
- demonstrate the capability to randomly generate short speech segments (200ms).
- demonstrate the capability to modify the phonetic content or the speaker identity for speech segments using the derived operations, without the need for parallel supervisory data.
Latent Attribute Representations
Suppose the prior distribution of the latent variable is an isotropic Gaussian, We make the following two assumptions:
- independent attributes, such as the phonetic content and the speaker identity, are modeled by VAEs using orthogonal latent subspaces.
- conditioning on some attribute $a$ being $r$, such as the phone being /ae/, the prior distribution of the latent variable is also a Gaussian, whose mean is defined as the latent attribute representation.
In other words, take the phonetic content and the speaker identity for example again: latent speaker representations of different speakers should reside in a subspace of the latent space, and so do latent phone representations of different phonemes; however, the two subspaces should be orthogonal if the two attributes are independent.
The figure below shows the cosine similarity scales between six latent speaker representations and ten latent phone representations. We can observe that off-diagonal blocks have lower cosine similarity scales, which indicates that the two groups of latent attribute representations reside in orthogonal subspaces.
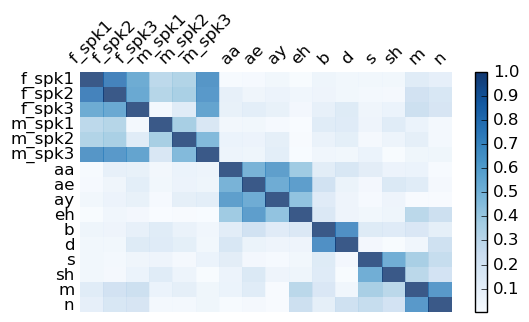
Modifying Speech Attributes
Since we’ve seen that VAEs model speaker and phone attributes using orthogonal subspaces, we are now able to modify one without affecting the other by applying some simple arithmetic operations in the latent space!
Suppose there are $K$ independent attributes that affect the realization of speech, each attribute is then modeled using a subspace that is orthogonal to those of the others. In other words, the latent representation can be decomposed into $K$ orthogonal latent attribute representations. Therefore, to replace the $k$-th attribute of a speech segment from being $r$ to $\tilde{r}$, we can simply apply the following operations:
- infer the latent variable $z$ of the speech segment $x$.
- subtract $z$ by the latent attribute representation of the $k$-th attribute being $r$.
- add the latent attribute representation of the $k$-th attribute being $\tilde{r}$ to the modified $z$ from step 2.
- generate speech segment conditioned on the modified $z$ from step 3.
Examples of Modified Speech
Modify the Phone
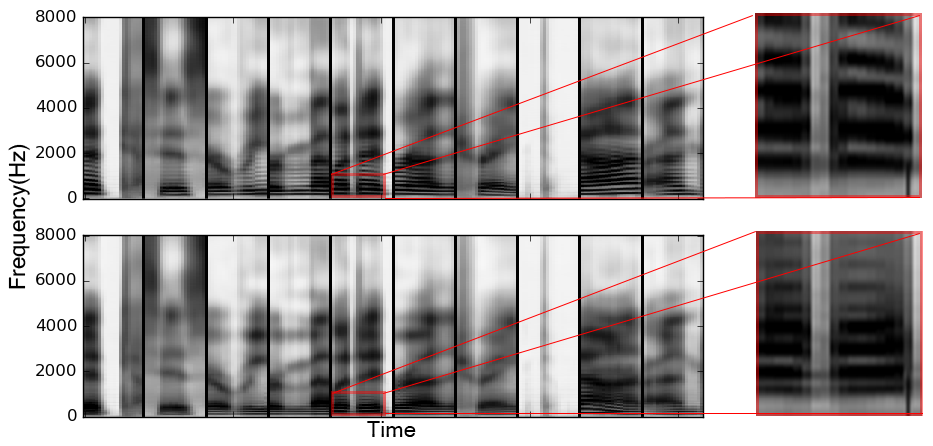
In the following figure, we modifying 10 speech segments of /aa/ to /ae/. The first row shows the original spectrogram, while the second row shows the modified spectrogram. The second formant, F2, is marked with red boxes. We can clearly observe that the second formant of each instance goes up after modification, because it is being changed from a back vowel to a front vowel. On the other hand, the harmonics of each instance, which are closely related to the speaker identity, maintain roughly the same.

Here we reconstruct a few audio clips before and after modification. Since the VAE is designed to model the magnitude spectrogram only, we use Griffin-Lim algorithm to estimate the phase from the magnitude spectrogram, and reconstruct the waveforms using the estimated phase.
From these examples, we can also clearly hear the difference of phonetic content after modification, while the speaker identity maintains the same perceptually.
Modify the Speaker
Likewise, we sample 10 speech segments of a female speaker falk0 and replace the latent speaker attribute of another male speaker, madc0. Results and audio samples are shown below in the same format.
We highlight and zoom in the regions where we can clearly observe one of the significant difference between male and female speakers – the harmonics, which are the horizontal stripes in the spectrogram. The more dense the horizontal stripes are, the lower the pitch of the speaker is. We can clearly observe from the figure or hear from the audio samples that the pitch is decreased after modification.
Quantitative Evaluation of Modification Capability
To quantitatively evaluate the modification performance, we trained two convolutional neural network discriminators, one for speaker classification, and the other for phoneme classification. We use the posterior probability of the original property and the target property of the attribute we want to modify as the indicator. The 58-class phone classifier achieves a test accuracy of 72.2%, while the 462-class speaker classifier achieves a test accuracy of 44.2%.
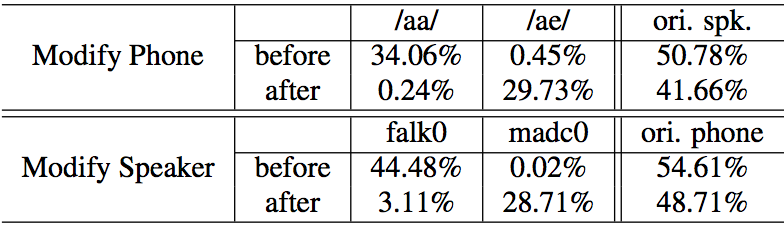
The upper half of the table contains results for speech segments that were transformed from /aa/ to /ae/. The first row shows that the average /aa/ posterior was 34% while the average correct speaker posterior was 51%. The second row shows that after modification to an /ae/, the average phone posteriors shift dramatically to be 30% /ae/, while slightly degrading the average correct speaker posterior.
The lower part of the table shows the results of speech segments that had speaker identity modified from speaker ‘falk0’ to ‘madc0’. The third row shows an average speaker posterior of 44% for ‘falk0’ in the unmodified samples, while the average correct phone posterior was 55%. After modification we see that the average speaker posterior has shifted to be 29% ‘madc0’ while slightly degrading the average correct phone posterior.
Conclusion and Future Work
- We present a convolutional VAE to model the speech generation process, and learn latent representations for speech in an unsupervised framework.
- The abilities to decompose the learned latent representations and modify attributes of speech segments are demonstrated qualitatively and quantitatively.
- The VAE framework leverages vast quantities of unannotated data to learn a general speech analyzer and a general speech synthesizer.
- The derived attribute-modifying operations can be potentially applied to voice conversion and speech denoising without the need of parallel training data.
Reference
Bibilographic inforamtion for this work:
@inproceedings{hsu2017learning,
title={Learning Latent Representations for Speech Generation and Transformation},
author={Hsu, Wei-Ning and Zhang, Yu and Glass, James},
booktitle={Interspeech},
pages={1273--1277},
year={2017},
}