Complete Publications
Recent Publications/Preprints
- Giannis Daras, Adrian Rodriguez-Munoz, Adam Klivans, Antonio Torralba, Constantinos Daskalakis: Ambient Diffusion Omni: Training Good Models with Bad Data.
In the 39th Annual Conference on Neural Information Processing Systems (NeurIPS), NeurIPS 2025. Spotlight. arXiv.
- Giannis Daras, Jeffrey Ouyang-Zhang, Krithika Ravishankar, William Daspit, Costis Daskalakis, Qiang Liu, Adam Klivans, Daniel J. Diaz: Ambient Proteins: Training Diffusion Models on Low Quality Structures.
In the 39th Annual Conference on Neural Information Processing Systems (NeurIPS), NeurIPS 2025. Spotlight. bioarXiv.
- Vardis Kandiros, Charilaos Pipis, Constantinos Daskalakis, Christopher Harshaw: The Conflict Graph Design: Estimating Causal Effects under Arbitrary Neighborhood Interference.
Under Submission, 2024. arXiv.
- Constantinos Daskalakis, Vardis Kandiros, Rui Yao: Learning Gaussian DAG Models without Condition Number Bounds.
In the 42nd International Conference on Machine Learning, ICML 2025. PDF.
- Yuval Dagan, Constantinos Daskalakis, Maxwell Fishelson, Noah Golowich, Robert Kleinberg, Princewill Okoroafor: Breaking the T^2/3 Barrier for Sequential Calibration.
In the 57th ACM Symposium on Theory of Computing, STOC 2025. arXiv. Invited to the Special Issue.
- Constantinos Daskalakis, Gabriele Farina, Maxwell Fishelson, Charilaos Pipis, Jon Schneider: Efficient Learning and Computation of Linear Correlated Equilibrium in General Convex Games.
In the 57th ACM Symposium on Theory of Computing, STOC 2025. arXiv.
- Giannis Daras, Yeshwanth Cherapanamjeri, Constantinos Daskalakis: How much is a noisy image worth? Data Scaling Laws for Ambient Diffusion.
In the 13th International Conference on Learning Representations, ICLR 2025. arXiv.
- Arnab Bhattacharyya, Constantinos Daskalakis, Themis Gouleakis, Yuhao Wang: Learning High-dimensional Gaussians from Censored Data.
In the 28th International Conference on Artificial Intelligence and Statistics, AISTATS 2025. arXiv.
- Constantinos Daskalakis, Ian Gemp, Yanchen Jiang, Renato Paes Leme, Christos Papadimitriou, Georgios Piliouras: Charting the Shapes of Stories with Game Theory.
In the 38th Annual Conference on Neural Information Processing Systems (NeurIPS), NeurIPS 2024, Creative Track. arXiv.
- Yang Cai, Constantinos Daskalakis, Haipeng Luo, Chen-Yu Wei, Weiqiang Zheng: On Tractable Φ-Equilibria in Non-Concave Games.
In the 38th Annual Conference on Neural Information Processing Systems (NeurIPS), NeurIPS 2024. arXiv.
- Angelos Assos, Yuval Dagan, Constantinos Daskalakis: Maximizing utility in multi-agent environments by anticipating the behavior of other learners.
In the 38th Annual Conference on Neural Information Processing Systems (NeurIPS), NeurIPS 2024. arXiv.
- Fan Chen, Constantinos Daskalakis, Noah Golowich, Alexander Rakhlin: Near-Optimal Learning and Planning in Separated Latent MDPs.
In the 36th Annual Conference on Learning Theory, COLT 2024. arXiv.
- Constantinos Daskalakis, Noah Golowich: Is Efficient PAC Learning Possible with an Oracle That Responds "Yes" or "No"?
In the 36th Annual Conference on Learning Theory, COLT 2024. arXiv.
- Giannis Daras, Alex Dimakis, Constantinos Daskalakis: Consistent Diffusion Meets Tweedie: Training Exact Ambient Diffusion Models with Noisy Data.
In the 41st International Conference on Machine Learning, ICML 2024. arXiv. twitter summary
- Yuval Dagan, Constantinos Daskalakis, Maxwell Fishelson, Noah Golowich: From External to Swap Regret 2.0: An Efficient Reduction and Oblivious Adversary for Large Action Spaces.
In the 56th ACM Symposium on Theory of Computing, STOC 2024. Invited to the Special Issue. arXiv. twitter summary
- Constantinos Daskalakis, Noah Golowich, Nika Haghtalab, Abhishek Shetty: Smooth Nash Equilibria: Algorithms and Complexity.
In the 15th Innovations in Theoretical Computer Science (ITCS), ITCS 2024. arXiv.
- Giannis Daras, Yuval Dagan, Alexandros G. Dimakis, Constantinos Daskalakis: Consistent Diffusion Models: Mitigating Sampling Drift by Learning to be Consistent.
In the 37th Annual Conference on Neural Information Processing Systems (NeurIPS), NeurIPS 2023. arXiv.
- Angelos Assos, Idan Attias, Yuval Dagan, Constantinos Daskalakis, Maxwell Fishelson: Online Learning and Solving Infinite Games with an ERM Oracle.
In the 35th Annual Conference on Learning Theory, COLT 2023. arXiv.
- Constantinos Daskalakis, Noah Golowich, Stratis Skoulakis, Manolis Zampetakis: STay-ON-the-Ridge: Guaranteed Convergence to Local Minimax Equilibrium in Nonconvex-Nonconcave Games.
In the 35th Annual Conference on Learning Theory, COLT 2023. arXiv.
- Constantinos Daskalakis, Noah Golowich, Kaiqing Zhang: The Complexity of Markov Equilibrium in Stochastic Games.
In the 35th Annual Conference on Learning Theory, COLT 2023. arXiv.
- Davin Choo, Yuval Dagan, Constantinos Daskalakis, Anthimos-Vardis Kandiros: Learning and Testing Latent-Tree Ising Models Efficiently.
In the 35th Annual Conference on Learning Theory, COLT 2023. arXiv.
- Yeshwanth Cherapanamjeri, Constantinos Daskalakis, Andrew Ilyas, Manolis Zampetakis: What Makes A Good Fisherman? Linear Regression under Self-Selection Bias.
In the 55th ACM Symposium on Theory of Computing, STOC 2023. arXiv.
- Giannis Daras, Yuval Dagan, Alex Dimakis, Constantinos Daskalakis: Score-Guided Intermediate Level Optimization: Fast Langevin Mixing for Inverse Problems.
In the 39th International Conference on Machine Learning, ICML 2022. arXiv.
- Yuval Dagan, Vardis Kandiros, Constantinos Daskalakis: EM's Convergence in Gaussian Latent Tree Models.
In the 35th Annual Conference on Learning Theory, COLT 2022. arXiv.
- Yang Cai, Constantinos Daskalakis: Recommender Systems meet Mechanism Design.
In the 23rd ACM Conference on Economics and Computation, EC 2022. arXiv.
- Yeshwanth Cherapanamjeri, Constantinos Daskalakis, Andrew Ilyas, Manolis Zampetakis: Estimation of Standard Auction Models.
In the 23rd ACM Conference on Economics and Computation, EC 2022. arXiv.
- Constantinos Daskalakis, Noah Golowich: Fast Rates for Nonparametric Online Learning: From Realizability to Learning in Games.
In the 54th ACM Symposium on Theory of Computing, STOC 2022. arXiv.
- Ioannis Anagnostides, Constantinos Daskalakis, Gabriele Farina, Maxwell Fishelson, Noah Golowich, Tuomas Sandholm: Near-Optimal No-Regret Learning for Correlated Equilibria in Multi-Player General-Sum Games.
In the 54th ACM Symposium on Theory of Computing, STOC 2022. arXiv.
- Constantinos Daskalakis, Petros Dellaportas, Ares Panos: How Good are Low-Rank Approximations in Gaussian Process Regression?
In the 36th AAAI Conference on Artificial Intelligence (AAAI), AAAI 2022. arXiv.
- Constantinos Daskalakis, Maxwell Fishelson, Noah Golowich: Near-Optimal No-Regret Learning in General Games.
In the 35th Annual Conference on Neural Information Processing Systems (NeurIPS), NeurIPS 2021. Oral. arXiv. twitter summary
- Constantinos Daskalakis, Patroklos Stefanou, Rui Yao, Manolis Zampetakis: Efficient Truncated Linear Regression with Unknown Noise Variance.
