IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2011
Switch to Silverlight if your browser is NOT Chrome
A Bayesian Approach to Adaptive Video Super Resolution
1Microsoft Research New England 2Brown University
Download the video frames used in our paper
Abstract |
|
| Although multi-frame super resolution has been extensively studied in past decades, super resolving real-world video sequences still remains challenging. In existing systems, either the motion models are oversimplified, or important factors such as blur kernel and noise level are assumed to be known. Such models cannot deal with the scene and imaging conditions that vary from one sequence to another. In this paper, we propose a Bayesian approach to adaptive video super resolution via simultaneously estimating underlying motion, blur kernel and noise level while reconstructing the original high-res frames. As a result, our system not only produces very promising super resolution results that outperform the state of the art, but also adapts to a variety of noise levels and blur kernels. Theoretical analysis of the relationship between blur kernel, noise level and frequencywise reconstruction rate is also provided, consistent with our experimental results. |
Introduction
Multi-frame super resolution, namely estimating the high-res frames from a low-res sequence, is one of the fundamental problems in computer vision and has been extensively studied for decades. The problem becomes particularly interesting as high-definition devices such as HDTV's dominate the market. There is a great need for converting low-res, low-quality videos into high-res, noise-free videos that can be pleasantly viewed on HDTV's.
Although a lot of progress has been made in the past 30 years, super resolving real-world video sequences still remains an open problem. Most of the previous work assumes that the underlying motion has a simple parametric form, and/or that the blur kernel and noise levels are known. But in reality, the motion of objects and cameras can be arbitrary, the video may be contaminated with noise of unknown level, and motion blur and point spread functions can lead to an unknown blur kernel.
Therefore, a practical super resolution system should simultaneously estimate optical flow [Horn 1981], noise level [Liu 2008] and blur kernel [Kundur 1996] in addition to reconstructing the high-res frames. As each of these problems has been well studied in computer vision, it is natural to combine all these components in a single framework without making oversimplified assumptions.
In this paper, we propose a Bayesian framework for adaptive video super resolution that incorporates high-res image reconstruction, optical flow, noise level and blur kernel estimation. Using a sparsity prior for the high-res image, flow fields and blur kernel, we show that super resolution computation is reduced to each component problem when other factors are known, and the MAP inference iterates between optical flow, noise estimation, blur estimation and image reconstruction. As shown in Figure 1 and later examples, our system produces promising results on challenging real-world sequences despite various noise levels and blur kernels, accurately reconstructing both major structures and fine texture details. In-depth experiments demonstrate that our system outperforms the state-of-the-art super resolution systems [VH 2010, Shan 2008, Takeda 2009] on challenging real-world sequences.
A Bayesian Model
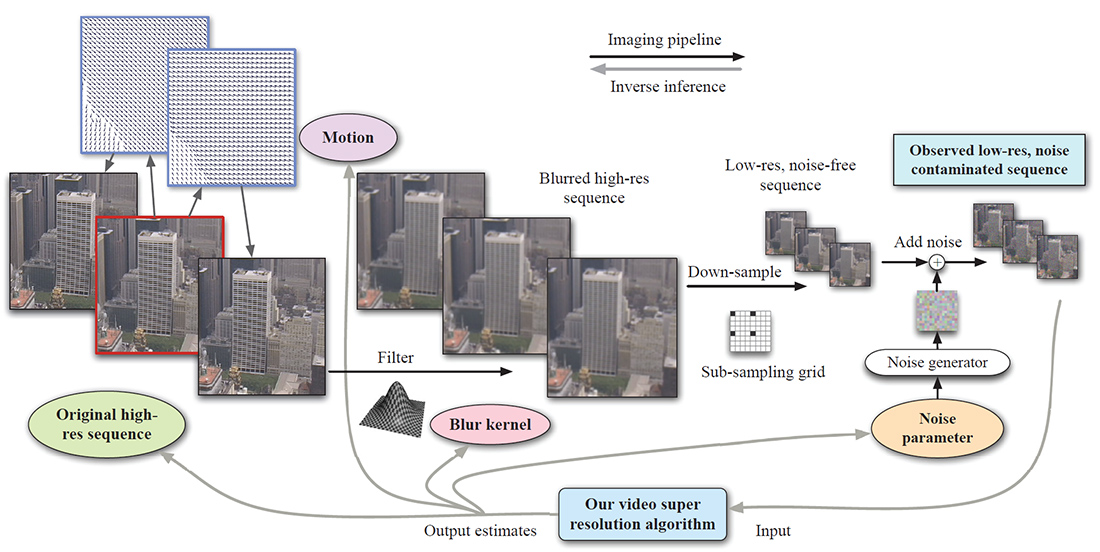
The imaging pipeline is shown in Figure 2, where the original high-res video sequence is generated by warping the high-res source frame (enclosed by a red rectangle) both forward and backward with some motion fields. The high-res sequence is then smoothed with a blur kernel, down-sampled and contaminated with noise to generate the observed sequence. Our adaptive video super resolution system not only estimates the high-res sequence, but also the underlying motion (on the lattice of original sequence), blur kernel and noise level.
