We thus arrive at the organizational back of the bus, the chapter containing the guidelines no one else would have. We begin with two Items on C++ software development that describe how to design systems that accommodate change. One of the strengths of the object-oriented approach to systems building is its support for change, and these Items describe specific steps you can take to fortify your software against the slings and arrows of a world that refuses to stand
We then examine how to combine C and C++ in the same program. This necessarily leads to consideration of extralinguistic issues, but C++ exists in the real world, so sometimes we must confront such
Finally, I summarize changes to the
Item 32: Program in the future tense.
As software developers, we may not know much, but we do know that things will change. We don't necessarily know what will change, how the changes will be brought about, when the changes will occur, or why they will take place, but we do know this: things will
Good software adapts well to change. It accommodates new features, it ports to new platforms, it adjusts to new demands, it handles new inputs. Software this flexible, this robust, and this reliable does not come about by accident. It is designed and implemented by programmers who conform to the constraints of today while keeping in mind the probable needs of tomorrow. This kind of software — software that accepts change gracefully — is written by people who program in the future tense.
To program in the future tense is to accept that things will change and to be prepared for it. It is to recognize that new functions will be added to libraries, that new overloadings will occur, and to watch for the potentially ambiguous function calls that might result (see Item E26). It is to acknowledge that new classes will be added to hierarchies, that present-day derived classes may be tomorrow's base classes, and to prepare for that possibility. It is to accept that new applications will be written, that functions will be called in new contexts, and to write those functions so they continue to perform correctly. It is to remember that the programmers charged with software maintenance are typically not the code's original developers, hence to design and implement in a fashion that facilitates comprehension, modification, and enhancement by
One way to do this is to express design constraints in C++ instead of (or in addition to) comments or other documentation. For example, if a class is designed to never have derived classes, don't just put a comment in the header file above the class, use C++ to prevent derivation; Item 26 shows you how. If a class requires that all instances be on the heap, don't just tell clients that, enforce the restriction by applying the approach of Item 27. If copying and assignment make no sense for a class, prevent those operations by declaring the copy constructor and the assignment operator private (see Item E27). C++ offers great power, flexibility, and expressiveness. Use these characteristics of the language to enforce the design decisions in your
Given that things will change, write classes that can withstand the rough-and-tumble world of software evolution. Avoid "demand-paged" virtual functions, whereby you make no functions virtual unless somebody comes along and demands that you do it. Instead, determine the meaning of a function and whether it makes sense to let it be redefined in derived classes. If it does, declare it virtual, even if nobody redefines it right away. If it doesn't, declare it nonvirtual, and don't change it later just because it would be convenient for someone; make sure the change makes sense in the context of the entire class and the abstraction it represents (see Item E36).
Handle assignment and copy construction in every class, even if "nobody ever does those things." Just because they don't do them now doesn't mean they won't do them in the future (see Item E18). If these functions are difficult to implement, declare them private (see Item E27). That way no one will inadvertently call compiler-generated functions that do the wrong thing (as often happens with default assignment operators and copy constructors — see Item E11).
Adhere to the principle of least astonishment: strive to provide classes whose operators and functions have a natural syntax and an intuitive semantics. Preserve consistency with the behavior of the built-in types: when in doubt, do as the ints
Recognize that anything somebody can do, they will do. They'll throw exceptions, they'll assign objects to themselves, they'll use objects before giving them values, they'll give objects values and never use them, they'll give them huge values, they'll give them tiny values, they'll give them null values. In general, if it will compile, somebody will do it. As a result, make your classes easy to use correctly and hard to use incorrectly. Accept that clients will make mistakes, and design your classes so you can prevent, detect, or correct such errors (see, for example, Item 33 and Item E46).
Strive for portable code. It's not much harder to write portable programs than to write unportable ones, and only rarely will the difference in performance be significant enough to justify unportable constructs (see Item 16). Even programs designed for custom hardware often end up being ported, because stock hardware generally achieves an equivalent level of performance within a few years. Writing portable code allows you to switch platforms easily, to enlarge your client base, and to brag about supporting open systems. It also makes it easier to recover if you bet wrong in the operating system
Design your code so that when changes are necessary, the impact is localized. Encapsulate as much as you can; make implementation details private (e.g., Item E20). Where applicable, use unnamed namespaces or file-static objects and functions (see Item 31). Try to avoid designs that lead to virtual base classes, because such classes must be initialized by every class derived from them — even those derived indirectly (see Item 4 and Item E43). Avoid RTTI-based designs that make use of cascading if-then-else statements (see Item 31 again, then see Item E39 for good measure). Every time the class hierarchy changes, each set of statements must be updated, and if you forget one, you'll receive no warning from your
These are well known and oft-repeated exhortations, but most programmers are still stuck in the present tense. As are many authors, unfortunately. Consider this advice by a well-regarded C++
You need a virtual destructor whenever someone deletes aB*that actually points to aD.
Here B is a base class and D is a derived class. In other words, this author suggests that if your program looks like this, you don't need a virtual destructor in B:
class B { ... }; // no virtual dtor needed
class D: public B { ... };
B *pb = new D;
However, the situation changes if you add this
delete pb; // NOW you need the virtual
// destructor in B
The implication is that a minor change to client code — the addition of a delete statement — can result in the need to change the class definition for B. When that happens, all B's clients must recompile. Following this author's advice, then, the addition of a single statement in one function can lead to extensive code recompilation and relinking for all clients of a library. This is anything but effective software
On the same topic, a different author
If a public base class does not have a virtual destructor, no derived class nor members of a derived class should have a destructor.
class string { // from the standard C++ library
public:
~string();
};
class B { ... }; // no data members with dtors,
// no virtual dtor needed
but if a new class is derived from B, things
class D: public B {
string name; // NOW ~B needs to be virtual
};
Again, a small change to the way B is used (here, the addition of a derived class that contains a member with a destructor) may necessitate extensive recompilation and relinking by clients. But small changes in software should have small impacts on systems. This design fails that
If a multiple inheritance hierarchy has any destructors, every base class should have a virtual destructor.
