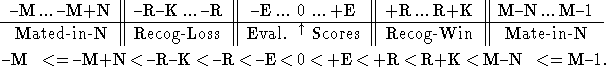 |
The basic idea of interior-node recognition is really trivial yet extremely powerful. It simply says: stop the search immediately and cut the whole subtree when reaching a position with a known game-theoretical value (draw, loss, or win). At a first glance, this theoretically sound cutoff scheme looks easy to implement. But the practical consequences of integrating it into a game-playing alpha-beta searcher are highly complex.
In case of losses and wins, for instance, you cannot just return the
same loss/win values as search results for all lost/won positions.
Otherwise, the game-playing program will not make any progress in these
positions because there is nothing to distinguish between them.
Consequently, appropriate scoring functions need to be supplied for all
recognized positions. While the recognizer scores must not interfere
with mate and static evaluation scores, they should still provide a good
estimate of the recognized game-theoretical value. Slate's concept of
interior-node score bounds [190] solves this problem
by reserving two normally unused ranges of values for recognizer scores.
Figure 1.2 shows how neatly the new ranges fit
directly in-between the usual mate and static evaluation scores.
During the 8th WCCC in 1995, DARKTHOUGHT used an equivalent scoring scheme for its interior-node recognizers which included access functions to Thompson's 5-piece endgame databases [205]. Such databases combine neatly with interior-node recognition because they contain game-theoretical values for elementary positions. Thompson's endgame databases employ a distance-to-conversion rather than a distance-to-mate metric and thus do not return exact mate scores. Therefore, the recognizers converted the raw database results into a special recognizer score accounting among others for the material balance of the position.
We abandoned the scheme of interior-node score bounds in 1996 when it became clear that disjoint scoring ranges for recognizers and the static evaluation tend to introduce frequent scoring inconsistencies during iteratively deepened searches of high depths. The inconsistencies are caused by incomplete recognizer coverage of positions that represent subgames of other positions for which recognizers exist. Pawn (under-) promotions often lead to such subgames, especially if any recognized positions contain more than one Pawn per side. This kind of recognizer incompleteness is hard to avoid in practice unless the implementation restricts recognizers to solely trivial cases. Hence, in our opinion Slate's theoretically sound scheme of interior-node score bounds with disjoint ranges for recognizer results and static evaluation scores carries only little practical value for modern high-speed chess programs.
Other difficult problems caused by interior-node recognizers relate to their efficient implementation. First and foremost, the efficient selection of recognizers proves to be a challenging task. The problem is to decide at each node in the search tree whether the current position lends itself to recognition at all and, if so, how to select the appropriate recognizer. Please note as an important constraint that the recognizer selection constitutes just a tiny fraction of the whole work done at each node with an overall frequency of several hundred thousand times per second. Further efficiency problems and general conceptual complications arise during the algorithmic encoding of the underlying chess knowledge into the final recognizer functions.