|
| Figure 2. Video super resolution diagram. The original high-res video sequence is generated by warping the source frame (enclosed by a red rectangle) both forward and backward with some motion fields. The high-res sequence is then smoothed with a blur kernel, downsampled and contaminated with noise to generate the observed sequence. Our adaptive video super resolution system not only estimates the high-res sequence, but also the underlying motion (on the lattice of original sequence), blur kernel and noise level. |
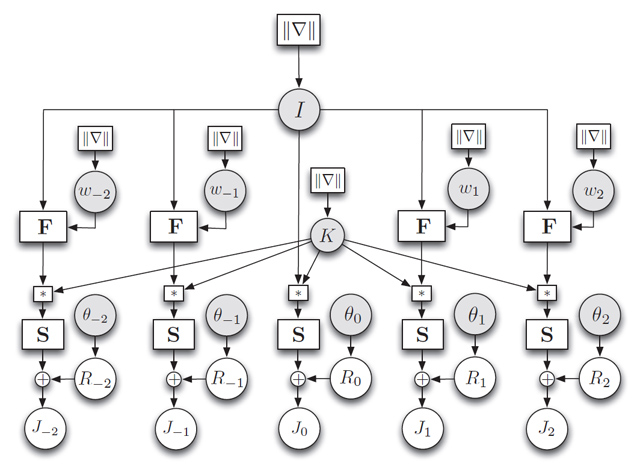
Now that we have the physical model of the imagine process, we can formulate all the unknowns as random variables, which are associated with priors and observations. Figure 2 can be translated to the graphical model in Figure 3.
|
|
Figure 3. The graphical model of video super resolution. The circular nodes are variables (vectors), whereas the
rectangular nodes are matrices (matrix multiplication). We do not put priors η,
λ, ξ, α and β on I, wi, K, and θi for succinctness. |
We use Bayesian maximum a posteriori (MAP) criterion to infer the optimum set of unknown variables
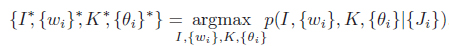
Where the posterior can be rewritten as the product of likelihood and prior
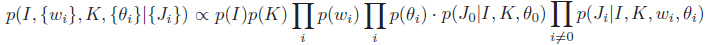
To deal with outliers, we assume an exponential distribution for the likelihood:
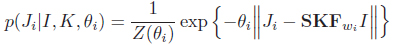
We use sparisty on derivatives to model the prior of the high-res image, flow field and blur kernel
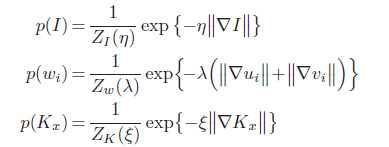
Naturally, the conjugae prior for the noise parameter θi is a Gamma distribution
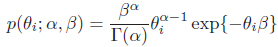
Our optimization strategy is to fix three sets of parameters and estimate the other. It is straightforward to find that we indeed itereate the following four steps:
-
Image reconstruction: infer I
-
Image reconstruction: infer {wi}
-
Image reconstruction: infer {θi}
-
Image reconstruction: infer K
It is clear that these four classical computer vision problems need to be solved simultaneously for video super resolution! The objective function has the form of L1 norm. We use iteratively reweighted least square (IRLS) [Liu 2009] to solve this convex optimization problem. The convergence procedure is shown in the following video, where the Itertion # shows the outer iteration where the four sets of variables are swept. IRLS # is the index of inner iteration where the high-res image gets optimized. Clearly, the images gets sharper as the algorithm progresses. In addition, the fact that the images gets dramatically sharper after the first outer iteration indicates that better estimates of motion, noise level and blur kernel lead to better estimate of the high-res image
| Figure 4. Convergence of our video super resolution system. You may want to play the video multiple times to see how the optimization procedure gradually sharpens the result image. |
Noise and blur
We used the benchmark sequence city in video compression society to evaluate the performance. Rich details at different scales make the city sequence ideal to observe how different frequency components get recovered. We simulated the imaging process by first smoothing every frame of the original video with a Gaussian filter with standard deviation σk. We downsample the smoothed images by a factor of 4, and add white Gaussian noise with standard deviation σn. As we vary the blur kernel σk and the noise level σn for evaluation, we initialize our blur kernel Kx, Ky with a standard normal distribution and initialize noise parameters θi using the temporal difference between frames. We use 15 forward and 15 backward adjacent frames to reconstruct a high-res image.
