Optimal coordination of
decentralized agents
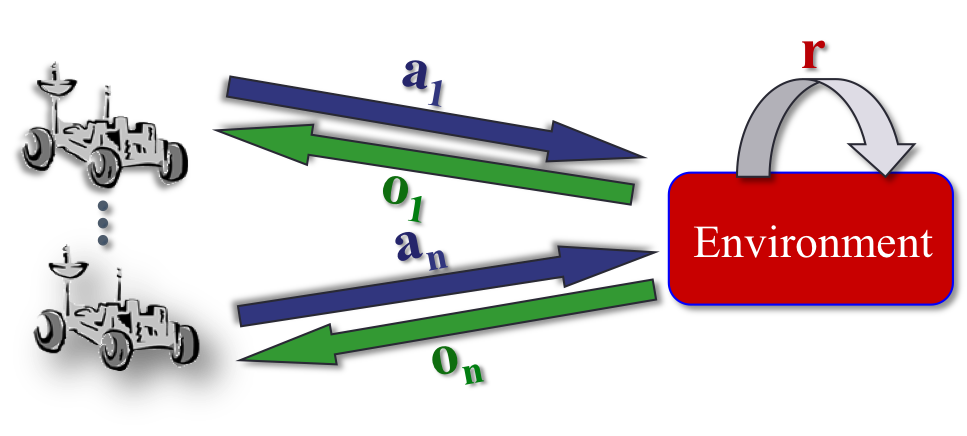
Coordination under uncertainty is difficult, even in cooperative
systems. When communication is unreliable, slow or costly, agents
must rely on local information to make decisions. These
cooperative systems can be modeled as decentralized partially
observable Markov decision processes (Dec-POMDPs). Dec-POMDPs
are very general and can represent agent teams with stochastic
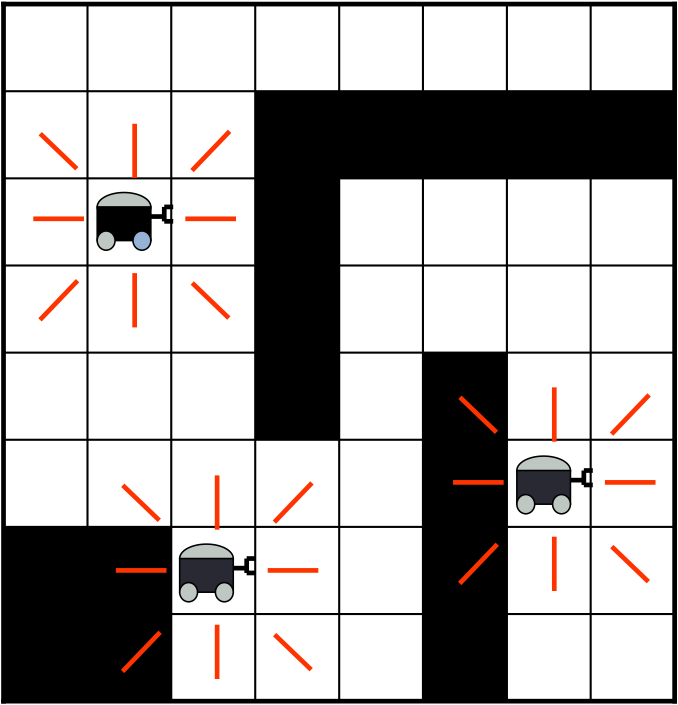
actions and partial information. One example is a vehicles
optimizing exploration while minimizing fuel and communication
usage such as Mars rovers or reconnaissance drones.
My research has made several contributions to generating optimal
and bounded-optimal Dec-POMDP solutions, including:
- The first (and only) epsilon-optimal solution method for
infinite-horizon Dec-POMDPs [JAIR
09]
- Using a centralized planning stage, but decentralized
execution to transform (finite-horizon) Dec-POMDPs into
continuous-state MDPs, allowing powerful centralized (POMDP)
methods to be used [IJCAI
13]
- An efficient dynamic programming algorithm that can
automatically take advantage of state-space structure [ICAPS
09]
- The most scalable optimal (top-down) heuristic search
technique for finite-horizon Dec-POMDPs [JAIR
13]
These algorithms represent the most scalable bounded and optimal
methods for Dec-POMDPs, showing that optimal methods can solve
large interesting problems.
|
|