Sebastian Claici
PhD in Computer Science
Massachusetts Institute of Technology
Biography
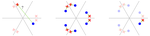
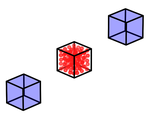
I am a final year PhD student in the Geometric Data Processing Group at MIT. My research focus is on discrete optimal transport with applications to Bayesian inference, robust learning, clustering, and data summarization. During my time in GDP I’ve been lucky to collaborate with many incredible people, among them Edward Chien, Matthew Staib, Hugo Lavenant, Pierre Monteiller, Charlie Frogner, Mikhail Yurochkin, Farzaneh Mirzazadeh, and Justin Solomon.
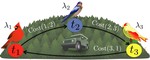
Prior to joining Justin’s group, I was a Master’s student with Daniela Rus in the Distributed Robotics Lab where I worked on modular robotics and path planning. Before coming to MIT, I received my BSc from the University of Southampton in the United Kingdom under the supervision of Klaus-Peter Zauner.
I have done internships in interpretability of deep learning at Google, semantic segmentation with Bosch Research and Technology Center, and user experience at EPFL in Lausanne.
In my spare time, I enjoy hiking, climbing, and reviewing books I’ve read.
Interests
- Optimal Transport
- Convex Optimization
- Bayesian Inference
- Robust Learning
Education
-
PhD in Computer Science, 2020
Massachusetts Institute of Technology
-
SM in Computer Science, 2016
Massachusetts Institute of Technology
-
BSc in Computer Science, 2014
University of Southampton