In the last post, I described Glia — an AI that designs computer systems by doing research instead of mutating code. It worked, but it had one stubborn limit: a single agent eventually fills up its context window and has to stop. Worse, long before it stops, its attention frays and it starts forgetting why it tried what it tried.
This post is about fixing that. The follow-up system is called Engram. Pointed at the same hard systems problems, an AI that can carry knowledge forward across many agents beats every prior LLM-based method — including Glia — and on the toughest of them, edges out the human state-of-the-art. One number to anchor: on a multi-cloud data-transfer benchmark whose published expert solution costs $626, Engram averages $662 and reaches $622 with a stronger model — actually beating the human design.
1. Two paradigms, two failures
By now there are two broad families of LLM-based systems design, and each fails in its own way.
The first is evolution via code mutation — AlphaEvolve, OpenEvolve, ADRS, FunSearch, Evolution of Heuristics. These run long searches across many candidates, which is a real strength. But the LLM only ever sees code, a score, and a template-based feedback. It never sees the thought process behind why something worked or didn’t work, why some experiments were tried, or tolerate temporary regressions. So it gets stuck doing what we call neighborhood bias: it keeps tweaking variations of whatever it started with, because a single coordinated leap to a different kind of solution can temporarily make the score worse — and a score-driven loop has low tolerance for anything that scores worse.
The second is iterative design with tools — Glia. This one reasons through experiments and data, which gives it coherence and flexibility the evolutionary methods lack. But its reasoning lives inside one growing context window, and as that window fills, the reasoning degrades. I call this the coherence ceiling.
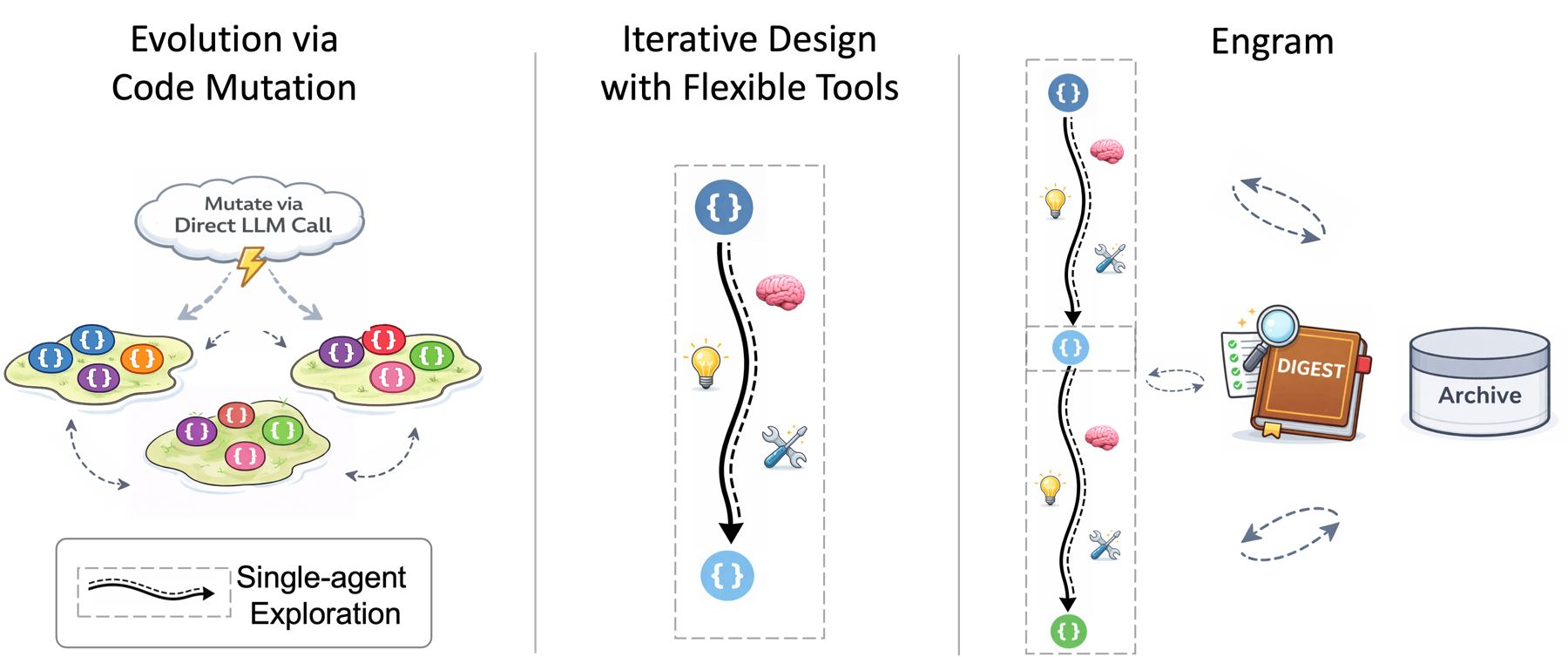
The cleanest way to see the whole landscape is along three axes. Coherence: are an agent’s decisions informed by the reasoning behind earlier attempts? Flexibility: can it take free-form actions — run code, inspect data, use tools — instead of filling in a fixed template? Persistence: can the search keep going over a long horizon without quality decaying?
