
Presented at 2010 IEEE CVPR
Massachusetts Institute of Technology
| |
![]()
There has been a growing interest in exploiting contextual information in addition to local features to detect and localize multiple object categories in an image. Context models can efficiently rule out some unlikely combinations or locations of objects and guide detectors to produce a semantically coherent interpretation of a scene. However, the performance benefit from using context models has been limited because most of these methods were tested on datasets with only a few object categories, in which most images contain only one or two object categories. In this paper, we introduce a new dataset with images that contain many instances of different object categories and propose an efficient model that captures the contextual information among more than a hundred of object categories. We show that our context model can be applied to scene understanding tasks that local detectors alone cannot solve.
![]()
![]()
Download the entire package sun09_hcontext.tar (8.7GB) or download each part separately from below.
Benchmark 1. For evaluation of a general object recognition system.
Download all images (.jpg) and annotations (.xml) in the SUN 09 dataset : sun09.tar (5.2GB)
- static_sun09_database: 12,000 annotated images
- static_sun_objects: additional images to train baseline detectors (not used to train the context model)
- out_of_context: 42 out-of-context images
Benchmark 2. For evaluation of a context model with precomputed baseline detector outputs.
One important source of variation among context-based models is the performance difference of the baseline detectors. Here we provide a precomputed set of detector outputs on a fixed train/test split so that context models can be evaluated using the same baseline detectors. We use the baseline detectors by [Felzenszwalb et al.].
Download baseline detector outputs in text files (.txt): detectorOutputsText.tar.gz (3.3GB)
- The file names correspond to [(test/train)/objectCategory/imageName.txt]
- Each line in the text file shows the bounding box locations and scores for one candidate window: [x1 y1 x2 y2 score]
- We use 4,367 training images and 4,317 test images. Each set has the same number of images per scene category.
Download baseline detector outputs in MATLAB files (.mat): datasetMat.tar (159MB)
- Load sun09_detectorOutputs.mat for baseline detector outputs and sun09_groundTruth.mat for ground-truth annotations.
See [README] for detailed instructions.Code MATLAB implementation of our hierarchical context model
Download hcontext_code.tar (0.4MB). This tarball only contains MATLAB scripts, and to run the code, you need to download the data file below.
Data SUN 09 dataset, baseline detector outputs, and pre-trained context models stored as MATLAB files (.mat)
Download datasetMat.tar (159MB). This file does not include images, so if you would like to display the detection results on images, you need to download sun09.tar (5.2GB) as well.
Precomputed results Results published in CVPR 2010 with 107 object categories.
Download results_cvpr10.mat (165MB). Load the file and run scripts/eval_performance.m to display the figures in the paper.
![]()
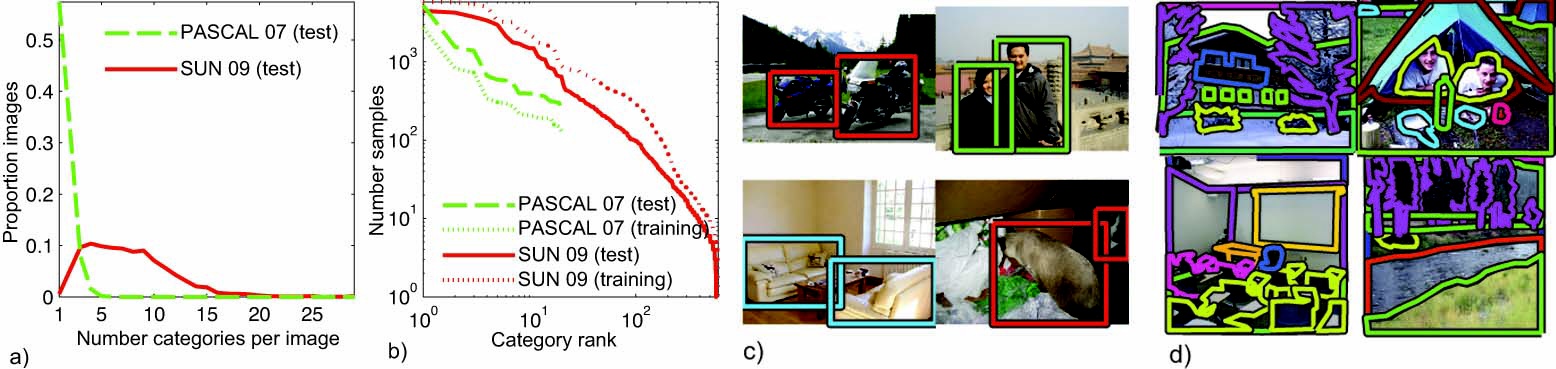
We introduce a new dataset (SUN 09) suitable for leveraging the contextual information. The dataset contains 12.000 annotated images covering a large number of scene categories (indoor and outdoors) with more than 200 object categories and 152.000 annotated object instances.