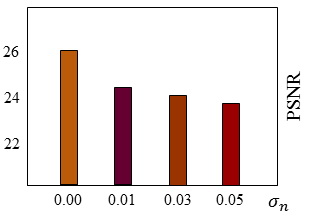
We first tested how our system performs under various noise levels. We fixed σk to be 1.6 and changed σn from small (0) to large (0.05). When σn=0, quantization is the only source of error in the image formation process. As shown in Figure 5 & 6, our system is able to produce fine details when the noise level is low (σn = 0.00 or 0.01). Our system can still recover major image structure even under very heavy noise (σn = 0.05). These results suggest that our system is robust to unknown noise. Note that the performance drops as the noise level increases is consistent with our theoretical analysis.
 |
| Figure 4. Our video super resolution system is robust to noise (click the figure to enlarge). We added synthetic additive white Gaussian noise (AWGN) to the input low-res sequence, with the noise level varying from 0.00 to 0.05 (top row, left to right). The super resolution results are shown in the bottom row. The first number in the parenthesis is PSNR score and the second is SSIM score. |
|
| Figure 5. PSNR as a function of noise level. PSNR monotonically decreases as noise level increases. |
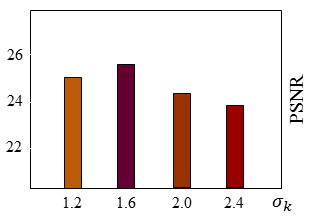
Next, we tested how well our system performs under various blur kernels. We gradually increase σk from 1.2 to 2.4 with step size 0.4 in generating the low-res input. As shown in Figure 8, the stimated blur kernels match the ground truth well. In general, fewer details are recovered as σk increase, consistent with our theoretical analysis. However, the optimal performance (in PSNR) of our system occurs for σk = 1.6 instead of 1.2. In fact, small blur kernel generates strong aliasing, a fake signal that can severely degrade motion estimation and therefore prevent reconstructing the true high-frequency details.

|
|
Figure 6. Our video super
resolution system is able to estimate the PSF (click the figure to
enlarge). As we varied the standard deviation of the blur kernel (or
PSF) σk = 1.2, 1.6, 2.0, 2.4,
our system is able to estimate the underlying PSF. Aliasing causes
performance degradation for the small blur kernel σk
=1.2 (see text for detail). Top: bicubic
up-sampling (×4); middle: output of our system; bottom: the ground truth
kernel (left) and estimated kernel (right). The first number in the
parenthesis is PSNR score and the second is SSIM score. |
|
| Figure 7. PSNR as a function of blur kernel. There is a peak of PSNR as we increase the size of blur kernel. |
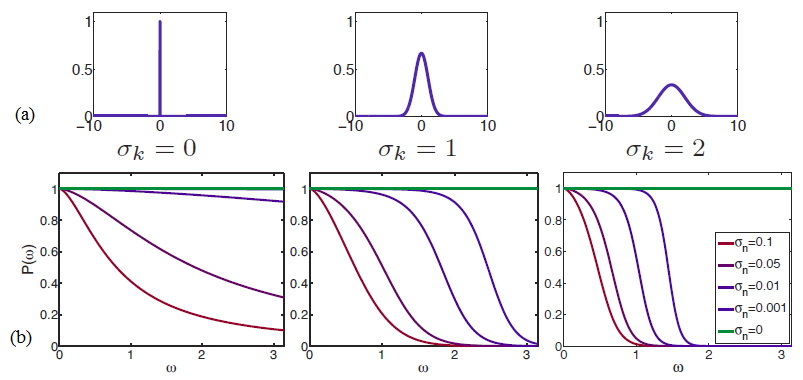
We can also can also analyze theoretical frequence response using Wiener filtering. When the scene is fixed and only camera motion is presen and controllable, super resolution probelm can be reduced to a deblurring and denoising problem. We can analyze the frequency-wise reconstruction rate using the optimum MMSE estimate -- Wiener filtering. The curves are shown in Figure 8.
|
| Figure 8. Performance of theWiener filter at different frequencies under different blur and noise conditions (1 corresponds to perfect reconstruction). Clearly, the reconstruction rate drops significantly as the noise level or blur kernel increases. |
Experimental results
We compared our method to two recent methods [Shan 2008, Takeda 2009] using the public implementations downloaded from the authors’ websites 1 and one state-of-the-art commercial software, “Video Enhancer” [VE 2010]. Since the 3DKR method [Takeda 2009] produced the best results amongst these methods, we are going to mainly compare against to their output.
