Next: Trace Results Up: Results Previous: Namespace Balancing
The second set of experiments explores k-Choices parameters for Gnutella-like systems. Our goal was to find a reasonable set of parameters for the subsequent experiments.
We generated a synthetic churn trace of 4k nodes with Pareto
distributed average lifetimes of 60 minutes and a Gnutella-like
capacity distribution with average capacity of 100 messages/second.
Each node initiated 10 queries/second. We ran each experiment for
three hours and monitored node utilization. We varied ![]() and
ran k-Choices in active and passive modes.
and
ran k-Choices in active and passive modes.
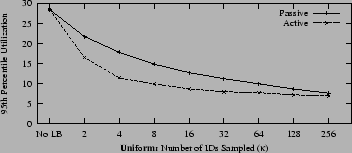
The ![]() percentile utilizations are plotted in Figure
12. When
percentile utilizations are plotted in Figure
12. When ![]() , k-Choices is not in use,
showing the situation without any load balancing. The results show
that active k-Choices lowers utilization at a significantly
faster rate than passive does as
, k-Choices is not in use,
showing the situation without any load balancing. The results show
that active k-Choices lowers utilization at a significantly
faster rate than passive does as ![]() increases. In both
lookup scenarios, the
increases. In both
lookup scenarios, the ![]() percentile utilizations do not
decrease much beyond when
percentile utilizations do not
decrease much beyond when ![]() in active mode. The results also
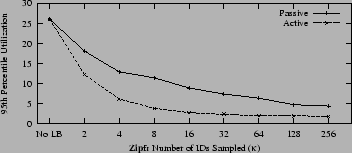
show that a skewed query distribution (
in active mode. The results also
show that a skewed query distribution (![]() ) has minimal
impact on utilization for k-Choices. In fact, it even lowers peak
utilization as nodes with more bandwidth are able to position their
VSs where the workload is concentrated. As noted above, there are
substantial drawbacks to large numbers of VSs per node and to setting
) has minimal
impact on utilization for k-Choices. In fact, it even lowers peak
utilization as nodes with more bandwidth are able to position their
VSs where the workload is concentrated. As noted above, there are
substantial drawbacks to large numbers of VSs per node and to setting
![]() to a large value (e.g., large numbers of probes). Therefore, we
used
to a large value (e.g., large numbers of probes). Therefore, we
used ![]() in subsequent experiments, unless otherwise noted.
As these results portend, preliminary experiments with Optimal ID
choice suggest that k-Choices works well without a huge sampling of
IDs. We also experimented with values for
in subsequent experiments, unless otherwise noted.
As these results portend, preliminary experiments with Optimal ID
choice suggest that k-Choices works well without a huge sampling of
IDs. We also experimented with values for ![]() , which we set to
, which we set to
![]() in our experiments. These results show that k-Choices
needs only a small number of choices to produce a substantial decrease in
node utilization.
in our experiments. These results show that k-Choices
needs only a small number of choices to produce a substantial decrease in
node utilization.
We ran similar experiments to find good parameters for
Threshold. Its two parameters ![]() and
and ![]() were set to
were set to ![]() and
and ![]() respectively.
respectively.