In the 35th Annual Conference on Neural Information Processing Systems (NeurIPS), NeurIPS 2021. arXiv.
- Yuval Dagan, Constantinos Daskalakis, Nishanth Dikkala, Surbhi Goel, Anthimos Vardis Kandiros: Statistical Estimation from Dependent Data.
In the 38th International Conference on Machine Learning, ICML 2021. arXiv.
- Constantinos Daskalakis, Vasilis Kontonis, Christos Tzamos, Manolis Zampetakis: A Statistical Taylor Theorem and Extrapolation of Truncated Densities.
In the 34th Annual Conference on Learning Theory, COLT 2021. arXiv.
- Constantinos Daskalakis, Qinxuan Pan: Sample-Optimal and Efficient Learning of Tree Ising models.
In the 53rd ACM Symposium on Theory of Computing, STOC 2021. arXiv. twitter summary
- Constantinos Daskalakis, Stratis Skoulakis, Manolis Zampetakis: The Complexity of Constrained Min-Max Optimization.
In the 53rd ACM Symposium on Theory of Computing, STOC 2021. arXiv. twitter summary
- Yuval Dagan, Constantinos Daskalakis, Nishanth Dikkala, Anthimos Vardis Kandiros: Learning Ising Models from One or Multiple Samples.
In the 53rd ACM Symposium on Theory of Computing, STOC 2021. arXiv. twitter summary
- Jelena Diakonikolas, Constantinos Daskalakis, Michael I. Jordan: Efficient Methods for Structured Nonconvex-Nonconcave Min-Max Optimization.
In the 24th International Conference on Artificial Intelligence and Statistics (AISTATS), AISTATS 2021. arXiv
- Mucong Ding, Constantinos Daskalakis, Soheil Feizi: GANs with Conditional Independence Graphs: On Subadditivity of Probability Divergences.
In the 24th International Conference on Artificial Intelligence and Statistics (AISTATS), AISTATS 2021. Oral. arXiv
- Fotini Christia, Michael Curry, Constantinos Daskalakis, Erik Demaine, John P. Dickerson, MohammadTaghi Hajiaghayi, Adam Hesterberg, Marina Knittel, Aidan Milliff: Scalable Equilibrium Computation in Multi-agent Influence Games on Networks.
In the 34th AAAI Conference on Artificial Intelligence, AAAI 2021. arXiv
- Noah Golowich, Sarath Pattathil, Constantinos Daskalakis: Tight last-iterate convergence rates for no-regret learning in multi-player games.
In the 34th Annual Conference on Neural Information Processing Systems (NeurIPS), NeurIPS 2020. arXiv
- Constantinos Daskalakis, Dylan Foster, Noah Golowich: Independent Policy Gradient Methods for Competitive Reinforcement Learning.
In the 34th Annual Conference on Neural Information Processing Systems (NeurIPS), NeurIPS 2020. arXiv
- Constantinos Daskalakis, Dhruv Rohatgi, Manolis Zampetakis: Truncated Linear Regression in High Dimensions.
In the 34th Annual Conference on Neural Information Processing Systems (NeurIPS), NeurIPS 2020. arXiv
- Constantinos Daskalakis, Dhruv Rohatgi, Manolis Zampetakis: Constant-Expansion Suffices for Compressed Sensing with Generative Priors.
In the 34th Annual Conference on Neural Information Processing Systems (NeurIPS), NeurIPS 2020. Spotlight. arXiv
- Constantinos Daskalakis, Manolis Zampetakis: More Revenue from Two Samples via Factor Revealing SDPs.
In the 21st ACM Conference on Economics and Computation, EC 2020. pdf
- Constantinos Daskalakis, Maxwell Fishelson, Brendan Lucier, Vasilis Syrgkanis, Santhoshini Velusamy: Simple, Credible, and Approximately-Optimal Auctions.
In the 21st ACM Conference on Economics and Computation, EC 2020. arXiv
- Johannes Brustle, Yang Cai, Constantinos Daskalakis: Multi-Item Mechanisms without Item-Independence: Learnability via Robustness.
In the 21st ACM Conference on Economics and Computation, EC 2020. arXiv
- Qi Lei, Jason D. Lee, Alexandros G. Dimakis, Constantinos P. Daskalakis: SGD Learns One-Layer Networks in WGANs.
In the 37th International Conference on Machine Learning, ICML 2020. arXiv
- Noah Golowich, Sarath Pattathil, Constantinos Daskalakis, Asuman Ozdaglar: Last Iterate is Slower than Averaged Iterate in Smooth Convex-Concave Saddle Point Problems.
In the 33rd Annual Conference on Learning Theory, COLT 2020. arXiv
- Constantinos Daskalakis, Nishanth Dikkala, Ioannis Panageas: Logistic regression with peer-group effects via inference in higher-order Ising models.
In the 23rd International Conference on Artificial Intelligence and Statistics, AISTATS 2020. arXiv.
- Constantinos Daskalakis, Andrew Ilyas, Manolis Zampetakis: A Theoretical and Practical Framework for Regression and Classification from Truncated Samples.
In the 23rd International Conference on Artificial Intelligence and Statistics, AISTATS 2020. pdf.
- Constantinos Daskalakis, Themis Gouleakis, Christos Tzamos, Manolis Zampetakis: Computationally and Statistically Efficient Truncated Regression.
In the 32nd Annual Conference on Learning Theory, COLT 2019. arXiv.
- Yuval Dagan, Constantinos Daskalakis, Nishanth Dikkala, Siddhartha Jayanti: Generalization and learning under Dobrushin's condition.
In the 32nd Annual Conference on Learning Theory, COLT 2019. arXiv.
- Constantinos Daskalakis, Nishanth Dikkala, Ioannis Panageas: Regression from Dependent Observations.
In the 51st Annual ACM Symposium on the Theory of Computing, STOC 2019. arXiv
- Ajil Jalal, Andrew Ilyas, Constantinos Daskalakis, Alexandros G. Dimakis: The Robust Manifold Defense: Adversarial Training using Generative Models. arXiv, 2019.
- Constantinos Daskalakis, Ioannis Panageas: Last-Iterate Convergence: Zero-Sum Games and Constrained Min-Max Optimization.
In the 10th Innovations in Theoretical Computer Science (ITCS) conference, ITCS 2019. arXiv.
- Constantinos Daskalakis, Ioannis Panageas: The Limit Points of (Optimistic) Gradient Descent in Min-Max Optimization.
In the 32nd Annual Conference on Neural Information Processing Systems (NeurIPS), NeurIPS 2018. arXiv.
- Constantinos Daskalakis, Nishanth Dikkala, Siddhartha Jayanti: HOGWILD!-Gibbs can be PanAccurate.
In the 32nd Annual Conference on Neural Information Processing Systems (NeurIPS), NeurIPS2018. arXiv.
- Nima Anari, Constantinos Daskalakis, Wolfgang Maass, Christos Papadimitriou, Amin Saberi, Santosh Vempala: Smoothed Analysis of Discrete Tensor Decomposition and Assemblies of Neurons.
In the 32nd Annual Conference on Neural Information Processing Systems (NeurIPS), NeurIPS 2018. arXiv.
- Jayadev Acharya, Arnab Bhattacharyya, Constantinos Daskalakis, Saravanan Kandasamy: Learning and Testing Causal Models with Interventions.
In the 32nd Annual Conference on Neural Information Processing Systems (NeurIPS), NeurIPS 2018. arXiv.
- Constantinos Daskalakis, Themis Gouleakis, Christos Tzamos, Manolis Zampetakis: Efficient Statistics, in High Dimensions, from Truncated Samples.
In the 59th Annual IEEE Symposium on Foundations of Computer Science, FOCS 2018. arXiv.
- Shipra Agrawal, Constantinos Daskalakis, Vahab Mirrokni, Balasubramanian Sivan: Robust Repeated Auctions under Heterogeneous Buyer Behavior.
In the 19th ACM conference on Economics and Computation, EC 2018. arXiv.
- Constantinos Daskalakis, Nishanth Dikkala, Nick Gravin: Testing Symmetric Markov Chains from a Single Trajectory.
In the 31st Annual Conference on Learning Theory, COLT 2018. arXiv.
- Constantinos Daskalakis, Christos Tzamos, Manolis Zampetakis: Bootstrapping EM via EM and Convergence Analysis in the Naive Bayes Model.
