This document provides an overview of the usage of jFuzz and how to extend jFuzz using the built in extension points. Usage Documentation describes how to use jFuzz and the arguments. Development Documentation describes the architecture of jFuzz and the requirements for each extension point.
Contents:Usage Documentation
This describes how to obtain jFuzz, preparing an subject program, and how to use jFuzz.
Obtaining jFuzz
jFuzz is included as an extension to Nasa Java PathFinder (JPF). Download JPF and compile the sources including the concolic extension (instructions below). This is the extension which includes jFuzz.
NOTE: Core JPF moved from SourceForge to BabelFish. Until we move jFuzz there as well, please keep using SVN from SourceForge. jFuzz was last tested on revision 1918 of JPF (October 1, 2009).
To install jFuzz and execute a simple test, run the following sequence of commands:
svn -r 1918 co https://javapathfinder.svn.sourceforge.net/svnroot/javapathfinder javapathfinder cd javapathfinder/trunk/ build-tools/bin/ant run-tests build-tools/bin/ant -f extensions/symbc/build.xml build-tools/bin/ant -f extensions/concolic/build.xml compile-extension compile-extension-tests cp -r build/test/jfuzz/tests/ build/jpf/jfuzz/ extensions/concolic/simpleTest.sh
Preparing the Subject Program
To prepare the subject program for jFuzz follow these steps:- Run the subject program under JPF. If this does not work you will need to modify the subject until it runs under JPF. Programs which make heavy use of reflection or have GUIs do not run well under JPF.
- Remove all calls to System.exit from the subject. Calls to System.exit cause jFuzz to terminate while executing the subject.
- Create a test driver and insert a call to jfuzz.DebugFuzz.fuzzPC. If there is a main method in the subject this will work as the test driver, just insert the call to fuzzPC at the end. If there is no main method create a small test driver which calls the method you are interested in and insert the call to fuzzPC at the end.
- Select or Create a symbolic method. This is the method which will mark arguments to be watched and included in the PathCondition. For best results, this method should be one which touches the input file directly.
jFuzz Arguments
This table contains the arguments which are required to run jFuzz:
| Argument | Value (* means required value) |
| jpf.listener | jfuzz.ConcolicListener* |
| search.class | gov.nasa.jpf.search.Simulation* |
| vm.insn_factory.class | gov.nasa.jpf.concolic.ConcolicInstructionFactory* |
| jpf.report.console.finished | [nothing]* |
| jpf.basedir | The path to the JPF code from the subject program. |
| symbolic.method | The method which will have it's inputs marked as symbolic. This is of the same form as is used for Symbolic JPF. |
| jfuzz.input.cp | The classpath required for running the subject program. |
| jfuzz.input | The well formed input file that will be used as the initial input. |
The following table contains optional jFuzz arguments:
| Argument | Description |
| jfuzz.cache | Specifies the CacheStrategy. |
| jfuzz.nextfile | Specifies the NextFileStrategy. |
| jfuzz.termination | Specifies the TerminationStrategy. |
| jfuzz.del | If true, jFuzz will delete inputs which do not cause errors. (Default is false) |
| jfuzz.timing | If true, timing measurements will be recorded (see here). (Default is false) |
| jfuzz.coverage | The jar specified will be used to measure coverage with EMMA. (see here). |
| jfuzz.debug | If true, jFuzz will run in Debug mode. (Default is false) |
CacheStrategy
CacheStrategy specifies how jFuzz caches PathConditions. Currently jFuzz has two available caching strategies: NameIndependentCache, and NoCache. See here for a description of how to implement a CacheStrategy.
- NameIndependentCache: removes the dependence on variable names from the PathCondition and stores the appropriate values. This is the default CacheStrategy.
- NoCache: does not cache any PathConditions.
NextFileStrategy
NextFileStrategy specifies how jFuzz caches PathConditions. Currently jFuzz has four available next file strategies: Coverage, Newest, Oldest, and Random. See here for a description of how to implement a NextFileStrategy.
- Coverage: Selects the next input based on which of the unprocessed inputs will increase the aggregate coverage the most. Requires the argument jfuzz.coverage.
- Newest: Selects the newest unprocessed input.
- Oldest: Selects the oldest unprocessed input. This is the default.
- Random: Selects a random unprocessed input.
TerminationStrategy
jFuzz with automatically stop when there are no unprocessed inputs available, if you wish to stop the execution of jFuzz sooner a TerminationStrategy should be used. Currently jFuzz has three available termination strategies: NeverTerminate, TimedTermination, and UptoFixedNumber. See here for a description of how to implement a TerminationStrategy.
- NeverTerminate: jFuzz will run until there are no more inputs. This is the default.
- TimedTermination: jFuzz will run until time runs out. Requires the argument jfuzz.time. The format is: hours,minutes,seconds,milliseconds.