 |
![]()
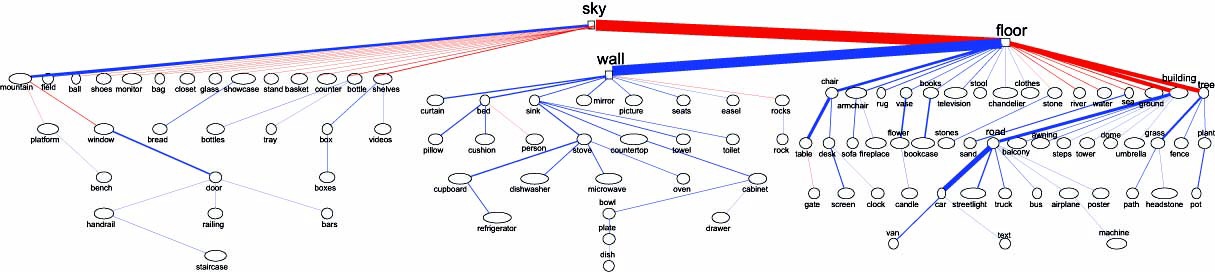
We use a tree-structured graphical model to learn dependencies among object categories. Our context model incorporates object dependencies, global image features, and outputs of local detectors into one probabilistic framework.
 |
 |
![]()
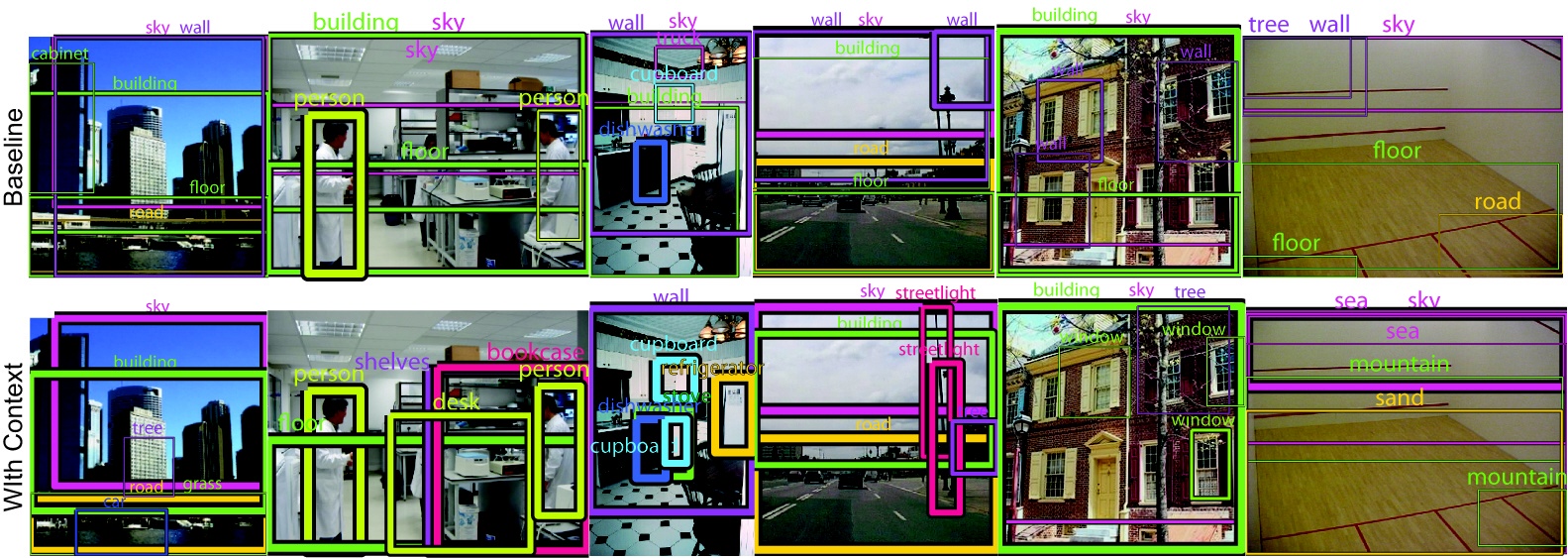
The figure below shows some images with one or more objects in an unusual setting such as scale, position, or scene. Objects that are out-of-context generally have different appearances or viewpoints from typical training examples, making local detectors perform poorly. Even if we have perfect local detectors, or ground-truth labels, we need contextual information to identify out-of-context scenes, which is not available from local detector outputs. The segments show the objects selected by the contextual model (the input of the system are the true segmentations and labels, and the model task is to select which objects are out of context).
 |
![]()
The authors would like to thank Taeg Sang Cho for helpful discussions and feedback. This research was partially funded by Shell International Exploration and Production Inc., by Army Research Office under award W911NF-06-1-0076, by NSF Career Award (ISI 0747120), and by the Air Force Office of Scientific Research under Award No.FA9550-06-1-0324. Any opinions, findings, and conclusions or recommendations expressed in this publication are those of the author(s) and do not necessarily reflect the views of the Air Force.
![]()
Last update: May 27. 2010