In the 21st International Conference on Artificial Intelligence and Statistics, AISTATS 2018. pdf
- Constantinos Daskalakis, Andrew Ilyas, Vasilis Syrgkanis, Haoyang Zeng: Training GANs with Optimism.
In the 6th International Conference on Learning Representations, ICLR 2018. arXiv.
- Constantinos Daskalakis, Christos Tzamos and Manolis Zampetakis: A Converse to Banach's Fixed Point Theorem and its CLS Completeness.
In the 50th Annual ACM Symposium on the Theory of Computing, STOC 2018. arXiv
- Constantinos Daskalakis, Gautam Kamath and John Wright: Which Distribution Distances are Sublinearly Testable?.
In the 29th Annual ACM-SIAM Symposium on Discrete Algorithms, SODA 2018. arXiv
- Constantinos Daskalakis, Nishanth Dikkala and Gautam Kamath: Testing Ising Models
In the 29th Annual ACM-SIAM Symposium on Discrete Algorithms, SODA 2018. arXiv
Journal version in IEEE Transactions on Information Theory, 65(11): 6829-6852, 2019. ieee
- Constantinos Daskalakis, Nishanth Dikkala and Gautam Kamath: Concentration of Multilinear Functions of the Ising Model with Applications to Network Data.
In the 31st Annual Conference on Neural Information Processing Systems (NeurIPS), NeurIPS 2017. arXiv
- Yang Cai and Constantinos Daskalakis: Learning Multi-Item Auctions with (or without) Samples.
In the 58th IEEE Symposium on Foundations of Computer Science (FOCS), FOCS 2017. arxiv
- Constantinos Daskalakis and Yasushi Kawase: Optimal Stopping Rules for Sequential Hypothesis Testing.
In the 25th Annual European Symposium on Algorithms (ESA), ESA 2017. pdf
- Bryan Cai, Constantinos Daskalakis and Gautam Kamath: Priv'IT: Private and Sample Efficient Identity Testing.
In the 34th International Conference on Machine Learning, ICML 2017. arXiv
- Constantinos Daskalakis, Christos Tzamos and Manolis Zampetakis: Ten Steps of EM Suffice for Mixtures of Two Gaussians.
In the 30th Annual Conference on Learning Theory, COLT 2017. Preliminary version presented at NeurIPS 2016 Workshop on Non-Convex Optimization for Machine Learning. arXiv
- Constantinos Daskalakis and Qinxuan Pan: Square Hellinger Subadditivity for Bayesian Networks and its Applications to Identity Testing.
In the 30th Annual Conference on Learning Theory, COLT 2017. arXiv
Research Highlights
Quick Description and Links: I work on Computation Theory and its interface with Game Theory, Economics, Probability Theory, Machine Learning and Statistics.
My work has studied Equilibrium Complexity, Mechanism Design,
and the interface of Property Testing and High-Dimensional Statistics.
My current work studies Machine Learning settings, which deviate from the classical, yet too idealized, paradigm wherein
multiple independent samples from the distribution of interest are available for learning. We
consider settings where data is biased, dependent or strategic.
Learn more about this work here:
Equilibrium Computation and Machine Learning 
A central challenge in Machine Learning, motivated by adversarial training applications, such
as GANs and adversarial attacks, multi-robot interactions and broader multi-agent learning settings wherein agents learn, choose actions and receive rewards in a shared environment,
is whether the success of optimization methods such as gradient descent in identifying local optima in minimization problems involving non-convex objectives
can be replicated in multi-agent learning settings:
Are there general-purpose methods for learning (local) equilibrium points in multi-agent learning settings?
The challenge encountered in practice is that, already in two-agent zero-sum problems, such as GANs, gradient descent and its variants commonly exhibit unstable, oscillatory or divergent behavior and the quality of the solutions encountered in the course of the training can be poor.
We build bridges to the complexity of fixed points and equilibrium computation problems, to prove intractability results for multi-agent learning when the agents have loss functions that are non-convex. In fact, we show this even when the setting is a two-agent zero-sum interaction,
establishing a stark separation between minimization and min-maximization. We show that any first-order method such as gradient descent
(accessing the objective using its values and the values of its gradient) will have to make exponentially many queries to compute even an approximate
local min-max equilibrium of a Lipschitz and smooth objective, and that no method at all (first-order, second-order, or whatever) can do this in polynomial time, subject to the complexity-theoretic assumption that the complexity classes P and PPAD are different, i.e. we show that the problem is PPAD-complete.
- Constantinos Daskalakis, Stratis Skoulakis, Manolis Zampetakis: The Complexity of Constrained Min-Max Optimization.
In the 53rd ACM Symposium on Theory of Computing, STOC 2021. arXiv. twitter summary
In the balance, these results establish the existence of a methodological roadblock in applying or extending Deep Learning to multi-agent settings.
While postulating a complex parametric model for some learning agent and training the model using gradient descent has been a successful framework in single-agent settings, choosing
complex models for a bunch of different agents and having them train their models via
competing gradient descent (or any other) procedures is just not going to work, even in two-agent settings, and even when one compromises on the solution concept, namely
shooting for approximate and local min-max equilibria.
Indeed, our work advocates that progress in multi-agent learning
will be unlocked via modeling and methodological insights, as well as better
clarity about the type of solution that is reasonable and attainable, combining ideas from Game Theory and Economics with Machine Learning and Optimization. Consistent
with that view we study families of multi-agent learning problems with further structure, showing further intractability results and/or identifying opportunities for tractable equilibrium learning. Below are some highlights.
- Stochastic Games / Multi-Agent Reinforcement Learning (MARL): We show that independent policy gradient methods converge to stationary Markov minimax equilibrium in two-player zero-sum stochastic games,
aka multi-agent reinforcement learning with two agents that are in direct competition with each other, trying to minimize and respectively maximize the same reward function.
- Constantinos Daskalakis, Dylan Foster, Noah Golowich: Independent Policy Gradient Methods for Competitive Reinforcement Learning.
In the 34th Annual Conference on Neural Information Processing Systems (NeurIPS), NeurIPS 2020. arXiv
On the other hand, we show that, outside of two-player zero-sum stochastic games/MARL settings, stationary Markov equilibrium computation (and learning) is intractable. Indeed, not only is stationary Markov Nash equilibrium computation
intractable but even Coarse Correlated equilibrium computation is intractable. This is true even when the game is known to the agents, there are only two agents, and the discount factor is 1/2, i.e. the game is expected to last for two rounds.
Motivated by this intractability result, we show that nonstationary Markov Coarse Correlated Equilibria can be learned efficiently (in terms of comutation and samples) in general MARL settings via decentralized learning dynamics.
- Constantinos Daskalakis, Noah Golowich, Kaiqing Zhang: The Complexity of Markov Equilibrium in Stochastic Games.
In the 35th Annual Conference on Learning Theory, COLT 2023. arXiv.
- Equilibrium existence and fast learning rates for infinite games:
- Constantinos Daskalakis, Noah Golowich: Fast Rates for Nonparametric Online Learning: From Realizability to Learning in Games.
In the 54th ACM Symposium on Theory of Computing, STOC 2022. arXiv.
- Near-Optimal Equilibrium Learning in multi-player games with convex objectives:
- Constantinos Daskalakis, Maxwell Fishelson, Noah Golowich: Near-Optimal No-Regret Learning in General Games.
In the 35th Annual Conference on Neural Information Processing Systems (NeurIPS), NeurIPS 2021. Oral. arXiv. twitter summary
- Ioannis Anagnostides, Constantinos Daskalakis, Gabriele Farina, Maxwell Fishelson, Noah Golowich, Tuomas Sandholm: Near-Optimal No-Regret Learning for Correlated Equilibria in Multi-Player General-Sum Games.
In the 54th ACM Symposium on Theory of Computing, STOC 2022. arXiv.
- Efficient Methods for Min-Max Problems with co-hypomonotone objectives:
- Jelena Diakonikolas, Constantinos Daskalakis, Michael I. Jordan: Efficient Methods for Structured Nonconvex-Nonconcave Min-Max Optimization.
In the 24th International Conference on Artificial Intelligence and Statistics (AISTATS), AISTATS 2021. arXiv
- Last-Iterate Convergence Results for Gradient Descent, Extra-Gradient, and Optimistic Gradient Descent in min-max problems with (non)convex-(non)concave objectives:
- Noah Golowich, Sarath Pattathil, Constantinos Daskalakis: Tight last-iterate convergence rates for no-regret learning in multi-player games.