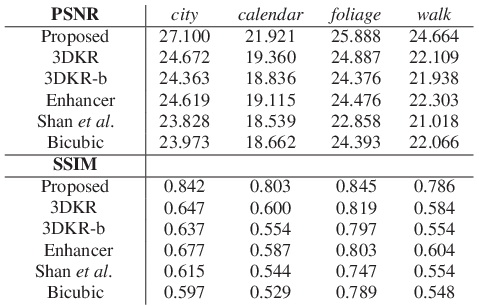
We used four real-world video sequences, city, calendar, foliage and walk for comparison. The results are listed in next tabs. Although the 3DKR method has recovered the major structures of the scene, it tends to over-smooth fine details. In contrast, our system performed consistently well across the test sequences. On the city sequence our system recovered the windows of the tall building while 3DKR only reconstructed some blurry outlines. On the calendar sequence, we can easily recognize the banner “MAREE FINE” from the output of our system, while the 3DKR method failed to recover such detail. Moreover, our system recovered the thin branches in the foliage sequence and revealed some facial features for the man in the walk sequence. The 3DKR method, however, oversmoothed these details and produced visually less appealing results.

|
| Figure 9. Comparison (close-ups). From top to bottom: city, calendar, foliage and walk. |
Tables 1 summarizes the PSNR and SSIM scores for these methods on the video frames in Figure 9. Our system consistently outperforms other methods across all the test sequences.
|
| Table 1.PSNR and SSIM scores. 3DKR-b is the output of the 3DKR method before postprocessing. |
City
There is no magic in video super resolution. In our graphical model, we assume that the motion is smooth, and that the pixel values are constant along the motion trajectories. So our super resolution approach works for the videos where these assumptions hold, and does not work so well when these assumptions fail. The city sequence is a good example where motion is smooth (only camera motion is present), and our system is able to perform well except for occlusion regions.
Below are close-up views of the video sequence.
Calendar
The Calendar sequence is perfect for our algorithm: rigid motion without occlusion! Therefore, our system performs very nicely on this video.
Below are close-up views of the sequence.
Foliage
Foliage is a challenge sequence. The motion of the leaves are not rigid at all. In addition, we may observe shadow/shading motion disjoint from the object motion. These all break the assumptions for the underlying motion in our model. Therefore, we observe artifacts especially in the areas where the assumptions are violated.
Our system is able to produce more details for the background, static, white car than for the foreground, moving, black car. The black car is occluded in many frames, therefore, there is not much information to borrow from adjacent frames.
On the tree trunch on the left, you may observe the shadow motion that is disjoint with the tree motion. This caused artifacts because the brightness constancy assumption in the motion estimation module is violated.
&
Our system works well for areas where the underlying motion is smooth.
Walk
Walk is a challenging sequence as we observe motion blur, which was not modeled. Motion blur was modeled in some previsou work [Bascle 1996], but considering motion blur would significantly increase computational complexity. But motion blur does occur when there are fast moving objects (compared to frame rate) in the video sequence. We leave it as our future work to handle motion blur.
Below you can observe three groups: static background, walking people and flying pigeon, where the super resolution results degraded from the static background to the flying pigeon. The artificially strengthened boundary of the pigeon comes from the L1 smoothness prior of the high-res frame.
Nonrigid motion can be challenging for supre resolution. Nonrigid motion makes it difficult to borrow information from adjacent frames: a pixel may just disappear due to self-occlusion, and brightness constancy assumption is often violated. We leave it as our future work to incorporate long-range motion estimation to substitute current two-frane motion estimation.
References
| [Bascle 1996] | B. Bascle, A. Blake, and A. Zisserman. Motion deblurring and superresolution from an image sequence. European Conference on Computer Vision (ECCV), 1996 |
| [VE 2010] | http://www.infognition.com/videoenhancer/, Sep. 2010. Version 1.9.5. |
| [Horn 1981] | B. Horn and B. Schunck. Determining optical flow. Artificial Intelligence, 16:185--203, Aug. 1981. |
| [Liu 2008] | C. Liu, R. Szeliski, S. B. Kang, C. L. Zitnick, andW. T. Freeman. Automatic estimation and removal of noise from a single image. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 30(2):299--314, 2008 [pdf]. |
| [Liu 2009] | C. Liu. Beyond pixels: exploring new representations and applications for motion analysis. Doctoral Thesis. Massachusetts Institute of Technology. May 2009. [pdf] |
| [Kundur 1996] | D. Kundur and D. Hatzinakos. Blind image deconvolution. Signal Proc. Magazine, IEEE, 13(3):43--64, 1996. |
| [Shan 2008] | Q. Shan, Z. Li, J. Jia, and C.-K. Tang. Fast image/video upsampling. ACM TOG, 27(5):153, 2008 |
| [Takeda 2009] | H. Takeda, P. Milanfar, M. Protter, and M. Elad. Super-resolution without explicit subpixel motion estimation. IEEE Transactions on Image Processing (TIP), 18(9):1958--1975, Sep. 2009. |
Last update: Aug, 2011