
News:
In January 2013, I will be joining the systems faculty in the Department of Computer Science
at the University of Chicago.
The bulk of the runtime and architecture work for the SEEC self-aware computing
project will be transitioning to Chicago with me. I will be
actively recruiting students and postdocs to work on SEEC as well as
some other projects on multicore architecture and programming.
My research on self-aware computing was just named
one of ten "World
Changing Ideas" by Scientific American . (Unfortunately the
article is behind a paywall).
Research | ( Curriculum Vitae ) |
For twelve years, my primary research interest has been making parallel computing more accessible to non-experts while balancing the oft competing concerns of performance and programmability. Doing so requires a holistic approach to computer system design in which applications, programming interfaces, runtime systems, systems software, and hardware are all considered and subject to redesign. Toward that end, I have done research on applications, programming interfaces, system software, and hardware architecture. I have worked in academia, a federally funded research laboratory, and a startup company.
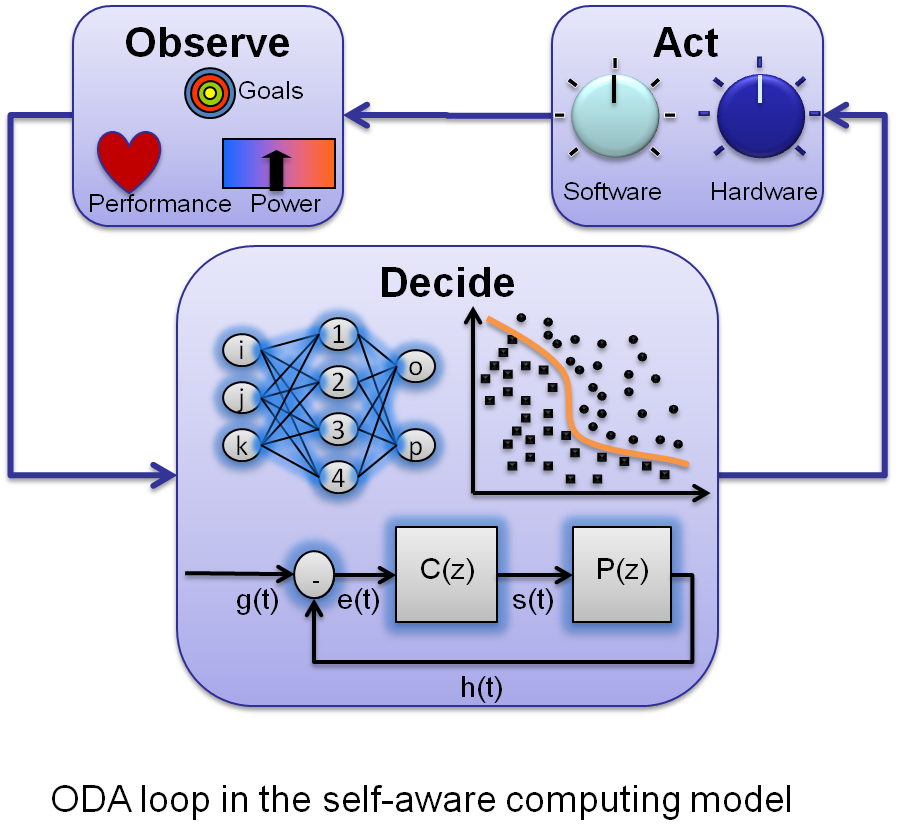
SEEC: A General and Extensible Framework for Self-Aware Computing
|
As the scale and complexity of computing systems increases,
application programmers must not only be experts in their application
domain, but also have the systems knowledge required to address the
constraints of parallelism, scale, power, energy, and reliability
concerns. SEEC proposes
a novel approach that is capable of addressing these constraints by
adding a self-awareness dimension to computational models. Self-aware
computational models automatically adjust their behavior in response
to environment stimuli to meet user specified goals. The SEEC model is
unique in that it supports a decoupled approach where applications and
systems developers separately contribute to the development of a
self-aware system, each focusing on their area of expertise. Using
SEEC, applications directly specify their goals through a standard
programming API while system components (e.g. runtime, OS, hardware, &
applications themselves) specify possible actions. Given a set of
goals and actions, SEEC uses analysis and decision engines (e.g.,
adaptive feedback control systems and machine learning) to monitor
application progress and select actions to meet goals optimally
(e.g. meeting performance goals with minimal power consumption).