In all these quotations, note the present-tense thinking. How do clients manipulate pointers now? What class members have destructors now? What classes in the hierarchy have destructors now?
Future-tense thinking is quite different. Instead of asking how a class is used now, it asks how the class is designed to be used. Future-tense thinking says, if a class is designed to be used as a base class (even if it's not used as one now), it should have a virtual destructor (see Item E14). Such classes behave correctly both now and in the future, and they don't affect other library clients when new classes derive from them. (At least, they have no effect as far as their destructor is concerned. If additional changes to the class are required, other clients may be
A commercial class library (one that predates the string specification in the C++ library standard) contains a string class with no virtual destructor. The vendor's
We didn't make the destructor virtual, because we didn't wantStringto have a vtbl. We have no intention of ever having aString*, so this is not a problem. We are well aware of the difficulties this could cause.
Is this present-tense or future-tense
Certainly the vtbl issue is a legitimate technical concern (see Item 24 and Item E14). The implementation of most String classes contains only a single char* pointer inside each String object, so adding a vptr to each String would double the size of those objects. It is easy to understand why a vendor would be unwilling to do that, especially for a highly visible, heavily used class like String. The performance of such a class might easily fall within the 20% of a program that makes a difference (see Item 16).
Still, the total memory devoted to a string object — the memory for the object itself plus the heap memory needed to hold the string's value — is typically much greater than just the space needed to hold a char* pointer. From this perspective, the overhead imposed by a vptr is less significant. Nevertheless, it is a legitimate technical consideration. (Certainly the string type has a nonvirtual
Somewhat more troubling is the vendor's remark, "We have no intention of ever having a String*, so this is not a problem." That may be true, but their String class is part of a library they make available to thousands of developers. That's a lot of developers, each with a different level of experience with C++, each doing something unique. Do those developers understand the consequences of there being no virtual destructor in String? Are they likely to know that because String has no virtual destructor, deriving new classes from String is a high-risk venture? Is this vendor confident their clients will understand that in the absence of a virtual destructor, deleting objects through String* pointers will not work properly and RTTI operations on pointers and references to Strings may return incorrect information? Is this class easy to use correctly and hard to use
This vendor should provide documentation for its String class that makes clear the class is not designed for derivation, but what if programmers overlook the caveat or flat-out fail to read the
An alternative would be to use C++ itself to prohibit derivation. Item 26 describes how to do this by limiting object creation to the heap and then using auto_ptr objects to manipulate the heap objects. The interface for String creation would then be both unconventional and inconvenient, requiring this,
auto_ptr<String> ps(String::makeString("Future tense C++"));
... // treat ps as a pointer to
// a String object, but don't
// worry about deleting it
String s("Future tense C++");
but perhaps the reduction in the risk of improperly behaving derived classes would be worth the syntactic inconvenience. (For String, this is unlikely to be the case, but for other classes, the trade-off might well be worth
There is a need, of course, for present-tense thinking. The software you're developing has to work with current compilers; you can't afford to wait until the latest language features are implemented. It has to run on the hardware you currently support and it must do so under configurations your clients have available; you can't force your customers to upgrade their systems or modify their operating environment. It has to offer acceptable performance now; promises of smaller, faster programs some years down the line don't generally warm the cockles of potential customers' hearts. And the software you're working on must be available "soon," which often means some time in the recent past. These are important constraints. You cannot ignore
Future-tense thinking simply adds a few additional
Future tense thinking increases the reusability of the code you write, enhances its maintainability, makes it more robust, and facilitates graceful change in an environment where change is a certainty. It must be balanced against present-tense constraints. Too many programmers focus exclusively on current needs, however, and in doing so they sacrifice the long-term viability of the software they design and implement. Be different. Be a renegade. Program in the future
Item 33: Make non-leaf classes abstract.
Suppose you're working on a project whose software deals with animals. Within this software, most animals can be treated pretty much the same, but two kinds of animals — lizards and chickens — require special handling. That being the case, the obvious way to relate the classes for animals, lizards, and chickens is like
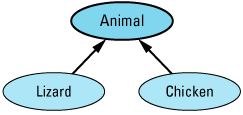
The Animal class embodies the features shared by all the creatures you deal with, and the Lizard and Chicken classes specialize Animal in ways appropriate for lizards and chickens,
Here's a sketch of the definitions for these
class Animal {
public:
Animal& operator=(const Animal& rhs);
...
};
class Lizard: public Animal {
public:
Lizard& operator=(const Lizard& rhs);
...
};
class Chicken: public Animal {
public:
Chicken& operator=(const Chicken& rhs);
...
};
Only the assignment operators are shown here, but that's more than enough to keep us busy for a while. Consider this
Lizard liz1; Lizard liz2;
Animal *pAnimal1 = &liz1; Animal *pAnimal2 = &liz2;
...
*pAnimal1 = *pAnimal2;
There are two problems here. First, the assignment operator invoked on the last line is that of the Animal class, even though the objects involved are of type Lizard. As a result, only the Animal part of liz1 will be modified. This is a partial assignment. After the assignment, liz1's Animal members have the values they got from liz2, but liz1's Lizard members remain
The second problem is that real programmers write code like this. It's not uncommon to make assignments to objects through pointers, especially for experienced C programmers who have moved to C++. That being the case, we'd like to make the assignment behave in a more reasonable fashion. As Item 32 points out, our classes should be easy to use correctly and difficult to use incorrectly, and the classes in the hierarchy above are easy to use
One approach to the problem is to make the assignment operators virtual. If Animal::operator= were virtual, the assignment would invoke the Lizard assignment operator, which is certainly the correct one to call. However, look what happens if we declare the assignment operators
class Animal {
public:
virtual Animal& operator=(const Animal& rhs);
...
};
class Lizard: public Animal {
public:
virtual Lizard& operator=(const Animal& rhs);
...
};
class Chicken: public Animal {
public:
virtual Chicken& operator=(const Animal& rhs);
...
