Student Research Opportunities
Contact: Xuhao Chen
We are looking for grad & undergrad students to join our lab. Feel free to reach out if you are interested in ML systems, computer architecture, parallel computing and/or databases. Our projects have the potential to become MEng thesis work. We have 6-A program opportunities available. If you are interested, please send your CV to cxh@mit.edu and fill in the recruiting form.
Where to find state-of-the-art papers? Top-tier conferences [ISCA], [VLDB], [SIGMOD] [ASPLOS], [OSDI, SOSP], [SC], [PPoPP], MICRO, HPCA.
Below are some ongoing research projects.
Scalable Vector Database [Elx Link]
Recent advances in deep learning models map almost all types of data (e.g., images, videos, documents) into high-dimension vectors. Queries on high-dimensional vectors enable complex semantic-analysis that was previously difficult if not impossible, thus they become the cornerstone for many important online services like search, eCommerce, and recommendation systems.
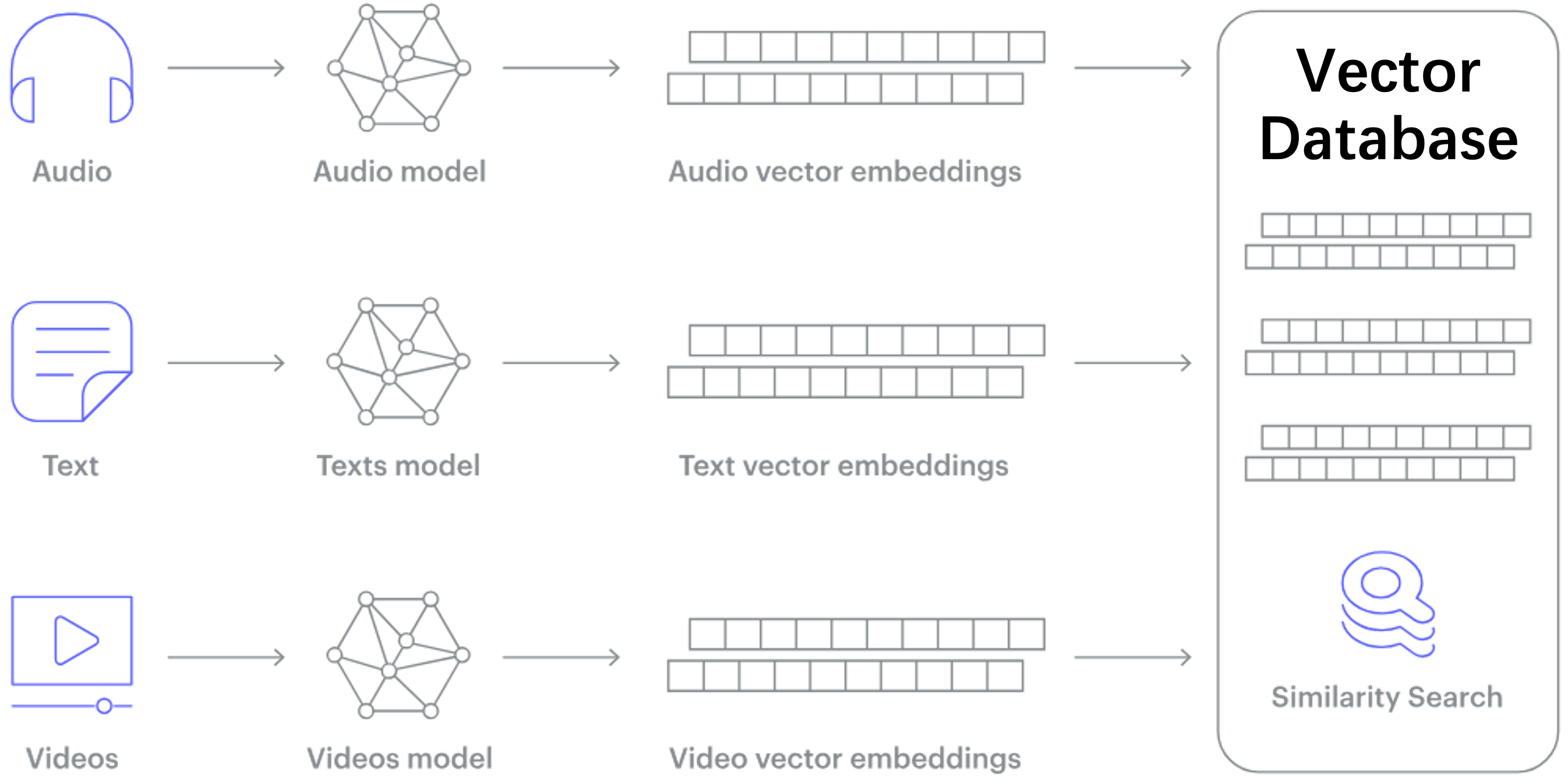
In this project we aim to build a massive-scale Vector Database on the multi-CPU and multi-GPU platform. In a Vector Database, the major operation is to search the k closest vectors to a given query vector, known as k-Nearest-Neighbor (kNN) search. Due to massive data scale, Approximate Nearest-Neighbor (ANN) search is used in practice instead. One of the most promising ANN approaches is the graph-based approach, which first constructs a proximity graph on the dataset, connecting pairs of vectors that are close to each other, then performs a graph traversal on the proximity graph for each query to find the closest vectors to a query vector. In this project we will build a vector database using graph-based ANN search algorithm that supports billion-scale datasets.