A key component of SEEC, the Application Heartbeats API, was published in ICAC. Control systems used in SEEC have been published in CDC and FeBID. A system that uses SEEC to create dynamic applications was published in ASPLOS . A comparison of control and machine learning approaches to decision making was published in ICAC. Additional tech reports on SEEC are available here, here and here. Further publications are available on the project webpage. |
(project page) (SEEC is a key component of CSAIL's Angstrom Project) (SEEC listed as one of ten "World Changing Ideas" by Scientific American . The article is behind a paywall). (SEEC in the news) (SEEC in the news again) |
Code Perforation
|
Many modern computations (such as video and audio encoders, Monte
Carlo simulations, and machine learning algorithms) are designed to
trade off accuracy in return for increased performance. To date, such
computations typically use ad-hoc, domain-specific techniques
developed specifically for the computation at hand. Our research
explores a new general technique, Code Perforation,
for automatically augmenting existing computations with the capability
of trading off accuracy in return for performance. In contrast to
existing approaches, which typically require the manual development of
new algorithms, our implemented SpeedPress compiler can automatically
apply code perforation to existing computations with no developer
intervention whatsoever. The result is a transformed computation that
can respond almost immediately to a range of increased performance
demands while keeping any resulting output distortion within
acceptable user-defined bounds.
Code perforation techniques have been published in ASPLOS, OOPSLA , ICSE , and FSE (to appear 2011). The original tech report can be found here. |

(code perforation project page) (code perforation in the news) |
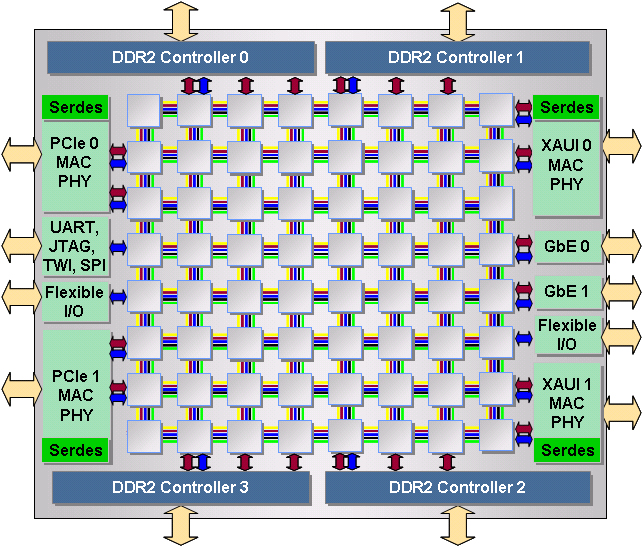
Tilera Multicore Processor
|
Tilera Corporation was founded in
December of 2004 to commercialize the technology behind MIT's Raw
Processor. I joined Tilera with a number of other Raw veterans and my
job was to serve as an internal customer -- writing application code
and providing feedback and suggestions for improvement at all levels
of Tilera's system stack, including APIs, the compiler, operating
system, device drivers, and hardware. In addition, I helped to
educate customers on Tilera technology and assist our sales and
business development teams with handling technical questions from
customers' engineering teams. Interacting with a number of different
customers inspired my research into Self-aware computing as a way to
help address programmability in complex modern computing environments.
While Tilera is a commercial venture, we published some aspects of our work on on-chip networks in IEEE Micro . In addition, at Tilera, I developed the Remote Store Programming model which is supported on Tilera products and is published in HiPEAC. Using Remote Store Programming, I implemented the BDTI OFDM Receiver Benchmark on the Tilera TILE64 processor and achieved the highest performance to date on a programmable processor (see certified results). |
(more Tilera photos) |
Raw Multicore Microprocessor
|
MIT's Raw
processor is an early multicore. While the prototype featured 16
cores, the Raw architecture is designed to scale up to 1024 cores.
