Implementation of the Policy Parser
Introduction
As briefly described in the Intro section, the Policy Parser consists of three major components: the Parser, which uses a feature-based context free grammar to extract semantic information of interest, the Policy Interpreter, which analyzes and processes the semantic information, and the RDF Generator, which generates the corresponding AIR policy in the RDF/N3 format. The system also includes the online RDF policy store as well as the AIR reasoner, but these can be considered peripheral to the above three components. In this section, we will describe each of these components in detail. Before we dive into the details, we first define the scope of our project with respect to the types of user input that the Policy Parser is designed to handle.
Automatically parsing an arbitrary natural language sentence is an extremely challenging task, and is beyond the scope of this project. Thus, we focus on a constrained set of natural language sentence forms. Past research has shown that constrained natural language can be effectively used for automatically generating policies, and that unconstrained natural language gives significantly poorer results [1], [2]. More specifically, our system assumes a specific structure for a natural language policy which is as follows:
subject mod action [object] [secondary_object] [for/to purpose] [if condition (and condition)*]
where the meanings of the constituents are the following:
- subject: The main actor or entity who carries out an action
- mod: The modality of the rule (i.e., whether the subject is allowed or disallowed to perform the specified action under the specified constraints, expressed using words such as "can", "cannot" etc.)
- action: The action performed by the subject
- object: The object on which the action is performed (when "action" is a transitive verb)
- secondary object: the secondary object for the action (applicable only if "action" is a ditransitive verb)
- purpose: an (optional) purpose for which the action is performed
- condition: an (optional) condition (or set of conditions) under which the rule is applicable
For example, consider the sentence "Police may search people's homes for a criminal investigation if the police has a warrant". Here, we have the following key value pairs:
- subject: police
- mod: yes
- action: search
- object: people's homes
- secondary_object: none
- purpose: criminal investigation
- condition: police has a warrant
Each sentence corresponds to a single policy. The constituents between '[' and ']' are optional; therefore, an input sentence must consist of, at minimum, a subject, an action and the modality of the rule. Also, '*' means "one or more"; thus, a policy may consist of any number of conditions.
Given a user's input policy, the first step is to parse this sentence into a structured format that can be manipulated further by a computer. As stated earlier, we do this using FCFGs. Each of the constituents of a policy statement (subject, action etc.) are further composed of simpler constituents such as noun phrases (NPs), verb phrases (VPs) etc. The permissible forms for each constituent as well as its sub-parts, and the relation of a node's semantic value with that of its children is specified by the FCFG. The start node of the FCFG (S) has a feature corresponding to each of the constituents (subject, action etc.) mentioned above. Since we are interested in the semantic interpretation of the natural language policy, we use the sem feature to record semantic values and propagate them up the parse tree by combining the semantic values of a node's children [7]. The values of features like subject, action, object etc. are derived from the values of the sem features of various constituents. Since we assume a rather constrained form of input, we are able to develop a simple grammar that parses sentences of the form described above and is able to infer the semantic role of a word in the sentences from its position in the parse tree relative to other constituents. In particular, we don't have to worry about many complications that arise in unconstrained natural language with quantifiers.
The words recognized by the system and their categories (N,V etc.) are included in a lexicon file. Spelling changes for words in the lexicon are handled by a kimmo rule (yaml) file. We have thus modularized our implementation so that the feature-based CFG is decoupled from the lexicon and the spelling rule changes. Also, the lexicon and the spelling change rules allow us to do some clever things, for example, the two sentence snippets "...for criminal investigation..." and "...to investigate crime..." lead to the same value for the feature purpose (purpose = (investigate crime)). This gives the user of the system some freedom in expressing a policy. This is particularly important in light of the way the AIR policy associates sentence fragments with predefined ontologies (as explained in the section on the RDF Generator). This and other such techniques may be used to make the system more flexible.