};
Due to relatively recent changes to the language, we can customize the return value of the assignment operators so that each returns a reference to the correct class, but the rules of C++ force us to declare identical parameter types for a virtual function in every class in which it is declared. That means the assignment operator for the Lizard and Chicken classes must be prepared to accept any kind of Animal object on the right-hand side of an assignment. That, in turn, means we have to confront the fact that code like the following is
Lizard liz;
Chicken chick;
Animal *pAnimal1 = &liz;
Animal *pAnimal2 = &chick;
...
*pAnimal1 = *pAnimal2; // assign a chicken to
// a lizard!
This is a mixed-type assignment: a Lizard is on the left and a Chicken is on the right. Mixed-type assignments aren't usually a problem in C++, because the language's strong typing generally renders them illegal. By making Animal's assignment operator virtual, however, we opened the door to such mixed-type
This puts us in a difficult position. We'd like to allow same-type assignments through pointers, but we'd like to forbid mixed-type assignments through those same pointers. In other words, we want to allow
Animal *pAnimal1 = &liz1; Animal *pAnimal2 = &liz2; ... *pAnimal1 = *pAnimal2; // assign a lizard to a lizardbut we want to prohibit this:
Animal *pAnimal1 = &liz; Animal *pAnimal2 = &chick; ... *pAnimal1 = *pAnimal2; // assign a chicken to a lizard
Distinctions such as these can be made only at runtime, because sometimes assigning *pAnimal2 to *pAnimal1 is valid, sometimes it's not. We thus enter the murky world of type-based runtime errors. In particular, we need to signal an error inside operator= if we're faced with a mixed-type assignment, but if the types are the same, we want to perform the assignment in the usual
We can use a dynamic_cast (see Item 2) to implement this behavior. Here's how to do it for Lizard's assignment
Lizard& Lizard::operator=(const Animal& rhs)
{
// make sure rhs is really a lizard
const Lizard& rhs_liz = dynamic_cast<const Lizard&>(rhs);
proceed with a normal assignment of rhs_liz to *this;
}
This function assigns rhs to *this only if rhs is really a Lizard. If it's not, the function propagates the bad_cast exception that dynamic_cast throws when the cast fails. (Actually, the type of the exception is std::bad_cast, because the components of the standard library, including the exceptions thrown by the standard components, are in the namespace std. For an overview of the standard library, see Item E49 and Item 35.)
Even without worrying about exceptions, this function seems needlessly complicated and expensive — the dynamic_cast must consult a type_info structure; see Item 24 — in the common case where one Lizard object is assigned to
Lizard liz1, liz2;
...
liz1 = liz2; // no need to perform a
// dynamic_cast: this
// assignment must be valid
We can handle this case without paying for the complexity or cost of a dynamic_cast by adding to Lizard the conventional assignment
class Lizard: public Animal {
public:
virtual Lizard& operator=(const Animal& rhs);
Lizard& operator=(const Lizard& rhs); // add this
...
};
Lizard liz1, liz2;
...
liz1 = liz2; // calls operator= taking
// a const Lizard&
Animal *pAnimal1 = &liz1;
Animal *pAnimal2 = &liz2;
...
*pAnimal1 = *pAnimal2; // calls operator= taking
// a const Animal&
In fact, given this latter operator=, it's simplicity itself to implement the former one in terms of
Lizard& Lizard::operator=(const Animal& rhs)
{
return operator=(dynamic_cast<const Lizard&>(rhs));
}
This function attempts to cast rhs to be a Lizard. If the cast succeeds, the normal class assignment operator is called. Otherwise, a bad_cast exception is
Frankly, all this business of checking types at runtime and using dynamic_casts makes me nervous. For one thing, some compilers still lack support for dynamic_cast, so code that uses it, though theoretically portable, is not necessarily portable in practice. More importantly, it requires that clients of Lizard and Chicken be prepared to catch bad_cast exceptions and do something sensible with them each time they perform an assignment. In my experience, there just aren't that many programmers who are willing to program that way. If they don't, it's not clear we've gained a whole lot over our original situation where we were trying to guard against partial
Given this rather unsatisfactory state of affairs regarding virtual assignment operators, it makes sense to regroup and try to find a way to prevent clients from making problematic assignments in the first place. If such assignments are rejected during compilation, we don't have to worry about them doing the wrong
The easiest way to prevent such assignments is to make operator= private in Animal. That way, lizards can be assigned to lizards and chickens can be assigned to chickens, but partial and mixed-type assignments are
class Animal {
private:
Animal& operator=(const Animal& rhs); // this is now
... // private
};
class Lizard: public Animal {
public:
Lizard& operator=(const Lizard& rhs);
...
};
class Chicken: public Animal {
public:
Chicken& operator=(const Chicken& rhs);
...
};
Lizard liz1, liz2;
...
liz1 = liz2; // fine
Chicken chick1, chick2;
...
chick1 = chick2; // also fine
Animal *pAnimal1 = &liz1;
Animal *pAnimal2 = &chick1;
...
*pAnimal1 = *pAnimal2; // error! attempt to call
// private Animal::operator=
Unfortunately, Animal is a concrete class, and this approach also makes assignments between Animal objects
Animal animal1, animal2;
...
animal1 = animal2; // error! attempt to call
// private Animal::operator=
Moreover, it makes it impossible to implement the Lizard and Chicken assignment operators correctly, because assignment operators in derived classes are responsible for calling assignment operators in their base classes (see Item E16):
Lizard& Lizard::operator=(const Lizard& rhs)
{
if (this == &rhs) return *this;
Animal::operator=(rhs); // error! attempt to call
// private function. But
// Lizard::operator= must
// call this function to
... // assign the Animal parts
} // of *this!
