Abstract
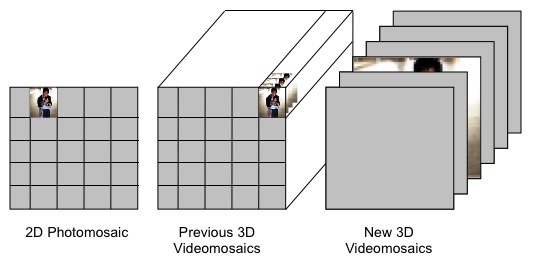
I aim to make a new type of videomosaic by replacing each frame of an input video along the time axis with a novel image found from a large database of images. Though the videomosaic is made from completely different content than the original video, the shape and movement of objects in the original video should still be evident.
Motivation

Photomosaics are appealing 2D montages that blend together technology, fine art and imagination. Is a similar concept possible in 3D? The advent of the Gist feature vector from Oliva and Torralba [1] has allowed new possibilities to find images that are similar in semantic content and layout. The introduction of the LabelMe database from Russell et al. [2] contains over 74k human labeled objects from 25k image scenes. Both of these allow for new possibilities in matching content and layout between images and the potential to make videomosaics possible.
Related Work
Previous attempts to make video mosaics have often divided the 2D image plane of the video into small squares and replaced each square with a new mini video with appropriate color and optical flow. Results of this type can be seen on Steve Martin's webpage or in the Klein et al paper on Video Mosaics [5].


I aim to create a video mosaic by a different method: dividing the video along the time axis instead of the 2D image plane axis. A project that sits in a similar space is descibed in Ronit Slyer's Flickrbooks where he attempts to morph between consecutive images.
Approach
Main idea:
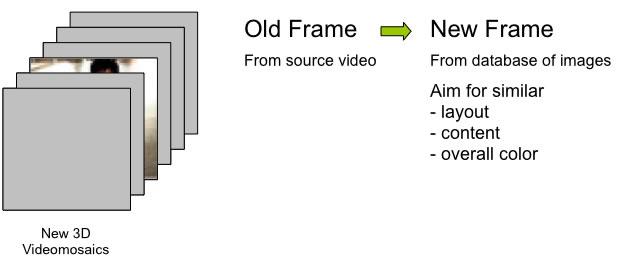
1) Gather a large database of images from Flickr and/or LabelMe
2) For each frame of an input video, choose a replacement frame from the database by finding the closest image match using either the gist feature vector, the sum of squared differences (SSD) on a 32x32 grayscale version of the image, or using labeled objects from the LabelMe database and cropping and centering the desired object.
Results
Here we present results of videomosaics found by using the gist feature vector and SSD to find replacement frames.
The gist of a scene is a scene representation introduced in [8] as a 512 length feature vector. It is found by calculating oriented filter features on a 4x4 grid of the image. In general, the gist of an image represents the spatial layout of an image; two images with similar gist vectors have similar layouts and often similar scenes.
The sum of squared difference matches are found by comparing the luminance values of a 32x32 grayscale versions of the images in the database. In general, the luminance values of each image should be normalize to average to 1(however, the example below did not take that into consideration).
These example videomosaic frames come from a database of 130k Flickr images. In order to get stronger or closer matching results the database needs to be larger (on the order of millions of images).
| Tilke input video | Gist matches | SSD matches |
| Walking input video | Gist matches |
In general what is viewable in these videomosaics is a general shape moving across the scene: the objects in the gist matches replacing the Tilke input video tend to appear and grow from left of right of the scene, and the walking videomosaic has objects that move from right to left. I call this spatial continuity. Although there is a fair amount of spatial continuity in these matches, there is little or no semantic continuity. This is particularly clear in the videomosaic of the clock below.
| Input Video | Top gist matches (no replicas allowed) | Handpicked matches |
Note that for the top gist matches of the clock shown below several of the matches are circular in shape (check the first frames individually). Even though the matches are circular, they are not clocks. Our videomosaic would be stronger if clock images were used. To test this out, I handpicked clock images from flickr for the result on the right above. The clocks are visible and understandable to a viewer, but they aren't spatially aligned. We'd really like to have both.
In order to get results that have both spatial and semantic consistency, we used the LabelMe database. This database consists of 74k human labeled objects from 25k image scenes. I query for an object (for example, 'clock') and then position and scale it as necessary.
| LabelMe 'face' | LabelME 'person walking' |
LabelME 'clock' |
LabelME 'car az90deg' |
Stronger results still can be found by combining images from LabelMe with a measure of consistency using gist. If I use the images returned from a labelMe query of 'car' alone, I end up with a sequence of cards in several different arrangements right after one another. If on the other hand I constrain image n+1 to have a similar gist feature vector to image n, then images with strong spatial consistency come after each other as seen below:

KISSR (short film)
Real footage collaged together with videomosaics to tell a simple yet universal story
Future Directions
- Use a bigger flickr database. The current examples are made with a database of 130k images. I'd like to use 6 million images instead. I will first run principle component analysis on the 6 million gist vectors to reduce their length from 512 to ~128 or fewer.
- Use better labelMe queries. LabelMe is capable of doing very specific queries such as 'car+building+road'.
applications for society and far-future impact
Videomosaics could be used as pieces of art, exhibits for museums, unique video advertisements. Other far-future applications include:
Remake homevideos
Change my crappy video into something cooler (higher resolution videomosaic of a low resolution camera video, celebrity version of a personal home video, "Be Kind, Rewind" remake of famous films). Remake videos using footage from different cultures or eras or genres of films to get a simple story in many different flavors.
Hybrid Videos
In the spirit of Aude Oliva and Antonio Torralba's hybrid images, it would be possible to make hybrid videos by merging the original video and the videomosaic remake together. Take the low frequency information from the original footage and place it with the highfrequency information from the videomosaic to create a surprising view: from far away the video looks like the original, and from upclose the video would be completely different footage.
Use input video to "drive" output video
For example, get lots of footage of a fish in an aquarium - enough that you cover the space of all possible locations and positions the fish can be. This will be the database for the videomosaic application. Then take a simple input video of some object moving - like an overhead view of a car moving through city streets. Replace each image of the car video with the closest image of the fish: the resulting videomosaic will be the fish moving in the path of the car.
Automatic stop motion animation from a home video.
On the first frame of a video, the user outlines the main objects of interest. Then the video automatically does object tracking to find calculate where the objects are flowing through the video. For the remake, a movie is made that just translates the static frame of the objects across the background with some jitteriness in a path that follows the original object motion.
Two videos in one video
Because different viewers (humans vs video camera) see videos at different frequencies, it might be possible to show separate movies to separate viewers using the temporal videomosaic principle. One video would be the primary video and is what humans would see. The other video would be interspersed in the first at a rate that makes it imperceptible to the human eye, but which would be picked up by video cameras that sample frames of the video. This could alternately be a way of sending encoded messages inside a video.
References
[1] A. Oliva, A. Torralba, The role of context in object recognition, Trends in Cognitive Sciences, vol. 11(12), pp. 520-527. December 2007.
[2] B. C. Russell, A. Torralba, K. P. Murphy, W. T. Freeman, LabelMe: a database and web-based tool for image annotation. MIT AI Lab Memo AIM-2005-025, September, 2005.
[3] J. Sivic, B Kaneva, A Torralba, S Avidan, B Freeman, Creating and Exploring a Large Photorealistic Virtual Space Presentation at Scene Understanding Symposium 2008 MIT
[4] Robert Silvers, Photomosaics, Editor Michael Hawley, Henry Holt and Company, Inc.
[5] Allison W. Klein , Tyler Grant , Adam Finkelstein , Michael F. Cohen, Video mosaics, Proceedings of the 2nd international symposium on Non-photorealistic animation and rendering, June 03-05, 2002, Annecy, France
[6] Steve Martin, Video Mosaics, Berkeley 2004, Final Project for CS283 Graduate Graphics with Prof James O'Brien, http://stevezero.com/eecs/mosaic/index.htm
[7] Ronit Slyer, Flickrbooks Final project for Computational Photography Fall 2007 CMU project page
[8] Oliva, A. and Torralba, A. (2001) Modeling the shape of the scene: a holistic representation of the spatial envelope. Int. J. Comput. Vis. 42, 145–175
Ukrainian translation provided by Viktor Kosenko