2.0 Notation
When servicing an access to a global variable, there are three types of nodes which may be involved; local node, home node, and remote node. The relationship between these nodes is pictured in Figure 1 below. The local node is the node on which the user program has requested access to the variable. The home node is the node which owns the data; the local node may send a request for the data to the home node. A remote node is one which has copies of the variable which the local node is requesting access to. The home node may send various requests to one or more remote nodes in the process of servicing a request from the local node. Note that although these nodes are separated logically, it is possible for a node to serve more than one role in a given transaction.
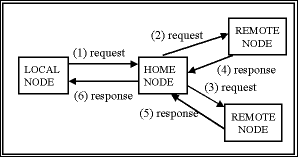
Figure 1: Nodes Involved in a Shared Memory Transaction
Split-C provides a two dimensional shared address space constructed from the
local memory of each processor. A global address consists of a
processor number and a local address. The local address part of
the global address is the virtual memory address of the variable, as
seen by the owning processor. For example, a global address of
8:0x0012 points to local memory location 0x0012 on processor 8.
To implement caching, we divide the address space into blocks. The
size of the blocks (block size) is a constant which is set when building the
SWCC-Split-C library. It would be possible to allow the user to
define the block size when compiling a program, but this would impact
the performance of the library functions since the block size would not
be a constant when building the SWCC-Split-C library.
Coherence is maintained at the block level. When the user program
accesses a global variable, the lower bits of the address are dropped
to determine the block address. All addresses associated
with the directory structure and coherence protocols are block addresses.
To maintain coherence in the software caches, we employ a directory
structure to manage the state of each shared block. Each cache block has
a home node, which is the processor that is responsible for servicing
requests for that block. The processor number of a global address gives
the home node for the block containing that global address.
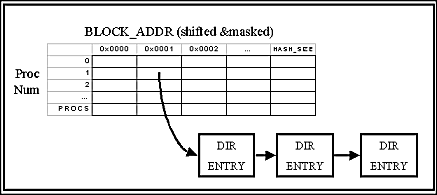
The directory structure consists of a directory hash
table of pointers to directory entries, as shown in Figure 2
below. The hash table is a two dimensional
array indexed by processor number and the lower bits of block address.
A lookup consists of finding the directory entry pointed to by the
hash table and checking that the full block address matches that entry.
If not, the correct entry is found by following a linked list of
directory entries starting with the one pointed to by the hash table.
The hash table has one row per processor, but the number of block addr
bits used to index into the table is chosen when building the
SWCC-Split-C library. This could also be chosen by the programmer,
but isn't for the same reason that block size is defined when building
the library.
Figure 2: Directory Hash Table Structure
Each directory entry consists of:
The possible values for the state of a block are:
A directory entry is created for every shared block which a
program accesses. Also, the home node creates a
directory entry for a block when it is accessed by another node.
Unlike many hardware or hardware/software directory
schemes [1,5,9], our implementation maintains directory entries for both
remote and local data; this is because we have no hardware or
operating system support for detecting access violations. The only
difference between a directory entry for a local block and one
for a remote block is that the user vector is maintained only
for local blocks.
When a directory entry is created on the home node, the data is copied from
local memory into the directory entry data field. After this, all accesses
to global variables in that directory entry must use the directory entry and not
the home node's local memory to maintain coherence. Once a directory entry
is created the data is never written back to the local memory of the
home node. This is to ensure that private (non-global) data of the
home node which may happen to reside in the directory entry is not
corrupted. An alternative could be to use the local memory of the
home node instead of making a copy in the directory entry and also maintain
a byte mask to track which bytes in the directory entry are actually global
[8]. Another alternative could be to partition the address space
into private and shared sections [2,10]; in this case there is no need
to make a copy of the data in the directory entry or to keep track of the
byte mask.
Previous implementations of software cache coherence have found that
the overhead of access control checks can be extremely important, and
must be optimized for an access hit[10,11]. In our implementation
we try to minimize the overhead for checks which result in a hit.
A standard software cache hit consists of these steps:
In the standard Split-C implementation, accesses to global variables
for which the local node is also the home node require very little
overhead; after a simple check, the memory access can proceed. We
are able to optimize for a subclass of these transactions. It may be
the case that although a region of memory is declared global, the
home node is actually the only node which ever accesses the memory.
This could occur for example in the data structures associated with an
"owner-computes" arrangement, in which each processor performs
computations on the portion of the global data which it
owns, and communicates with other processors only as necessary. If
there is a separate result data structure, or if only a small portion
of each processor's data is actually shared with other processors, it
is very likely that the associated software cache blocks will only be
accessed by the home node. Furthermore, Owner-computes parallel programming
is especially common in Split-C programs due to the semantics of the
language [3,4].
The coherence is maintained using a three-state invalidate
protocol. The simplified state diagram is given below. The state
diagram has been divided into local node, home node, and
remote node, although it is important to realize that a single
node may serve more than one role in a given transaction. Some
details involving NACK's and retries, and non-FIFO network order are
not shown in the diagrams.
