What is the Policy Parser?
Lawyers work with laws and policies all the time. They also determine given a scenario and a set of policies, whether a particular sequence of events in this scenario violates one or more of the given policies. Enforcing policies can be a challenging and error-prone process, as the number of policies gets larger or the scenario itself becomes more complex. In some cases, for example enforcing privacy policies governing access to data on the World Wide Web, manual enforcement of policies is particularly inefficient. Fortunately, some parts of the policy enforcement process are purely deductive reasoning, and therefore, can be automated by a computer. Thanks to recent advancements in knowledge-based reasoning, there now exist systems that can assist in this process; the AIR ("Accountability in RDF") Reasoner [1] is one of such systems.
The AIR reasoner takes input policies and scenarios expressed in RDF and determines whether or not the given scenario violates any of the given policies. RDF (Resource Description Framework) is a data model proposed by the WWW Consortium as a major mechanism of data exchange on the web. AIR can be used for automatically enforcing policies (for example data access policies) without manual intervention.
One of the current barriers to wide spread use of AIR is that it requires the user (person who specifies the policies; often a lawyer) of the system to write the AIR policies in RDF. Although RDF is a well-known, portable language, it is likely that most lawyers will not be well versed in its use. Even for someone who is an expert in RDF, translating a natural language policy into RDF can be tedious and a time-consuming task. It thus becomes difficult to create and update policies that can be enforced automatically.
As a first step towards addressing these challenges, we have built the Policy Parser, which takes a policy, written in constrained natural language, and automatically translates it into its RDF representation. A high-level architecture of our system is shown in the following diagram:
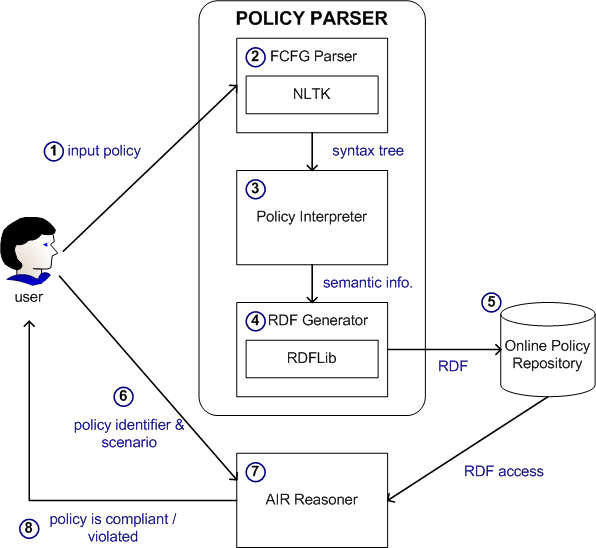
The user enters a policy sentence into our system which is a Firefox sidebar extension available here (Step 1). The sentence is then parsed using a feature-based context-free grammar (FCFG) which extracts semantic information of interest from the input natural language policy. This parsing system is built on top of the NLTK system [2] and the feature parsing library (featureparse) [3]. The semantic information contained in the natural language sentence is recorded in the features of the parse tree. In Step 3, the Policy Interpreter then further processes and analyzes this semantic information about the policy (e.g. the actor who is responsible for a particular action) contained in the features of the parse tree and bundles it up into a suitable form, which is then passed to the RDF Generator. The RDF generator generates an RDF file that corresponds to this policy and stores it in a persistent location (URI) on the web (Steps 4 & 5). The user can immediately (or at any later convenient time) check the compliance/violation of the policy by providing the URI and a particular scenario to the AIR reasoner (Steps 6 - 8), which is executible directly from the web.
A more detailed description of each component can be found in the Implementation page. If you want to experience the Policy Parser, click Try It Now!
References:
[1] AIR (Accountability in RDF). http://dig.csail.mit.edu/TAMI/2007/AIR/
[2] Steve Bird and Edward Loper. NLTK: The Natural Language Toolkit. Proceedings of the ACL demonstration session. pp 214-217, Barcelona, Association for Computational Lingusitics, July 2004.
[3] Rob Speer. The 6.863 Feature Parsing Library. http://web.mit.edu/6.863/www/parser.