|
The site is now moved to https://cloudygoose.github.io/ Hi! I'm currently a postdoc at UW, supervised by Yulia Tsvetkov, who runs the Tsvetshop. Not long ago, I was a PhD student at MIT, supervised by Prof. James Glass, who runs the SLS group. My research interest lies in natural language processing and deep learning. Most of my works during my PhD is focused on neural language generation. You can download my PhD defense slides here. I did my bachelor and master degree at Shanghai Jiao Tong University, and my research there was supervised by Prof. Kai Yu, who runs the SJTU SpeechLab. At SJTU I was in the ACM honored class. Teaching: My guest lecture slides for UW NLP Course (undergrad/master level), Basics on NNLM(Back-propagation, RNN, etc.), and Advanced NNLM(attention, transformers, etc.). My wife and I raise two corgis Minnie&Mickey! We post their photos on RED , and Instagram . I like to make fun videos with games, two of my favourite (most of them are in Chinese): (1) MarioKart at MIT. (2) I built a theme park for proposal. I plan to be on academia job market mainly in U.S./China/Canada in fall/winter 2023. CV / Email / Google Scholar / Twitter |

|
|
My current research interest lies in identifying and mitigating the risk of deployment of large language models in real-world applications. Most of my works during my PhD is focused on neural language generation. Representative papers are highlighted. |
|
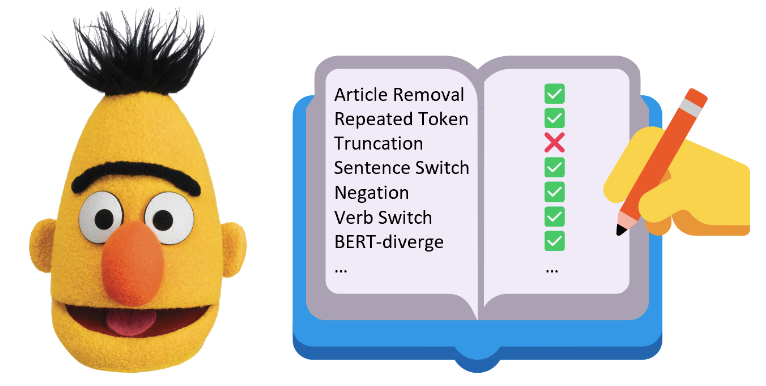
Tianxing He*, Jingyu Zhang*, Tianle Wang, Sachin Kumar, Kyunghyun Cho, James Glass, Yulia Tsvetkov ACL 2023, selfcontained-oral-slide In this work, we explore a useful but often neglected methodology for robustness analysis of text generation evaluation metrics: stress tests with synthetic data. Basically, we design and synthesize a wide range of potential errors and check whether they result in a commensurate drop in the metric scores. Our experiments reveal interesting insensitivities, biases, or even loopholes in existing metrics. Further, we investigate the reasons behind these blind spots and suggest practical workarounds for a more reliable evaluation of text generation. |
|
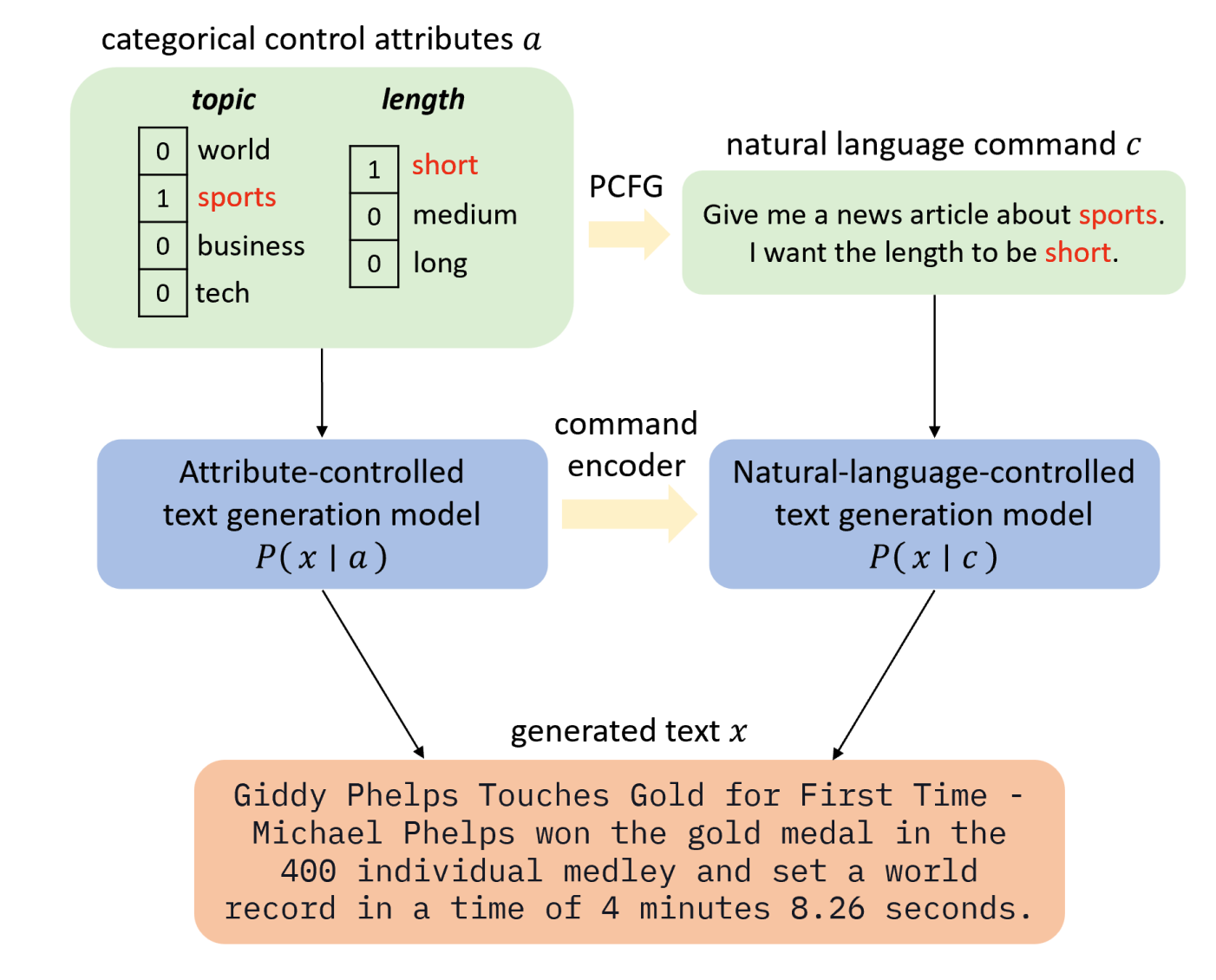