Evolution is persistent but has weak coherence and flexibility. Glia is coherent and flexible but not persistent. Each paradigm gets two out of three. The goal for Engram was to get all three at once.
Three properties, three methods.
| Method | Coherence | Flexibility | Persistence |
|---|---|---|---|
| Code mutation (FunSearch, OpenEvolve, …) | Low | Low | High |
| Iterative design with tools (Glia) | High | High | Low |
| Engram | High | High | High |
2. Engram: coherent agents with a shared persistent memory
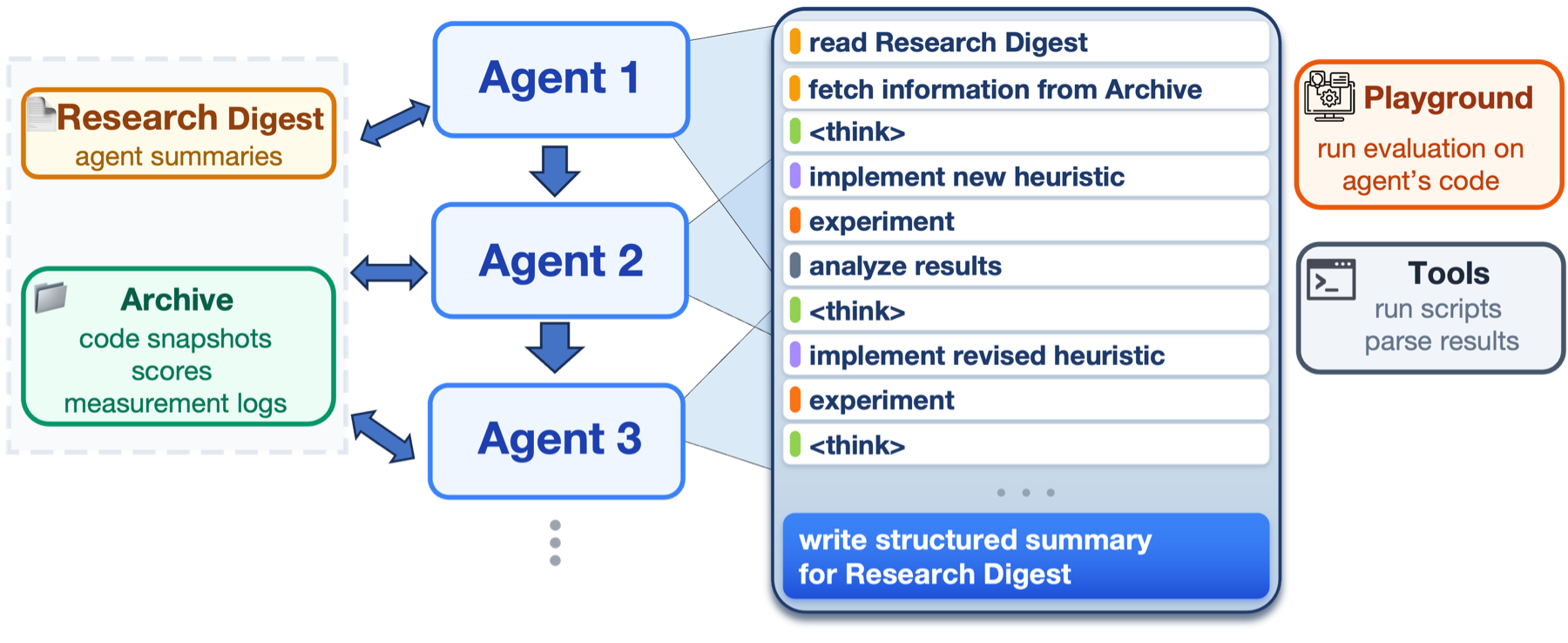
Engram’s idea is simple to state. Instead of one agent that runs until its context fills up, run a sequence of agents — and let them hand off what they learned.
