If you’ve ever built a complex system, you know how hard it can be. You spend days experimenting, weeks testing ideas, and sometimes months chasing a problem. Early in my PhD, it took me almost two years to design one new systems algorithm. Can we use AI for automated system research?
Here’s the short version of what we found. Pointed at a hard LLM inference problem, an AI that does research — not just code edits — beat every prior LLM-based design framework and matched the best human expert’s solution. The system is called Glia, and the rest of this post is how it got there. Expert took two weeks to design a solution, but Glia did it in about two hours.
1. Why “guess code and keep the best” isn’t enough?
The popular recipe for AI-driven design rely on code mutation and evolutionary algorithms. You start with some code, along with a score and some structured feedback. Then an LLM mutates the selected codes into a few new versions, each gets a new score, and the process repeats. This is how systems like AlphaEvolve, OpenEvolve, ADRS, FunSearch, ShinkaEvolve, and Evolution of Heuristics work.
The problem is that none of these methods really ask why something worked or didn’t work. Code mutation can beat a score on a benchmark, but systems design is open-ended — it demands insight into how the system actually behaves. Code mutation is like fixing a car by randomly swapping parts and only checking whether the car got faster, never opening the hood.
Two things go wrong as a result. Many of the code variants don’t even make logical sense; the loop tries them anyway because it has no way to judge whether an idea is sound. And the programs that do survive are tangled messes of hand-tuned weights and special-case branches — they score well, but no one can explain why, and they break the moment the workload shifts. They are hard to Understand, hence hard to trust. The core limitation is not the LLM’s reasoning capability or the evolutionary framework itself, but the level of abstraction at which the system operates: reasoning purely in code, with limited visibility into system behavior or design principles
2. Glia: Teaching AI to design systems like a researcher
Our vision for Glia is to teach AI to design and optimize complex systems the way a human expert would: by following the scientific method. A systems engineer hands Glia a task and a research playground — a simulator or a testbed. Glia models the system, designs and runs experiments, instruments telemetry, analyzes the results, and lets each discovery feed back into a better mental model.
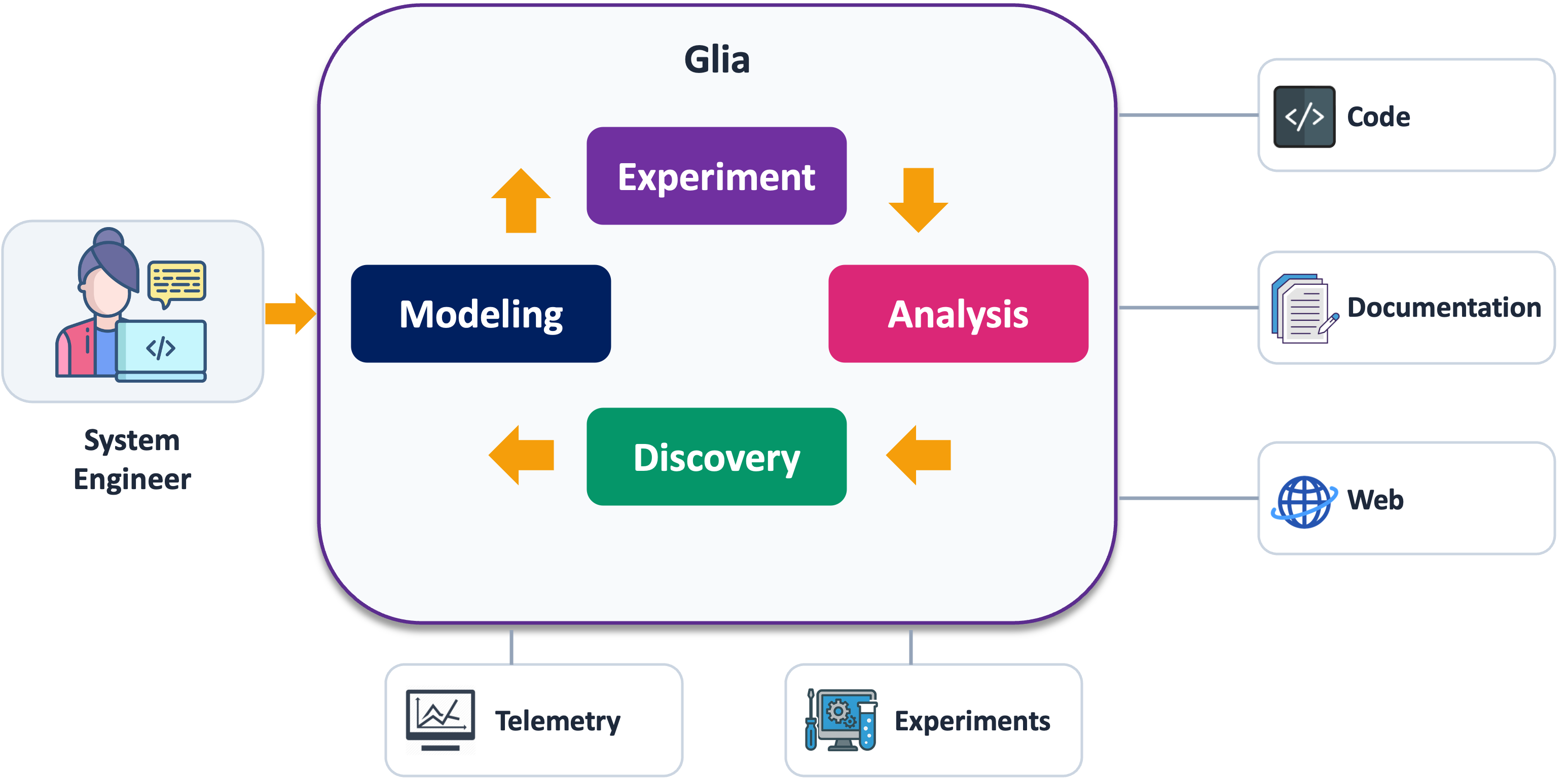
The result is coherent exploration. Every step forward comes from understanding something new — each one grounded in what the last one taught Glia about the system.

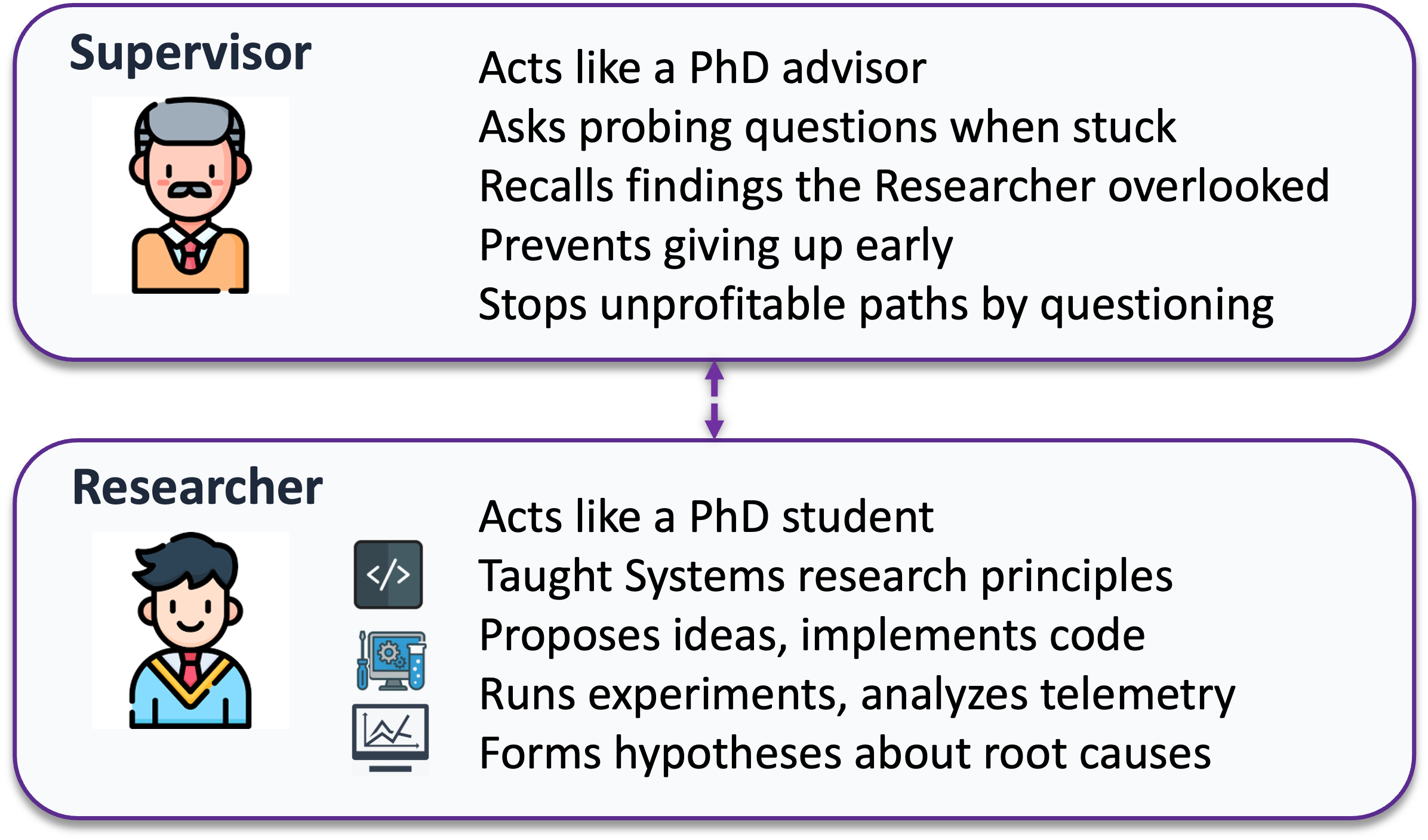
We designed Glia the way a PhD researcher and supervisor interact. There are two agents.
The Researcher acts like a PhD student. It has been taught the principles of systems research and has full access to the playground. It proposes ideas, writes code, runs experiments, analyzes telemetry, and forms hypotheses about root causes.
The Supervisor acts like a PhD advisor and is more of a high-level thought partner. Most of the time it just says proceed. But when the Researcher gets stuck, the Supervisor asks a probing question or recalls a finding the Researcher overlooked — preventing it from giving up too early. It also stops unprofitable paths by questioning the Researcher’s direction, pushing it to reconsider before going further.