In the 34th Annual Conference on Neural Information Processing Systems (NeurIPS), NeurIPS 2020. arXiv
- Noah Golowich, Sarath Pattathil, Constantinos Daskalakis, Asuman Ozdaglar: Last Iterate is Slower than Averaged Iterate in Smooth Convex-Concave Saddle Point Problems.
In the 33rd Annual Conference on Learning Theory, COLT 2020. arXiv
- Constantinos Daskalakis, Ioannis Panageas: Last-Iterate Convergence: Zero-Sum Games and Constrained Min-Max Optimization.
In the 10th Innovations in Theoretical Computer Science (ITCS) conference, ITCS 2019. arXiv.
- Constantinos Daskalakis, Ioannis Panageas: The Limit Points of (Optimistic) Gradient Descent in Min-Max Optimization.
In the 32nd Annual Conference on Neural Information Processing Systems (NeurIPS), NeurIPS 2018. arXiv.
- Constantinos Daskalakis, Andrew Ilyas, Vasilis Syrgkanis, Haoyang Zeng: Training GANs with Optimism.
In the 6th International Conference on Learning Representations, ICLR 2018. arXiv.
Learning from Biased Data
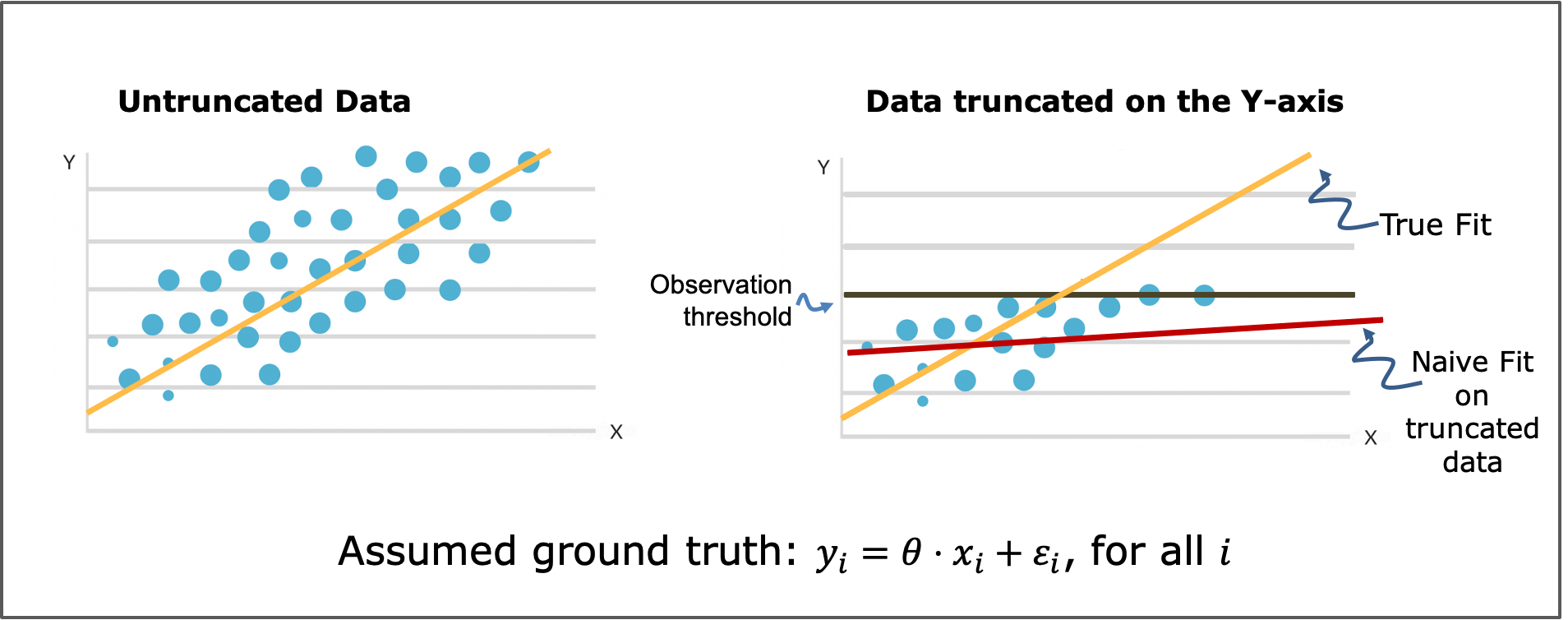
Censoring and truncation are common ways in which the training data are biased samples from the distribution of interest. They
can be caused by instrument failures or saturation effects, badly designed experiments or data collection campaigns, ethical or privacy constraints
preventing the use of all data that is available, or societal biases which are reflected in the available data. It is well-understood that training
a model on data that is censored or truncated can give rise to a biased model, which makes incorrect predictions, or disproportionately correct predictions,
and which replicates the biases in its training data. In the following figure, data produced by a linear model (on the left) are truncated according to their
label (on the right) making the naive linear fit incorrect. Is there a way to recover from this?
Inference from truncated and censored samples has a long history, going back to Galton, Pearson & Lee, and Fisher, who developed techniques for estimating
Normal distributions from truncated samples, using respectively curve fitting, the method of moments, and maximum likelihood estimation. The topic was further
developed in Statistics and Econometrics for more general distributions and regression problems. Finally, truncation and censoring
of data has received lots of study in Machine Learning and the field of domain adaptation. Despite several decades of work on these problems and their
practical importance, however, known estimation methods are computationally inefficient or have suboptimal statistical rates, especially in
high-dimensional settings, and even for the most basic problems such as truncated Gaussian estimation and truncated linear regression.
We build connections to high-dimensional probability, harmonic analysis and optimization to develop computationally and statistically efficient
methods for solving high-dimensional, parametric or non-parametric statistical learning tasks with truncated data, which had evaded efficient methods. These
include estimation from truncated data of multi-dimensional Gaussians, linear, logistic and probit regression models, as well as non-parametric multi-dimensional
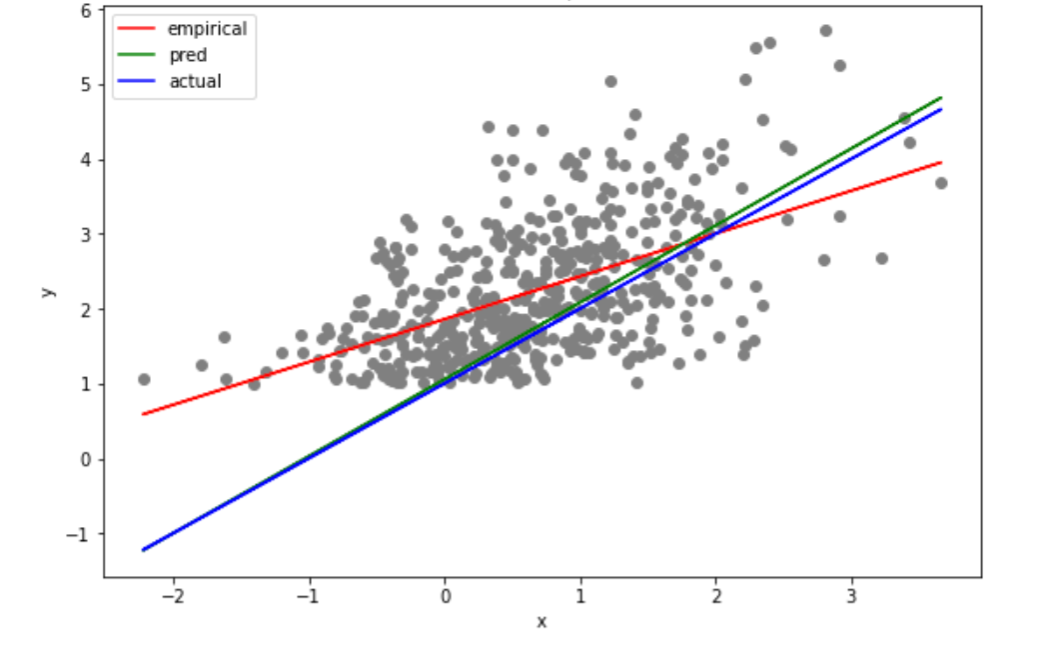
distributions with smooth log-densities. The figure shows an application of our method to truncated linear regression, wherein we are aiming to estimate a linear model as well as the noise variance
when the observations from the model are truncated according to their labels. The naive fit is shown in red, the true model
in blue, and our prediction in green.