Each agent works like a Glia-style researcher: it reads the problem, forms a hypothesis, implements a heuristic, runs experiments in the playground, and analyzes the results. When it’s done — or when it’s exhausted its useful context — it writes two things. It dumps the raw material (code snapshots, scores, measurement logs) into a persistent Archive. And, crucially, it distills the interpretation — what it tried, what it learned, what failed and why, what to try next — into a compact Research Digest.
The next agent starts fresh, with an empty context window. It reads the Research Digest first, pulls only the relevant pieces of the Archive it needs, and builds on top of that. It never inherits the previous agent’s bloated, decaying history — only a clean, structured summary of the insight.
3. The discovery: escaping the obvious solution
The clearest demonstration is a problem called multi-cloud multicast: copy a large dataset from one cloud region to many others — possibly hopping through intermediate waypoints that can be switched on to dodge expensive links — as cheaply as possible under a time budget.
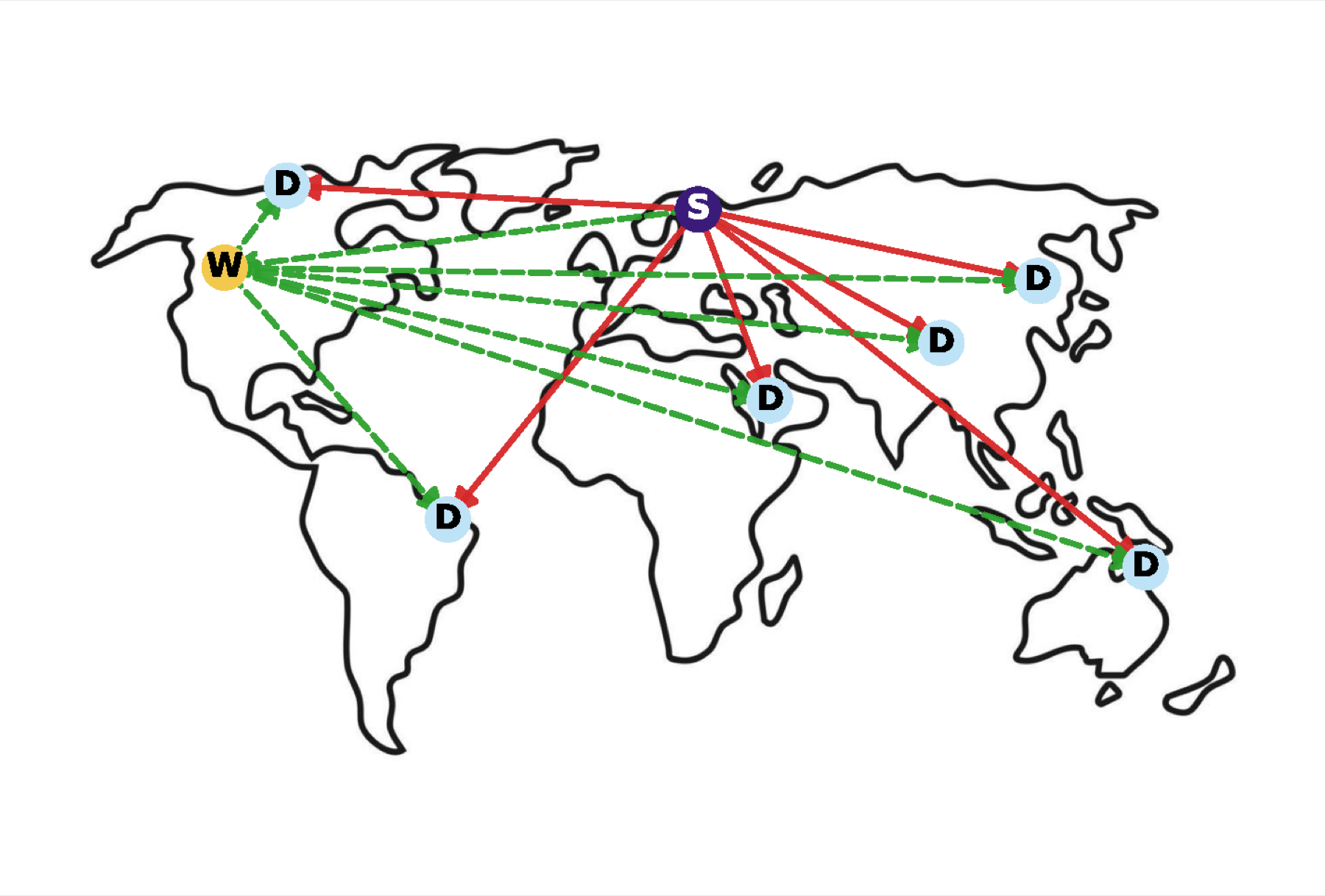