3. How Glia actually discovers things?
Let me show you what this looks like on a real problem: LLM serving. When you prompt a chatbot, your requests — along with those of millions of other users — arrive at a request router whose job is to ship each one to a GPU that will serve it. The goal is to distribute requests in a way that minimizes latency. This problem is hard because the decode length of each request is unknown at routing time.
Glia tried the obvious heuristics first; none helped much. Instead of guessing more, it profiled where time was actually going — and found something surprising: about 26% of requests were being evicted and restarted mid-decode, throwing away work. The real bottleneck wasn’t what everyone assumed (uneven load). GPUs were running out of KV-cache memory during decoding, because a request’s eventual memory footprint isn’t known when it first arrives.
Glia then got stuck. The Researcher reported it couldn’t make progress. The Supervisor asked one probing question — why do restarts stubbornly persist? — and in answering, the Researcher had its breakthrough: the router couldn’t foresee how much memory a request would grow to need.
The solution it landed on, the Head-Room Allocator, is the kind of thing a thoughtful human would invent. Estimate each request’s eventual memory footprint, and admit it only to a GPU that will still have a safety margin afterwards. Combine that with serving shorter requests first. The whole policy fits in about 50 lines. A human expert took several days to uncover the same memory bottleneck. Glia found it in about an hour.
