Time-Constrained Photography
Samuel W. Hasinoff, Kiriakos N. Kutulakos, Frédo Durand, and William T. Freeman


Samuel W. Hasinoff, Kiriakos N. Kutulakos, Frédo Durand, and William T. Freeman, Time-Constrained Photography. Proc. 12th IEEE International Conference on Computer Vision, ICCV 2009, pp. 333-340 [pdf]
Kiriakos N. Kutulakos and Samuel W. Hasinoff, Focal Stack Photography: High-Performance Photography with a Conventional Camera. Proc. 11th IAPR Conference on Machine Vision Applications, MVA 2009, pp. 332-337 (invited paper). [pdf]
Samuel W. Hasinoff, Variable-Aperture Photography.
PhD Thesis, University of Toronto, Dept. of Computer Science, 2008.
[pdf]
Alain Fournier Ph.D. Thesis Award
General notes
The photos below are in 16-bit PNG format and are linear (γ=1). Note that the underexposed input may appear completely black (or be posterized when rescaled) unless a suitable viewer such as Adobe Photoshop or MATLAB is used.
Image restoration under a time budget (Fig.4)



- DOF spanned by a 13-photo focal stack with a standard camera
- time budget of T=0.1Topt (1/130 of the time for an ideally-exposed focus stack)
- ground truth - in-focus, ideally-exposed image
- standard camera, 1 photo - input 1, restoration result (17.5 dB)
- standard camera, 30 photos - input 1, 2, 3, ... 10, ... 20, ... 30, restoration result (20.1 dB)
- standard camera, Nopt=8 photos - input 1, 2, 3, 4, 5, 6, 7, 8, restoration result (21.8 dB)
- wavefront coding, Nopt=2 photos - input 1, 2, restoration result (22.2 dB)
- upper bound, Nopt=1 photo - input 1, restoration result (26.2 dB)
Image restoration with unknown depth (Fig. 5)





- DOF spanned by a 13-photo focal stack with a standard camera
- time budget of T=0.1Topt (1/130 of the time for an ideally-exposed focus stack)
- ground truth - source layers 1, 2, 3, depth map, in-focus, ideally-exposed image
- standard camera, Nopt=8 photos - input 1, 2, 3, 4, 5, 6, 7, 8
Experiments with real photos
Common experimental setup:Printed advertisement (scene from Fig. 8)
- Canon 1D Mark III with a Canon EF 85mm f1.2L II lens, using an f/1.2 aperture
- DOF of [95,98]cm approximately spanned by a 13-photo focal stack
- scene prior parameter set to α=6.0e3/ymax
- dim room with Topt=1/20s




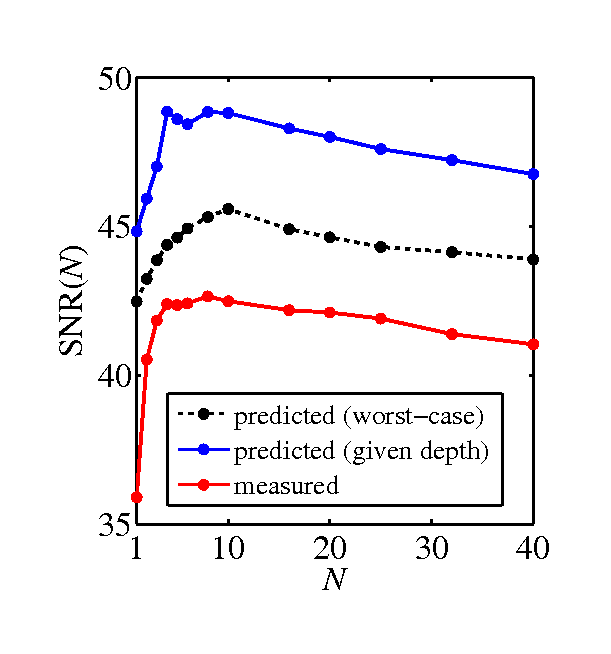
Bottles and spices, covered in text [new]
- planar scene at worst-case depth of 95cm
- ground truth in-focus, ideally-exposed image, and known depth
- time budget of T=Topt (1/13 of the time for an ideally-exposed focus stack)
- time budget of T=0.1Topt (1/130 of the time for an ideally-exposed focus stack)
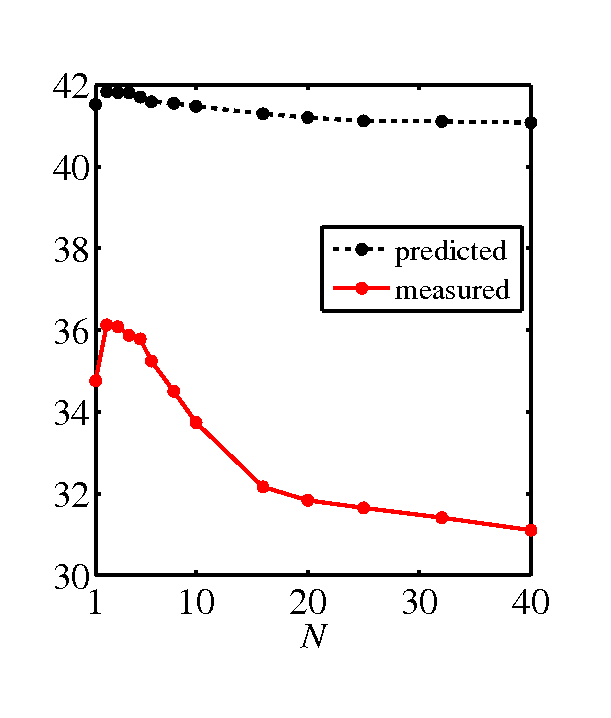
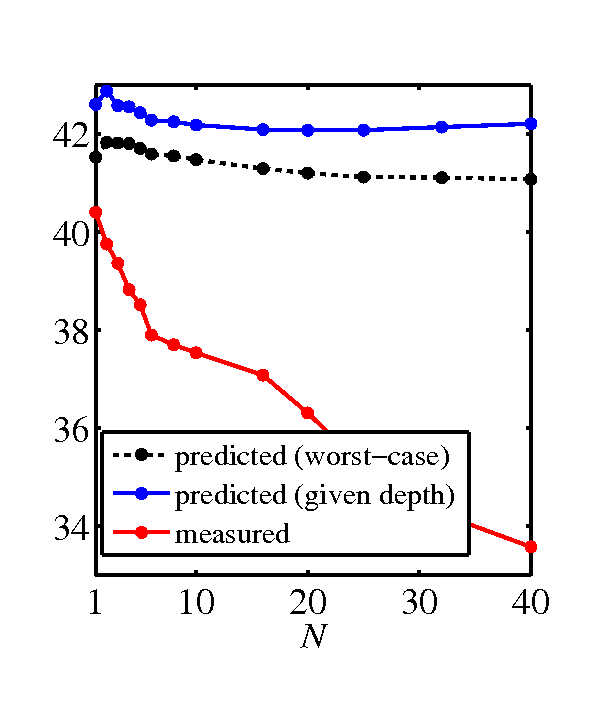
- SNR graphs, predicted by the model and measured
- Nopt=2 photos - input 1, 2, restoration result (36.1 dB), estimated depth