There’s an obvious framing. It looks like classical multicast, so you reach for Steiner-tree-style graph heuristics. That’s exactly the trap: every evolutionary method, and sometimes Glia too, plateaus there — well above the human state-of-the-art. The framing that actually works is completely different: write the problem as a Mixed-Integer Linear Program (MILP) and then apply tractable relaxations to make it solvable. That’s what the human expert solution (Cloudcast, NSDI ‘24) does.
Getting from the obvious framing to the right one isn’t a small tweak — it’s a leap to a different family of solutions, and the first attempts at it score worse before they score better. That’s precisely the move a score-driven evolutionary loop can’t make, and the move a context-bound single agent runs out of room to complete.
Engram makes it. Here’s a single run, step by step:
- It starts from a strong Steiner-tree heuristic baseline — cost $772.
- The next agent attempts to formulate the problem as a MILP. The cost explodes to $1,104 — much worse.
- A follow-up attempt fails outright; the agent reports “no opportunities.”
- A fresh agent reads the Digest, understands why the MILP was being attempted, and recovers — implementing a reduced-edge MILP with explicit tractability knobs. The cost drops to $644, a ~17% improvement over the baseline.
Why this matters. Steps 2 and 3 score worse than the baseline. An evolutionary loop would have pruned the MILP idea right there. Engram doesn’t — because the Digest preserves why step 2 was attempted, not just that its score got worse. The next agent inherits the diagnosis, not the dead end. Tolerating a temporary regression is the whole point: that’s where the conceptual shift lives.
4. The results
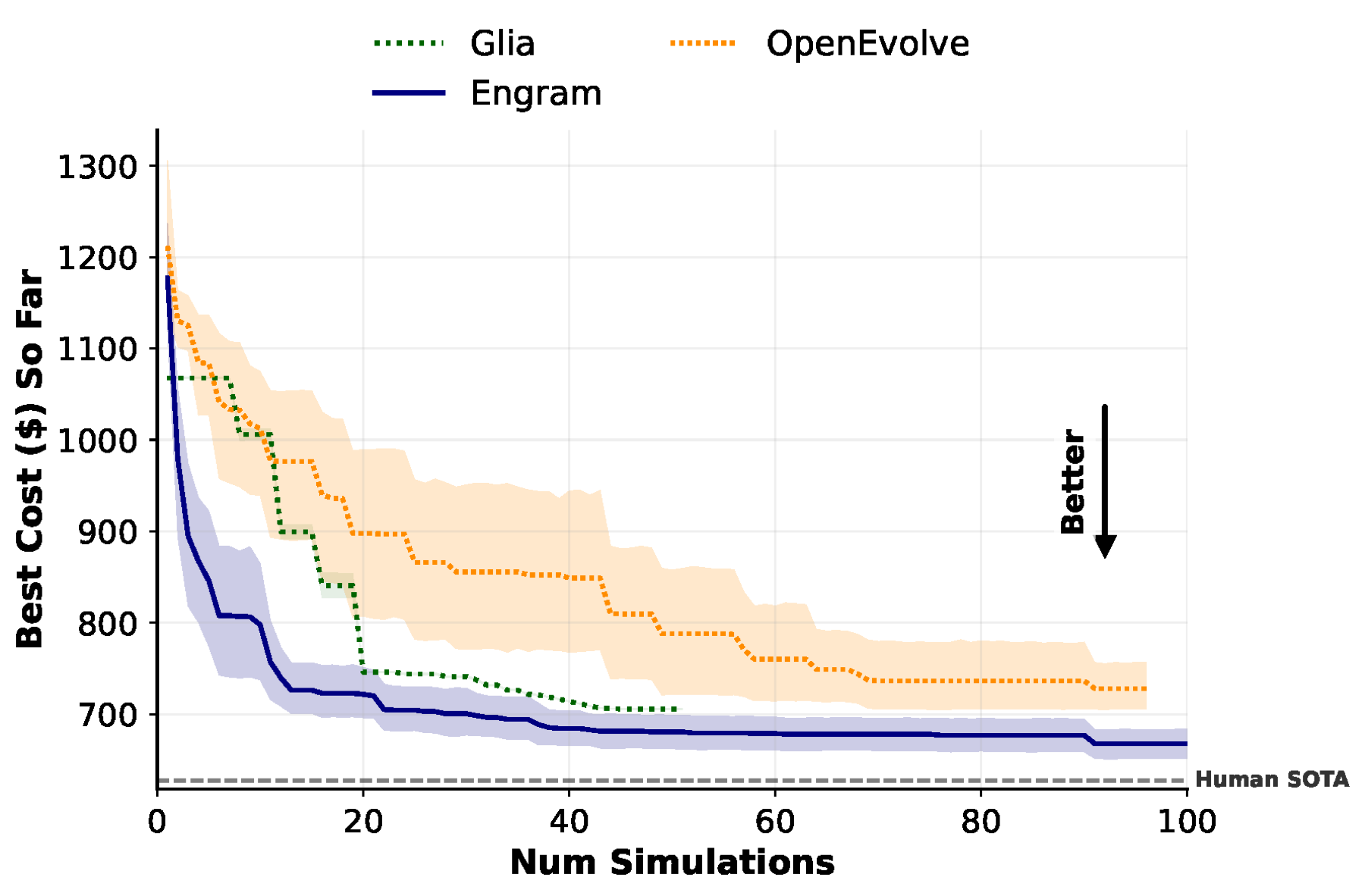
Across ten runs on multi-cloud multicast, every baseline gets stuck in the Steiner-tree neighborhood. Glia’s provider-aware trees land at $706; OpenEvolve and FunSearch around $719–728; EoH at $782. Engram is the only LLM-based method that reframes the problem as an optimization, the same family as the human state-of-the-art. It averages $662, with its best run reaching $625 — essentially matching the human expert’s $626.
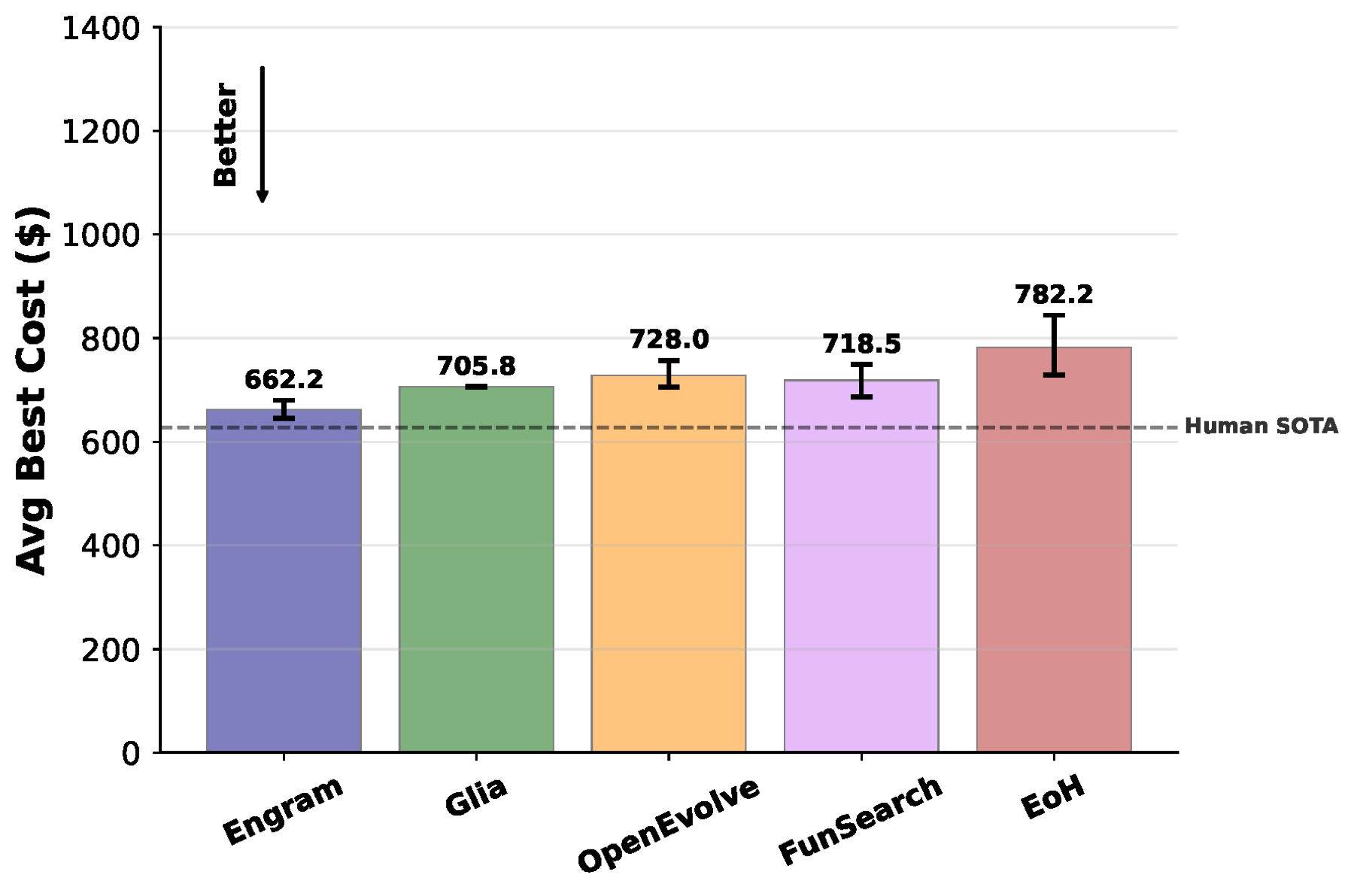
The shape of the trajectory is just as telling. Engram’s cost drops fast — past Glia’s plateau within the first 20 simulations — and keeps trending toward the human SOTA line for the rest of the budget. OpenEvolve and Glia both plateau early and stay there.
Two more results worth flagging:
With gpt-5.2, Engram doesn’t just match the expert and other baselines; it discovers a new solution family the experts didn’t use, based on dynamic programming, averaging $622 — beating human SOTA outright.