Jingyu Zhang, James Glass, Tianxing He The 2022 Efficient Natural Language and Speech Processing Workshop (NeurIPS ENLSP 2022) The Best Paper Award at the Workshop We propose a natural language (NL) interface for controlled text generation, where we craft a PCFG to embed the control attributes into natural language commands, and propose variants of existing CTG models that take commands as input. |

|
Jiabao Ji, Yoon Kim, James Glass, Tianxing He ACL-Findings 2022 Different focus in the context leads to different generation! We develop the "focus vector" method to control the focus of a pretrained language model. |
|
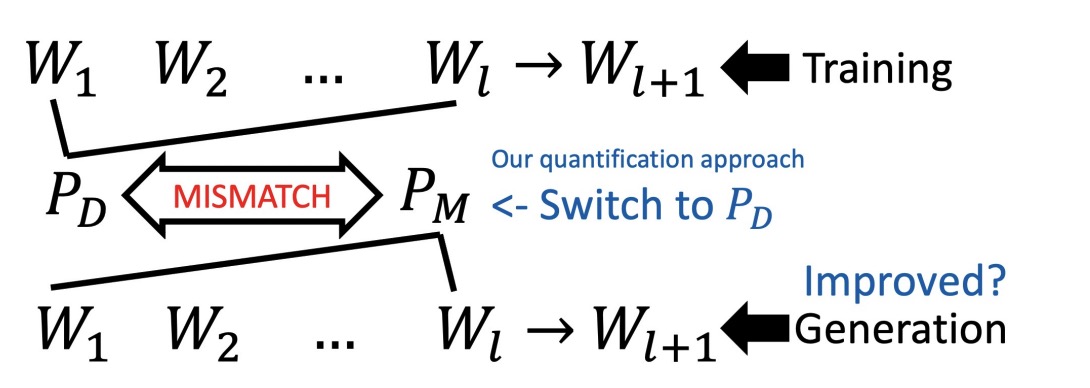
Tianxing He, Jingzhao Zhang, Zhiming Zhou, James Glass EMNLP 2021 By feeding the LM with different types of prefixes, we could assess how serious exposure bias is. Surprisingly, our experiments reveal that LM has the self-recovery ability, which we hypothesize to be countering the harmful effects from exposure bias. |
|
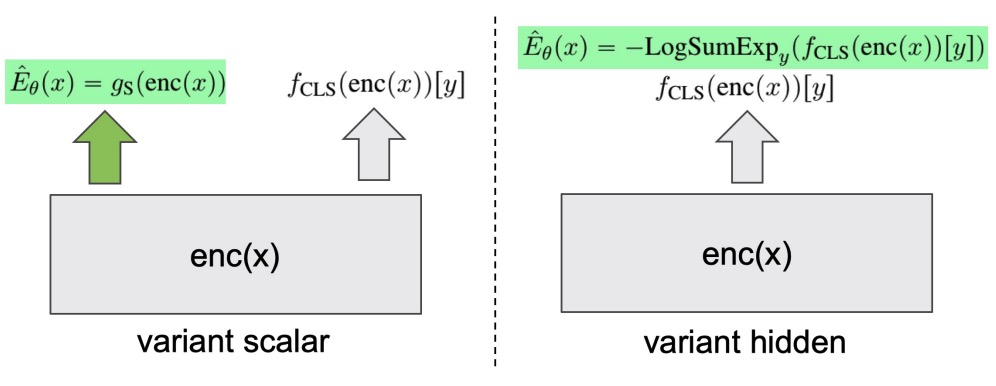