Interestingly, our results are obtained by instantiating to these learning tasks a broader learning framework, based on maximum likelihood
estimation and stochastic gradient descent, which is modular and can accommodate much broader learning tasks beyond those for which theorems
can be obtained, including models that are expressible via Deep Neural Networks. As such, we develop a Machine Learning framework that can exploit
software and hardware optimizations as well as models developed in Deep Learning to extend its reach to the more uncharted territory of dealing with
truncation and censoring phenomena in the data.
- Constantinos Daskalakis, Themis Gouleakis, Christos Tzamos, Manolis Zampetakis: Efficient Statistics, in High Dimensions, from Truncated Samples.
In the 59th Annual IEEE Symposium on Foundations of Computer Science, FOCS 2018. arXiv.
- Constantinos Daskalakis, Themis Gouleakis, Christos Tzamos, Manolis Zampetakis: Computationally and Statistically Efficient Truncated Regression.
In the 32nd Annual Conference on Learning Theory, COLT 2019. arXiv.
- Constantinos Daskalakis, Andrew Ilyas, Manolis Zampetakis: A Theoretical and Practical Framework for Regression and Classification from Truncated Samples.
In the 23rd International Conference on Artificial Intelligence and Statistics, AISTATS 2020. pdf.
- Constantinos Daskalakis, Dhruv Rohatgi, Manolis Zampetakis: Truncated Linear Regression in High Dimensions.
In the 34th Annual Conference on Neural Information Processing Systems (NeurIPS), NeurIPS 2020. arXiv
- Constantinos Daskalakis, Patroklos Stefanou, Rui Yao, Manolis Zampetakis: Efficient Truncated Linear Regression with Unknown Noise Variance.
In the 35th Annual Conference on Neural Information Processing Systems (NeurIPS), NeurIPS 2021. arXiv.
- Constantinos Daskalakis, Vasilis Kontonis, Christos Tzamos, Manolis Zampetakis: A Statistical Taylor Theorem and Extrapolation of Truncated Densities.
In the 34th Annual Conference on Learning Theory, COLT 2021. arXiv.
More recently we have turned our attention to a more general and very prevalent type of bias due
to "self-selection." This bias arises when an agent (or a group of agents) choose, using their
private information, among several available options, e.g. which major to pursue in college,
which profession to follow, whether to join the labor force, etc. This poses statistical
challenges for model estimation because the counterfactual information about the options
that weren't chosen is not observed.
- Yeshwanth Cherapanamjeri, Constantinos Daskalakis, Andrew Ilyas, Manolis Zampetakis: Estimation of Standard Auction Models.
In the 23rd ACM Conference on Economics and Computation, EC 2022. arXiv.
- Yeshwanth Cherapanamjeri, Constantinos Daskalakis, Andrew Ilyas, Manolis Zampetakis: What Makes A Good Fisherman? Linear Regression under Self-Selection Bias.
In the 55th ACM Symposium on Theory of Computing, STOC 2023. arXiv.
Learning from Dependent Data and Statistical Physics
Statistical inference and machine learning methods commonly assume access to independent observations
from the phenomenon of interest. This assumption that the available data are independent samples is, of course, too strong. In many applications,
variables are observed on nodes of a network, or some spatial or temporal domain, and are dependent. Examples abound in financial, epidemiological, geographical, and meteorological,
applications, and dependencies naturally arise in social networks through peer effects, whose study has been recently explored in topics as diverse
as criminal activity, welfare participation, school achievement, participation in retirement plans, obesity, etc. Estimating models that combine peer
and individual effects to predict behavior has been challenging, and for many standard statistical inference tasks even consistency results are elusive.
Is it possible to have a statistical learning theory for dependent data?
We develop a PAC-learning framework which extends VC dimension and other measures of learning complexity to the data dependent setting, wherein training
samples and test samples are jointly sampled from a high-dimensional distribution. This general framework accommodates weakly dependent data, where the
strength of the dependencies is measured via classical notions of temperature in statistical physics.
- Yuval Dagan, Constantinos Daskalakis, Nishanth Dikkala, Siddhartha Jayanti: Generalization and learning under Dobrushin's condition.
In the 32nd Annual Conference on Learning Theory, COLT 2019. arXiv.
In networked prediction tasks, we have developed estimation methods that even accommodate strong dependencies in the response variables, as long as the temperature is lower bounded by some constant.
- Constantinos Daskalakis, Nishanth Dikkala, Ioannis Panageas: Regression from Dependent Observations.
In the 51st Annual ACM Symposium on the Theory of Computing, STOC 2019. arXiv
- Constantinos Daskalakis, Nishanth Dikkala, Ioannis Panageas: Logistic regression with peer-group effects via inference in higher-order Ising models.
In the 23rd International Conference on Artificial Intelligence and Statistics, AISTATS 2020. arXiv.
- Yuval Dagan, Constantinos Daskalakis, Nishanth Dikkala, Surbhi Goel, Anthimos Vardis Kandiros: Statistical Estimation from Dependent Data.
In the 38th International Conference on Machine Learning, ICML 2021. arXiv.
As a byproduct of our work, we show concentration and anti-concentration of measure results for functions of dependent variables, advancing the
state-of-the-art in high-dimensional probability & statistical physics on this topic. These can be leveraged to obtain a framework for learning Ising models from one, a few, or many samples.
- Constantinos Daskalakis, Nishanth Dikkala and Gautam Kamath: Concentration of Multilinear Functions of the Ising Model with Applications to Network Data.
In the 31st Annual Conference on Neural Information Processing Systems (NeurIPS), NeurIPS 2017. arXiv
- Yuval Dagan, Constantinos Daskalakis, Nishanth Dikkala, Anthimos Vardis Kandiros: Learning Ising Models from One or Multiple Samples.
In the 53rd ACM Symposium on Theory of Computing, STOC 2021. arXiv
We thus unify under one umbrella two strands of literature on estimating Ising models:
(1) a renaissance of recent work in Computer Science on estimating them from multiple independent samples under minimal assumptions about the model's
interaction matrix; and (2) a growing literature in Probability Theory on estimating them from one sample in restrictive settings.
In particular,
we provide guarantees for one-sample estimation, which quantify the estimation error in terms of the metric entropy of a family of
interaction matrices. As corollaries of our main theorem, we derive bounds when the model's interaction matrix is a (sparse) linear combination
of known matrices, or it belongs to a finite set, or to a high-dimensional manifold. Our result handles multiple independent samples
by viewing them as one sample from a larger model, and can be used to derive estimation bounds that are qualitatively similar to state-of-the-art in
the multiple-sample literature.
Equilibrium Complexity
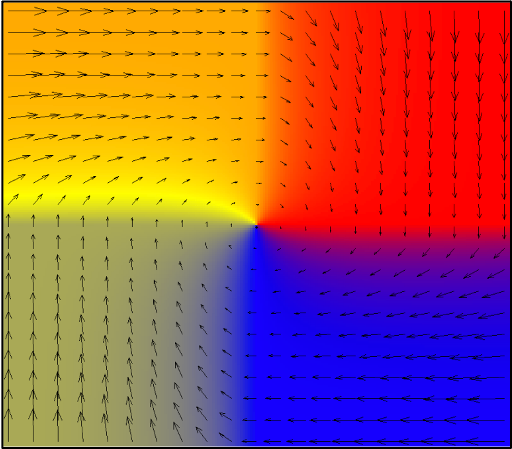
My Ph.D. research examines whether rational, strategic agents may arrive,
through their interaction, at a state where no single one of them would be better off by changing their own strategy unless others did
so as well. Such a state is called Nash equilibrium, in honor of John Nash, who showed that such a state always exists. It is commonly
used in Game Theory to predict the outcome arising through the interaction of strategic individuals in situations of conflict.
With Paul Goldberg and Christos Papadimitriou, I show that in complex systems Nash equilibrium can be computationally unachievable. This
implies that it is not always justifiable or relevant to study the Nash equilibria of a system.
- Constantinos Daskalakis, Paul W. Goldberg and Christos H. Papadimitriou: The Complexity of Computing a Nash Equilibrium.
In the 38th ACM Symposium on Theory of Computing, STOC 2006.