For example, the sentence above, "Police may search people's homes for criminal investigation if the police have a warrant" is parsed into the following syntax tree:

Figure 1: Example Parse Tree (click on the image to enlarge; image will be displayed in another window)
As shown in this tree, the left-hand side of the top-level production rule 'S' contains a feature for each of the semantic constituents (for example, the feature "action" for the action constituent in the policy) for the natural language rule. The value assigned to each top-level feature is defined in terms of features from the subtrees. Note that the l.h.s. of each part-of-speech rule (e.g. 'NP' for noun-phrase) is augmented with the 'sem' feature; this allows us to assign a logical expression to each node in the tree. Here, we use the application of the lambda function 'cat' to concatenate one or more lexicons into a single constituent.
By explicitly defining a top-level feature corresponding to each constituent of interest, the implementation of the Policy Interpreter (the next component in the pipeline) is greatly simplified - it just needs to walk over the list of top-level features and map each to a corresponding RDF construct.
We make us of the existing infrastructure in the Natural Language Toolkit (NLTK) [3] for this part of the Policy Parser. More specifically, we use the featureparser class [4], which in turn is built on top of the Natural Language Toolkit for Python. In addition to a user's sentence, the FCFG parser in NLTK requires three arguments; the FCFG grammar (stored as a .fcfg file), the spelling change rules (a Kimmo file), and the lexicon (.lex file). All of these files are available in the Download Code section.
Given a syntax tree generated by the NLTK Parser, the role of the Policy Interpreter is to extract the semantic information about the user's policy - i.e. the value for each of the constituents in the policy. As mentioned above, this process is relatively straightforward, as it simply involves looking through the list of features that are stored in the root of the syntax tree. The only intricate step in this process is walking over a lambda-calculus expression that is a concatenation of multiple lexical tokens (e.g. '(cat prox (cat card data))' for "prox card data"); this step is implemented using a recursive function for traversing an expression.
The output from the Policy Interpreter is a dictionary (i.e. a list of key-value pairs) that maps each constituent to its value. For example, given the syntax tree for the sentence "Committee on Discipline may access prox card data for criminal investigation", the Policy Interpreter outputs the following dictionary:
| Key | Value | |
|---|---|---|
| 'POLICY' | 'MIT Prox Card Policy' | /* name of the policy */ |
| 'ENTITY' | 'Committee on Discipline' | /* actor */ |
| 'FLAG' | True | /* modality (True for positive, such as 'can') */ |
| 'ACTION' | 'use' | |
| 'PURPOSE' | 'investigate crime' | |
| 'DATA' | 'prox card data' | /* object */ |
| 'CONDITION' | [ ] | |
| 'SECONDARY ENTITY' | None |
Note that some of the keys in the dictionary have different names than the constituents, but there is a 1-1 correspondence between these two sets of names. The renaming was done due to the fact that RDF uses a set of pre-designated identifiers for its constructs.
The Policy Interpreter has been implemented in Python and can be found in the PolicyInterpreter directory of the downloadble code.
This module is responsible for generating AIR (Accountability In RDF) [4] policies. Once the user's sentence is fragmented into the relevant constituents as described above, it will identify the corresponding RDF segments and create the RDF graph using the RDFLib [3] Python library.
AIR is a rule-based policy language written in RDF for accountability and access control. Each AIR policy consists of one or more rules:
policy = { rule* } Each rule is made up of a pattern that when matched
causes an action to be fired. Optionally
there could be description and
justification
elements as well.
rule = { pattern, action [ description justification ] } An action can either be an assertion (which is a set of facts that are added to the knowledge base) or a nested rule.
action = { assertion | rule } The basic skeleton of an AIR policy is as follows:
:MyFirstPolicy a air:Policy;
air:rule [
air:variable { ... };
air:pattern { ... };
air:assertion { ... };
air:rule [ ... ]
].
In order to generate an AIR policy from a constrained natural language sentence, two additional parameters, besides the policy itself, are required:
- Name for the policy
- One or more domain ontologies
The name of the policy is required because the user should be able to identify the policy, and it is not suitable to have a random machine-generated policy name. The domain ontology is required because some of the sentence fragments need to be identified with the corresponding term (which could be either a subject or a predicate or an object) in RDF.