We can solve this latter problem by declaring Animal::operator= protected, but the conundrum of allowing assignments between Animal objects while preventing partial assignments of Lizard and Chicken objects through Animal pointers remains. What's a poor programmer to
The easiest thing is to eliminate the need to allow assignments between Animal objects, and the easiest way to do that is to make Animal an abstract class. As an abstract class, Animal can't be instantiated, so there will be no need to allow assignments between Animals. Of course, this leads to a new problem, because our original design for this system presupposed that Animal objects were necessary. There is an easy way around this difficulty. Instead of making Animal itself abstract, we create a new class — AbstractAnimal, say — consisting of the common features of Animal, Lizard, and Chicken objects, and we make that class abstract. Then we have each of our concrete classes inherit from AbstractAnimal. The revised hierarchy looks like
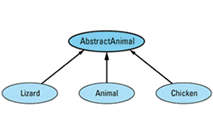
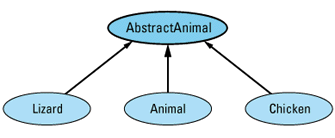
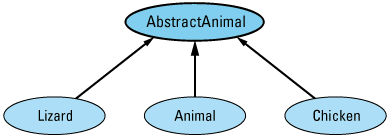
and the class definitions are as
class AbstractAnimal {
protected:
AbstractAnimal& operator=(const AbstractAnimal& rhs);
public:
virtual ~AbstractAnimal() = 0; // see below
...
};
class Animal: public AbstractAnimal {
public:
Animal& operator=(const Animal& rhs);
...
};
class Lizard: public AbstractAnimal {
public:
Lizard& operator=(const Lizard& rhs);
...
};
class Chicken: public AbstractAnimal {
public:
Chicken& operator=(const Chicken& rhs);
...
};
This design gives you everything you need. Homogeneous assignments are allowed for lizards, chickens, and animals; partial assignments and heterogeneous assignments are prohibited; and derived class assignment operators may call the assignment operator in the base class. Furthermore, none of the code written in terms of the Animal, Lizard, or Chicken classes requires modification, because these classes continue to exist and to behave as they did before AbstractAnimal was introduced. Sure, such code has to be recompiled, but that's a small price to pay for the security of knowing that assignments that compile will behave intuitively and assignments that would behave unintuitively won't
For all this to work, AbstractAnimal must be abstract — it must contain at least one pure virtual function. In most cases, coming up with a suitable function is not a problem, but on rare occasions you may find yourself facing the need to create a class like AbstractAnimal in which none of the member functions would naturally be declared pure virtual. In such cases, the conventional technique is to make the destructor a pure virtual function; that's what's shown above. In order to support polymorphism through pointers correctly, base classes need virtual destructors anyway (see Item E14), so the only cost associated with making such destructors pure virtual is the inconvenience of having to implement them outside their class definitions. (For an example, see page 195.)
(If the notion of implementing a pure virtual function strikes you as odd, you just haven't been getting out enough. Declaring a function pure virtual doesn't mean it has no implementation, it
=0").
True, most pure virtual functions are never implemented, but pure virtual destructors are a special case. They must be implemented, because they are called whenever a derived class destructor is invoked. Furthermore, they often perform useful tasks, such as releasing resources (see Item 9) or logging messages. Implementing pure virtual functions may be uncommon in general, but for pure virtual destructors, it's not just common, it's
You may have noticed that this discussion of assignment through base class pointers is based on the assumption that concrete base classes like Animal contain data members. If there are no data members, you might point out, there is no problem, and it would be safe to have a concrete class inherit from a second, dataless, concrete
One of two situations applies to your data-free would-be concrete base class: either it might have data members in the future or it might not. If it might have data members in the future, all you're doing is postponing the problem until the data members are added, in which case you're merely trading short-term convenience for long-term grief (see also Item 32). Alternatively, if the base class should truly never have any data members, that sounds very much like it should be an abstract class in the first place. What use is a concrete base class without
Replacement of a concrete base class like Animal with an abstract base class like AbstractAnimal yields benefits far beyond simply making the behavior of operator= easier to understand. It also reduces the chances that you'll try to treat arrays polymorphically, the unpleasant consequences of which are examined in Item 3. The most significant benefit of the technique, however, occurs at the design level, because replacing concrete base classes with abstract base classes forces you to explicitly recognize the existence of useful abstractions. That is, it makes you create new abstract classes for useful concepts, even if you aren't aware of the fact that the useful concepts
If you have two concrete classes C1 and C2 and you'd like C2 to publicly inherit from C1, you should transform that two-class hierarchy into a three-class hierarchy by creating a new abstract class A and having both C1 and C2 publicly inherit from
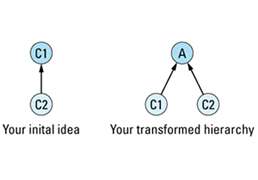
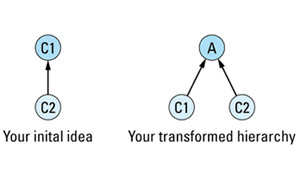
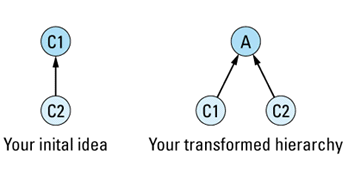
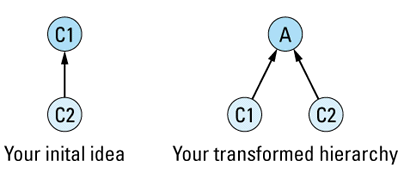
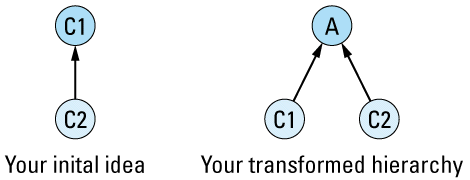
The primary value of this transformation is that it forces you to identify the abstract class A. Clearly, C1 and C2 have something in common; that's why they're related by public inheritance (see Item E35). With this transformation, you must identify what that something is. Furthermore, you must formalize the something as a class in C++, at which point it becomes more than just a vague something, it achieves the status of a formal abstraction, one with well-defined member functions and well-defined
All of which leads to some worrisome thinking. After all, every class represents some kind of abstraction, so shouldn't we create two classes for every concept in our hierarchy, one being abstract (to embody the abstract part of the abstraction) and one being concrete (to embody the object-generation part of the abstraction)? No. If you do, you'll end up with a hierarchy with too many classes. Such a hierarchy is difficult to understand, hard to maintain, and expensive to compile. That is not the goal of object-oriented
The goal is to identify useful abstractions and to force them — and only them — into existence as abstract classes. But how do you identify useful abstractions? Who knows what abstractions might prove useful in the future? Who can predict who's going to want to inherit from
Well, I don't know how to predict the future uses of an inheritance hierarchy, but I do know one thing: the need for an abstraction in one context may be coincidental, but the need for an abstraction in more than one context is usually meaningful. Useful abstractions, then, are those that are needed in more than one context. That is, they correspond to classes that are useful in their own right (i.e., it is useful to have objects of that type) and that are also useful for purposes of one or more derived