Tianxing He, Bryan McCann, Caiming Xiong, Ehsan Hosseini-Asl EACL 2021 We explore joint energy-based model (EBM) training during the finetuning of pretrained text encoders (e.g., Roberta) for natural language understanding (NLU) tasks. Our experiments show that EBM training can help the model reach a better calibration that is competitive to strong baselines, with little or no loss in accuracy. |

|
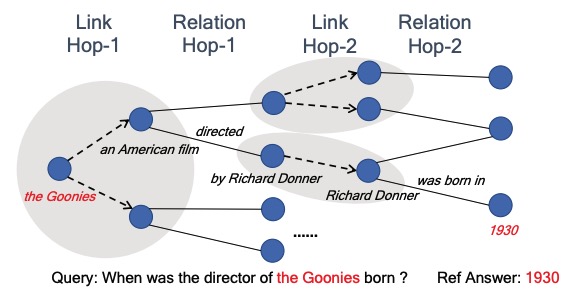
Tianxing He, Kyunghyun Cho, James Glass On Arxiv We compare a variety of approaches under a few-shot knowledge probing setting, where only a small number (e.g., 10 or 20) of example triples are available. In addition, we create a new dataset named TREx-2p, which contains 2-hop relations. |
|
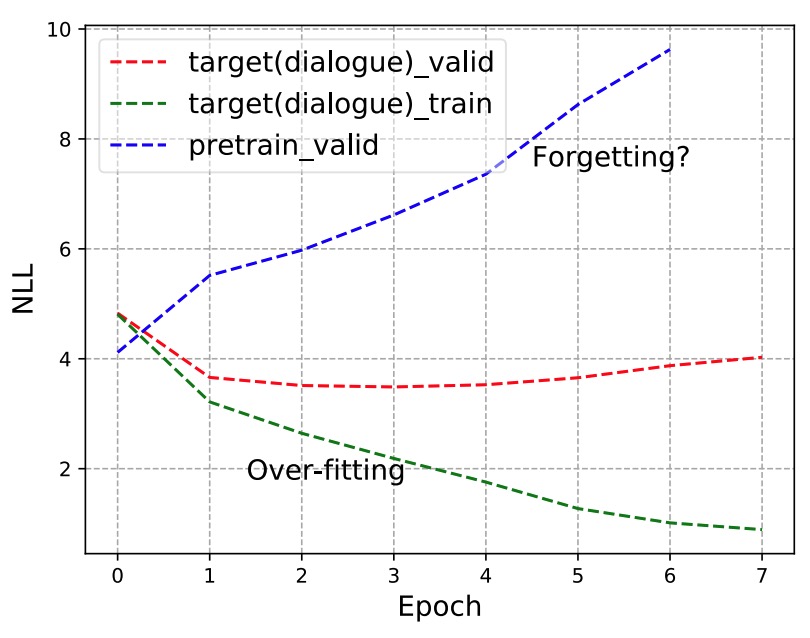
Tianxing He, Jun Liu, Kyunghyun Cho, Myle Ott, Bing Liu, James Glass, Fuchun Peng EACL 2021 After finetuning of pretrained NLG models, does the model forget some precious skills learned pretraining? We demonstrate the forgetting phenomenon through a set of detailed behavior analysis from the perspectives of knowledge transfer, context sensitivity, and function space projection. |