Qualifications:
- Strong programming skills in C/C++/Python language
- Experience with design and analysis of algorithms, e.g., MIT 6.1220 (previously 6.046)
- Experience with performance engineering is a plus, e.g., MIT 6.1060 (previously 6.172)
- GPU/CUDA programming is a plus
References
Zero-Knowledge Proof [Elx Link]
Zero-knowledge proof (ZKP) is a cryptographic method of proving the validity of a statement without revealing anything other than the validity of the statement itself. This “zero-knowledge” property is attractive for many privacy-preserving applications, such as blockchain and cryptocurrency systems. Despite its great potential, ZKP is notoriously compute intensive, which hampers its real-world adoption. Recent advances in cryptography, known as zk-SNARK, have brought ZKP closer to practical use. Although zk-SNARK enables fast verification of the proof, proof generation in ZKP is still quite expensive and slow.
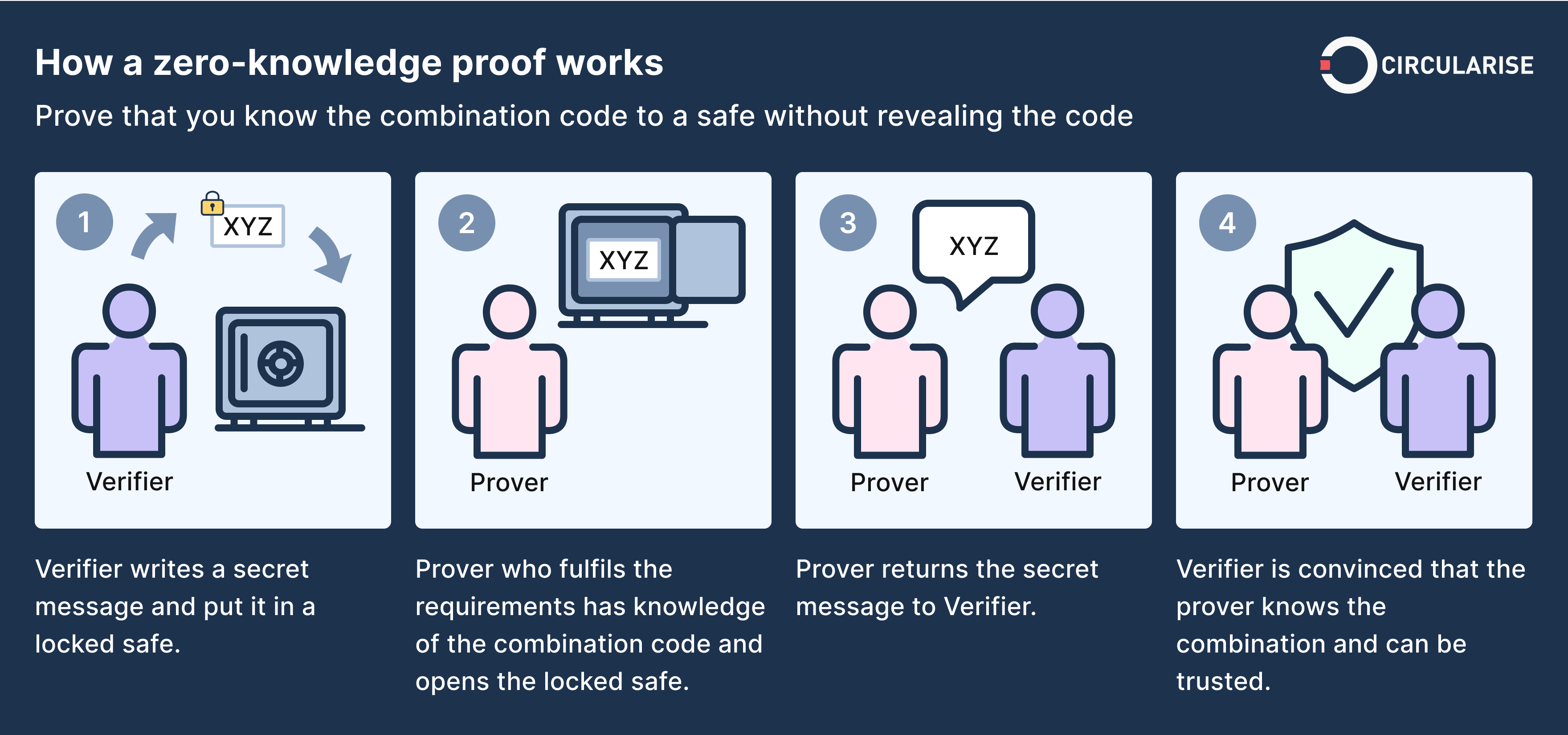
In this project, we will explore ZKP acceleration by using algorithm innovations, software performance engineering, and parallel hardware like GPU, FPGA or even ASIC. We aim to investigate and implement efficient algorithms for accelerating elliptic curve computation. We will also explore acceleration opportunities for the major operations, e.g., finite field arithmetic, Multi-scalar Multiplication (MSM) and Number-theoretic transformations (NTT).