This is precisely why the transformation from concrete base class to abstract base class is useful: it forces the introduction of a new abstract class only when an existing concrete class is about to be used as a base class, i.e., when the class is about to be (re)used in a new context. Such abstractions are useful, because they have, through demonstrated need, shown themselves to be
The first time a concept is needed, we can't justify the creation of both an abstract class (for the concept) and a concrete class (for the objects corresponding to that concept), but the second time that concept is needed, we can justify the creation of both the abstract and the concrete classes. The transformation I've described simply mechanizes this process, and in so doing it forces designers and programmers to represent explicitly those abstractions that are useful, even if the designers and programmers are not consciously aware of the useful concepts. It also happens to make it a lot easier to bring sanity to the behavior of assignment
Let's consider a brief example. Suppose you're working on an application that deals with moving information between computers on a network by breaking it into packets and transmitting them according to some protocol. All we'll consider here is the class or classes for representing packets. We'll assume such classes make sense for this
Suppose you deal with only a single kind of transfer protocol and only a single kind of packet. Perhaps you've heard that other protocols and packet types exist, but you've never supported them, nor do you have any plans to support them in the future. Should you make an abstract class for packets (for the concept that a packet represents) as well as a concrete class for the packets you'll actually be using? If you do, you could hope to add new packet types later without changing the base class for packets. That would save you from having to recompile packet-using applications if you add new packet types. But that design requires two classes, and right now you need only one (for the particular type of packets you use). Is it worth complicating your design now to allow for future extension that may never take
There is no unequivocally correct choice to be made here, but experience has shown it is nearly impossible to design good classes for concepts we do not understand well. If you create an abstract class for packets, how likely are you to get it right, especially since your experience is limited to only a single packet type? Remember that you gain the benefit of an abstract class for packets only if you can design that class so that future classes can inherit from it without its being changed in any way. (If it needs to be changed, you have to recompile all packet clients, and you've gained
It is unlikely you could design a satisfactory abstract packet class unless you were well versed in many different kinds of packets and in the varied contexts in which they are used. Given your limited experience in this case, my advice would be not to define an abstract class for packets, adding one later only if you find a need to inherit from the concrete packet
The transformation I've described here is a way to identify the need for abstract classes, not the way. There are many other ways to identify good candidates for abstract classes; books on object-oriented analysis are filled with them. It's not the case that the only time you should introduce abstract classes is when you find yourself wanting to have a concrete class inherit from another concrete class. However, the desire to relate two concrete classes by public inheritance is usually indicative of a need for a new abstract
As is often the case in such matters, brash reality sometimes intrudes on the peaceful ruminations of theory. Third-party C++ class libraries are proliferating with gusto, and what are you to do if you find yourself wanting to create a concrete class that inherits from a concrete class in a library to which you have only read
You can't modify the library to insert a new abstract class, so your choices are both limited and
class Window { // this is the library class
public:
virtual void resize(int newWidth, int newHeight);
virtual void repaint() const;
int width() const;
int height() const;
};
class SpecialWindow { // this is the class you
public: // wanted to have inherit
... // from Window
// pass-through implementations of nonvirtual functions
int width() const { return w.width(); }
int height() const { return w.height(); }
// new implementations of "inherited" virtual functions
virtual void resize(int newWidth, int newHeight);
virtual void repaint() const;
private:
Window w;
};
None of these choices is particularly attractive, so you have to apply some engineering judgment and choose the poison you find least unappealing. It's not much fun, but life's like that sometimes. To make things easier for yourself (and the rest of us) in the future, complain to the vendors of libraries whose designs you find wanting. With luck (and a lot of comments from clients), those designs will improve as time goes
Still, the general rule remains: non-leaf classes should be abstract. You may need to bend the rule when working with outside libraries, but in code over which you have control, adherence to it will yield dividends in the form of increased reliability, robustness, comprehensibility, and extensibility throughout your
Item 34: Understand how to combine C++ and C in the same program.
In many ways, the things you have to worry about when making a program out of some components in C++ and some in C are the same as those you have to worry about when cobbling together a C program out of object files produced by more than one C compiler. There is no way to combine such files unless the different compilers agree on implementation-dependent features like the size of ints and doubles, the mechanism by which parameters are passed from caller to callee, and whether the caller or the callee orchestrates the passing. These pragmatic aspects of mixed-compiler software development are quite properly ignored by
Having done that, there are four other things you need to consider: name mangling, initialization of statics, dynamic memory allocation, and data structure
Name mangling, as you may know, is the process through which your C++ compilers give each function in your program a unique name. In C, this process is unnecessary, because you can't overload function names, but nearly all C++ programs have at least a few functions with the same name. (Consider, for example, the iostream library, which declares several versions of operator<< and operator>>.) Overloading is incompatible with most linkers, because linkers generally take a dim view of multiple functions with the same name. Name mangling is a concession to the realities of linkers; in particular, to the fact that linkers usually insist on all function names being
As long as you stay within the confines of C++, name mangling is not likely to concern you. If you have a function name drawLine that a compiler mangles into xyzzy, you'll always use the name drawLine, and you'll have little reason to care that the underlying object files happen to refer to xyzzy.