|
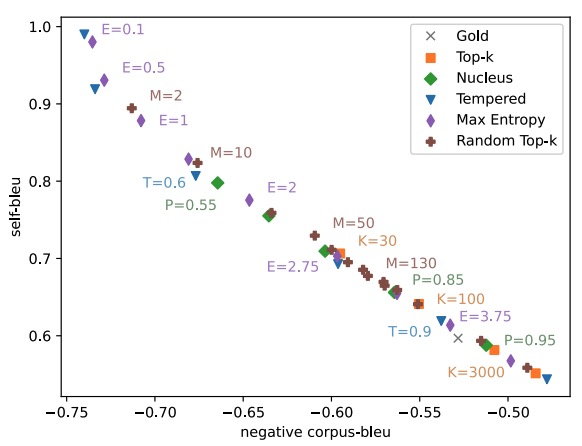
Moin Nadeem*, Tianxing He* (equal contribution), Kyunghyun Cho, James Glass AACL 2020 We identify a few interesting properties that are shared among existing sampling algorithms for NLG. We design experiments to check whether these properties are crucial for the good performance. |
|
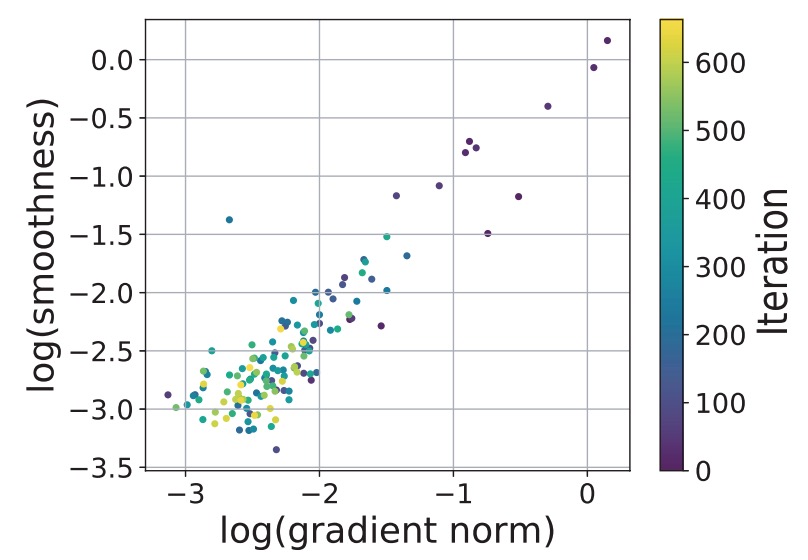
Jingzhao Zhang, Tianxing He, Suvrit Sra, Ali Jadbabaie ICLR 2020 Reviewer Scores: 8/8/8 We provide a theoretical explanation for the effectiveness of gradient clipping in training deep neural networks. The key ingredient is a new smoothness condition derived from practical neural network training examples. |

|
Tianxing He, James Glass ACL 2020 Can we "correct" some detected bad behaviors of a NLG model? We use negative examples to feed negative training signals to the model. |
|
Seunghak Yu, Tianxing He, James Glass Preprint We propose a novel framework to automatically construct a KG from unstructured documents that does not require external alignment. |
|
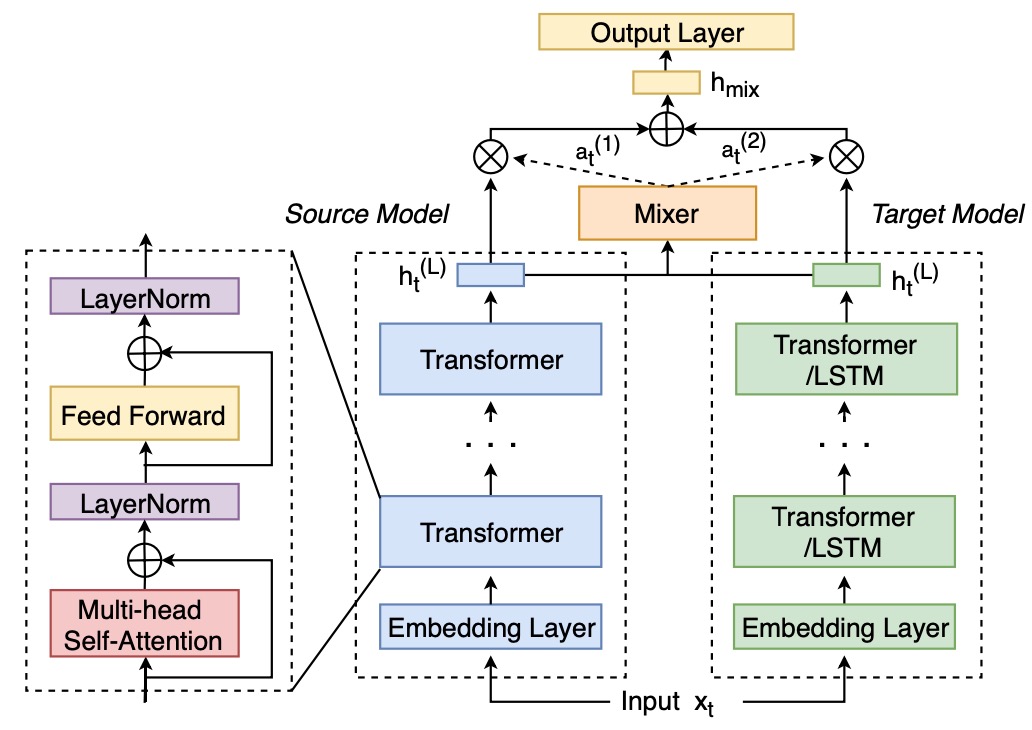