Journal version as SIAM Journal on Computing, 39(1), 195--259, May 2009. (Invited, special issue for STOC 2006.) pdf
Expository article in Communications of the ACM 52(2):89--97, 2009. (Invited.) pdf
My dissertation, focusing on this work, received the 2008 ACM Doctoral Dissertation Award. With Paul Goldberg and Christos Papadimitriou, I also received the inaugural Kalai Prize from the
Game Theory Society, with the following citation: "This paper made key conceptual and technical contributions in an illustrious line of work on the complexity of computing Nash
equilibrium. It also highlights the necessity of constructing practical algorithms that compute equilibria efficiently on important subclasses of games."
Here is a blog post from the congress by Paul. In 2011, our same work was awarded the 2011 SIAM Outstanding Paper Prize.
In more recent work I've shown that even arriving at an approximate Nash equilibrium can be computationally intractable, and I've identified families of games with structure where (approximate) Nash equilibria are tractable.
-
Constantinos Daskalakis: On the Complexity of Approximating a Nash Equilibrium.
In the 22nd Annual ACM-SIAM Symposium on Discrete Algorithms, SODA 2011.
ACM Transactions on Algorithms (TALG), 9(3): 23, 2013. Special Issue for SODA 2011. Invited. pdf
- Constantinos Daskalakis and Christos Papadimitriou: Approximate Nash Equilibria in Anonymous Games.
Journal of Economic Theory, 156:207--245, 2015. pdf
Journal version of papers in FOCS 2007, FOCS 2008, and STOC 2009.
- Yang Cai, Ozan Candogan, Constantinos Daskalakis and Christos Papadimitriou: Zero-sum Polymatrix Games: A Generalization of Minmax.
Mathematics of Operations Research, 41(2): 648-655, 2016. pdf
Journal version of papers in ICALP 2009 and SODA 2011.
Further Resources:
- video recording of tutorial on Complexity of Equilibria, at Simons Insitute for Theory of Computation, August 2015
- survey article on the complexity of Nash equilibria, which appeared in a Computer Science Review special volume dedicated to Christos Papadimitriou's work
Mechanism Design
 (image credit)
(image credit)
Mechanism design, sometimes called "inverse Game Theory," studies how to design incentives that promote a desired objective in the
outcome of the strategic interaction between agents. Examples include designing an election protocol that ensures the election of the best candidate,
designing a procedure for allocating public resources in order to maximize the social welfare from the allocation, and designing an auction for
selling paintings that maximizes the auctioneer's revenue. In all these cases, the design challenge lies in the fact that the designer's objective is not
aligned with that of each strategic agent: a voter wants to maximize the chance that her favorite candidate is elected, while a bidder wants to maximize his own utility.
So the right incentives need to be put in place in order to incentivize the agents to behave in a manner that promotes the designer's objective, as much as
this is feasible.
Mechanism design has received a lot of study in Economics since the 1960s, and has found a plethora of applications in practice
such as in the design of online markets and the sale of radio spectrum to telecoms by governments, but many challenges remain. My group has focused on the challenge of
multi-dimensional mechanism design,
which targets mechanism design settings in which the preferences of the agents are multi-dimensional, e.g. selling multiple items in an auction, multiple radio-frequencies, etc. While maximizing social welfare in this setting can be achieved with the
celebrated VCG mechanism, the understanding of other objectives such as revenue optimization is quite limited. With Yang Cai and Matt Weinberg, I provide an
algorithmic framework
for computing optimal mechanisms for arbitrary objectives.
- Yang Cai, Constantinos Daskalakis and Matt Weinberg: Understanding Incentives: Mechanism Design becomes Algorithm Design.
In the 54th IEEE Symposium on Foundations of Computer Science, FOCS 2013. arxiv
An application of our framework provides an
algorithmic generalization
of Myerson's celebrated single-item revenue-optimal auction to the multi-item setting. Given the auctioneer's information about the bidders, in the form of a distribution over their preferences over items and bundles of items, our algorithmic framework efficiently
computes a revenue-optimal auction.
- Yang Cai, Constantinos Daskalakis and Matt Weinberg: An Algorithmic Characterization of Multi-Dimensional Mechanisms.
In the 44th ACM Symposium on Theory of Computing, STOC 2012. ECCC Report.
- Yang Cai, Constantinos Daskalakis and Matt Weinberg: Optimal Multi-Dimensional Mechanism Design: Reducing Revenue to Welfare Maximization.
In the 53rd Annual IEEE Symposium on Foundations of Computer Science (FOCS), FOCS 2012. FOCS 2022 Test of Time Award. arxiv
In work with Alan Deckelbaum and Christos Tzamos, we obtain analytical characterizations of revenue-optimal multi-item mechanisms in the single-buyer setting, using optimal transport theory.
These results are contained in our Econometrica paper below, whose preliminary form received the Best Paper Award at the ACM Conference on Economics and Computation in 2013.
Also below is a survey article I wrote about multi-item auctions.
- Constantinos Daskalakis, Alan Deckelbaum and Christos Tzamos: Mechanism Design via Optimal Transport.
In the 14th ACM Conference on Electronic Commerce, EC 2013. Best Paper and Best Student Paper Award.
pdf
- Constantinos Daskalakis, Alan Deckelbaum and Christos Tzamos: Strong Duality for a Multiple-Good Monopolist.
In the 16th ACM Conference on Economics and Computation (EC), EC 2015.
Journal version as Econometrica, 85(3):735-767, 2017. arXiv
Futher resources:
- Slides on Algorithmic Bayesian Mechanism Design from an EC 2014 tutorial with Cai and Weinberg.
- video recording of tutorial on Algorithmic Mechanism Design, at Simons Insitute for Theory of Computation
High-Dimensional Statistics & Property Testing 
Statistics has traditionally focused on the asymptotic analysis of tests, as the number of samples tends to infinity. Moreover,
statistical tests typically only detect certain types of deviations
from the null hypothesis, or are designed to select between a null and an alternative hypothesis that are fixed distributions
or are from parametric families of distributions. Motivated by applications where the
sample size is small
relative to the support of the distribution, which arises naturally in high-dimensional settings,
the field of Property Testing has aimed at rethinking the foundations of Statistics in the small sample regime,
placing emphasis on accommodating composite and non-parametric hypotheses, as well as detecting all rather than some deviations from the null.
In a NeurIPS'15 spotlight paper with Acharya and Kamath, we provide statistical tests for testing non-parametric properties of distributions, such
monotonicty, unimodality, log-concavity, monotone hazard rate, in the non-asymptotic regime and with tight control for type II errors. Our tests
are derived from a general testing framework we provide, based on a robust and sample-optimal goodness-of-fit test.
- Jayadev Acharya, Constantinos Daskalakis and Gautam Kamath: Optimal Testing for Properties of Distributions.
In the 29th Annual Conference on Neural Information Processing Systems (NeurIPS), NeurIPS 2015. Spotlight Paper. arXiv
video recording from a talk at UT Austin, October 2015.
Here is also a survey-ish paper I wrote on non-asymptotic statistical hypothesis testing with Kamath and Wright:
- Constantinos Daskalakis, Gautam Kamath and John Wright: Which Distribution Distances are Sublinearly Testable?.
In the 29th Annual ACM-SIAM Symposium on Discrete Algorithms, SODA 2018. arXiv
Our more recent work has focused on high-dimensional testing problems:
- Constantinos Daskalakis and Qinxuan Pan: Square Hellinger Subadditivity for Bayesian Networks and its Applications to Identity Testing.
In the 30th Annual Conference on Learning Theory, COLT 2017. arXiv
- Constantinos Daskalakis, Nishanth Dikkala and Gautam Kamath: Testing Ising Models
In the 29th Annual ACM-SIAM Symposium on Discrete Algorithms, SODA 2018. arXiv
Journal version in IEEE Transactions on Information Theory, 65(11): 6829-6852, 2019. ieee
on testing causal models:
- Jayadev Acharya, Arnab Bhattacharyya, Constantinos Daskalakis, Saravanan Kandasamy: Learning and Testing Causal Models with Interventions.
In the 32nd Annual Conference on Neural Information Processing Systems (NeurIPS), NeurIPS 2018. arXiv.
and on testing while respecting the privacy of the sample:
- Bryan Cai, Constantinos Daskalakis and Gautam Kamath: Priv'IT: Private and Sample Efficient Identity Testing.
In the 34th International Conference on Machine Learning, ICML 2017. arXiv
Here are slides from a tutorial I gave on this line of work at Greek Stochastics Theta.