Coherency is maintained using the directory and messages. When the
user program running on a node attempts to read or write a global
variable, the local node first checks if the corresponding directory entry
is in an appropriate state to complete the transaction. If not, a
request is sent to the home node. The home node does the necessary
work to preserve coherency; for example it may need to send invalidate
or flush requests to remote nodes. Once the home node finishes the
necessary protocol transactions, the block is returned to the
local node.
Our messages are implemented using Active Messages[7]. With Active
Messages (AM), a node issues an AM call to a request handler function on a
remote node which in turn processes the request and issues an AM call to a
reply handler function on the requesting processor. However, in the
interest of simplicity and time, we did not follow the semantics of AM
exactly. Currently, we issue more AM requests from within request and
reply handlers. The specification of AM says that in order to insure
that the system is deadlock free, this should not be done. We did not
experience any known problems with our method, but for a production system,
more care would have to be taken to avoid deadlock.
In preserving the coherence and consistency model of Split-C, we take
an approach similar to the SGI Origin2000 system. The serialization
requirement for coherence is provided by ensuring that all accesses to
global variables go through the home node. Additionally, the
home node uses busy states to ensure that the requests are processed
in the order in which it accepts them. If it receives an access request
for a block which is still being processed, the home node sends a NACK
and the requesting node must retry the request. Write completion is
guaranteed because the local node waits for the response from the
home node before it completes the request and returns control to the
user program. Write atomicity is ensured because an
invalidation-based protocol is used in which the home node doesn't
reply to the local node until all invalidation acknowledgments have
been received from remote nodes.
Split-C also allows the programmer to use a more relaxed consistency
model via the "split-phase" transactions "get" and "put" which are the
asynchronous analogies to "read" and "write". For these accesses, control
returns to the programmer after the request has been issued, and
completion isn't guaranteed until the user program issues an explicit
synchronization command. Our implementation supports this model by
returning to the user program after a request has been sent to the
home node, without waiting for the response. In this case, memory
consistency is only guaranteed at the explicit synchronization points.
Due to Split-C's split-phase transactions, it is possible for a node
to attempt to access a block while a previous request is still
outstanding for that block. One approach to dealing with this
situation is to keep track of pending transactions to avoid sending
a redundant request to the home node [10]. In the interest of
simplicity, we don't do this, and instead always send a request to the
home node. Usually in this case the home node will be in a busy state
servicing the previous request, and will NACK the second request for
the block. An optimization which we perform in this scenario is that
when the local node receives the NACK, it re-checks the state of the
directory entry to determine if it already magically has the block in the
desired state (due to completion of the previous request). If so, it
completes the memory transaction instead of sending a retry request to
the home node.
Active Message handlers execute atomically with respect to the user
program, but there are still possible race conditions.
While a SWCC-Split-C library function is handling a request from the
user program it is possible that it will be interrupted by an Active
Message. This can lead to a race condition if the library function is
handling a write request from the user program and it determines that
the state of the directory entry is modified, but before it can update the
data, an Active Message handler is invoked which changes the state of
the directory entry. In order to avoid this situation, the SWCC-Split-C
library function which handles write requests from the user program
sets a write lock flag to be the block address of the global variable it will
modify before it checks the state of the entry. Now, if an AM handler
will change the state of a directory entry it first checks if the write lock flag
matches the block address of the directory entry it will change. If so, it
aborts the transaction by sending a NACK to the requesting node which
will then have to retry the request.
The NOW doesn't guarantee that messages are delivered in FIFO order.
This can lead to anomalous situations in which a node receives a
request for a directory entry which doesn't make sense based on the state of
the entry. For example, if the home node issues a write response to
a node followed by a flush request, the node may receive the
flush request first, and it won't have the directory
entry in the modified state. In such situations, the
anomaly is detected, and the node responds with a NACK so that the
request will be retried.
In the situations where the local node must send a request for a block
to the home node, it is possible to optimize the transaction if the
local node happens to also be the home node. We don't optimize for
this situation, and the node will just send a message to itself.
This makes the protocol much simpler since an access by the home node
is handled in the same way as an access by any other node.
Split-C provides a family of bulk memory access functions for
efficiency. The standard Split-C implementation divides these bulk
transactions up into medium-sized Active Messages (8192 bytes in the
AM implementation we are using). In our SWCC implementation, we
divide these bulk transactions up into directory block size transactions in the
interest of simplicity. This design puts us at a disadvantage if
block size is small compared to the medium-sized AM.
Split-C provides a special "store" operation which is an asynchronous
write; the difference between a store and a put is that the requesting
node isn't notified of the completion of a store operation. We take
the semantics of store to mean that the home node will access the
variable next, and should obtain the directory entry in a modified state,
rather than the local node as with a write or a put. Thus, to handle
a store, the local node issues a request to the home node which
essentially tells the home node to write the data contained in the
message.