It's a different story if drawLine is in a C library. In that case, your C++ source file probably includes a header file that contains a declaration like
void drawLine(int x1, int y1, int x2, int y2);
and your code contains calls to drawLine in the usual fashion. Each such call is translated by your compilers into a call to the mangled name of that function, so when you write
drawLine(a, b, c, d); // call to unmangled function name
your object files contain a function call that corresponds to
xyzzy(a, b, c, d); // call to mangled function mame
But if drawLine is a C function, the object file (or archive or dynamically linked library, etc.) that contains the compiled version of drawLine contains a function called drawLine; no name mangling has taken place. When you try to link the object files comprising your program together, you'll get an error, because the linker is looking for a function called xyzzy, and there is no such
To solve this problem, you need a way to tell your C++ compilers not to mangle certain function names. You never want to mangle the names of functions written in other languages, whether they be in C, assembler, FORTRAN, Lisp, Forth, or what-have-you. (Yes, what-have-you would include COBOL, but then what would you have?) After all, if you call a C function named drawLine, it's really called drawLine, and your object code should contain a reference to that name, not to some mangled version of that
To suppress name mangling, use C++'s extern "C"
// declare a function called drawLine; don't mangle // its name extern "C" void drawLine(int x1, int y1, int x2, int y2);
Don't be drawn into the trap of assuming that where there's an extern "C", there must be an extern "Pascal" and an extern "FORTRAN" as well. There's not, at least not in extern "C" is not as an assertion that the associated function is written in C, but as a statement that the function should be called as if it were written in C. (Technically, extern "C" means the function has C linkage, but what that means is far from clear. One thing it always means, however, is that name mangling is
For example, if you were so unfortunate as to have to write a function in assembler, you could declare it extern "C",
// this function is in assembler — don't mangle its name extern "C" void twiddleBits(unsigned char bits);
You can even declare C++ functions extern "C". This can be useful if you're writing a library in C++ that you'd like to provide to clients using other programming languages. By suppressing the name mangling of your C++ function names, your clients can use the natural and intuitive names you choose instead of the mangled names your compilers would otherwise
// the following C++ function is designed for use outside // C++ and should not have its name mangled extern "C" void simulate(int iterations);
Often you'll have a slew of functions whose names you don't want mangled, and it would be a pain to precede each with extern "C". Fortunately, you don't have to. extern "C" can also be made to apply to a whole set of functions. Just enclose them all in curly
extern "C" { // disable name mangling for
// all the following functions
void drawLine(int x1, int y1, int x2, int y2);
void twiddleBits(unsigned char bits);
void simulate(int iterations);
...
}
This use of extern "C" simplifies the maintenance of header files that must be used with both C++ and C. When compiling for C++, you'll want to include extern "C", but when compiling for C, you won't. By taking advantage of the fact that the preprocessor symbol __cplusplus is defined only for C++ compilations, you can structure your polyglot header files as
#ifdef __cplusplus extern "C" { #endif void drawLine(int x1, int y1, int x2, int y2); void twiddleBits(unsigned char bits); void simulate(int iterations); ... #ifdef __cplusplus } #endif
There is, by the way, no such thing as a "standard" name mangling algorithm. Different compilers are free to mangle names in different ways, and different compilers do. This is a good thing. If all compilers mangled names the same way, you might be lulled into thinking they all generated compatible code. The way things are now, if you try to mix object code from incompatible C++ compilers, there's a good chance you'll get an error during linking, because the mangled names won't match up. This implies you'll probably have other compatibility problems, too, and it's better to find out about such incompatibilities sooner than
Once you've mastered name mangling, you need to deal with the fact that in C++, lots of code can get executed before and after main. In particular, the constructors of static class objects and objects at global, namespace, and file scope are usually called before the body of main is executed. This process is known as static initialization (see Item E47). This is in direct opposition to the way we normally think about C++ and C programs, in which we view main as the entry point to execution of the program. Similarly, objects that are created through static initialization must have their destructors called during static destruction; that process typically takes place after main has finished
To resolve the dilemma that main is supposed to be invoked first, yet objects need to be constructed before main is executed, many compilers insert a call to a special compiler-written function at the beginning of main, and it is this special function that takes care of static initialization. Similarly, compilers often insert a call to another special function at the end of main to take care of the destruction of static objects. Code generated for main often looks as if main had been written like
int main(int argc, char *argv[])
{
performStaticInitialization(); // generated by the
// implementation
the statements you put in main go here;
performStaticDestruction(); // generated by the
// implementation
}
Now don't take this too literally. The functions performStaticInitialization and performStaticDestruction usually have much more cryptic names, and they may even be generated inline, in which case you won't see any functions for them in your object files. The important point is this: if a C++ compiler adopts this approach to the initialization and destruction of static objects, such objects will be neither initialized nor destroyed unless main is written in C++. Because this approach to static initialization and destruction is common, you should try to write main in C++ if you write any part of a software system in
Sometimes it would seem to make more sense to write main in C — say if most of a program is in C and C++ is just a support library. Nevertheless, there's a good chance the C++ library contains static objects (if it doesn't now, it probably will in the future — see Item 32), so it's still a good idea to write main in C++ if you possibly can. That doesn't mean you need to rewrite your C code, however. Just rename the main you wrote in C to be realMain, then have the C++ version of main call realMain:
extern "C" // implement this int realMain(int argc, char *argv[]); // function in C int main(int argc, char *argv[]) // write this in C++ { return realMain(argc, argv); }
If you do this, it's a good idea to put a comment above main explaining what is going
If you cannot write main in C++, you've got a problem, because there is no other portable way to ensure that constructors and destructors for static objects are called. This doesn't mean all is lost, it just means you'll have to work a little harder. Compiler vendors are well acquainted with this problem, so almost all provide some extralinguistic mechanism for initiating the process of static initialization and static destruction. For information on how this works with your compilers, dig into your compilers' documentation or contact their
That brings us to dynamic memory allocation. The general rule is simple: the C++ parts of a program use new and delete (see Item 8), and the C parts of a program use malloc (and its variants) and free. As long as memory that came from new is deallocated via delete and memory that came from malloc is deallocated via free, all is well. Calling free on a newed pointer yields undefined behavior, however, as does deleteing a malloced pointer. The only thing to remember, then, is to segregate rigorously your news and deletes from your mallocs and frees.