On the broader ADRS suite of systems problems, Engram matches or beats the human state-of-the-art on all tasks but one evaluated with o3, and beats or matches ADRS results on all tasks but two.
Engram vs. Human SOTA on the ADRS suite (averaged over 10 runs).
| Benchmark | Direction | Human SOTA | Engram | OpenEvolve |
|---|---|---|---|---|
| CBL | lower ↓ | 101.7 | 103.6 ± 1.1 | 103.4 ± 0.9 |
| CBL-Multi | lower ↓ | 92.3 | 79.9 ± 0.8 | 79.9 ± 0.4 |
| EPLB | higher ↑ | 0.251 | 0.273 ± 0.00 | 0.214 ± 0.06 |
| Prism | higher ↑ | 21.89 | 27.94 ± 1.70 | 26.21 ± 0.03 |
| Telemetry | higher ↑ | 0.822 | 0.954 ± 0.00 | 0.953 ± 0.00 |
| TXN | higher ↑ | 2724.8 | 3918.6 ± 56.6 | 3713.7 ± 77.9 |
The takeaway
Engram’s lesson builds directly on Glia’s. Glia showed an AI can do systems research like a PhD student. Engram shows you can let that research run indefinitely — across hundreds of trials and many agents — by handing off the right thing at each step.
Three ideas carry the whole system. Carry forward interpretation, not raw history — a clean diagnosis beats a decaying transcript. Tolerate temporary regressions — the conceptual leaps that escape local optima almost always score worse before they score better. And persist knowledge across agents, through a Digest that explains and an Archive that records.