Qualifications:
- Strong programming skills in C/C++ language
- Experience with design and analysis of algorithms, e.g., MIT 6.1220 (previously 6.046)
- Experience with performance engineering is a plus, e.g., MIT 6.1060 (previously 6.172)
- GPU/CUDA and/or Rust/Web Assembly/Javascript programming is a plus
References
- Efficient Verifiable Computation Made Easy. MEng Thesis
- Accelerating Zero-Knowledge Proofs Through Hardware-Algorithm Co-Design. MICRO 2024
- GZKP. ASPLOS 2023.
Graph AI Systems [Elx Link]
Deep Learning is good at capturing hidden patterns of Euclidean data (images, text, videos). But what about applications where data is generated from non-Euclidean domains, represented as graphs with complex relationships and interdependencies between objects? That’s where Graph AI or Graph ML come in. Handling the complexity of graph data and graph algorithms requires innovations in every layer of the computer system, including both software and hardware.

In this project we will design and build efficient graph AI systems to support scalable graph AI computing. In particular, we will build software frameworks for Graph AI and ML, e.g., graph neural networks (GNN), graph pattern mining (GPM) and graph sampling, and hardware accelerators that further enhance system efficiency and scalability.
Qualifications:
- Strong programming skills in C/C++/Python language
- Experience with design and analysis of algorithms, e.g., MIT 6.1220 (previously 6.046)
- Basic understanding of computer architecture, e.g., MIT 6.1910 (previously 6.004)
- Experience with performance engineering is a plus, e.g., MIT 6.1060 (previously 6.172)
- GPU/CUDA programming is a plus
- Familiarity with deep learning frameworks is a plus, e.g., PyTorch
References
- Efficient Systems for Large-Scale Graph Representation Learning. PhD Thesis
- gSampler. SOSP 2023 [Code]
AI/ML for Performance Engineering [Elx Link]
Generative AI, such as Large Language Models (LLMs), has been successfully used to generate computer programs, a.k.a code generation. However, its model performance degrades substantially when asked to do code optimization a.k.a. software performance engineering (SPE), i.e., generate not just correct but fast code.
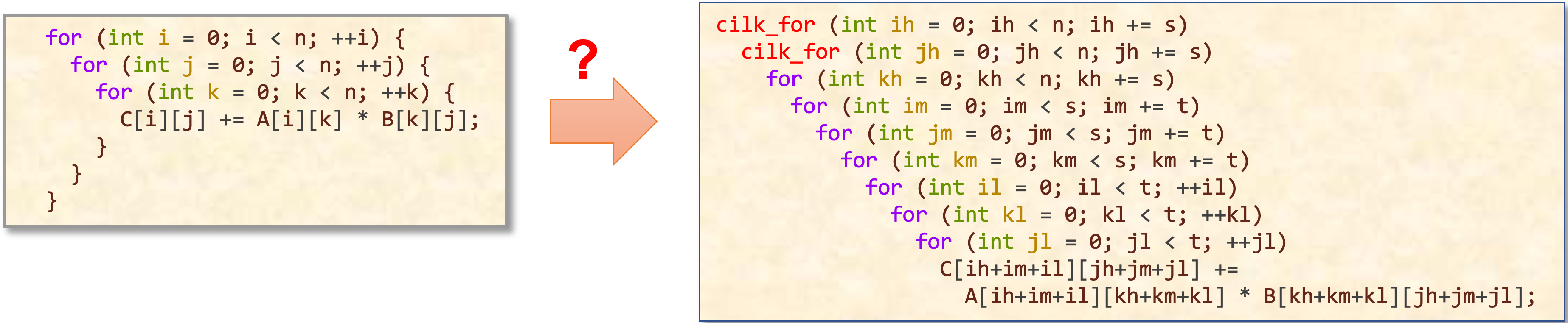
This project aims to leverage the capabilities of LLMs to revolutionize the area of automatic code optimization. We focus on transforming existing sequential code into high-performance, parallelized code, optimized for specific parallel hardware.
Qualifications:
- Strong programming skills in Python and C/C++ language
- Background and prior experience with design and analysis of algorithms (e.g., 6.046)
- Familiarity with LLMs such as ChatGPT and Code Llama
References