Ke Li, Zhe Liu, Tianxing He, Hongzhao Huang, Fuchun Peng, Daniel Povey, Sanjeev Khudanpur ICASSP 2020 We propose a mixer of dynamically weighted LMs that are separately trained on source and target domains, aiming to improve simple linear interpolation with dynamic weighting. |

|
Tianxing He, James Glass ICLR 2019 Can we trick dialogue response models to emit dirty words? |
|
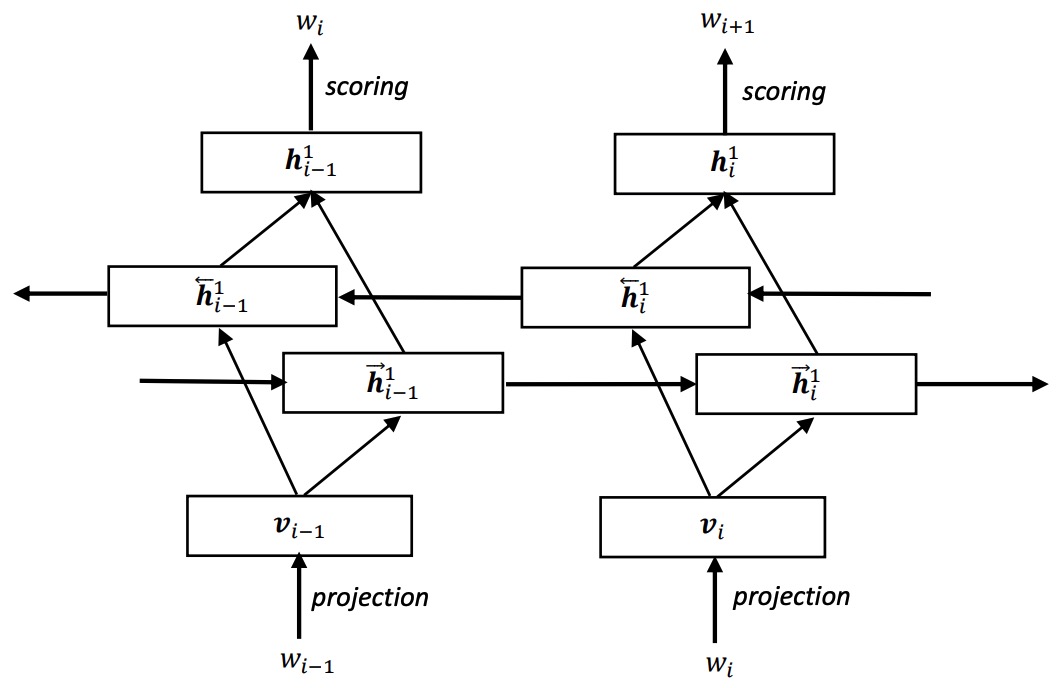
Tianxing He, Yu Zhang, Jasha Droppo, Kai Yu ISCSLP 2016 We attempt to train a bi-directional RNNLM via noise contrastive estimation. |
|
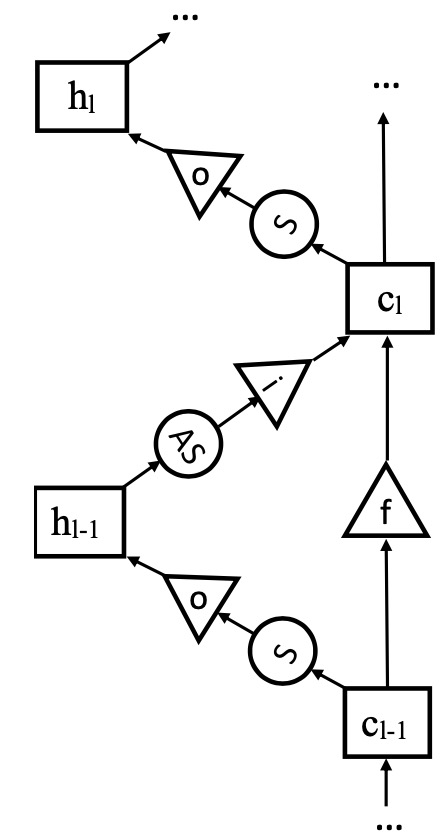
Tianxing He, Jasha Droppo ICASSP 2016 We design a LSTM structure in the depth dimension, instead of its original use in time-step dimension. |
|
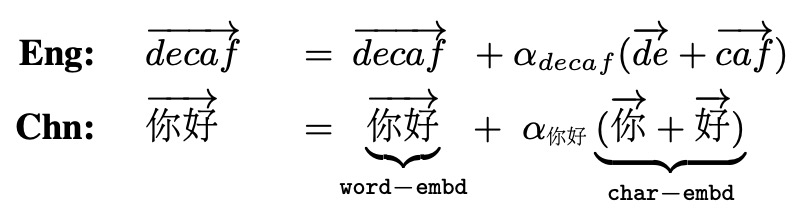
Tianxing He, Xu Xiang, Yanmin Qian, Kai Yu ICASSP 2015 We restructure word embeddings in a RNNLM to take advantage of its sub-units. |
|
Tianxing He, Yuchen Fan, Yanmin Qian, Tian Tan, Kai Yu ICASSP 2014 We prune neurons of a DNN for faster inference. |
|
The design and code of this website is borrowed from Jon Barron's site. |