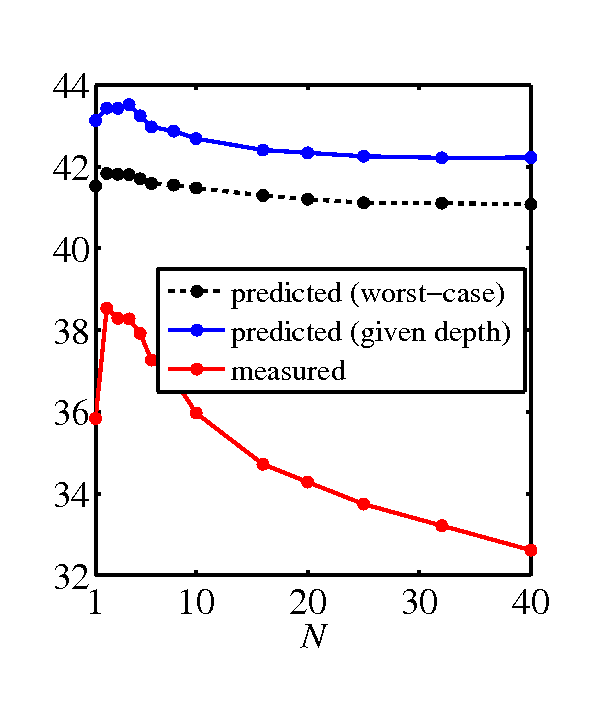
Bigfoot figurine head [new]
- ground truth in-focus, ideally-exposed image, and depth-from-focus
- time budget of T=Topt (1/13 of the time for an ideally-exposed focus stack)
- time budget of T=0.1Topt (1/130 of the time for an ideally-exposed focus stack)
- SNR graphs, predicted by the model and measured
- Nopt=2 photos - input 1, 2, restoration result (38.5 dB), estimated depth



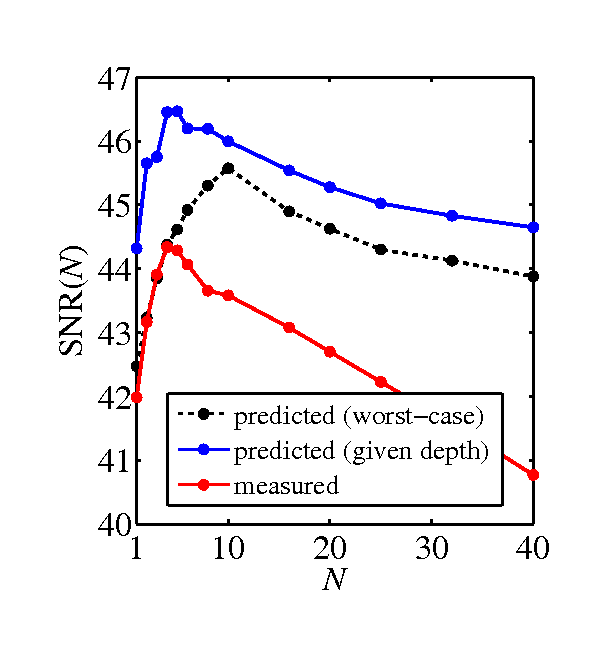
- ground truth in-focus, ideally-exposed image, and depth-from-focus
- time budget of T=Topt (1/13 of the time for an ideally-exposed focus stack)
- time budget of T=0.1Topt (1/130 of the time for an ideally-exposed focus stack)
- SNR graphs, predicted by the model and measured
- Nopt=2 photos - input 1, 2, restoration result (39.8 dB), estimated depth
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}