This scalability is enabled by Raw's unique networks which are mapped
into the register file and allow data to be transferred from the
registers of one tile to the registers of another.
Work on Raw has been published in IEEE Micro, ISSCC, and ISCA. In addition, I developed a novel programming model designed to take advantage of Raw's unique networks and achieve scalable performance on 1024 processors. This work has been published in the Journal of Instruction Level Parallelism, BARC, ParaPLoP, and was the basis of my Master's Thesis. |

(more Raw photos) (Raw project page) |
Parallel Design Patterns
|
While TAing Comp 6.846 (Parallel Computing) I became interested in
design patterns of parallel software development as a tool for both
software engineering and teaching. Existing parallel patterns have
tremendous descriptive power, but it is often unclear to non-experts
how to choose a pattern based on the specific performance goals of a
given application. This work addresses the need for a pattern
selection methodology by presenting four patterns and an accompanying
decision framework for choosing from these patterns given an
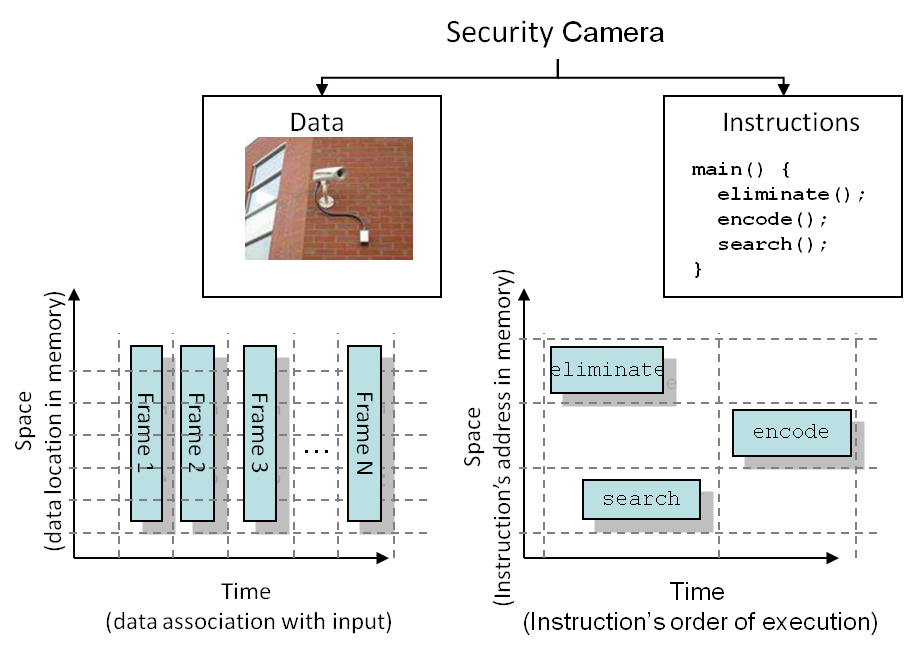
application's throughput and latency goals. The patterns are based on
recognizing that one can partition an application's data or
instructions and that these partitionings can be done in time or
space, hence we refer to them as spatiotemporal partitioning
strategies. This work introduces a taxonomy that describes each of the
resulting four partitioning strategies and presents a three-step
methodology for selecting one or more given a throughput and latency
goal.