Links to Selected Talks, Videos, Slides
Karp Distinguished Lecture: Equilibrium Computation and Machine Learning at Simons Institute for Theory of Computing
a four part tutorial on "Equilibrium Computation and Machine Learning" at Simons Institute for Theory of Computing: part 1, part 2, part 3, part 4
talk recording: Three ways Machine Learning fails and what to do about them, Columbia University Distinguished Lecture in CS, September 2020
talk recording: The Complexity of Min-Max Optimization, Montreal Machine Learning and Optimization, July 2020
talk recording: Robust Learning from Censored Data, MIT-MSR Trustworthy and Robust AI Collaboration Workshop, June 2020
talk recording: Equilibria, Fixed Points, and Computational Complexity, Nevanlinna Prize Lecture, International Congress of Mathematicians, Rio de Janeiro, 1 August 2018
talk recording: Complexity and Algorithmic Game Theory I (Equilibrium Complexity) and II (Mechanism Design) at Simons Insitute for Theory of Computation, Special Semester on Economics and Computation, August 2015
talk recording: Testing Properties of Distributions, UT Austin, October 2015
slides: Distribution Property Testing Tutorial, at Greek Stochastics Theta workshop
slides: Algorithmic Bayesian Mechanism Design, from EC 2014 tutorial with Yang Cai and Matt Weinberg.
some general audience articles about my work
Selected Publications
Equilibrium Complexity
- Constantinos Daskalakis, Paul W. Goldberg and Christos H. Papadimitriou: The Complexity of Computing a Nash Equilibrium.
In the 38th ACM Symposium on Theory of Computing, STOC 2006.
Journal version as SIAM Journal on Computing, 39(1), 195--259, May 2009. (Invited, special issue for STOC 2006.) pdf
Expository article in Communications of the ACM 52(2):89--97, 2009. (Invited.) pdf
2008 Kalai Prize from Game Theory Society; 2011 SIAM Outstanding Paper Prize; 2022 ACM SIGECOM Test of Time Award.
-
Constantinos Daskalakis: On the Complexity of Approximating a Nash Equilibrium.
In the 22nd Annual ACM-SIAM Symposium on Discrete Algorithms, SODA 2011.
ACM Transactions on Algorithms (TALG), 9(3): 23, 2013. Special Issue for SODA 2011. Invited. pdf
- Constantinos Daskalakis and Christos Papadimitriou: Approximate Nash Equilibria in Anonymous Games.
Journal of Economic Theory, 156:207--245, 2015. pdf
Journal version of papers in FOCS 2007, FOCS 2008, and STOC 2009.
- Constantinos Daskalakis, Stratis Skoulakis, Manolis Zampetakis: The Complexity of Constrained Min-Max Optimization.
In the 53rd ACM Symposium on Theory of Computing, STOC 2021. arXiv. twitter summary
- Constantinos Daskalakis, Noah Golowich, Kaiqing Zhang: The Complexity of Markov Equilibrium in Stochastic Games.
In the 35th Annual Conference on Learning Theory, COLT 2023. arXiv.
- Yuval Dagan, Constantinos Daskalakis, Maxwell Fishelson, Noah Golowich: From External to Swap Regret 2.0: An Efficient Reduction and Oblivious Adversary for Large Action Spaces.
In the 56th ACM Symposium on Theory of Computing, STOC 2024. Invited to the Special Issue. arXiv. twitter summary
Equilibrium Computation, Online Learning and Machine Learning
- Constantinos Daskalakis and Qinxuan Pan: A Counter-Example to Karlin's Strong Conjecture for Fictitious Play.
In the 55th IEEE Symposium on Foundations of Computer Science, FOCS 2014. arxiv
- Yang Cai, Ozan Candogan, Constantinos Daskalakis and Christos Papadimitriou: Zero-sum Polymatrix Games: A Generalization of Minmax.
Mathematics of Operations Research, 41(2): 648-655, 2016. pdf
- Constantinos Daskalakis, Andrew Ilyas, Vasilis Syrgkanis, Haoyang Zeng: Training GANs with Optimism.
In the 6th International Conference on Learning Representations, ICLR 2018. arXiv.
- Noah Golowich, Sarath Pattathil, Constantinos Daskalakis: Tight last-iterate convergence rates for no-regret learning in multi-player games.
In the 34th Annual Conference on Neural Information Processing Systems (NeurIPS), NeurIPS 2020. arXiv
- Constantinos Daskalakis, Stratis Skoulakis, Manolis Zampetakis: The Complexity of Constrained Min-Max Optimization.
In the 53rd ACM Symposium on Theory of Computing, STOC 2021. arXiv. twitter summary
- Constantinos Daskalakis, Maxwell Fishelson, Noah Golowich: Near-Optimal No-Regret Learning in General Games.
In the 35th Annual Conference on Neural Information Processing Systems (NeurIPS), NeurIPS 2021. Oral. arXiv. twitter summary
- Constantinos Daskalakis, Noah Golowich, Kaiqing Zhang: The Complexity of Markov Equilibrium in Stochastic Games.
In the 35th Annual Conference on Learning Theory, COLT 2023. arXiv.
- Angelos Assos, Idan Attias, Yuval Dagan, Constantinos Daskalakis, Maxwell Fishelson: Online Learning and Solving Infinite Games with an ERM Oracle.
In the 35th Annual Conference on Learning Theory, COLT 2023. arXiv.
- Yuval Dagan, Constantinos Daskalakis, Maxwell Fishelson, Noah Golowich: From External to Swap Regret 2.0: An Efficient Reduction and Oblivious Adversary for Large Action Spaces.
In the 56th ACM Symposium on Theory of Computing, STOC 2024. Invited to the Special Issue. arXiv. twitter summary
- Yuval Dagan, Constantinos Daskalakis, Maxwell Fishelson, Noah Golowich, Robert Kleinberg, Princewill Okoroafor: Breaking the T^2/3 Barrier for Sequential Calibration.
In the 57th ACM Symposium on Theory of Computing, STOC 2025. arXiv. Invited to the Special Issue.
Diffusion Models
- Giannis Daras, Yuval Dagan, Alexandros G. Dimakis, Constantinos Daskalakis: Consistent Diffusion Models: Mitigating Sampling Drift by Learning to be Consistent.
In the 37th Annual Conference on Neural Information Processing Systems (NeurIPS), NeurIPS 2023. arXiv.
- Giannis Daras, Alex Dimakis, Constantinos Daskalakis: Consistent Diffusion Meets Tweedie: Training Exact Ambient Diffusion Models with Noisy Data.
In the 41st International Conference on Machine Learning, ICML 2024. arXiv. twitter summary
- Giannis Daras, Yeshwanth Cherapanamjeri, Constantinos Daskalakis: How much is a noisy image worth? Data Scaling Laws for Ambient Diffusion.
In the 13th International Conference on Learning Representations, ICLR 2025. arXiv.
- Giannis Daras, Adrian Rodriguez-Munoz, Adam Klivans, Antonio Torralba, Constantinos Daskalakis: Ambient Diffusion Omni: Training Good Models with Bad Data.
In the 39th Annual Conference on Neural Information Processing Systems (NeurIPS), NeurIPS 2025. Spotlight. arXiv.
- Giannis Daras, Jeffrey Ouyang-Zhang, Krithika Ravishankar, William Daspit, Costis Daskalakis, Qiang Liu, Adam Klivans, Daniel J. Diaz: Ambient Proteins: Training Diffusion Models on Low Quality Structures.
In the 39th Annual Conference on Neural Information Processing Systems (NeurIPS), NeurIPS 2025. Spotlight. bioarXiv.
Learning from Biased Data/Truncated Statistics/Econometrics
- Constantinos Daskalakis, Themis Gouleakis, Christos Tzamos, Manolis Zampetakis: Efficient Statistics, in High Dimensions, from Truncated Samples.
In the 59th Annual IEEE Symposium on Foundations of Computer Science, FOCS 2018. arXiv.
- Constantinos Daskalakis, Themis Gouleakis, Christos Tzamos, Manolis Zampetakis: Computationally and Statistically Efficient Truncated Regression.
In the 32nd Annual Conference on Learning Theory, COLT 2019. arXiv.
- Constantinos Daskalakis, Vasilis Kontonis, Christos Tzamos, Manolis Zampetakis: A Statistical Taylor Theorem and Extrapolation of Truncated Densities.
In the 34th Annual Conference on Learning Theory, COLT 2021. arXiv.
