Next: k-Choices Algorithm Up: Distributed, Secure Load Balancing Previous: Introduction
In this section, we introduce our model and assumptions for load balancing in p2p systems.
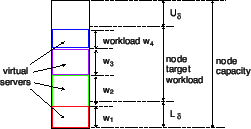
Overload. Physical nodes, i.e., computers, participate in p2p
systems. Each node ![]() has a capacity
has a capacity ![]() , which
corresponds to the maximum amount of load that node can process per
unit time. Nodes create virtual servers (VSs), which join the p2p
network. A node
, which
corresponds to the maximum amount of load that node can process per
unit time. Nodes create virtual servers (VSs), which join the p2p
network. A node ![]() might have
might have ![]() VSs
VSs
![]() , each with loads
, each with loads
![]() , respectively.
Load is applied to nodes via their virtual servers. In a unit of
time, node
, respectively.
Load is applied to nodes via their virtual servers. In a unit of
time, node ![]() might have load (work)
might have load (work)
![]() .
.
Overload occurs when, for a node ![]() ,
, ![]() . An
overloaded node is not able to store objects given to it, route
packets, or perform computation, depending on the application. A
node fails to process requests that impose work beyond its capacity.
Per unit time, the successful work per node is:
. An
overloaded node is not able to store objects given to it, route
packets, or perform computation, depending on the application. A
node fails to process requests that impose work beyond its capacity.
Per unit time, the successful work per node is:
Each node stores its virtual servers in a set, called VSset of size VSset.size. Depending on the algorithm, this size may have an upper bound of VSset.maxsize.
Routing. Structured overlays allow routing of messages to
destinations on top of an underlying network constantly undergoing
topology change
[36,38,43,47].
Each message's destination ID is a number on the overlay's namespace
![]() , e.g.,
, e.g., ![]() . Messages traverse overlay hops from a source
VS to a destination VS. The number of hops is typically
. Messages traverse overlay hops from a source
VS to a destination VS. The number of hops is typically
![]() , where
, where ![]() is the current number of VSs.
is the current number of VSs.
Each VS has a unique ID chosen from the namespace ![]() . In our
model, the destination of a message is the VS with the next largest
logical identifier on the namespace mod
. In our
model, the destination of a message is the VS with the next largest
logical identifier on the namespace mod ![]() . The VS with the next
largest (smallest) ID is called the successor
(predecessor). We denote the distance in the namespace
between two virtual servers
. The VS with the next
largest (smallest) ID is called the successor
(predecessor). We denote the distance in the namespace
between two virtual servers ![]() and
and ![]() with
with ![]() .
.
Each structured overlay allows new VSs to join the
system. In general, each VS join and departure requires ![]() maintenance messages. Reactive load balancing algorithms use
artificial join and departure to change
IDs.
maintenance messages. Reactive load balancing algorithms use
artificial join and departure to change
IDs.
Network as Bottleneck. We focus on how load balancing
algorithms function at the routing level. Blake and Rodrigues
provide evidence that even in remote storage applications, network
bandwidth is likely to be the primary
bottleneck [2]. As storage becomes cheaper and cheaper
relative to bandwidth, particularly ``last-mile'' bandwidth, this
case will likely become more common. In compute-dominated
scenarios, whether the processing or the network will be the bottleneck
depends on the application. We let a node ![]() 's capacity
's capacity ![]() be the number of routing hops it can provide per unit time. We
compare algorithms on the percentage of messages that successfully
reach their destinations.
be the number of routing hops it can provide per unit time. We
compare algorithms on the percentage of messages that successfully
reach their destinations.
Security. A key issue in the operation of a p2p network is whether or not one assumes it may contain malicious nodes. A malicious node can subvert content or attempt to control particular portions of the identifier space. Attacks that center around the falsification of a node's identifier are called Sybil attacks [14]. Douceur outlines the main difficulties in allowing nodes to choose their own IDs. He shows that validating nodes must verify all other nodes' credentials simultaneously, an act that may exceed the verifier's resources.
A system may acquire a low level of security by requiring that IDs
be based on the hash of the node's IP address [12]. However, falsifying
IP addresses is straightforward; basing any level of authentication
on IP addresses would not repel a determined attacker. For this
reason, Castro et al. propose that each ID ![]() is certified by a
central authority, which generates
is certified by a
central authority, which generates
![]() [9]. This option is scalable because
each node contacts this authority once, the first time it joins the
system.
[9]. This option is scalable because
each node contacts this authority once, the first time it joins the
system.
Instead of having this authority certify IDs, we propose that it
certify a unique number ![]() for each node, creating
for each node, creating ![]() . Each
node can then use this number to generate its own IDs using an
ID-generating hash function
. Each
node can then use this number to generate its own IDs using an
ID-generating hash function ![]() . For a node with ID
. For a node with ID ![]() , a verifier
verifies that
, a verifier
verifies that ![]() instead of
instead of ![]() . k-Choices
creates a set of verifiable IDs by generating each
. k-Choices
creates a set of verifiable IDs by generating each
![]() where
where ![]() has a well-known bound.
We refer to
has a well-known bound.
We refer to ![]() as
as ![]() below for purposes of
presentation.
below for purposes of
presentation.
The k-Choices solution we propose retains this Sybil attack resilience. Algorithms that permit a node to relocate its virtual server to an arbitrary node ID location do not have this quality. Algorithms that do not allow for certified IDs can only be expected to function in a trusted environment.
System Characteristics. Although structured overlays are
targeted to provide the framework for applications such as
application-level multicast [8], distributed
storage [10,16], and publish-subscribe
content distribution [34,42], there
are no benchmark workloads. Gummadi et al. and others have found
Zipf query distributions in their trace analysis of Kazaa
[3,24,39] and
this distribution is common to many other usages (e.g., web page file
access [18], file
popularity [17]). We examine load balancing
under uniformly random and Zipf queries. A Zipf workload with
parameter ![]() means that destinations are ranked by popularity.
Destination with rank
means that destinations are ranked by popularity.
Destination with rank ![]() is
is ![]() times more likely to
be accessed than that with rank
times more likely to
be accessed than that with rank ![]() .
.
A characteristic related to skew is workload shift. Shift refers to a change in workload skew. For example, on one day, one stored object might be the most popular, on the next, a different one might be, but the general distribution would be the same. Studies of object popularities in deployed p2p systems have found the existence of shifting Zipf skewed workloads [24].
A third characteristic is the distribution of node capacities. As is generally the case in p2p scenarios, bandwidth is the main capacity limiter [2]. In the traces which we draw from, node capacities vary by six orders-of-magnitude [39] and a simple function does not capture the trace bandwidth distribution well.
A final characteristic is the distribution of node joins and
departures (churn). As we discuss in Section V,
this cannot be captured with a simple rate ![]() . Instead, churn
tends to be Pareto: heavy-tailed and memory-full. Nodes that have
been in the system for a long time tend to remain longer
than average [3]. Pareto distributions
have two parameters, shape
. Instead, churn
tends to be Pareto: heavy-tailed and memory-full. Nodes that have
been in the system for a long time tend to remain longer
than average [3]. Pareto distributions
have two parameters, shape ![]() and scale
and scale ![]() , and have a mean of
, and have a mean of
![]() .
.

|
 |
Jonathan Ledlie 2006-01-06