Sometimes this is easier said than done. Consider the humble (but handy) strdup function, which, though standard in neither C nor C++, is nevertheless widely
char * strdup(const char *ps); // return a copy of the
// string pointed to by ps
If a memory leak is to be avoided, the memory allocated inside strdup must be deallocated by strdup's caller. But how is the memory to be deallocated? By using delete? By calling free? If the strdup you're calling is from a C library, it's the latter. If it was written for a C++ library, it's probably the former. What you need to do after calling strdup, then, varies not only from system to system, but also from compiler to compiler. To reduce such portability headaches, try to avoid calling functions that are neither in the standard library (see Item E49 and Item 35) nor available in a stable form on most computing
Which brings us at long last to passing data between C++ and C programs. There's no hope of making C functions understand C++ features, so the level of discourse between the two languages must be limited to those concepts that C can express. Thus, it should be clear there's no portable way to pass objects or to pass pointers to member functions to routines written in C. C does understand normal pointers, however, so, provided your C++ and C compilers produce compatible output, functions in the two languages can safely exchange pointers to objects and pointers to non-member or static functions. Naturally, structs and variables of built-in types (e.g., ints, chars, etc.) can also freely cross the C++/C
Because the rules governing the layout of a struct in C++ are consistent with those of C, it is safe to assume that a structure definition that compiles in both languages is laid out the same way by both compilers. Such structs can be safely passed back and forth between C++ and C. If you add nonvirtual functions to the C++ version of the struct, its memory layout should not change, so objects of a struct (or class) containing only non-virtual functions should be compatible with their C brethren whose structure definition lacks only the member function declarations. Adding virtual functions ends the game, because the addition of virtual functions to a class causes objects of that type to use a different memory layout (see Item 24). Having a struct inherit from another struct (or class) usually changes its layout, too, so structs with base structs (or classes) are also poor candidates for exchange with C
From a data structure perspective, it boils down to this: it is safe to pass data structures from C++ to C and from C to C++ provided the definition of those structures compiles in both C++ and C. Adding nonvirtual member functions to the C++ version of a struct that's otherwise compatible with C will probably not affect its compatibility, but almost any other change to the struct
If you want to mix C++ and C in the same program, remember the following simple
extern "C".
main in C++.
delete with memory from new; always use free with memory from malloc.
Item 35: Familiarize yourself with
Since its publication in 1990,
The post-ARM changes to C++ significantly affect how good programs are written. As a result, it is important for C++ programmers to be familiar with the primary ways in which the C++ specified by the standard differs from that described by the
The
bool, the mutable and explicit keywords, the ability to overload operators for enums, and the ability to initialize constant integral static class members within a class definition.
unexpected function may now throw a bad_exception object.
operator new[] operator delete[] new/new[] new/new[] static_cast, dynamic_cast, const_cast, and reinterpret_cast.
Almost all these changes are described in
The changes to C++ proper pale in comparison to what's happened to the standard library. Furthermore, the evolution of the standard library has not been as well publicized as that of the language. The Design and Evolution of C++, for example, makes almost no mention of the standard library. The books that do discuss the library are sometimes out of date, because the library changed quite substantially in
The capabilities of the standard library can be broken down into the following general categories (see also Item E49):
string type, there will be blood in the streets!" (Some people get so emotional.) Calm yourself and put away those hatchets and truncheons — the standard C++ library has strings.
iostream and fstream) and some have been replaced (e.g., string-based stringstreams replace char*-based strstreams, which are now deprecated), the basic capabilities of the standard iostream classes mirror those of the implementations that have existed for several years.
valarrays) that restrict aliasing. These arrays are eligible for more aggressive optimization than are built-in arrays, especially on multiprocessing architectures. The library also provides a few commonly useful numeric functions, including partial sum and adjacent difference.
Before I describe the STL, though, I must dispense with two idiosyncrasies of the standard C++ library you need to know
First, almost everything in the library is a template. In this book, I may have referred to the standard string class, but in fact there is no such class. Instead, there is a class template called basic_string that represents sequences of characters, and this template takes as a parameter the type of the characters making up the sequences. This allows for strings to be made up of chars, wide chars, Unicode chars,
What we normally think of as the string class is really the template instantiation basic_string<char>. Because its use is so common, the standard library provides a
typedef basic_string<char> string;
Even this glosses over many details, because the basic_string template takes three arguments; all but the first have default values. To really understand the string type, you must face this full, unexpurgated declaration of basic_string:
template<class charT,
class traits = string_char_traits<charT>,
class Allocator = allocator>
class basic_string;
You don't need to understand this gobbledygook to use the string type, because even though string is a typedef for The Template Instantiation from Hell, it behaves as if it were the unassuming non-template class the typedef makes it appear to be. Just tuck away in the back of your mind the fact that if you ever need to customize the types of characters that go into strings, or if you want to fine-tune the behavior of those characters, or if you want to seize control over the way memory for strings is allocated, the basic_string template allows you to do these
The approach taken in the design of the string type — generalize it and make the generalization a template — is repeated throughout the standard C++ library. IOstreams? They're templates; a type parameter defines the type of character making up the streams. Complex numbers? Also templates; a type parameter defines how the components of the numbers should be stored. Valarrays? Templates; a type parameter specifies what's in each array. And of course the STL consists almost entirely of templates. If you are not comfortable with templates, now would be an excellent time to start making serious headway toward that
The other thing to know about the standard library is that virtually everything it contains is inside the namespace std. To use things in the standard library without explicitly qualifying their names, you'll have to employ a using directive or (preferably) using declarations (see Item E28). Fortunately, this syntactic administrivia is automatically taken care of when you #include the appropriate
The biggest news in the standard C++ library is the STL, the Standard Template Library. (Since almost everything in the C++ library is a template, the name STL is not particularly descriptive. Nevertheless, this is the name of the containers and algorithms portion of the library, so good name or bad, this is what we
The STL is likely to influence the organization of many — perhaps most — C++ libraries, so it's important that you be familiar with its general principles. They are not difficult to understand. The STL is based on three fundamental concepts: containers, iterators, and algorithms. Containers hold collections of objects. Iterators are pointer-like objects that let you walk through STL containers just as you'd use pointers to walk through built-in arrays. Algorithms are functions that work on STL containers and that use iterators to help them do their
It is easiest to understand the STL view of the world if we remind ourselves of the C++ (and C) rules for arrays. There is really only one rule we need to know: a pointer to an array can legitimately point to any element of the array or to one element beyond the end of the array. If the pointer points to the element beyond the end of the array, it can be compared only to other pointers to the array; the results of dereferencing it are
We can take advantage of this rule to write a function to find a particular value in an array. For an array of integers, our function might look like
int * find(int *begin, int *end, int value)
{
while (begin != end && *begin != value) ++begin;
return begin;
}
This function looks for value in the range between begin and end (excluding end — end points to one beyond the end of the array) and returns a pointer to the first occurrence of value in the array; if none is found, it returns end.