Split-C provides the ability to convert freely between local and
global pointers. Local pointers simply access memory with a load or
store, while global pointers invoke the library functions. This
functionality is used when the programmer knows that a global variable
lives on a certain processor, and wishes to access it without the
overhead of a library call.
Consider the code fragment below, executed on processor 3:
First processor 3 will find the directory entry via its directory hash table. If
it doesn't find the directory entry it creates a new one and sets the state
to invalid.
When processor 4 receives the write request, it finds the
directory entry in its directory hash table, and checks the state.
When processor 3 receives the response from processor 4, it updates
the directory entry with the data sent by processor 4, then writes the data
from the user program's write request to the directory entry, changes the
state of the directory entry to modified, and returns to the user program.
Consider the code fragment below, executed on processor 3:
First processor 3 will find the directory entry via its directory hash table. If
it doesn't find the directory entry it creates a new one and sets the state
to invalid.
When processor 4 receives the read request, it finds the
directory entry in its directory hash table, and checks the state.
When processor 3 receives the response from processor 4, it updates
the directory entry with the data sent by processor 4, then reads the data
which was requested by the user program, changes the state of the
directory entry to shared, and returns to the user program.
2.1 Address Blocks
2.2 Directory Structure
The block is not cached at this node. The data is not current.
One or more processors has a read-only copy of the block. The
data is current and can be read from (but not written).
The processor has exclusive access to the
block. The data is current and can be read or written.
The user vector indicates which node has exclusive access to
the block
(this may or may not be the home node).
The processor is the home node, and there is currently an
outstanding read request.
The processor is the home node, and there is currently an
outstanding write request.
Note that it is possible to discard a directory entry which is in the shared
or invalid state if the node is not the home node. We have a flag
which determines whether or not to discard directory entries as they become
invalidated, but in our current implementation we do not discard the
entries.
2.3 Optimizations to Lookup
In order to optimize for this case, we realize that it is a waste of
time and space to create and access directory entries for blocks which
are only used by the home node. To avoid this, we initialize all of
the home node's entries in
the directory hash table to NULL. Then, an access to a
global variable which is owned by the requesting node and has not been
accessed by any other node consists of these steps:
Note that as soon as a memory block is accessed by another processor,
the pointer in the directory hash table will no longer be NULL, and
all accesses to global variables in that block must go to the
directory entry even if the local node is the home node. A disadvantage of
this optimization is that extra checks are performed when the data is
local but the block has been accessed by another processor.
2.4 Protocols
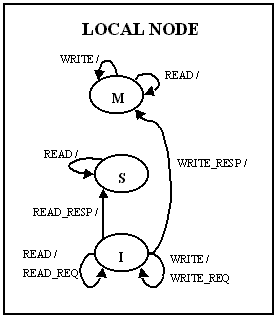
Figure 3: Local node State Transition Diagram
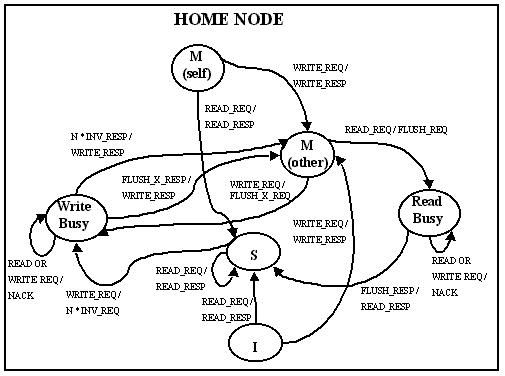
Figure 4: Home node State Transition Diagram
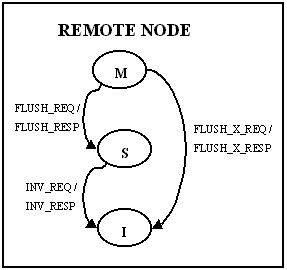
Figure 5: Remote node State Transition Diagram
2.5 Other Design Points
We must restrict the use of conversions from global to local pointers. The
local memory is in general not consistent with the data in a directory
entry. In certain cases, it may be ok to use local pointers, for
example if the programmer is sure that a directory entry has not been
created for the block in question, but great care must be taken in
doing this.
2.6 Examples
2.6.1 Example Write
remote_ptr = toglobal(4, ADDR);
*remote_ptr = 5;
This will execute a write to location ADDR on processor 4.
In this case, processor 3 is the local node and processor 4 is the home node.
Next processor 3 sets the write lock flag to ADDR as described above, and then it
checks the state of the entry.
2.6.2 Example Read
remote_ptr = toglobal(4, ADDR);
local_var = *remote_ptr;
This will execute a read of location ADDR on processor 4.
In this case, processor 3 is the local node and processor 4 is the home node.
Next processor 3 checks the state of the entry.
[Prev]
[Next]
[Index]