SIFT flow: dense correspondence across difference scenes
Ce Liu1 Jenny Yuen1 Antonio Torralba1 Josef Sivic2 William T. Freeman1,3
1CSAIL, MIT 2INRIA/Ecole Normale Supérieure 3Adobe Systems
{celiu,jenny,torralba,billf}@csail.mit.edu, josef@di.ens.fr
Presented at ECCV 2008 [pdf]
Abstract
While image registration has been studied in different areas of computer vision, aligning images depicting different scenes remains a challenging problem, closer to recognition than to image matching. Analogous to optical flow, where an image is aligned to its temporally adjacent frame, we propose SIFT flow, a method to align an image to its neighbors in a large image collection consisting of a variety of scenes. For a query image, histogram intersection on a bag-of-visual-words representation is used to find the set of nearest neighbors in the database. The SIFT flow algorithm then consists of matching densely sampled SIFT features between the two images, while preserving spatial discontinuities. The use of SIFT features allows robust matching across different scene/object appearances and the discontinuity-preserving spatial model allows matching of objects located at different parts of the scene. Experiments show that the proposed approach is able to robustly align complicated scenes with large spatial distortions. We collect a large database of videos and apply the SIFT flow algorithm to two applications: (i) motion field prediction from a single static image and (ii) motion synthesis via transfer of moving objects.
Image alignment at scene level: scene alignment
There are several possible levels for image alignment. We are interested in image alignment at the scene level: two images coming from a similar scene category, but from different instances. Ideally, we want the scene alignment to be performed at the semantic level, i.e. objects that belong to the same category in correspondence. But object recognition is still far from being reliable for such task. Our approach is to match salient image structures, and we hope that semantically meaningful correspondences can be established through matching local image structures. Nevertheless, scene alignment is a very challening problem. Can we align the following four examples using one algorithm?
 |
 |
 |
 |
|
Changing perspective, occlusions |
Multiple objects; no global transform |
|||
 |
 |
 |
 |
|
Background clutter |
Intra-class variation |
|||
Can we develop an algorithm to align all these images? |
||||
The SIFT flow algorithm
SIFT descriptor [1] is well known for capturing invariant local image structural information. We compute dense SIFT descriptors for every pixel. For a [w x h] image, we get a 3D SIFT image of dimension [w x h x 128]. To visualize SIFT images, we project the 128D SIFT vector onto the 3D RGB space, by mapping the top three principal components of SIFT to the principal components of RGB, as shown below. Notice that this projection is for visualization only. In the SIFT flow algorithm, we use the complte 128D representation of SIFT for matching.
 |
|
||||
The principal components of SIFT are mapped to the principal components of RGB for visualization |
Using the visualization diagram on the left, we compute the SIFT image of an RGB image in (a), and visualize it in (b). The projection is for visualization only. |


We formulate SIFT flow the same as optical flow with the exception of matching SIFT descriptors instead of RGB values. Therefore, the objective function of SIFT flow is very similar to that of optical flow:
In the above equation, p is the index of pixels, w(p)=(u(p),v(p)) is the flow vector for every pixel. s1 and s2 denotes the SIFT image for two frames, respectively. Notice that in the above objective function, truncated L1 norms are used for matching to account for outliners, and also for the regularization terms to encourage sharp discontuinity. We also added an extra term to favor small displacement.
 |
One big difference between optical flow and SIFT flow is that the search window size for SIFT flow is much larger since an object can move drastically from one image to another in scene alignment. This constrains us in chosing optimization algorithms. |
As illustrated above, the size of search window for SIFT flow is much larger than that for optical flow since an object can move significant from one image to another in scene alignment. So we use max-product loop belief propagation algorithm to optmize the energy. The dual-plane representation [2] is used to decouple the smoothness constraint for the x and y components of the flow (this can be seen from the objective function) to reduce the complexity from O(L4) to O(L2), where L is the number of states. We use the acceleration techniques proposed in [3] such as distance transform function, bipartite update and a mult-grid impelementation to significantly speed up the message passing process. It takes about 50 seconds for matching 145x105 images with 80x80 neighborhood on a 2.83GHZ quad-core machine.
