Next: Varying Up: Results Previous: Results
|
| Skew | Random | Balanced | ||
| Succ. |
Succ. |
|||
| Uniform | ||||
| Zipf ( |
||||
| Zipf ( |
||||
| Zipf ( |
||||
These first experiments confirm that, under conditions of constant or near-constant capacity and uniform query distribution, simple namespace balancing is highly effective. However, when either of these conditions fails to hold, it is not.
In order to see the correlation between a node's namespace and its
utilization, we ran a simple set of experiments in which we varied
workload skew in a system that was performing no load balancing. We
monitored the incoming routing and maintenance messages for each
node and compared this to the fraction of the ID space for which
that node was used as a hop or destination. We ran two sets of
experiments: one where VS identifiers were chosen at random and a
second where they were set offline to be exactly equal. This second
case shows the best that namespace balancing could achieve. We used
![]() nodes and set all node capacities so that they could route
nodes and set all node capacities so that they could route
![]() messages per second. No churn was used because the exactly
equal ID computation is only performed offline. We varied workload
skew from uniform to Zipf with
messages per second. No churn was used because the exactly
equal ID computation is only performed offline. We varied workload
skew from uniform to Zipf with ![]() . Because no active
algorithm was used and there was no churn, each experiment
stabilized immediately. Every node had one virtual server and there
were
. Because no active
algorithm was used and there was no churn, each experiment
stabilized immediately. Every node had one virtual server and there
were ![]() queries per second (10 queries per alive node).
queries per second (10 queries per alive node).
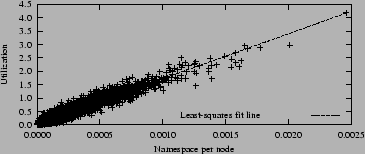
We plot the correlation between namespace and node utilization for a
uniform workload in Figure 11. As is
expected, the average namespace per node is
![]() . Because no load balancing is used, the distribution of
namespaces is long-tailed. Analytically, the largest distance between two VSs
should be
. Because no load balancing is used, the distribution of
namespaces is long-tailed. Analytically, the largest distance between two VSs
should be
![]() , close to the measured value of
, close to the measured value of ![]() . Utilizations with random IDs ranged
from almost 0 to about 4. In contrast, the case where the
namespaces were completely balanced yielded an extremely small range
of utilizations from
. Utilizations with random IDs ranged
from almost 0 to about 4. In contrast, the case where the
namespaces were completely balanced yielded an extremely small range
of utilizations from ![]() to
to ![]() .
.
As we relax the assumption that workloads are uniform, the benefit in perfectly uniform address spaces declines. Table I shows how the correlation and success rates for queries decline as workload skew increases. Separate experiments confirm a similar decline as heterogeneity in nodes' capacities changes from a constant. We can conclude from this that, in order to achieve reasonable performance, a load balancing algorithm must include some workload parameter and cannot aim for address space balancing alone.
Jonathan Ledlie 2006-01-06