4. The results
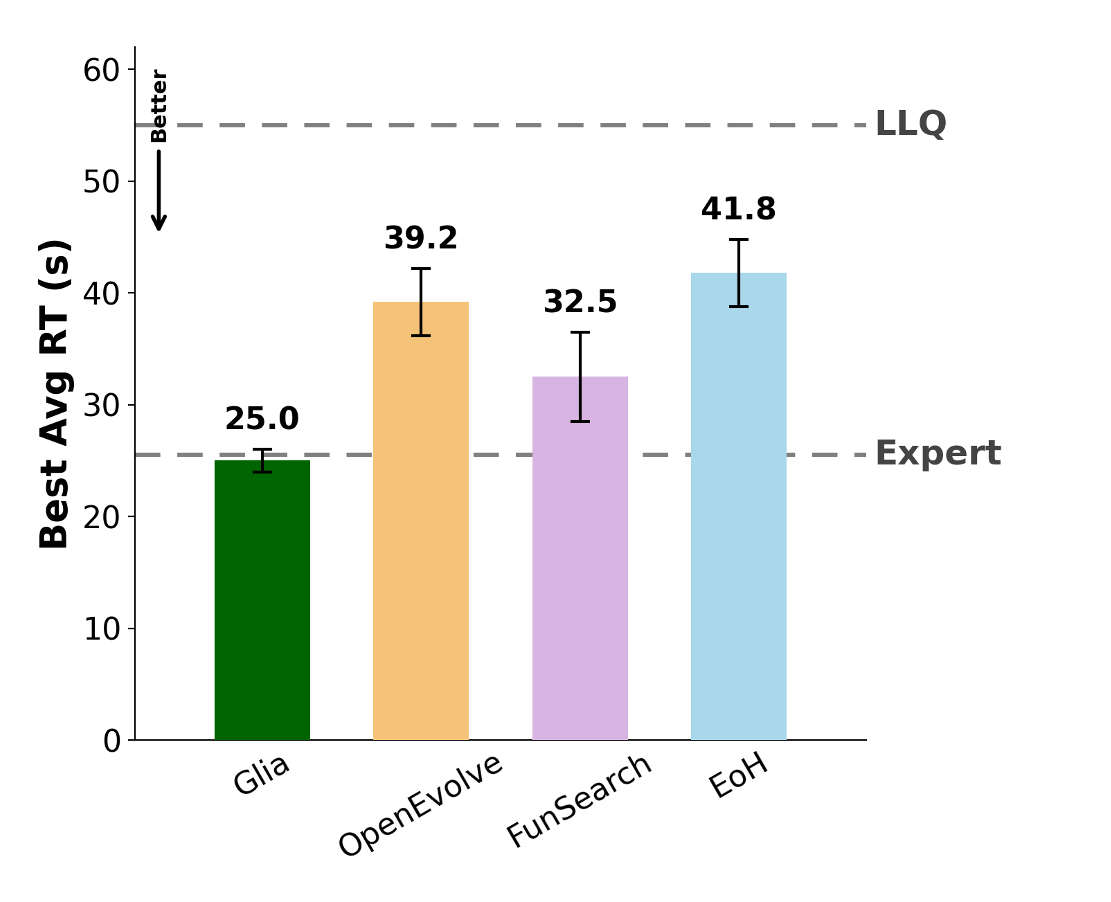
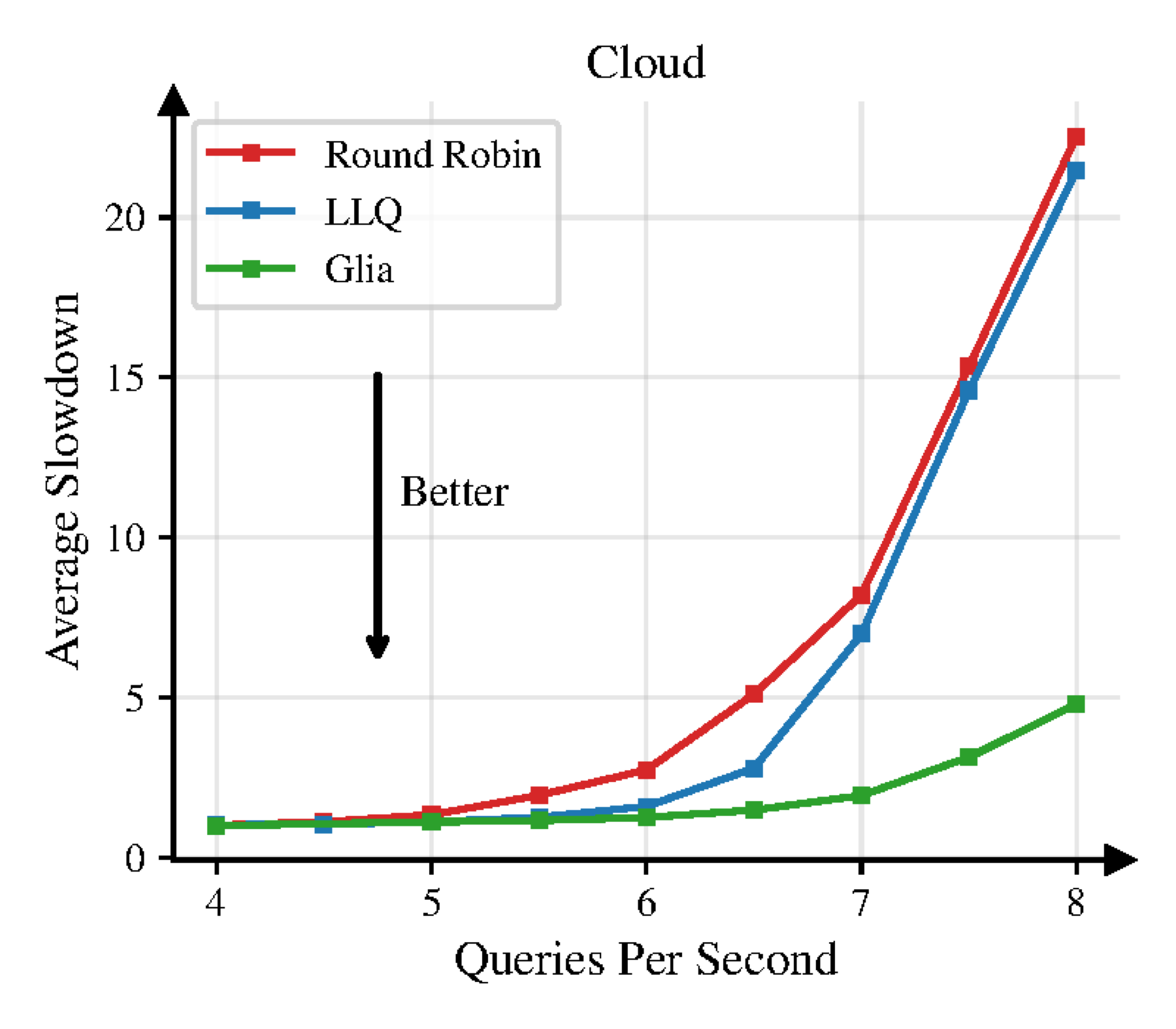
So how do existing methods do on this problem? Human-designed baselines like LLQ sit near the top of the chart — slow. Down at the bottom, Professor Mohammad Alizadeh — one of the leading systems researchers in the world — took two weeks to design a routing algorithm with roughly half the latency of those baselines. We also ran OpenEvolve, FunSearch, and Evolution of Heuristics. They all improve over simple baselines, but none of them reach the expert.
Glia beats all of them — including the expert solution. And it did this in just two hours, not two weeks.
The discovery also survived contact with real hardware. Implemented on four GPUs in vLLM’s production stack, the algorithm cut slowdown by more than 4.5× versus the standard approach, with the same trends the simulator predicted.