Meaningful matching
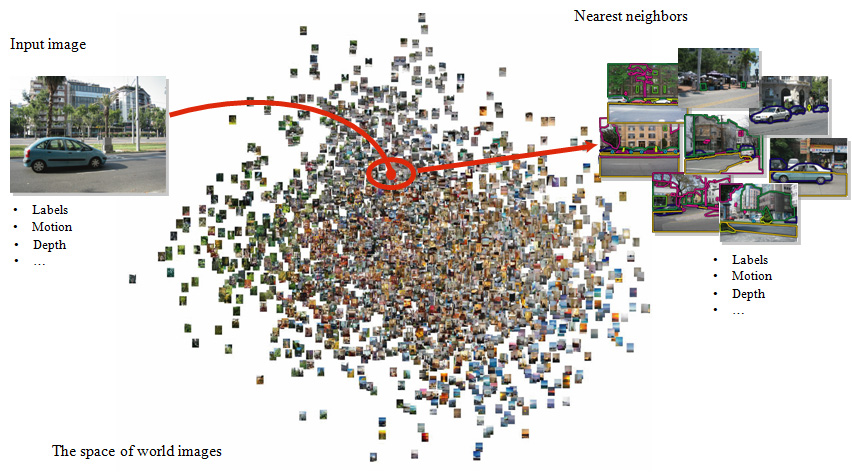
In theory, we can apply optical flow to two arbitrary images to compute flow, but we wouldn't get a meaningful flow field. In fact, there is another underlying assumption for optical flow: there is a dense sampling in time and the two adjacent frames are visually close. Similarly, we need to find neighboring frames for SIFT flow for a meaningful scene alignment. What if we had dense samplings for all world images so that for any given image we could find its nearest neighbor in this image space? Because of the dense sampling, the SIFT flow between this image and its neighbors should give us meaningful correspondences. This is the analogy we derive for SIFT flow from optical flow:
Dense sampling in time : optical flow :: dense sampling in world images : SIFT flow
Image retrieval results
We collected 731 videos consisting of 102,206 frames as our database for the experiments. The videos are mostly of street scenes. If we apply SIFT flow to match more than 100,000 images in our database, it would take more than two months to retrieve one image. In fact, if two images have very different distributions of SIFT descriptors, for instance, one has dorminant horizontal structures and the other has dorminant vertical structures, there is no need to apply SIFT flow. We use a simple algorithm [4] to find a set of nearest neighbors that are close to the query. Then we apply SIFT flow to find correspondence between the query and each of the nearest neighbors. Below are the results of the correspondence between the query and the best match from the whole database.
|
||||||||||||||
|
In this example, SIFT flow reshuffles the windows in the best match image to match the query. |
||||||||||||||
|
||||||||||||||
|
SIFT flow repositions and rescales the sailboat in the best match image to match the query. Notice that not only the foreground objects, but also the background pixels are aligned in SIFT flow. |
||||||||||||||
|
||||||||||||||
|
For this example, SIFT flow hallucinated a third window from the taxi to match the input SUV. Again, not only are the foreground objects aligned, but also the background objects. It shows the power of dense correspondence. |
||||||||||||||
|
||||||||||||||
|
SIFT flow can also deal with multiple objects. In this example, SIFT flow reproduced and rearranged the sailboats in the best match to align to the query. |
||||||||||||||
|
||||||||||||||
|
For these two example where the correspondence is not obvious to humans, SIFT flow is able to find a reasonable correspondence that aligns these two very different houses. |
||||||||||||||
|
||||||||||||||
|
Since there is only one sequence of clock in our database, SIFT flow can only find an elevator door as the best match to the query, by breaking the rectangular structure and reforming it to form a circl. |


































Applications: Large database-driven approach for image processing and understanding
A large, annotated database and a dense correspondence algorithm result in a new framework for image processing and understanding: for a query image, we can search its nearest neighbors, and then transfer the metadata information from the nearest neighbors to the query. This example-based approach has been demonstrated in object recognition via label transfer [5]. Here we show some example applications.
Motion Hallucination
The goal is, given a single static image, to predict what motions are plausible in the image. This is similar to the recognition problem, but instead of assigning a
label to each pixel, we want to assign possible motions.
Using the SIFT-based histogram matching, we can retrieve very similar video frames that are roughly spatially aligned. For common events such as cars moving forward on a street, the motion prediction can be quite accurate given enough samples in the database. We further refine the coarse motion prediction using the SIFT flow from the matched video frame to the query image. We use this correspondence to warp the temporally estimated motion of the retrieved video frame and hallucinate a motion field.
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
Original Image |
Database match |
Motion of database match |
Warped and transferred motion |
Ground truth of original |
While there are many improbable flow fields (e.g. a car moving upwards), each image can have multiple plausible motions : a car or a boat can move
forward, in reverse, turn, or remain static:
 |
A still query image with its temporally estimated motion field (in the green frame) and multiple motion fields predicted by
motion transfer from a large video database. |
Motion Synthesis Via Moving Objects Transfer
Given a still image, our system retrieves a video that matches the scene the best. Since the scenes are already aligned, the moving objects in the video already have the correct size, orientation, and lighting to fit in the still image. The third column shows synthesized video created by transferring the moving pixels from the video to the still image. Click on the thumbnails to show the videos.
 |
 |
 |
 |
 |
 |
 |
 |
 |
Stil Query Image
|
Database Video Retrieval
|
Composite Video
|