- UpToFixedNumber: jFuzz will run a set number of times. Requires the argument jfuzz.numexec.
Timing Measurement
If the argument jFuzz.timing is set to true, as jFuzz executes it will keep track of the time several operations take. These include: Total time, JPF time, Fuzzing time, solving time, simplifying time, time creating inputs. These will be aggregated into the CSV file timeAgg.csv in the generated directory.
Coverage Measurement
If the argument jfuzz.coverage is passed a jar, as jFuzz executes it will run each input processed through EMMA to measure the aggregate coverage achieved. This will be aggregated into the CSV file coverage.csv in the generated directory. The jar passed to jfuzz.coverage should be an unmodified version of the subject program because otherwise the program will fail because fuzzPC will try to call JPF methods and fail.
Usage Examples
Here are jFuzz usage examples. These are the programs that were used in evaluating jFuzz. Please download our modified sources for jLex and SAT4J.
Simple Test
This is a simple example on how to use jFuzz. To run this example, execute the following command from inside the JPF trunk folder. Remember to escape the parentheses if you are using the command line. For convenience, you can use the simpleTest.sh script in the main jFuzz directory.java -cp ./build/jpf jfuzz.JFuzz +jpf.basedir=. +search.class=gov.nasa.jpf.search.Simulation +jfuzz.input=extensions/concolic/test/txtfiles/largepc.txt +jfuzz.time=0,3,0,0 +jfuzz.del=false +jfuzz.nextfile=jfuzz.nextfile.Oldest +jfuzz.termination=jfuzz.termination.TimedTermination +jfuzz.cache=jfuzz.cache.NameIndependentCache +jfuzz.timing=false +vm.insn_factory.class=gov.nasa.jpf.concolic.ConcolicInstructionFactory +jpf.listener=jfuzz.ConcolicListener +symbolic.method=foo(sym) +jpf.report.console.finished= jfuzz.tests.LargePC
SAT4J
SAT4J is SAT solver written in Java. The code had to be slightly modified to to run with jFuzz. You can download the modified sources. There are two instructive changes:
- In org.sat4j.Lanceur, we removed all calls to System.exit() and inserted a call to jfuzz.DebugFuzz.fuzzPC at the end of the main method.
- In org.sat4j.reader.LecteurDimacs, we made every char that was read pass through a method foo(char c). This is used to mark every character from the input file as symbolic.
When running our tests these are the arguments used:
+jpf.basedir=../javapathfinder-trunk +jfuzz.input.cp=./lib/sat4j-apache.jar:. +search.class=gov.nasa.jpf.search.Simulation +jfuzz.input=test1.dimacs +jfuzz.termination=jfuzz.termination.TimedTermination +jfuzz.time=0,60,0,0 +jfuzz.cache=jfuzz.cache.NameIndependentCache +jfuzz.nextfile=jfuzz.nextfile.Coverage +jfuzz.coverage=sat4j.jar +jfuzz.timing=true +jfuzz.del=false +jfuzz.debug=false +vm.insn_factory.class=gov.nasa.jpf.concolic.ConcolicInstructionFactory +jpf.listener=jfuzz.ConcolicListener +symbolic.method=foo(sym) +jpf.report.console.finished= org.sat4j.Lanceur
JLex
JLex is a lexical analyzer generator, written for Java, in Java. The code had to be slightly modified to to run with jFuzz. You can download the modified sources. There are two instructive changes:- In jlex.Main, we removed all calls to System.exit() and inserted a call to jfuzz.DebugFuzz.fuzzPC at the end of the main method.
- In jlex.CInput, we wrote a readLine method which passes ever character read through the symbolic method foo(char c). This is used to mark every character from the input file as symbolic.
+jpf.basedir=../javapathfinder-trunk +jfuzz.input.cp=./bin +search.class=gov.nasa.jpf.search.Simulation +jfuzz.input=simple.lex +jfuzz.nextfile=jfuzz.nextfile.Coverage +jfuzz.termination=jfuzz.termination.TimedTermination +jfuzz.time=0,60,0,0 +jfuzz.cache=jfuzz.cache.NameIndependentCache +jfuzz.coverage=jlex.jar +jfuzz.timing=true +jfuzz.del=false +jfuzz.debug=false +vm.insn_factory.class=gov.nasa.jpf.concolic.ConcolicInstructionFactory +jpf.listener=jfuzz.ConcolicListener +symbolic.method=foo(sym) +jpf.report.console.finished= JLex.Main
Developer Documentation
This section provides an overview of the architecture of jFuzz and describes the requirements for each extention point.