5. Scaling across the inference stack
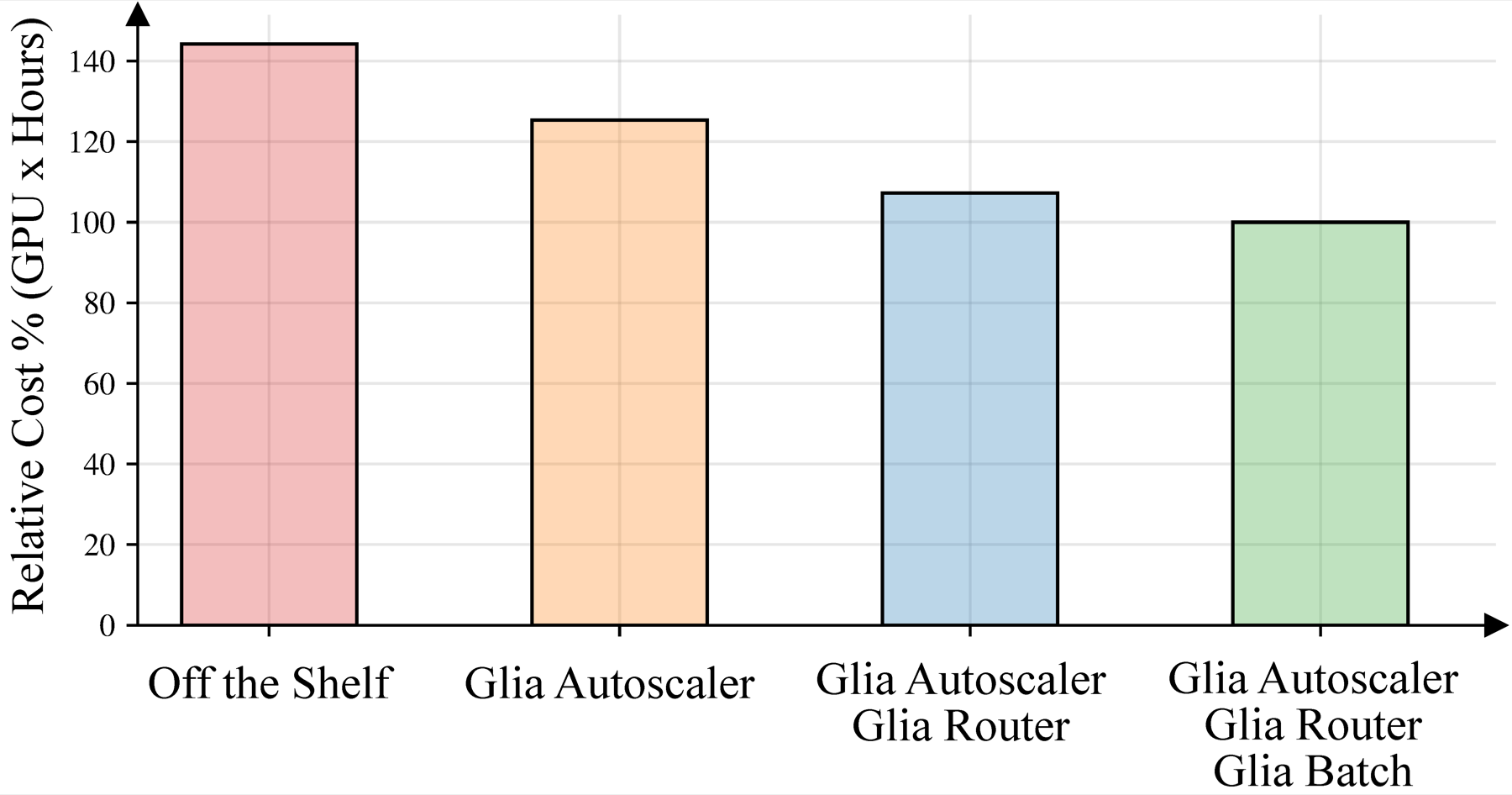
The router is one of several layers where this kind of research pays off. A human engineer has to eat and sleep; Glia doesn’t. We pointed it at other layers too: the batch scheduler and the autoscaler. Without Glia, you’d have to spend 40% more GPU-hours to serve the same work.
The takeaway
Glia’s lesson is that an AI can do systems research the way you’d train a PhD student to: hypothesize, experiment, analyze, refine. The payoff isn’t only speed (10–100× faster than human experts). It’s that the discovered designs are understandable, grounded in reasoning, and robust enough to survive contact with real hardware.
One known limit: a single Glia agent eventually fills up its context window and has to stop. The follow-up work, Engram, tackles exactly that — letting progress persist across many agents over long horizons. That’s a story for the next post.