Constructing
3D Class Models
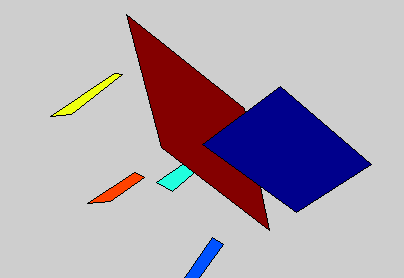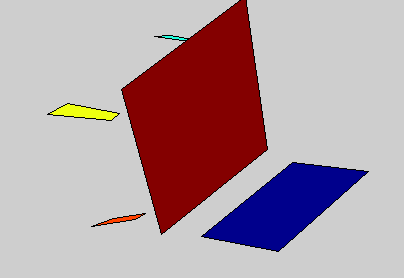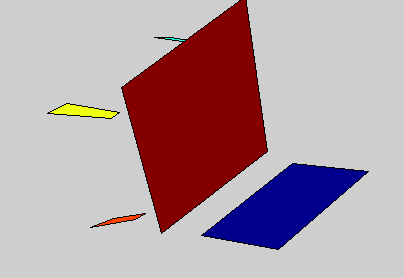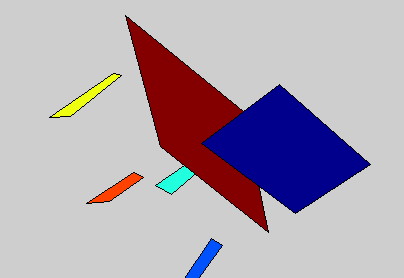
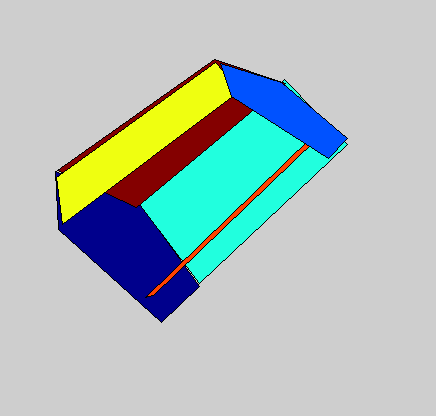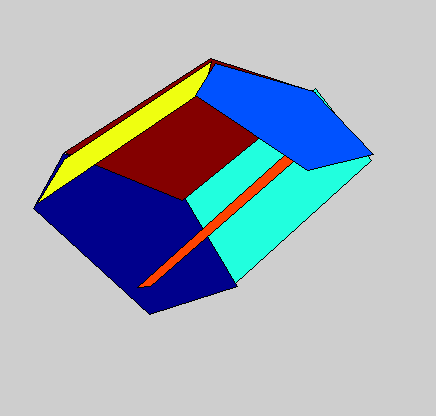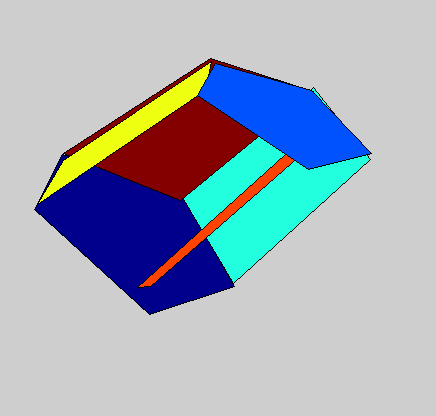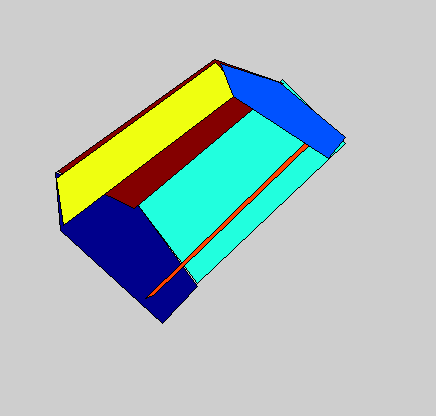
Detailed 3D models of variable object classes can be difficult to learn and use. In this project, we propose the 3D Potemkin model, which is a relatively weak 3D model, but which is powerful enough to support reconstruction of the 3D shapes of objects. Informally, the 3D Potemkin model can be viewed as a collection of 3D planar shapes, one for each part, which are arranged in three dimensions. This model can also be viewed as a simplification of a detailed 3D model using a small set of 3D planar polygons. The 3D Potemkin model is extended from the Potemkin model, but they are quite different. The Potemkin model, which is too weak to support 3D reconstruction, only estimates 2D image-image transforms and a set of 3D points (part centroids). Compared to the Potemkin model, the 3D Potemkin model retains the property that can be constructed using only a few real images of an object of the class, but computes a set of 3D planes rather than 2D transforms.
The learned 3D Potemkin model can be used to enable existing
detection systems to reconstruct the 3D shapes of detected objects. Current existing
detection methods are only able to obtain 2D shapes (or partial 3D information)
from the detected objects, which are not sufficient for artificial systems to
interact with the external object in 3D space, such as moving a robot arm to
grasp objects. Thus, we develop the 3D Potemkin model that enables existing
detection methods to reconstruct the 3D shapes of objects and to be applicable
to applications in computer graphics and robotics.
Publications
Han-Pang Chiu, Leslie Pack Kaelbling, and Tomas Lozano-Perez, "Automatic
Class-Specific 3D Reconstruction from a Single Image", MIT CSAIL
Technical Report MIT-CSAIL-TR-2009-008, February 2009. pdf
Han-Pang Chiu, Leslie Pack Kaelbling, and Tomas Lozano-Perez, "Learning to Generate Novel Views of Objects for Class Recognition", Computer Vision and Image Understanding, 2009. pdf