Architecture
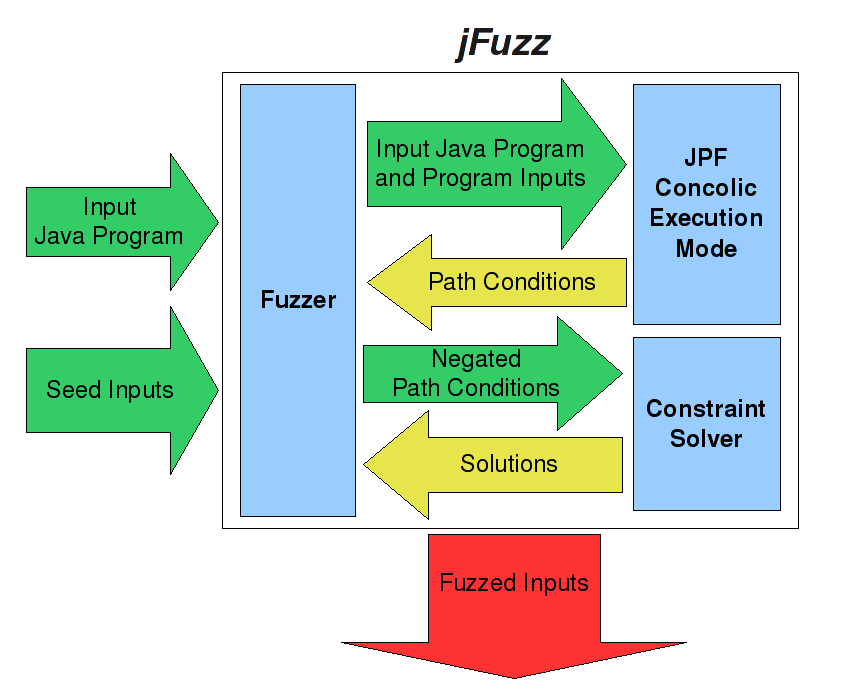
jFuzz architecture. Given the program under test and seed inputs, jFuzz generates new inputs by modifying (fuzzing) the seed inputs so that each new input executes a unique control-flow path. jFuzz is built as an extension to NASA Java PathFinder. Java PathFinder is an explicit state software model checker for Java bytecode, that also provides hooks for a variety of analysis techniques. The figure above illustrates the architecture of jFuzz.
jFuzz works in three steps:
- Concolic Execution: jFuzz executes the subject program using concolic execution in Java PathFinder on the seed input, and collects the path condition. Each byte in the seed inputs is marked symbolic.
- Constraint Solving: Once the concolic execution has completed, jFuzz systematically negates the constraints encountered on the executed path. jFuzz conjoins the corresponding path condition with the negated constraint, to obtain a new path condition query for the solver. The solution is in terms of input bytes, i.e., describes the values of the input bytes.
- Fuzzing: For each solution, jFuzz changes the corresponding input bytes of the initial seed input to obtain a new modified input for the program under test.
Extension Points
There are three areas in which jFuzz is designed to be easily extended: TerminationStrategy, NextFileStrategy, and CacheStrategy. This section describes the function and interface of each of these extension points.
CacheStrategy
CacheStrategy specifies how jFuzz caches PathConditions. Currently jFuzz has two available caching strategies: NameIndependentCache, and NoCache. See here for a description of each of these and how to use them. Every CacheStrategy must implement the CacheStrategy interface. This means implementing the following methods:- Map
- void clearCache(): Clears the cache.
- void initialize(Config config): Initialize this CacheStrategy. config contains the arguments passed to jFuzz.
NextFileStrategy
NextFileStrategy specifies how jFuzz selects the next input to process. Currently jFuzz has four available next file strategies: Coverage, Newest, Oldest, and Random. See here for a description of each of these and how to use them. Every NextFileStrategy must implement the NextFileStrategy interface. This means implementing the following methods:- File getFileFromQueue(File queueDir): Returns the next input to process. queueDir is the directory with unprocessed inputs.
- void initialize(Config config): Initialize this NextFileStrategy. config contains the arguments passed to jFuzz.
TerminationStrategy
jFuzz with automatically stop when there are no unprocessed inputs available, if you wish to stop the execution of jFuzz sooner a TerminationStrategy should be used. Currently jFuzz has three available termination strategies: NeverTerminate, TimedTermination, and UptoFixedNumber. See here for a description of each of these and how to use them. Every TerminationStrategy must implement the TerminationStrategy interface. This means implementing the following methods:- boolean isDone(): This method returns true if jFuzz should stop executing.
- String getReason(): Returns a message which indicates why execution was stopped.
- void initialize(Config config): Initialize this TerminationStrategy. Config contains the arguments passed to jFuzz.
Links
- jFuzz website
- NASA Java PathFinder website
- Symbolic JPF
- jpaul - Java Program Analysis Utilities Library
- SAT4J - a Boolean SAT solver
- JLex - a lexical analyzer generator for Java