The following diagram shows how the dictionary keys and values from the Policy Interpreter is used in constructing the AIR policy.
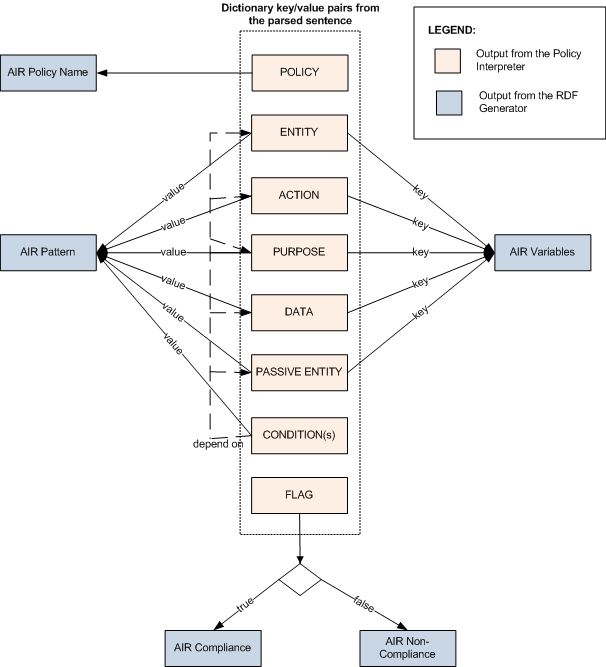
Figure 2: Mapping from the sentence fragments to the AIR Policy
The dictionary element 'POLICY' is used to name
the policy. If the keys of dictionary elements:
'ENTITY',
'ACTION', 'PURPOSE', 'DATA' and 'PASSIVE ENTITY'
have non-null values, they are used to assign
air:variables. The values of these
dictionary
elements are then mapped on to air:patterns
where each air:variables in the previous
step are assigned the corresponding rdf:types.
The sentence could include conditions as in the following sentence: "Committee on Discipline can use prox card data if the Committee on Discipline has authorization". The conditional phrase beginning with the word "if" may refer to components which are already identified, such as "Committee on Discipline" (identified as the 'ENTITY'). Therefore another pattern will be constructed with the subject, predicate or object values encoded in the 'CONDITION'.
All of these steps requires proper identification
of the RDF terms as defined in the ontology. SPARQL queries are used to identify the correct
term from the RDF ontolgy. There is an underlying assumption that for each rdfs:Class and rdfs:Property, which corresponds to
subject/object and predicate respectively, the ontology author has
defined a proper rdfs:label attribute. This attribute is very much likely to be used by the policy author, hence the SPARQL query
is to search for the subject which matches the dictionary value.
Finally, the 'FLAG' sent by the Policy Interpreter will determine to specify whether 'ACTION' is compliant or not with the policy.
References:
[1] Carolyne A. Brodie, Clare-Marie N. Karat, John Karat and JinJuan Feng. Usable Security and Privacy:
A Case Study of Developing Privacy Management Tools. SOUPS 2005 Symposium on Usable Privacy and Security . ACM, April 2005
[2] Clare-Marie Karat. SPARCLE (Server Privacy Architecture and Capability Enablement) policy workbench.
http://domino.watson.ibm.com/comm/research.nsf/pages/r.security.innovation2.html
[3] Steve Bird and Edward Loper. NLTK: The Natural
Language Toolkit. Proceedings of the ACL demonstration
session. pp 214-217, Barcelona, Association for
Computational Lingusitics, July 2004.
[4] Rob Speer. The 6.863 Feature Parsing Library.
http://web.mit.edu/6.863/www/parser
[5] RDFLib http://rdflib.net/
[6] Lalana Kagal, Chris Hanson, Daniel Weitzner at al, Decentralized Information Group, CSAIL, MIT.
AIR Policy Language http://dig.csail.mit.edu/TAMI/2007/AIR/
[7] Natural Language Toolkit Book http://nltk.org/index.php/Book