- Yeshwanth Cherapanamjeri, Constantinos Daskalakis, Andrew Ilyas, Manolis Zampetakis: Estimation of Standard Auction Models.
In the 23rd ACM Conference on Economics and Computation, EC 2022. arXiv.
- Yeshwanth Cherapanamjeri, Constantinos Daskalakis, Andrew Ilyas, Manolis Zampetakis: What Makes A Good Fisherman? Linear Regression under Self-Selection Bias.
In the 55th ACM Symposium on Theory of Computing, STOC 2023. arXiv.
Learning from Dependent Data/Statistical Physics
- Yuval Dagan, Constantinos Daskalakis, Nishanth Dikkala, Siddhartha Jayanti: Generalization and learning under Dobrushin's condition.
In the 32nd Annual Conference on Learning Theory, COLT 2019. arXiv.
- Constantinos Daskalakis, Nishanth Dikkala, Ioannis Panageas: Regression from Dependent Observations.
In the 51st Annual ACM Symposium on the Theory of Computing, STOC 2019. arXiv
- Yuval Dagan, Constantinos Daskalakis, Nishanth Dikkala, Anthimos Vardis Kandiros: Learning Ising Models from One or Multiple Samples.
In the 53rd ACM Symposium on Theory of Computing, STOC 2021. arXiv.
- Yuval Dagan, Constantinos Daskalakis, Nishanth Dikkala, Surbhi Goel, Anthimos Vardis Kandiros: Statistical Estimation from Dependent Data.
In the 38th International Conference on Machine Learning, ICML 2021. arXiv.
Phylogenetics:
- Constantinos Daskalakis, Elchanan Mossel and Sebastien Roch: Optimal Phylogenetic Reconstruction.
In the 38th ACM Symposium on Theory of Computing, STOC 2006. arXiv
Journal version as Probability Theory and Related Fields, 149(1-2):149-189, 2011.
Coding Theory:
-
Sanjeev Arora, Constantinos Daskalakis and David Steurer: Message-Passing Algorithms and Improved LP Decoding.
In the 41st ACM Symposium On Theory of Computing, STOC 2009.
Journal version as IEEE Transactions on Information Theory, 58(12):7260--7271, 2012. pdf
Probability Theory:
- Constantinos Daskalakis and Christos Papadimitriou: Sparse Covers for Sums of Indicators.
Probability Theory and Related Fields, 162(3):679-705, 2015. arXiv
- Constantinos Daskalakis, Anindya De, Gautam Kamath and Christos Tzamos: A Size-Free CLT for Poisson Multinomials and its Applications.
In the 48th ACM Symposium on Theory of Computing, STOC 2016. arXiv
- Constantinos Daskalakis, Nishanth Dikkala and Gautam Kamath: Concentration of Multilinear Functions of the Ising Model with Applications to Network Data.
In the 31st Annual Conference on Neural Information Processing Systems (NeurIPS), NeurIPS 2017. arXiv
Mechanism Design:
- Yang Cai, Constantinos Daskalakis and Matt Weinberg: An Algorithmic Characterization of Multi-Dimensional Mechanisms.
In the 44th ACM Symposium on Theory of Computing, STOC 2012. ECCC Report.
- Yang Cai, Constantinos Daskalakis and Matt Weinberg: Optimal Multi-Dimensional Mechanism Design: Reducing Revenue to Welfare Maximization.
In the 53rd IEEE Symposium on Foundations of Computer Science, FOCS 2012. FOCS 2022 Test of Time Award. arxiv
- Yang Cai, Constantinos Daskalakis and Matt Weinberg: Understanding Incentives: Mechanism Design becomes Algorithm Design.
In the 54th IEEE Symposium on Foundations of Computer Science, FOCS 2013. arxiv
- Constantinos Daskalakis, Alan Deckelbaum and Christos Tzamos: Mechanism Design via Optimal Transport.
In the 14th ACM Conference on Electronic Commerce, EC 2013. Best Paper and Best Student Paper Award.
pdf
- Constantinos Daskalakis, Alan Deckelbaum and Christos Tzamos: Strong Duality for a Multiple-Good Monopolist.
In the 16th ACM Conference on Economics and Computation (EC), EC 2015. arXiv
Journal version as Econometrica, 85(3):735-767, 2017.
- Yang Cai, Constantinos Daskalakis and Christos H. Papadimitriou: Optimum Statistical Estimation with Strategic Data Sources.
In the 28th Annual Conference on Learning Theory (COLT), COLT 2015. arXiv
- Constantinos Daskalakis, Christos Papadimitriou and Christos Tzamos: Does Information Revelation Improve Revenue?.
In the 17th ACM Conference on Economics and Computation (EC), EC 2016. Invited to Special Issue. pdf
- Constantinos Daskalakis and Vasilis Syrgkanis: Learning in Auctions: Regret is Hard, Envy is Easy.
In the 57th IEEE Symposium on Foundations of Computer Science (FOCS), FOCS 2016. arxiv
- Yang Cai and Constantinos Daskalakis: Learning Multi-Item Auctions with (or without) Samples.
In the 58th IEEE Symposium on Foundations of Computer Science (FOCS), FOCS 2017. arxiv
- Johannes Brustle, Yang Cai, Constantinos Daskalakis: Multi-Item Mechanisms without Item-Independence: Learnability via Robustness.
In the 21st ACM Conference on Economics and Computation, EC 2020. arXiv
- Yang Cai, Constantinos Daskalakis: Recommender Systems meet Mechanism Design.
In the 23rd ACM Conference on Economics and Computation, EC 2022. arXiv.
Property Testing ∩ Statistics:
- Jayadev Acharya, Constantinos Daskalakis and Gautam Kamath: Optimal Testing for Properties of Distributions.
In the 29th Annual Conference on Neural Information Processing Systems (NeurIPS), NeurIPS 2015. Spotlight Paper. arXiv
- Constantinos Daskalakis and Qinxuan Pan: Square Hellinger Subadditivity for Bayesian Networks and its Applications to Identity Testing.
In the 30th Annual Conference on Learning Theory, COLT 2017. arXiv
- Bryan Cai, Constantinos Daskalakis and Gautam Kamath: Priv'IT: Private and Sample Efficient Identity Testing.
In the 34th International Conference on Machine Learning, ICML 2017. arXiv
- Constantinos Daskalakis, Gautam Kamath and John Wright: Which Distribution Distances are Sublinearly Testable?
In the 29th Annual ACM-SIAM Symposium on Discrete Algorithms, SODA 2018. arXiv
- Constantinos Daskalakis, Nishanth Dikkala and Gautam Kamath: Testing Ising Models
In the 29th Annual ACM-SIAM Symposium on Discrete Algorithms, SODA 2018. arXiv
Journal version in IEEE Transactions on Information Theory, 65(11): 6829-6852, 2019. ieee
Other Machine Learning and Statistics:
- Constantinos Daskalakis, Ilias Diakonikolas and Rocco A. Servedio: Learning Poisson Binomial Distributions.
In the 44th ACM Symposium on Theory of Computing, STOC 2012. arXiv
Algorithmica, 72(1):316-357, 2015. Special Issue on New Theoretical Challenges in Machine Learning. Invited. arXiv
- Constantinos Daskalakis, Christos Tzamos and Manolis Zampetakis: Ten Steps of EM Suffice for Mixtures of Two Gaussians.
In the 30th Annual Conference on Learning Theory, COLT 2017. Preliminary version presented at NeurIPS 2016 Workshop on Non-Convex Optimization for Machine Learning. arXiv
- Constantinos Daskalakis, Christos Tzamos and Manolis Zampetakis: A Converse to Banach's Fixed Point Theorem and its CLS Completeness.
In the 50th Annual ACM Symposium on the Theory of Computing, STOC 2018. arXiv
- Constantinos Daskalakis, Dhruv Rohatgi, Manolis Zampetakis: Constant-Expansion Suffices for Compressed Sensing with Generative Priors.
In the 34th Annual Conference on Neural Information Processing Systems (NeurIPS), NeurIPS 2020. Spotlight. arXiv
- Constantinos Daskalakis, Qinxuan Pan: Sample-Optimal and Efficient Learning of Tree Ising models.
In the 53rd ACM Symposium on Theory of Computing, STOC 2021. arXiv. twitter summary
|
and pettiness and indifference.
and offers you satrapies and the like.
these things that you do not want.
the Agora, the Theater, and the Laurels.