This work has appeared in the first two editions of the ParaPLoP workshop including the original description of the four spatiotemporal partitioning strategies and a pattern for exploiting multicores with a scalar-operand network . A revised version of the partitioning strategies paper was presented at PDCS . A methodology for selecting patterns based on user performance goals was recently accepted to IEEE Transactions on Parallel and Distributed Systems . |
(project page) |
PVL/VSIPL++
|
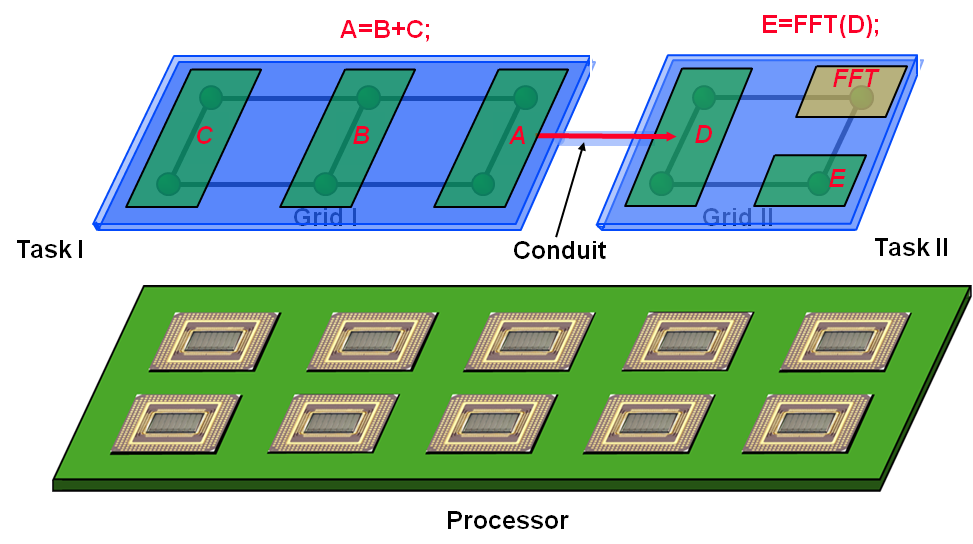
The parallel vector library, or PVL, is designed to ease the burden of
programming high-performance, parallel signal processing applications
such as radar systems. PVL supports both data and task distribution
through the use of a Map. Data objects, like vectors and matrices,
can be assigned a map which describes how the data should be assigned
to cores. In addition, PVL supports Task objects which can also be
mapped. One unique feature of PVL is that the process of writing
applications is separate from the process of mapping them, so maps can
be changed from one run to the next without recompiling the
application. PVL later served as the basis for the VSIPL++ standard
(which no longer looks much like PVL, unfortunately).
PVL was developed at MIT Lincoln Laboratory. PVL was originally published at HPEC. Software fault recovery mechanisms in PVL were published in the SIAM conference on parallel processing. A system for automatically generating maps in PVL programs was published at a later HPEC. An early paper describing VSIPL++ was published in the Proceedings of the IEEE. |
|
pMapper
|
The design of the PVL interface later served as the basis for MIT
Lincoln Laboratory's Parallel MATLAB. Like PVL, Parallel MATLAB is
designed to separate the process of writing parallel code from the
process of mapping, or assigning resources, to that code. The pMapper
project is designed to automatically find an optimal mapping for a
given Parallel MATLAB program. The key insight in the pMapper project
is to use lazy evaluation of parallel MATLAB codes. Instead of
executing functional blocks, pMapper computes a directed acyclic graph
representing the Parallel MATLAB program. When a user requests that a
Parallel MATLAB object be displayed to the screen or printed to a
file, pMapper assigns resources to all nodes in the graph and then
executes it.
The pMapper project was published in Cluster Computing, HPEC, and the DoD User's Group Conference. The key technology behind pMapper is patented. |
|
Teaching
6.846 Parallel Computing
6.846 teaches
parallel computing using a holistic approach. The course begins with
a discussion of applications and parallelism within an application.
Subsequent lectures cover programming APIs and the hardware mechanisms
used to implement and support those APIs. I TA'd this course when it
was taught for the first time in six years. I was responsible for
writing and grading the homework assignments and developing and
evaluating the final project. We used the Tilera TILE64 processor to
teach the class and I created a great deal of supplemental course
material describing the use of that architecture. In addition, I
taught several lectures on the design and implementation of the TILE
processor, design patterns for parallel computing, and parallelizing
video encoding applications.
Steppingstone FoundationVolunteer Tutor, 2007-2008
Education
|