Returning end seems like a funny way to signal a fruitless search. Wouldn't 0 (the null pointer) be better? Certainly null seems more natural, but that doesn't make it "better." The find function must return some distinctive pointer value to indicate the search failed, and for this purpose, the end pointer is as good as the null pointer. In addition, as we'll soon see, the end pointer generalizes to other types of containers better than the null
Frankly, this is probably not the way you'd write the find function, but it's not unreasonable, and it generalizes astonishingly well. If you followed this simple example, you have mastered most of the ideas on which the STL is
You could use the find function like
int values[50]; ... int *firstFive = find(values, // search the range values+50, // values[0] - values[49] 5); // for the value 5 if (firstFive != values+50) { // did the search succeed? ... // yes } else { ... // no, the search failed }
You can also use find to search subranges of the
int *firstFive = find(values, // search the range values+10, // values[0] - values[9] 5); // for the value 5 int age = 36; ... int *firstValue = find(values+10, // search the range values+20, // values[10] - values[19] age); // for the value in age
There's nothing inherent in the find function that limits its applicability to arrays of ints, so it should really be a
template<class T>
T * find(T *begin, T *end, const T& value)
{
while (begin != end && *begin != value) ++begin;
return begin;
}
In the transformation to a template, notice how we switched from pass-by-value for value to pass-by-reference-to-const. That's because now that we're passing arbitrary types around, we have to worry about the cost of pass-by-value. Each by-value parameter costs us a call to the parameter's constructor and destructor every time the function is invoked. We avoid these costs by using pass-by-reference, which involves no object construction or destruction (see Item E22).
This template is nice, but it can be generalized further. Look at the operations on begin and end. The only ones used are comparison for inequality, dereferencing, prefix increment (see Item 6), and copying (for the function's return value — see Item 19). These are all operations we can overload, so why limit find to using pointers? Why not allow any object that supports these operations to be used in addition to pointers? Doing so would free the find function from the built-in meaning of pointer operations. For example, we could define a pointer-like object for a linked list whose prefix increment operator moved us to the next element in the
This is the concept behind STL iterators. Iterators are pointer-like objects designed for use with STL containers. They are first cousins to the smart pointers of Item 28, but smart pointers tend to be more ambitious in what they do than do STL iterators. From a technical viewpoint, however, they are implemented using the same
Embracing the notion of iterators as pointer-like objects, we can replace the pointers in find with iterators, thus rewriting find like
template<class Iterator, class T> Iterator find(Iterator begin, Iterator end, const T& value) { while (begin != end && *begin != value) ++begin; return begin; }
Congratulations! You have just written part of the Standard Template Library. The STL contains dozens of algorithms that work with containers and iterators, and find is one of
Containers in STL include bitset, vector, list, deque, queue, priority_queue, stack, set, and map, and you can apply find to any of these container
list<char> charList; // create STL list object
// for holding chars
...
// find the first occurrence of 'x' in charList
list<char>::iterator it = find(charList.begin(),
charList.end(),
'x');
"Whoa!", I hear you cry, "This doesn't look anything like it did in the array examples above!" Ah, but it does; you just have to know what to look
To call find for a list object, you need to come up with iterators that point to the first element of the list and to one past the last element of the list. Without some help from the list class, this is a difficult task, because you have no idea how a list is implemented. Fortunately, list (like all STL containers) obliges by providing the member functions begin and end. These member functions return the iterators you need, and it is those iterators that are passed into the first two parameters of find
When find is finished, it returns an iterator object that points to the found element (if there is one) or to charList.end() (if there's not). Because you know nothing about how list is implemented, you also know nothing about how iterators into lists are implemented. How, then, are you to know what type of object is returned by find? Again, the list class, like all STL containers, comes to the rescue: it provides a typedef, iterator, that is the type of iterators into lists. Since charList is a list of chars, the type of an iterator into such a list is list<char>::iterator, and that's what's used in the example above. (Each STL container class actually defines two iterator types, iterator and const_iterator. The former acts like a normal pointer, the latter like a pointer-to-const.)
Exactly the same approach can be used with the other STL containers. Furthermore, C++ pointers are STL iterators, so the original array examples work with the STL find function,
int values[50]; ... int *firstFive = find(values, values+50, 5); // fine, calls // STL find
At its core, STL is very simple. It is just a collection of class and function templates that adhere to a set of conventions. The STL collection classes provide functions like begin and end that return iterator objects of types defined by the classes. The STL algorithm functions move through collections of objects by using iterator objects over STL collections. STL iterators act like pointers. That's really all there is to it. There's no big inheritance hierarchy, no virtual functions, none of that stuff. Just some class and function templates and a set of conventions to which they all
Which leads to another revelation: STL is extensible. You can add your own collections, algorithms, and iterators to the STL family. As long as you follow the STL conventions, the standard STL collections will work with your algorithms and your collections will work with the standard STL algorithms. Of course, your templates won't be part of the standard C++ library, but they'll be built on the same principles and will be just as
There is much more to the C++ library than I've described here. Before you can use the library effectively, you must learn more about it than I've had room to summarize, and before you can write your own STL-compliant templates, you must learn more about the conventions of the STL. The standard C++ library is far richer than the C library, and the time you take to familiarize yourself with it is time well spent (see also Item E49). Furthermore, the design principles embodied by the library — those of generality, extensibility, customizability, efficiency, and reusability — are well worth learning in their own right. By studying the standard C++ library, you not only increase your knowledge of the ready-made components available for use in your software, you learn how to apply the features of C++ more effectively, and you gain insight into how to design better libraries of your